AttentionからGANベースの手法まで画像キャプション生成の技術まとめ
3つの要点
✔️ 画像キャプション生成のサーベイ論文
✔️ 現在の技術、データセット、ベンチマーク、評価指標を紹介
✔️ GANベースのモデルが最も高いスコアを達成した
A Thorough Review on Recent Deep Learning Methodologies for Image Captioning
written by Ahmed Elhagry, Karima Kadaoui
(Submitted on 28 Jul 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
画像キャプションには画像の自動インデックス作成などの様々な用途があります。人間のアノテーションは非常にコストがかかります。そのため自動でキャプションを生成する技術の需要はますます高まっています。この分野ではすでに多くの研究が行われ、サーベイ論文も出ていますが近年のいくつかの重要なモデルをカバーするものはありません。最近発表された最も関連性の高い論文をいくつか取り上げ、そのモデルの性能を比較し、その仕組みを説明するためにこの論文を紹介します。今日、画像キャプションにおいてattentionの使用が最も重要な技術の一つです。Transformerが登場して以来、機械翻訳や言語モデリングなどの多くのタスクは、Transformerのおかげで大幅な性能の向上を達成しました。画像キャプション生成も同様で、本論文で紹介するように、様々なモデルで利用されています。研究者の注目を集めたもう一つの技術は深層強化学習です。「森の中のベッド」などの特に珍しい画像に適していることが示されています。
手法
Updown
今日のvisual attentionを用いる一般的な技術のほとんどはトップダウン型(マクロ→ミクロ)です。これらのモデルでは各タイムステップで部分的に完成したキャプションが与えられ、文脈を得ることができます。しかし、画像のどの領域に焦点を当てるかについての問題があります。顕著な、わかりやすいオブジェクトに焦点を当てるようにすることで人間が作成するようなキャプションを生成することが可能となります。
これらの問題を踏まえ、こちらでは視覚的なボトムアップの手法とタスク固有の文脈のトップダウンの手法を結合したモデルである"Up-down"を提案しています。前者は顕著と思われるオブジェクト領域に関する提案を与え、後者は文脈を利用してそれらに対するatentionの分布を計算します。その結果、入力画像中の重要なオブジェクトに注意を向けることができます。
Up-downの実装について紹介します。ボトムアップ部分はFaster R-CNNのオブジェクト検出モデルを用いており、バウンディングボックスで囲む処理を行います。Resnet-101で初期化し、Visual Genomeデータセットで事前学習します。トップダウン部分は、visual attention LSTMとlanguage attention LSTMを用いています。attention LSTMには、前のlanguage LSTMの出力、時刻t-1に生成された単語、平均プーリングされた画像特徴が与えられ、どの領域に焦点を当てるかを決定します。そしてその時点までに生成されたキャプションを用いて、出力単語に対する条件付き分布を計算し、キャプションに対する分布を得ます。
OSCAR
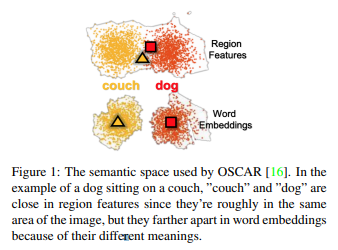
Vision-language pre-training (VLP)はクロスモーダル(画像・言語)な表現を学習するために広く用いられています。しかしVLPには各画像の領域が重なっていることによる識別の困難さや単語とそれに対応する画像領域の位置のズレという2つの問題があります。こちらではOSCARが提案され、オブジェクトのタグを"アンカーポイント"として利用することでこれらの問題を解決しています。画像領域の特徴量・オブジェクトタグ・単語列(キャプション)の3つを入力として使用します。これによりある1つが不完全であったり、ノイズが多い場合にその他で情報を補完することができます。
OSCARの実装について紹介します。OSCARはFaster R-CNNを用いてオブジェクトタグを検出し、以下の2つを得ます:
- タグとキャプションのトークンを含む言語的意味空間と画像領域を含む視覚的意味空間(Figure 1)
- 画像特徴量とタグを含む画像モダリティとキャプショントークンを含む言語モダリティ
VIVO
nocapsチャレンジでは画像キャプション生成のデータセットとしてMS COCOのみ認められいるため、VLP手法は適用できません。そのためこちらではVIVO(VIsual VOcabulary pre-training)を考案しています。これはタグと画像領域の合同埋め込み空間であり、意味的に近いオブジェクト(アコーディオンと楽器など)のベクトルが近いところに存在するような"visual vocabulary"を定義しています(Figure 2)。
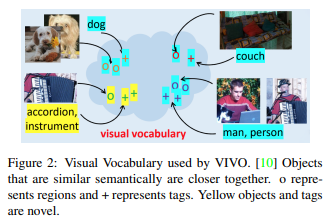
