
LLMに因果推論能力はあるか?
3つの要点
✔️ 大規模言語モデルの因果推論能力をテストするベンチマークデータセットを提案
✔️ 17の既存の大規模言語モデルを評価
✔️ 現状のモデルは因果推論能力が低いことがわかった
Can Large Language Models Infer Causation from Correlation?
written by Zhijing Jin, Jiarui Liu, Zhiheng Lyu, Spencer Poff, Mrinmaya Sachan, Rada Mihalcea, Mona Diab, Bernhard Schölkopf
(Submitted on 9 Jun 2023)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
導入
因果推論能力は,人間の知能の重要な能力の一つです.この能力は,経験的な知識によるものと,純粋な因果推論によるものの二つから成り立っています.
大規模言語モデル(LLM)は膨大な言語データから,用語間の相関関係を捉えることはできますが,そこから,因果関係を抽出することができるかは重要な問いとして残っています.
本論文では,純粋に因果関係を推論する能力をテストするためのデータセットCORR2CAUSEを提案します.
その上で,現状のLLMの能力と,再学習によって成績を向上させられるかを調査します.
データセット
用語の整理
グラフ理論に基づいて因果関係を記述します.例えば,二つの事象(ノード)$X_i$,$X_j$の間の関係性(エッジ)$e_{i,j}$が$X_i \rightarrow X_j$となっている時,$X_i$が$X_j$の直接の原因であることを示します.ここでは,サイクルはないものとします.
その他の用語として,$X_i \rightarrow X_j$の時,$X_i$は$X_j$の親であるといい,逆に$X_j$は$X_i$の子であると言います.また,$X_i$から$X_j$に繋がる有向パスがある時,$X_i$は$X_j$の祖先であるといい,逆に$X_j$は$X_i$の子孫であると言います.
