局所ラベルを用いた複数ラベリングによるImageNetの再ラベリング手法「ReLabel」!
3つの要点
✔️ImageNetにおいて複数クラスの再ラベリングを行うReLabelの提案
✔️複数クラスラベルの識別学習の手法LabelPoolingも提案
✔️ReLabelによるりImageNetのベンチマーク、転移学習、複数ラベル識別などのタスクで効果を発揮
Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels
written by Sangdoo Yun, Seong Joon Oh, Byeongho Heo, Dongyoon Han, Junsuk Choe, Sanghyuk Chun
(Submitted on 13 Jan 2021)
Comments: 15 pages, 10 figures, tech report
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
はじめに
ImageNetはコンピュータビジョンの各タスクにおいて非常に有用なデータセットで数、クラス数ともに莫大な量存在します。ImageNetのおかげで、コンピュータビジョンにおける機械学習モデルの精度が発展したといっても過言ではありません。しかし、ImageNetを実際に使ってみるとわかりますが、ImageNetの画像内には複数のカテゴリが存在しており非常に紛らわしいクラスが多数含まれています(犬の種類等)。そのためImageNetで学習すると他のクラスが出力される場合や類似するクラスだと認識されることがあります。このため、近年ではImageNetに対して複数ラベリングを行おうとした研究が見られ(Lucas et al., Vaishaal et al.)、複数ラベルに対する評価手法も提案されてきました。さらに、複数ラベルデータセットに対しての識別タスクでは人間の性能を下回ることがわかりました(Qizhe et al., Huga et al.)。
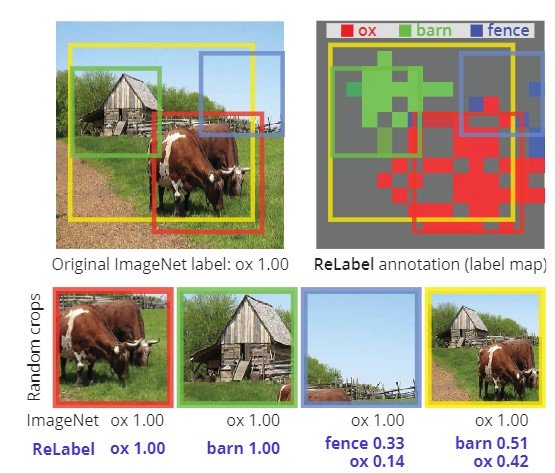
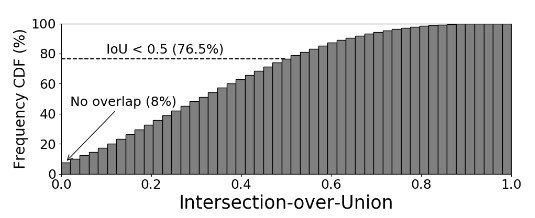
複数の物体が存在するデータに対して単一のラベルしか割り当てられていない問題は、評価のみでなく学習に対しても影響を及ぼし、データセットに対しノイズを加えることになります。特に水増しの際にrandom cropを行うと思いますが、図1のように切り取った画像に異なる物体を含む可能性があります。1つしか物体がない場合でも、random cropにより物体が存在しない場所を切り取る可能性もあります。実験によると、ImageNetの学習セットを用いるとrandom cropを用いたときの8%は正解データが切り取られておらず、23.5%のみしか正解データのボックスとIoUが50%以上となりません(図2)。
そのため、複数のラベリングを行うために新たにラベリングを行います。人手によるラベリングでは128万枚のImageNetに対して莫大な時間がかかるため、この研究では再ラベリングの手法としてReLabelを提案し、複数ラベル、局所ラベルに対応したpixel-wiseのラベリングを可能にしました。以下では、ReLabelを用いたラベリングとそれぞれのrandom cropサンプルに対してラベリングスコアをプーリングすることで複数ラベルの正解データを出力するLabelPoolingについて解説します。
