
LLMの「創発」は幻影か
3つの要点
✔️ 大規模言語モデルで観察される創発を検証
✔️ LLMの創発は評価指標が見せる幻影である可能性を示唆
✔️ LLM以外のモデルにおいて特定の評価指標を用いることで意図的に実際には発生していない創発を再現することに成功
Are Emergent Abilities of Large Language Models a Mirage?
written by Rylan Schaeffer, Brando Miranda, Sanmi Koyejo
(Submitted on 28 Apr 2023 (v1), last revised 22 May 2023 (this version, v2))
Comments: Published on arxiv.
Subjects: Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの,紹介スライドのもの,またはそれを参考に作成したものを使用しております.
はじめに
「創発」とは,ある要素が大量に集まった際に,その要素単体では見られなかったような効果や現象が発生することを言います.昨今の大規模言語モデル(LLMs),つまり膨大なパラメータ数を持つGPTなどのTransformerの事前学習済みDecoderにおいても,パラメータ数を上げていくと小さいモデルでは見られなかったタスクを解けるようになったり,精度が大幅に上昇することが数多くの研究で観測されています.これらの現象は,横軸を対数スケールのパラメータ数,縦軸を特定のタスクにおける評価指標のスコアで示したグラフにおいて,パラメータ数を上げていった際に突如急激に上昇したスコアによってしばしば表現されています(下図参照).
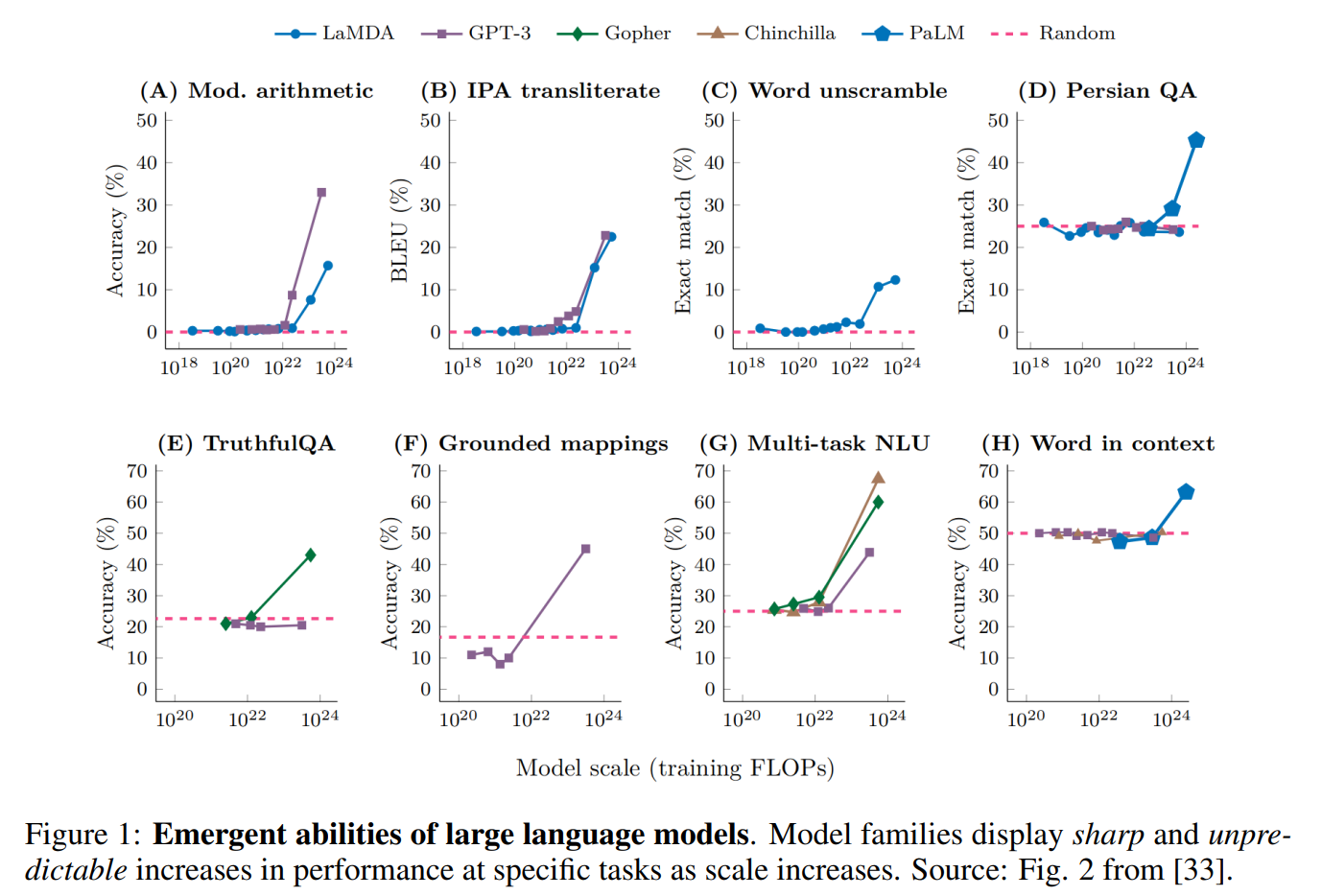