また,3つの要素$X_i, X_j, X_k$について,$X_k$が共通の親$X_i, X_j$(つまり共通の原因)を持つ時,$X_k$はconfounderと呼ばれ,逆に,$X_k$が$X_i, X_j$の子である(つまり共通の結果である)時,$X_k$はcolliderと呼ばれ,$X_i \rightarrow X_k \rightarrow X_j$の時,$X_k$はmediatorと呼ばれます.
タスク設定
$N$個の要素$\mathbf{X}=\{X_1, …, X_N\}$間の相関関係を記述したステートメント$\mathbf{s}$と,その中の要素$X_i$と$X_j$の因果関係について述べた仮説$\mathbf{h}$のペア$(\mathbf{s}, \mathbf{h})$から,その仮説が正しいかどうかを表すラベル$v$を予測するというタスクです.仮説が正しければ$v=1$,誤りであれば$v=0$と予測します.
データセットの作成
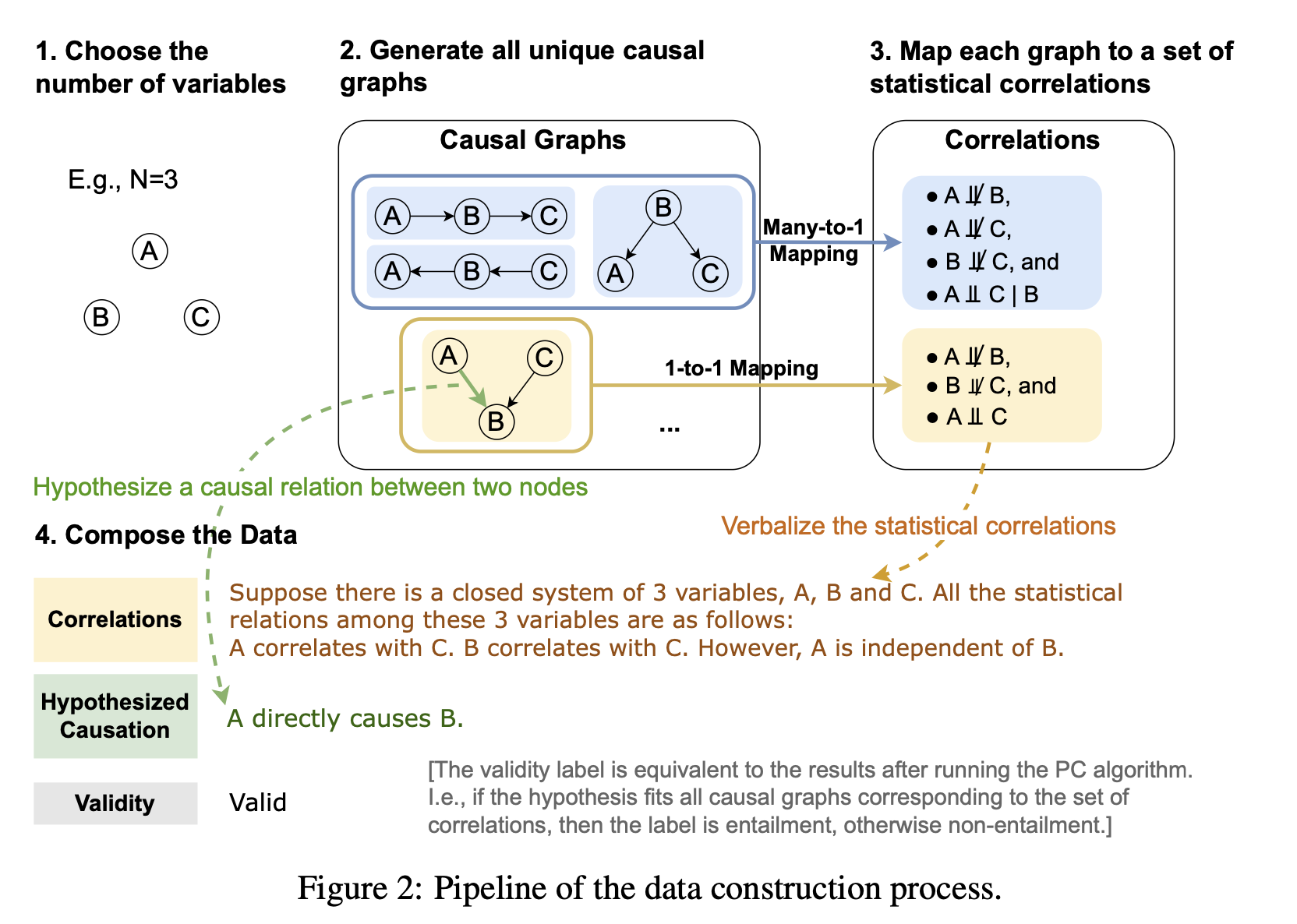
上の図が,データセット作成の概要図です.はじめに,要素(ノード)数$N$を決定し,あり得る関係性(グラフ)を列挙します.その後,各グラフ(関係性)から,要素を二つ取り出し,それらの間の因果関係について,次の6つのパターンで仮説を作ります.
Is-Parent:親かどうか.
Is-Child:子かどうか.
Is-Ancestor:祖先かどうか.ただし,親は除く.
Is-Descendant:子孫かどうか.ただし,子は除く.
Has-Confounder:confounder(共通の原因)があるか
Has-Collider:collider(共通の結果)があるか
そして,仮説が正しければ1を,誤りであれば0をラベルとして付与します.
以上で得られた,関係性(グラフ)と仮説を,以下の表のように自然言語に言い換えます.