提案手法:ReLabel
著者らはImageNetの学習セットに対してピクセルレベルの正解ラベルを出力するため再ラベリング手法である、「ReLabel」を提案しました。ターゲットとなるラベルマップは2種類あります。
- 複数クラスラベル
- 局所的ラベル
ラベルマップは追加のデータに対して学習させたSoTAの画像識別器を用い、局所的な複数ラベルを用いて画像識別モデルを学習させるために、学習フレームワークである「LabelPooling」を提案しラベルマップを作成しています。以下ではそれぞれについて解説していきます。
ImageNetの再ラベリング
まず正解ラベルを取得するために、人手でラベリングをするためには莫大なコストがかかるために、ここではsuper-ImageNetと題してJFT-300MやInstagramNet-1Bのような膨大なデータセットを用いて画像識別器を学習させ、ImageNetでファインチューニングをすることで、ImageNetのクラスを予測できる学習モデルを作成します。
ここで特筆すべき点として、ImageNetでは単一ラベルを出力するように学習している(softmax cross-entropy lossを使っている)のですが、画像内に複数カテゴリーが存在する場合に複数ラベルの予測も行われます。理由としては、前提として識別器の損失関数にcross-entropy lossを用いており、正しいカテゴリと画像が入力として与えられ、加えて他のラベルが存在しているとします。すると、他のラベルと区別するためにcross-entropy lossは以下のように与えられます。
\begin{equation}-\frac{1}{2}(\Sigma_k y^0_k \log p_k(x) + \Sigma_k y^1_k \log p_k(x)) = - \Sigma_k \frac{y^0_k + y^1_k}{2} \log p_k(x)\end{equation}
で、$y^c$はインデックス$c$に1が存在するone-hotベクトルで、$p(x)$は画像$x$に対する予測ベクトルを表しています。
このcross-entropy lossを最小化するためには、$-\Sigma_k q_k \log p_k$に対して$p=q$の時となり、これは$p(x) = (\frac{1}{2}, \frac{1}{2})$を用いて予測した場合になります。ここで$q$はラベル(1か0)、$p$はラベルとなる予測ベクトルを表しています。これにより、データセット内に複数のラベルノイズが存在する場合、単一ラベルのcross-entropy lossを用いたモデルでも複数ラベルを出力することができます。
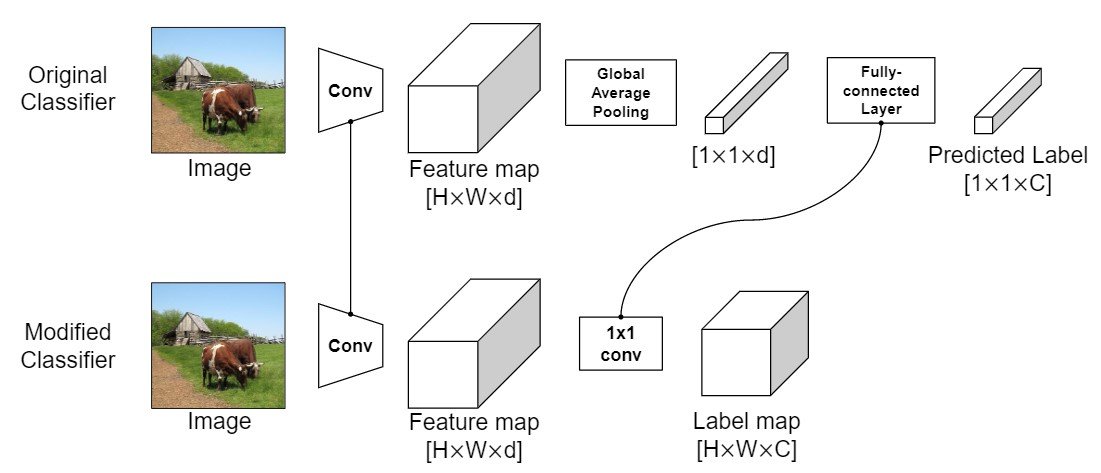