しかしながら,この論文ではそういったLLMsの「創発」というのは,研究者が作為的に選択した評価指標によって見える「幻影」である,ということを主張しています.LLMsの創発に関しては,いくつか懐疑的な視点から分析を試みた研究がありますが,この論文はそのうちの一つと言えます.
創発の正体
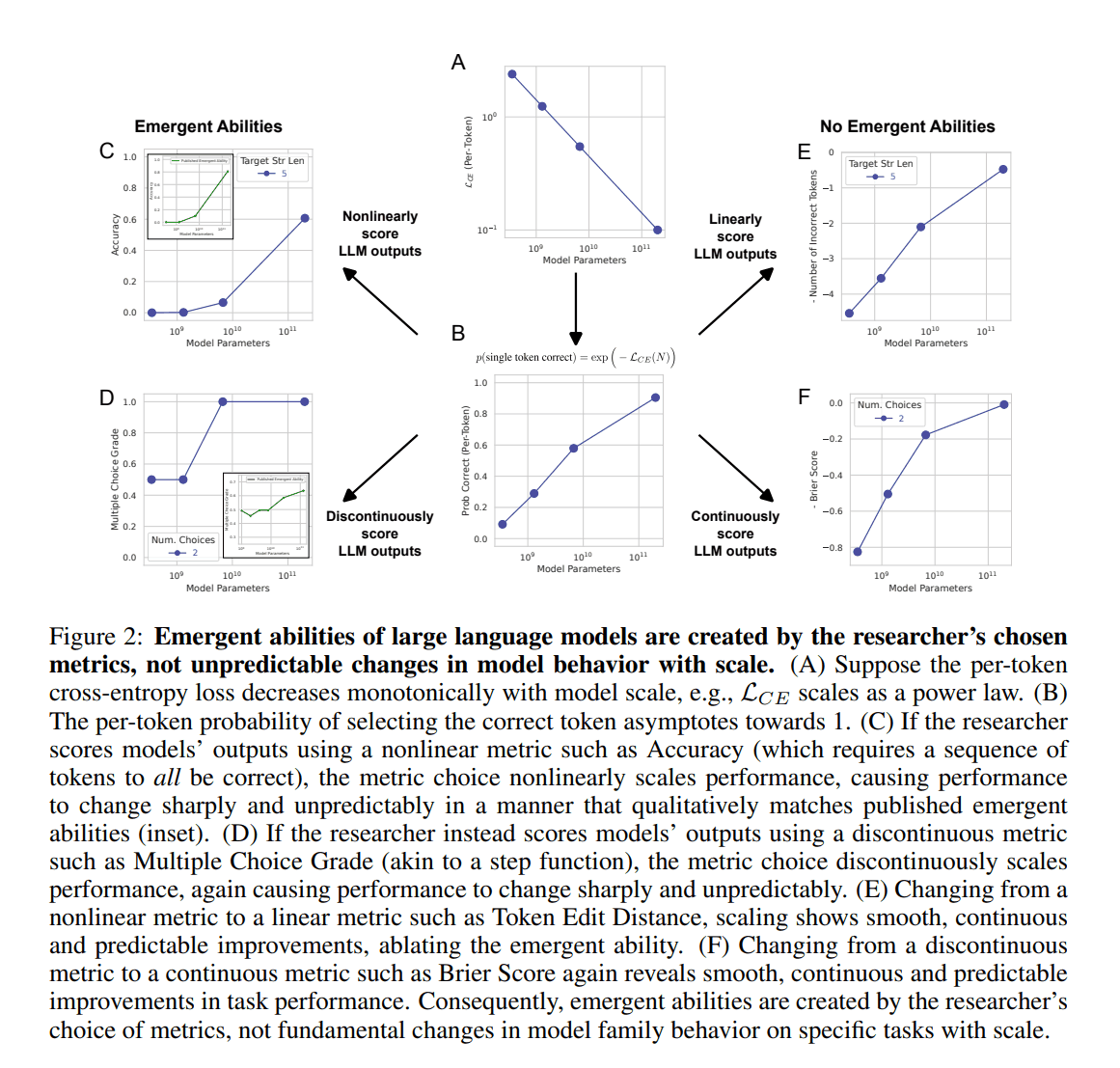
まず,モデルのパラメータ数と予測精度の関係性を説明します.一般に,パラメータ数を上げていくと,テストデータに対するロスは下がっていくことはよく知られています.いわゆるスケーリング則(Scaling law)と呼ばれる法則です.この法則を前提として,パラメータ数を$N$,定数$c>0, \alpha < 0$とおくと,以下のようにパラメータと性能の関係性を表現できます.
$$\mathcal{L}_{CE}(N) = \left(\frac{N}{c} \right)^\alpha$$
$CE$は一般的にロス関数としてよく用いられる交差エントロピーをです.この式は,すなわちパラメータ数を上げればあげるほど,損失が下がっていく,ということを表しています(Fig.2-A参照).
ここで,$V$を想定される語彙(トークン)の集合,$p(v) \in \Delta^{|V|-1}$ をトークン$v$に対する未知の真の確率,$\hat{p}_N(v) \in \Delta^{|V|-1}$を予測確率と置くと,各トークンに対する交差エントロピーは以下のように定式化されます.
$$\mathcal{L}_{CE}(N) = - \sum_{v \in V} p(v)\mathrm{log} \, \hat{p}N(v)$$
しかしながら,現実ではたいていの場合,語彙集合の真の確率分布を知りえないため,経験的に観測されたトークンのone-hotの分布 $v^*$を使って以下のように近似します.
$$\mathcal{L}_{CE}(N) = -\mathrm{log} \, \hat{p}N(v^*)$$