語彙の事前学習後、MS COCOデータセットを用いて画像とキャプションのペアでモデルのfine-tuningを行います。VIVOと他のVLPモデルの違いとして、VIVOは画像とタグのペアで事前学習し、fine-tuningを行うまではキャプションのデータセットを用いないことです。タグはキャプションに比べ、自動で生成されやすいためアノテーションの費用を抑えることができます。さらに膨大な数のタグを使用することができるため非常に有用です。
VIVOの実装について紹介します。多層Transformerによってタグとそれに対応する画像領域の位置合わせを行います。その後線形層とsoftmaxを使用します。事前学習ではUp-downのオブジェクト検出モデルを用いて入力画像から画像領域を抽出し、画像とタグのペアセットとともにTransformerに入力します。モデルはマスクされたその他のタグと画像領域に対して予測を行います。fine-tuningでは先ほども紹介しましたが、画像領域・タグ・キャプションの3つを入力し、キャプションのトークンの一部がマスクされモデルはそれらを予測するように学習します。
Meta Learning
強化学習の欠点の一つとして、エージェントがより良い品質のキャプションを生成せずにスコアを最大化する方法を見つけてしまう報酬関数のオーバーフィッティングがあります。例えば、CIDEr最適化を使用する場合、短すぎるキャプションには罰が与えられます。そのため短いキャプションが生成されると、長くするために冗長なフレーズが追加され、"a little girl holding a cat in a. "のような不自然な文末が生成されることになります。こちらでは複数の異なるタスクに対し最適化し、適応することができるメタ学習を導入しています。本手法によりモデルは報酬関数の最適化(強化学習のタスク)と教師有り学習を両方向に同時に行います。これによりキャプションが人間に近い文章となります。
Meta Learningの実装について紹介します。上記で開設したUp-downアーキテクチャを使用します。このモデルが今回最適化するタスクは強化学習タスクと教師有り学習の最尤推定タスクです。すなわち2つの勾配をとり、パラメータθを更新します。θは"meta update"と呼ばれる自己で更新する手法を行います。このようにして2つのタスクを最適化するパラメータθを学習することができます。
Conditional GAN-Based Model
先ほどのMeta Learningにおいて問題点となっていた報酬関数のオーバーフィッティングに対して、こちらでは生成されたキャプションのが人間によるものなのか、機械(モデル)によるものなのかを判定する識別器を使用しています。元論文では手法に名前を付けていないのでIC-GAN (Image Captioning GAN)と呼びます。
実装について紹介します。識別器のアーキテクチャとして全結合層とシグモイド関数を用いたCNNと、全結合層とソフトマックス関数を用いたRNN(LSTM)の2種類を実験しています。また、それぞれ4つのCNNとRNNを用いたアンサンブルの実験もしています。本手法ではキャプション生成までを生成器と捉えています。生成器についてはいくつかのアーキテクチャで実験されていますが、今回はUp-downアーキテクチャを用いた場合の結果を中心に紹介します。いずれのケースにおいても生成器・識別器ともにfine-tuningする前に事前学習を必要とします。
評価指標
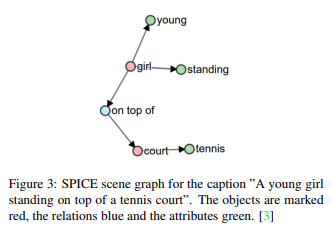
生成されたキャプションと教師データを比較するために多くの評価指標を用います。一般的に使用されるのはCIDEr、SPICE、BLEU、METEORです。今回紹介した手法全て共通で用いられている手法はCIDErとSPICEであるため本論文ではこれらを比較します。CIDEr は画像分類の評価指標で、TF-IDFを用いて人間との一致度を測ります。SPICEグラフベースの意味表現であるシーングラフ(Figure 3)に基づく、新しい意味概念に基づくキャプションの評価指標です。
Benchmark
nocapsはMicrosoft COCO Captionデータセットを利用していますが、それに加えOpenImagesオブジェクト検出データセットも利用することで前者では見られなかった新規のオブジェクトを導入しました。nocapsはOpenImagesの15100枚の画像と166100個のキャプションによって構成されています。OSCARとVIVOはnocapsの検証セットで評価されています。Karpathy splitsはMeta LearningとIC-GANの評価に用いられています。最後にUp-downを両ベンチマークで評価します。
結果
MS COCO Karpathy Splits Benchmark
手法とそれに対応する評価指標はTable 1です。
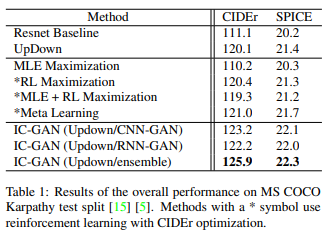