加えてこの識別器を用いてラベルを取得することで、局所ラベルを取得することができます。通常の識別器におけるglobal average pooling層をなくし、1 x 1の畳み込み層に線形層を加えることで、識別器を全結合ネットワークとして機能します(Bolei et al., Jonathan et al.)モデルの出力は$f(x) \in \mathbf{R}^{WxHxC}$で出力$f(x)$をラベルマップアノテーション$L \in \mathbf{R}^{WxHxC}$として用いています。詳細図は以下の通りです。
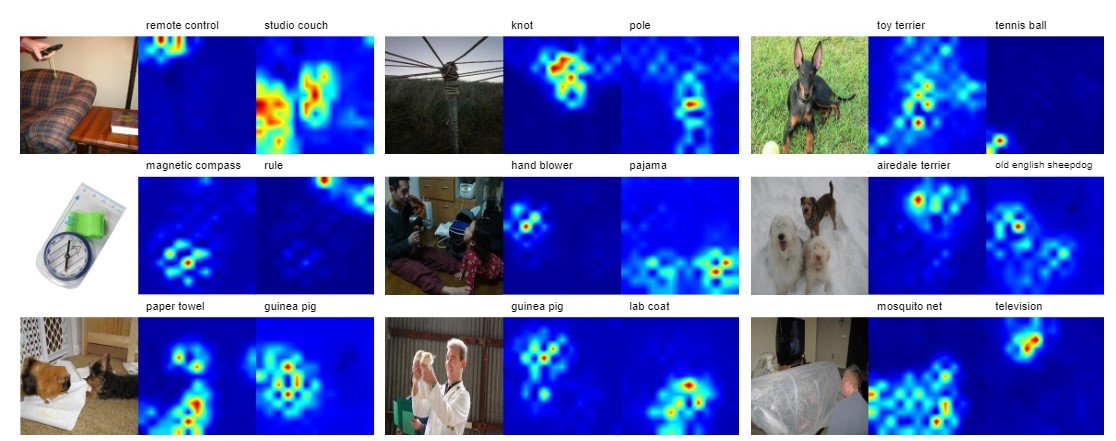
この識別器により出力されるラベルマップは以下のようになります。図ではtop-2のカテゴリーに対してのヒートマップを表示しています。
複数ラベルによる画像識別器の学習
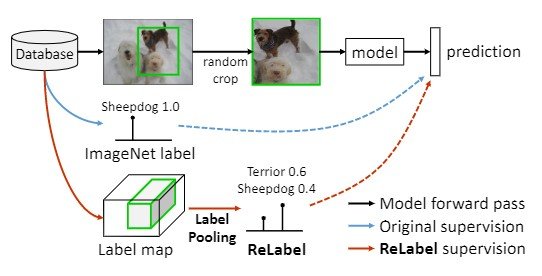
複数ラベル$L \in \mathbf{R}^{WxHxC}$を用いて学習する手法として、この研究では、LabelPoolingを提案。LabelPoolingは局所的な正解データを考慮することで複数データに対応しています(図3)。
通常のImageNetにおける学習の設定においては、画像につき単一のラベルによるランダムな切り抜きが行われます。一方LabelPoolingは事前に作成したラベルマップを用いてランダムな切り抜きに対応した箇所に対して領域プーリングを行います。(ROIAlign regional pooling approach) Global average poolingとsoftmaxによって複数ラベルの予測を行います。擬似コードは以下の通りになっています。

実験と結果
提案した局所的複数ラベルのラベリングとそれを用いた学習を用いて、様々なタスクで実験をしています。複数のネットワーク構造と評価指標を比較するために、ImageNet上でReLabelを用いて画像認識を行います。次に、画像検出、インスタンスセグメンテーション、画像識別タスクでReLabelを用いて学習したモデルで転移学習を行い性能を評価し、さらにCOCOデータセットの複数ラベル識別タスクでReLabelが良い精度を出したことを証明しました。以下NAVER Amart Machine Learning(NSML)プラットフォーム上でPyTorchを用いてすべての実験を行っています。
ImageNetでの画像識別
ImageNet-1Kベンチマークを用いてReLabelを評価します。データセットには128万枚の学習セットと5万枚の評価画像、1000カテゴリー存在します。データの水増しには、random cropping、flipping、color jitteringを用います。学習率0.1から始め、SGDを用いて300エポック学習しています。バッチサイズは1024、重み減衰率は0.0001です。
・ラベリング手法の比較
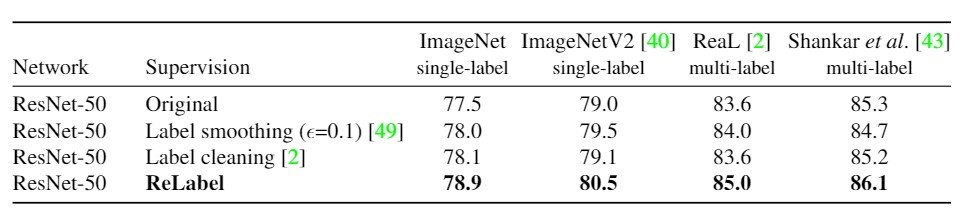