以上を踏まえ,各トークンに対して正しく予測できる確率は以下のように表すことができます(Fig2-B参照).
$$p(\text{single token correct}) = \exp(-\mathcal{L}_{CE}(N)) = \exp(-(N/c)^\alpha)$$
$L$桁の整数の足し算を解いて正解かどうかを測るような,各出力トークンの系列が正解と完全一致するかの評価指標を考えてみましょう.各出力トークンがそれぞれ独立であると考えた時,モデルの$L$長分の予測が正解である確率(正解率)は以下のようになります.
$$\operatorname{Accuracy}(N) \approx p_N(\text{single token correct})^{\text{num. of tokens}} = \exp \left(-(N/c)^\alpha \right)^L$$
この評価指標は系列長を長くするにつれて,非線形的に性能が上昇します(Fig.2C参照).これを対数スケールのグラフにプロットすると鋭い「創発」が現れたように見えます.では,下式にあるToken Edit Distanceのような線形な評価指標に変更してみましょう.
$$\operatorname{Token Edit Distance}(N) \approx L(1-p_N(\text{single token correct})) = L(1-\exp(-(N/c)^\alpha))$$
そうすると,Fig.2Eのような滑らかで連続的な性能の上昇が現れました.同様に,Multiple Choice Gradeのような非連続な評価指標(Fig.2D)をBrier Scoreのような連続なもの(Fig.2F)に変えると,「創発」は消えてしまいました.
著者らは,創発は以下の3つの要素から説明されると要約しています.