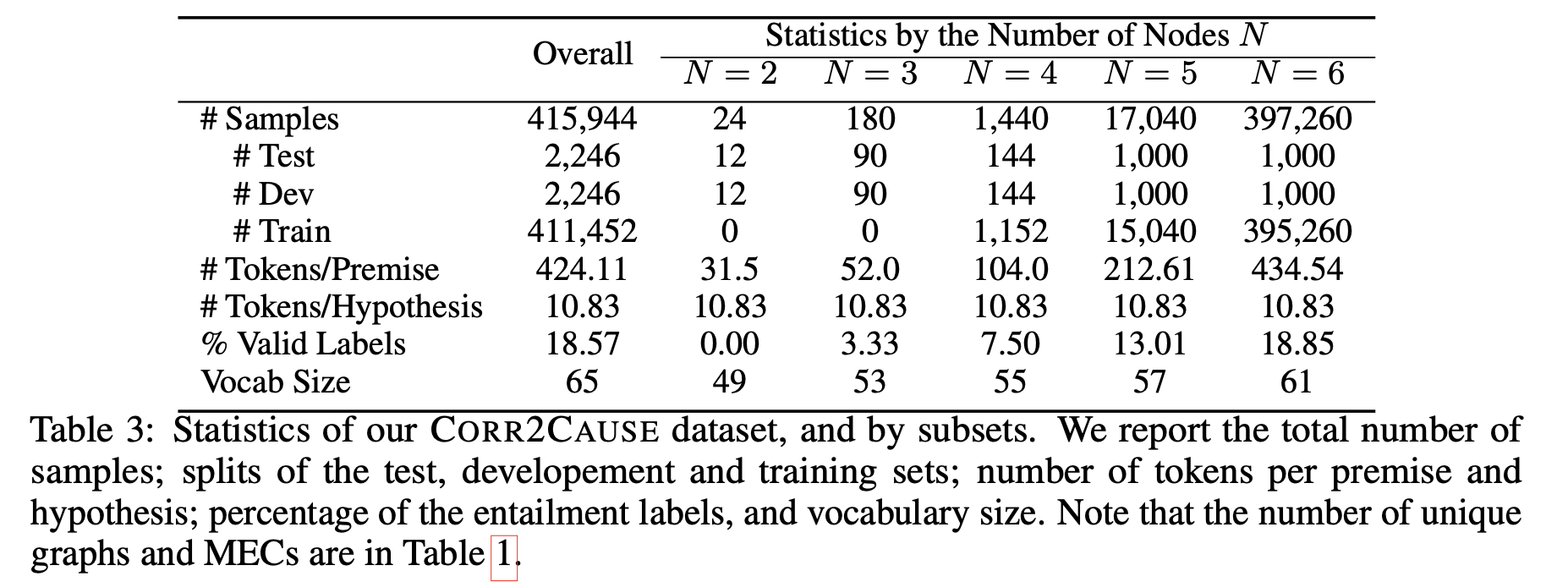
データセットの統計的情報
作成されたデータセットCORR2CAUSEは,合計415944個のサンプルを持ち,そのうちの411452個を訓練用のデータとして使用します.(以下の表を参照)
実験結果
BERT-basedなモデルや,GPT-basedなモデル,LLaMa-basedなモデルを複数用意し