まず最初の実験として、他のラベリング手法と比較します。Label smoothingは前面のクラスに対しては小さい重みを用い$(1-\epsilon)$、後面のクラスに対しては$\epsilon$を重みに用いる手法です。Label cleaningは教師識別器の予測が正解データのアノテーションと異なっていれば学習サンプルからデータを外してしまう、という手法です。この研究では、Label cleaning後の洗練されたデータセットを用いることとし、ResNet-50に対してReLabelを用いて実験を行います。 結果は表3のとおりです。ImageNetとImageNetV2の評価用データセットに対して単一ラベルの精度を求めています。また、複数ラベルの精度を求めるために、ここではReaLとShankarのデータセットを用いて比較しています。
評価手法は$\frac{1}{N}\Sigma^N_{n=1} 1 (\arg\max f(x_n) \in y_n)$で$1(\cdot )$はindicator関数、$\arg\max f(x_n)$はモデル$f$のtop-1の予測を用いています。$N$はクラス数です。画像$x_n$に対する正解データは$y_n$で表されます。表によると、すべての指標において、ReLabelが最も精度が高く、複数ラベルのベンチマークに対してReLabelのみが特筆して精度が高いことがわかります。
・様々なネットワーク構造の比較
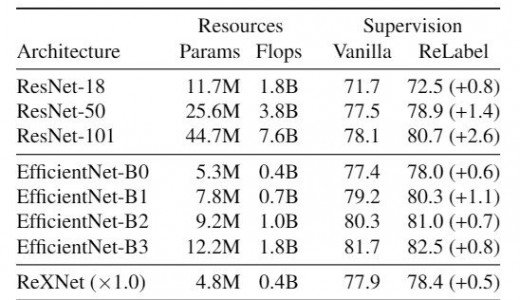

ReLabelは異なる学習手法を用いた様々なネットワークに対して汎用的に活用できる構造です。ここでは、ResNet-18, ResNet-101, EfficientNet-{B0, B1, B2, B3}, ReXNetを用いて実験をしています。上記の表のとおり、ReLabelを用いたすべてのネットワークで精度の向上を確認できました。
また、先行研究のCutMixアルゴリズムの切り取った画像に対して、ReLabelを用いることで、ImageNet top-1の精度においてSoTAを達成しています。
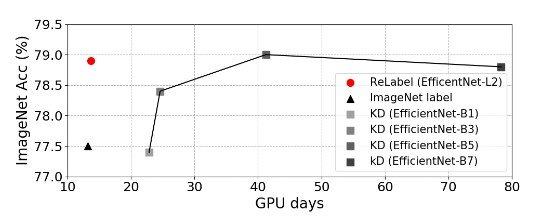
さらに、学習時間コストを評価するために、knowledge distillation (KD)とReLabelを比較しました。EfficientNetに対してKDを用いた場合、ReLabelに比べて高い精度を達成しましたが、ReLabelに比べて最低でも3倍以上もの学習時間がかかることがわかりました。
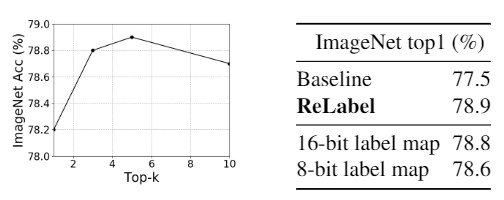
次に、ReLabelでの学習においてメモリストレージと性能のトレードオフの関係について調べています。通常ReLabelではtop-k (k=5)で効率的に実験を行っていますが、用いるデータが増えるごとにメモリを圧迫し精度が落ちていることがわかります。さらに、ラベルマップを量子化する際に8-bitよりも16-bit量子化の方が精度が良いことがわかりました。
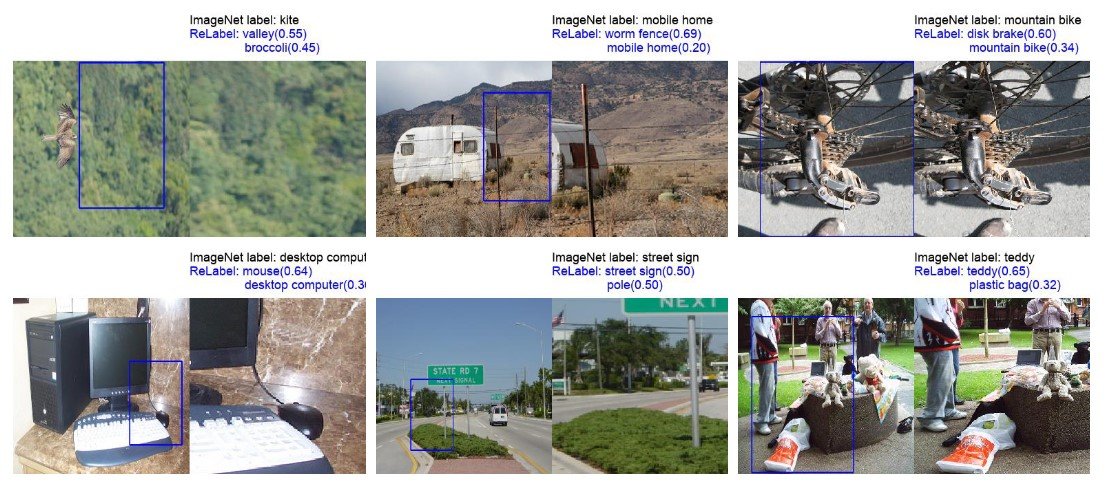
ReLabelを用いて出力した画像結果は以下のようになります。
転移学習
標準的なベンチマークとしてImageNetは広く、事前学習済みモデルとして使用されています。ここではImageNetにReLabelを用いて転移学習をした実験を行っています。COCOデータセットをもちいて、5つのfine-grained識別タスク、物体検出、そしてインスタンスセグメンテーションタスクに使っています。

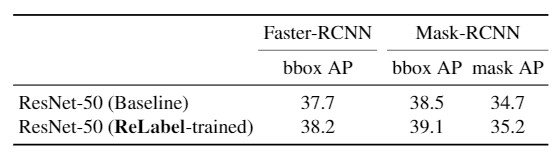