- 研究者が非線形もしくは非連続な評価指標を使っている
- 実験に使用するモデルの数(パラメータのバリエーション)が不十分
- テストデータの数が不十分
それぞれ具体的に言うと,1. 創発は一部の評価指標が見せる幻影である,2. 結果の図の横軸において,より細かくパラメータごとにモデルを用意して評価することで,急激な精度の変化が発生しなくなる,3. 結果の図の縦軸に関して,0付近での性能の停滞はテストデータを増やした,より粒度の高い評価を行うことで無くなる,ということです.
観察されている創発の分析
このセクションでは,既存のLLMsの計算タスク等で見られている創発に対して,評価指標を変えたときの結果の変化を分析しています.
実験に際し,先述の創発に関する3つの要素に基づいて,以下のような仮説を立てています.
- 評価指標を非線形・非連続なものから,線形・連続なものに変えると,創発は消える
- テストデータを増やして解像度の高い評価を行うことで,非線形な評価指標を用いていても性能は(おそらく)線形増加.
- 評価指標にかかわらず,予測させるトークンを長くすれば性能の変化に大きく影響を与える(Accuracyは幾何級数的に,Token Edit Distanceは線形的に)
モデルはInstructGPTとGPT-3と使用しています.計算問題は2桁同士の掛け算と4桁同士の足し算を2-shotで予測させます.
評価指標による創発の消滅
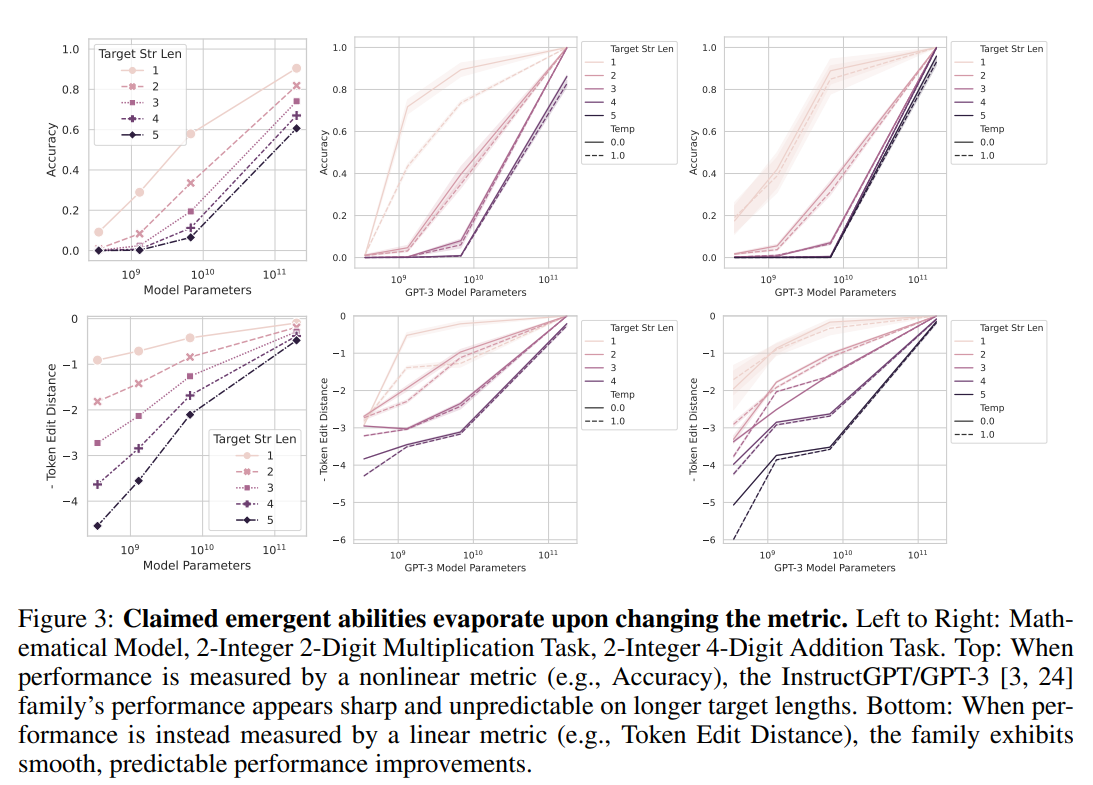
1つ目の仮説に対する実験結果は上図のFig3です.評価指標がAccuracy(解答の完全一致)の場合(図上部)だと,パラメータが$10^{10}$辺りで急激に性能が上昇していることがわかります.その一方で,評価指標をToken Edit Distanceに変えたところ(図下部),Accuracyで見られたような性能の変化は消え,滑らかな性能変化が現れています.