,CORR2CAUSEデータセットに対するパフォーマンスを調査しました.
訓練済みのLLMの場合
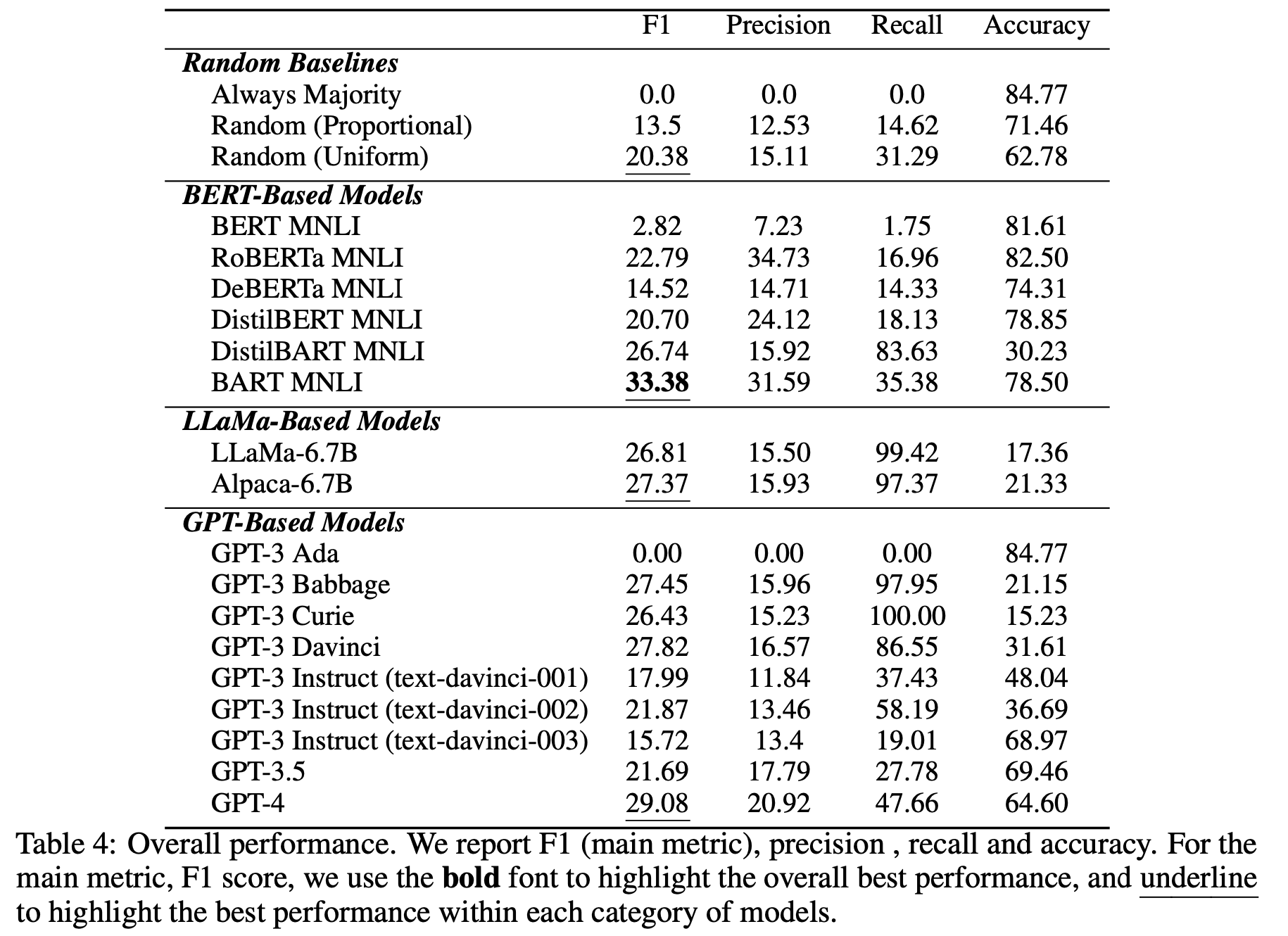
上の表が,公開されている訓練済みLLMのパフォーマンスを示したものになります.どのモデルもCORR2CAUSEのタスクに苦戦しており,最も良いものでも33.38%F1スコアと,低い値となっていました.