複数のデータセットを用いて識別タスクに対して実験をした結果上記の表の結果となり、それぞれReLabelを用いて学習した方が性能が向上していることがわかります。学習の際には、5000イテレーションでSGDを用いて、グリッドサーチを用いてハイパーパラメータチューニングを行っています。
さらに、物体検出とインスタンスセグメンテーションタスクに対してはFaster-RCNN、Mask-RCNNともに0.5pp、average precisionが向上していることがわかります。
複数ラベルの識別
複数ラベルの学習にはrandom croppingの水増しが効果的なことから、ReLabelとLabelPoolingに対して追加で局所的な情報を与えてあげると、複数ラベルの学習が効果的になるのかを検証します。実験するために、COCOデータセットと人間によるアノテーション済みのデータを利用した。また、機械学習で作成したラベルマップを用いてラベルマップのオラクルの効果を調査した。次に、random cropの座標に従って作成されたラベルマップを元にLabelPoolingを用いて複数ラベルの識別器を学習させました。224 x 224と448 x 448の入力画像を用いてResNet-50とResNet-101ネットワークに入力し、binary cross-entropy lossを適用させました。
結果を以下に示します。
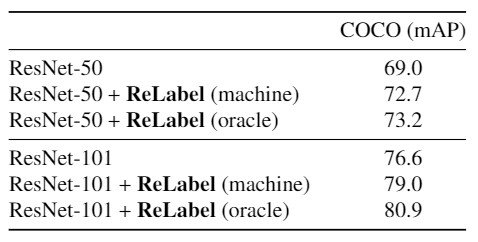
表を見ると、機械学習により作成されたラベルマップを用いたReLabelを用いた結果ResNet-50では+3.7pp、ResNet-101で+2.4ppのmAPを達成、オラクルラベルマップを用いた場合、ResNet-50で+4.2pp、ResNet-101で+4.3ppを達成しました。これにより、ReLabelによるlocation wiseな複数ラベル識別の学習の性能を上げることができました。
おわりに
画像識別で著名なImageNetデータセット、ラベリングノイズがひどく、単一ラベルのベンチマークであるのに対して複数クラスの物体が存在するという問題がありました。そこで、先行研究では複数ラベルのアノテーションを行ったが、アノテーションコストが多大にかかるために、コストの需要が少なく、学習時点で複数切り抜かれることがあり、ランダムな画像の切り抜きでも異なる物体として識別されることが多いという結果に終わっていました。そのため、この研究ではImageNetの学習セットに対して、単一ラベルの学習を複数ラベルの学習に変換することができるReLabelを提案しました。また、より強固な画像認識モデルと追加の画像データで複数ラベルを生成するために、最後のpooling層の前にpixel-wise multi-label predictionsを用いるLabelPoolingを提案。結果として、ResNet-50で78.9%の識別精度、ImageNet with CutMix正則で80.2%の精度を達成しました。加えて転移学習、複数ベンチマークにおいても性能が向上することがわかりました。今後も様々なデータセットでの応用が期待されます。






この記事に関するカテゴリー