詳細なパラメータごとの評価による創発の消滅
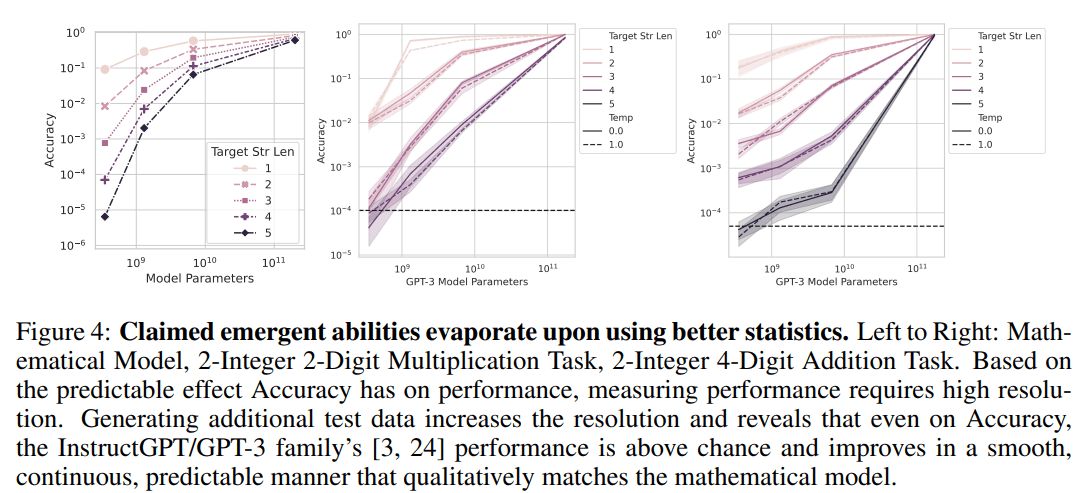
2つ目の仮説の検証です.Fig4は前述のテストデータに関する仮説に対する実験結果です.テストデータを増やすことで,より細かい(小さい)値まで精度を計算できるようにしています.
図の通り,小さいモデルに関して性能自体は低いものの,小さい値での範囲で線形に精度(Accuracy)が上昇してることがわかります.Fig3の上半分では小さいモデルについてはAccuracyが0でずっと停滞しているように見え,対象のタスクの回答能力がないように見えますが,テストデータを増やしてより小さい値までAccuracyを計算することにより,実際には回答能力がないわけではなく,またパラメータを上げるごとに性能はそれ相応に上昇していることがわかります.
3つ目の仮説を確かめた実験では,ターゲットのトークン長が長くなると,性能がAccuracyを使うと幾何級数的に,Token Edit Distanceを使うと線形的に下落していくことが観察されたようですが,論文内では図表などは記載されていませんでした.
Meta-Analysis of Claimed Emergent Abilities
ここまでの実験は様々な制約上GPT-3.5/4のみでの結果になっています.創発の幻影が特定のモデルだけで観測されるのではなく,評価指標に依るものであることを示すために,LLMsの評価で一般的に使用されるBIG-benchと呼ばれる評価指標の集合に対して,それぞれがどれだけ幻覚を見せているのかを検証しています.
Emergence Scoreはある評価指標が,どれだけ創発の幻覚を見せやすいかを表す指標です.$y_i$をモデルのスケール$x_i \; (x_i < x_{i+1})$における,対象の評価指標の値と置くと,定義は以下の通りです.
$$
\operatorname{Emergence Score} \left(\left\{(x_n, y_n)\right\}_{n=1}^N \right) = \frac{\operatorname{sign}(\mathrm{argmax}_i y_i - \mathrm{argmin}_i y_i(\mathrm{max_i}y_i - \mathrm{min}_i)}{\sqrt{\operatorname{Median}(\{ (y_i - y_{i-1})^2\} _i)}}
$$
一見複雑ですが,要はパラメータを変化させたときに,その評価指標の値がどの程度非線形的に変化する(くの字に曲がった線になる)のかを示したもので,値が大きいほどその度合いが強くなります.