Fine-tuningされた場合
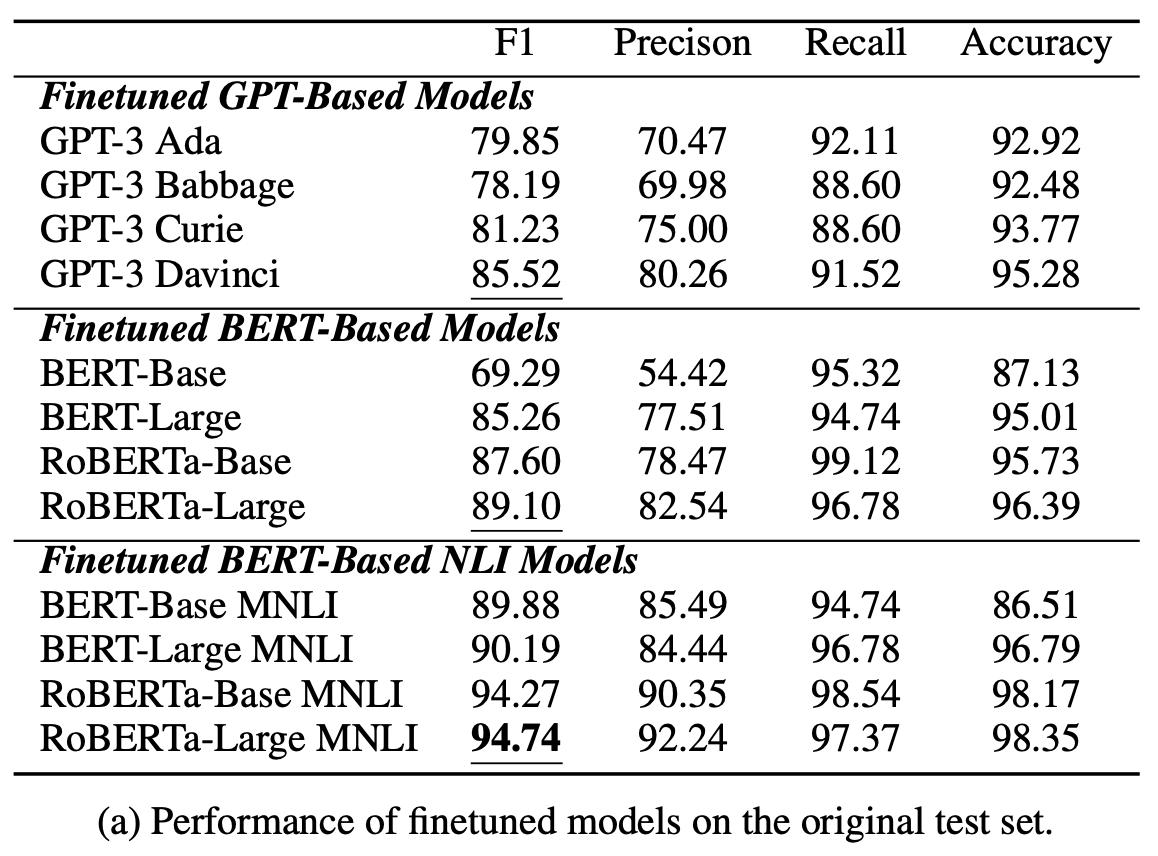
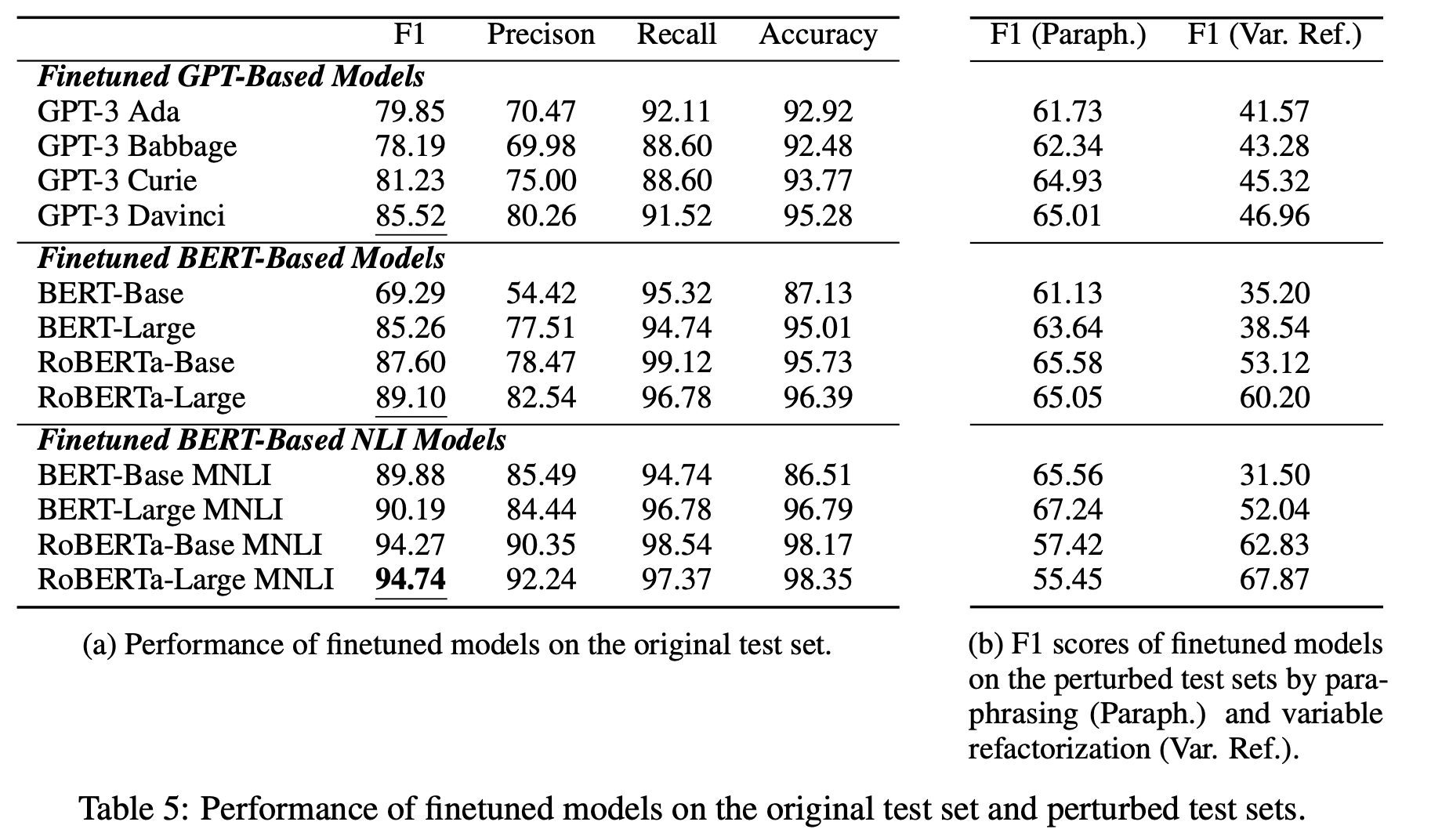
上の表が,CORR2CAUSEデータセットでfine-tuiningされた後のLLMのモデルのパフォーマンスを示したものになります.一見すると,どのモデルもfine-tuningする前に比べて,大幅に性能が向上しているのがわかります.