UpDown手法の比較ベースラインモデルとしてResnetの実験を行っています。UpDownはCIDEr、SPICEどちらにおいても性能の向上が見られます。この結果から、ボトムアップ的なattentionの追加は画像キャプション生成タスクにおいてプラスの影響を与えることがわかります。メタ学習を用いたモデルと最尤推定による最大化、強化学習、MLEと強化学習の勾配を単純に加算する状況を比較するとどちらの指標に対しても最も指標が高くなります。また、メタ学習を用いないUpDown手法に対しても若干ですが良い性能となりました。一方、IC-GANは3つのモデル全てが他の手法に比べて大幅に高い性能となりました。なお、CNN-GANの方がRNN-GANよりも良いスコアとなっていますが、RNN-GANの方が学習時間を短縮することができます。また、IC-GANは従来の強化学習手法で見られる単語の重複や「a group of people standing on top of a clock」のような論理の破綻を回避し、より人間らしいキャプションを生成することができます。
nocaps Benchmark
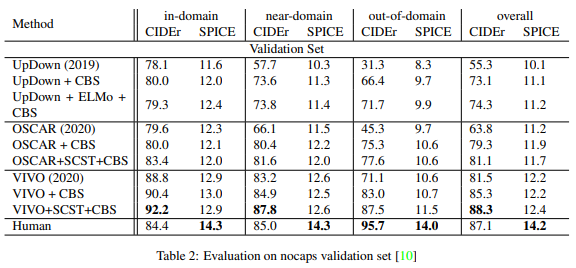
OSCARはUpDown手法に比べ、in-domain・near-domain・out-of-domain全てのサブセットで性能が優れています。さらにConstrained Beam Search(CBS)とSelf Critical Sequential Training(SCST)を加えることにより性能は飛躍的に向上しました。特にout-of-domainで顕著に見られます。しかし、OSCARよりも良い性能を出しているのがVIVOです。VIVO+SCST+CBSはin-domainとnear-domainにおいてCIDErのスコアが人間によるキャプションよりも良い性能を出しました。
まとめ
現在の画像キャプション生成の研究は深層学習に重きを置いています。これは本タスクがコンピュータビジョンと自然言語処理両方を組み合わせたものであり非常に複雑であるためそのレベルを扱うことができるような"パワー"のある技術が求められているためです。また、本論文で紹介されているようにattentionは深層強化学習や敵対的学習と並んで活発に研究されています。Faster R-CNNはLSTMと並んで人気のあるアーキテクチャであり、特にUpDownモデルは近年の論文の基礎技術として使われています。
本論文では最新の手法とその実装について紹介しました。今回紹介したUpDown、OSCAR、VIVO、Meta Learning、GANベースの手法のうち、GANベースが最も性能が高く、UpDownはインパクトがあり、OSCARとVIVOはより有用であることがわかりました。
参考文献
※本記事で紹介した技術に関する論文のみ
[1] P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson,S. Gould, and L. Zhang. Bottom-up and top-down attention for image captioning and VQA. CoRR, abs/1707.07998,2017.
[2]X. Li, X. Yin, C. Li, P. Zhang, X. Hu, L. Zhang, L. Wang, H. Hu, L. Dong, F. Wei, et al. Oscar: Object-semanticsaligned pre-training for vision-language tasks. In EuropeanConference on Computer Vision, pages 121–137. Springer,2020.
[3]H. Agrawal, K. Desai, Y. Wang, X. Chen, R. Jain, M.Johnson, D. Batra, D. Parikh, S. Lee, and P. Anderson. nocaps: novel object captioning at scale. CoRR, abs/1812.08658,2018.
[4]X. Hu, X. Yin, K. Lin, L. Wang, L. Zhang, J. Gao, and Z. Liu.Vivo: Visual vocabulary pre-training for novel object captioning, 2021.
[5]N. Li, Z. Chen, and S. Liu. Meta learning for image captioning. Proceedings of the AAAI Conference on ArtificialIntelligence, 33:8626–8633, 2019.
[6]C. Chen, S. Mu, W. Xiao, Z. Ye, L. Wu, and Q. Ju. Improving image captioning with conditional generative adversarialnets. Proceedings of the AAAI Conference on Artificial Intelligence, 33:8142–8150, 2019.



この記事に関するカテゴリー