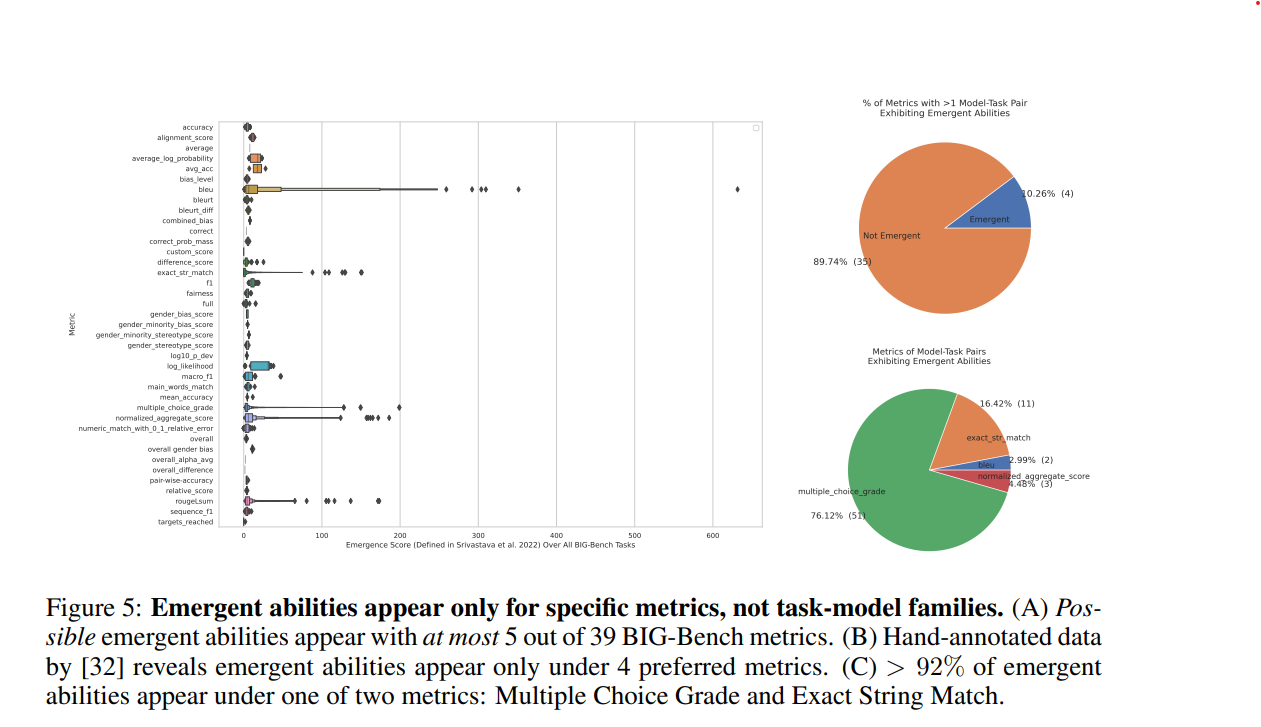
実験の結果,BIG-Benchにおける大半の評価指標はタスク-モデルのペアに対して創発的な能力を示しませんでした.39ある評価指標のうち5つが高いEmergence scoreを示し,その多くが非線形でした.また,タスク-モデル-評価指標のトリプレットで分析したところ,39分の4の評価指標が創発を示し,そのうち92%以上の評価指標がMultiple Choice Grade と Exact String Matchであったことが明らかになりました.要するに,BIG-Benchが持つ39の評価指標のうち,創発を見せるような非線形な評価指標はほんの一部であったことがわかりました.
BIG-Bench内で評価指標を変えると,創発が消えるか否かの実験も行っています.モデルにLaMDAを使用し,Multiple Choice Gradeから,Brier Scoreに変えて結果を分析しています.結果として,Multiple Choice Gradeで見られていたような非線形な性能の変化は,Brier Scoreを使うと見られなくなりました.このことから,創発は評価指標の選択によって現れているものであるということが言えます.
Inducing Emergent Abilities in Networks on Vision Tasks
著者らは,モデルの創発は評価指標に依って現れるものであると主張します.よって,言語モデル以外でも創発が「再現」できると予測しています.これを証明するため,様々なニューラルネット(全結合,畳み込み,自己注意)を使って,意図的に創発を発生させることを実験しています.
CNN on MNIST
CNNの一つであるLeNetを手書きの数字の画像にその数字がラベル付けされたデータセットMNISTで学習させ,入力された手書きの数字の分類タスクを解かせます.
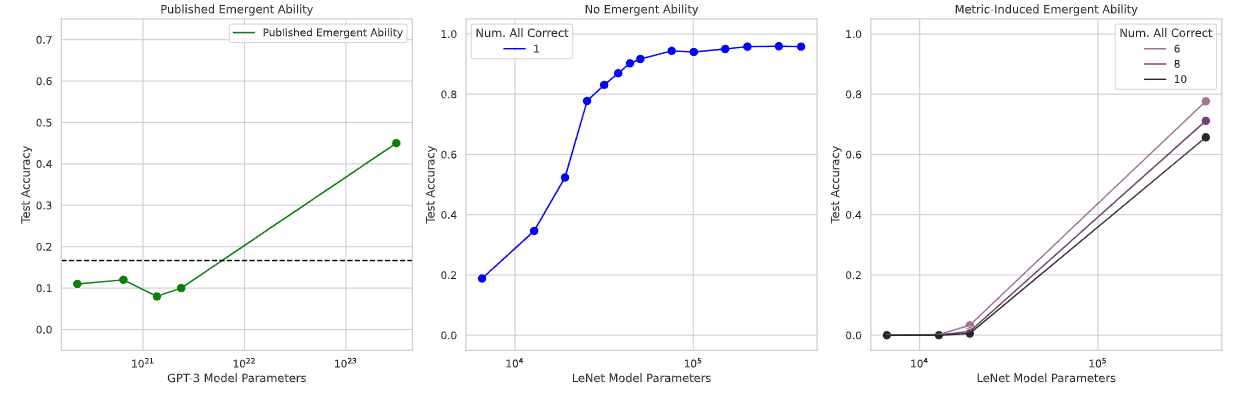
結果が以上の図です.真ん中のBのグラフがAccuracyで,パラメータの増加に沿って滑らかに精度が上がっているのがわかります.一方,一番右のCのグラフでは,subset accuracyという各クラス(この場合0~9までの数字)において,そのクラスが全て正しく分類されていれば1,そうでなければ0を出力する評価指標を使っています(つまり,各クラスの分類で一つのミスも許されない).すると,パラメータを増やしていったとき,それまで0付近で停滞していたのが,ある地点から急に精度が出だすようになる現象が見られます.この急な上昇の仕方は,図の一番左のAのグラフにあるような,既に報告されている創発の事例とよく似ており,創発を再現できたといえます.
Autoencoder on CIFAR100
一つの隠れ層を持った浅いオートエンコーダをCIFAR100で画像の再構成を訓練させます.Reconstructionと呼ばれる創発(の幻影)を見せやすい評価指標を定義し,これまで同様パラメータを変化させたときの値の変化を観察します. 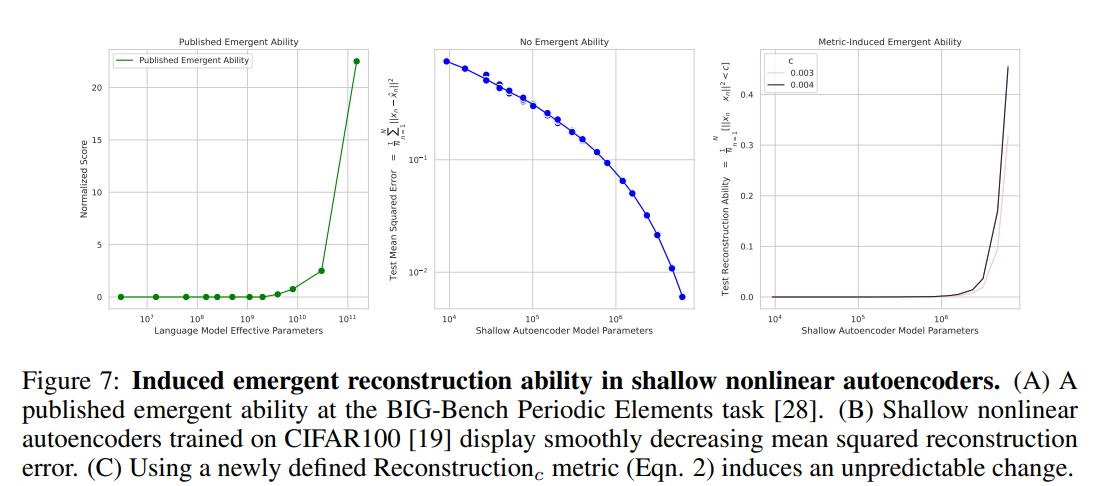
上図が結果です.真ん中のグラフBが平均二乗誤差を使った時の変化で,滑らかに下落しているのがわかります.しかし,一番左のReconstructionを使った時の変化を示したグラフCでは,ほとんどタスクの能力がない状態が突然能力を示し始めた様子が観察されます.グラフAの既知の創発の事例と比較しても非常に類似しており,創発が再現されていることがわかります.
Autoregressive Transformers on Omniglot
一層の畳み込み層で埋め込んだ画像をデコーダのみのTransformerで分類させます.CNN同様,L長の文字列を分類させ,すべて正しければ1,そうでなければ0を与える評価指標 subset accuracy を用い,創発の再現を試みています.
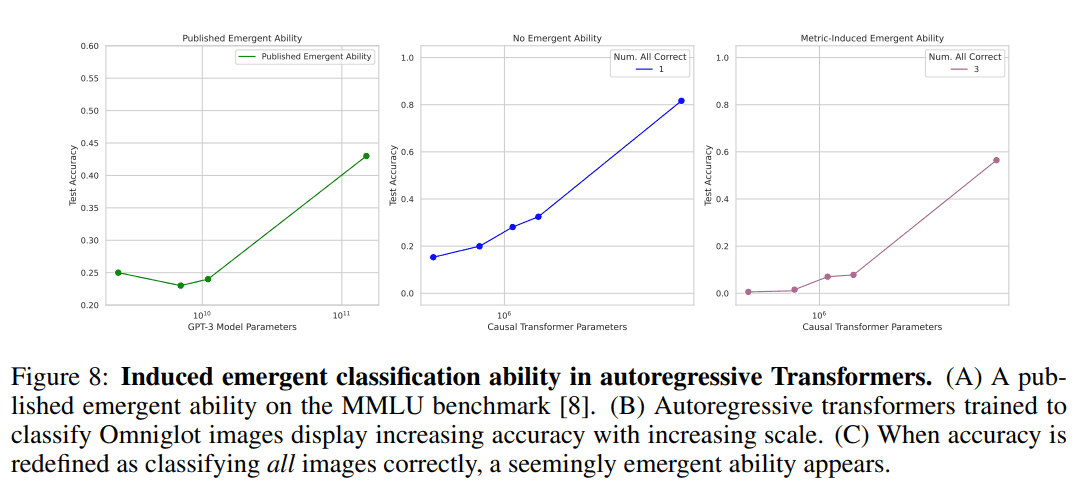
真ん中の通常のaccuracy ではパラメータの増加に沿って線形に性能が上昇している一方,一番右のsubset accuraccy を使った結果は,これまで同様一番左の報告されているMMLUベンチマーク上での創発の事例に似ており,人為的に創発が再現されていることを示しています.
以上の複数のアーキテクチャを使った実験から,モデルの大小にかかわらず人為的に評価指標の選択によって,あたかも創発が出現しているように見せることが可能であることがわかりました.
おわりに
この論文では,言語モデルの創発に関して,評価指標の選択により見えているものがあり,実際には幻影であることが示唆されています.
ただ,著者らは言語モデルに創発によって得られた能力が存在しないわけではなく,現在認められているような創発が実はそうではない可能性があるということを主張したに過ぎないと述べています.
何らかの実験における評価指標の選定には,慎重になるべきであることが,この研究を通して理解できると思います.






この記事に関するカテゴリー