最も性能が良かったRoBERTa-Large MNLIについて,因果関係のパターンごとに性能を評価したものが下の図になります.Is-Parent, Is-Descendant, Has-Cofounderのパターンに対しては強い一方で,Has-Colliderに対しては若干苦戦しているのがわかります. 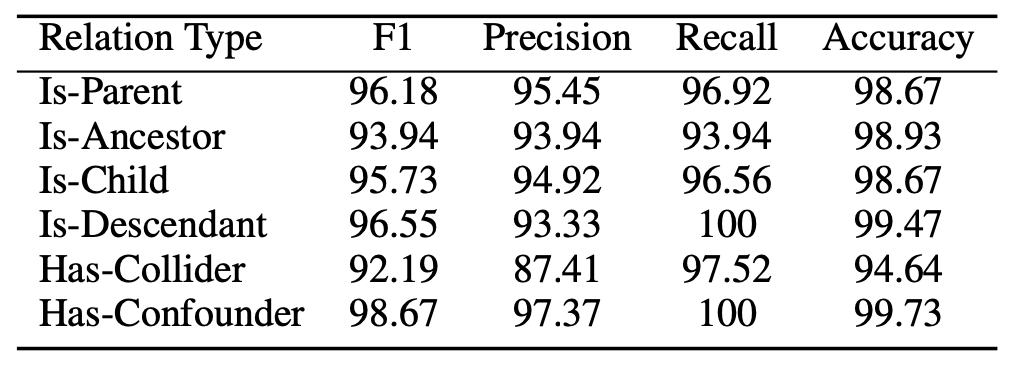
頑健性の調査
fine-tuningによって大きく性能が向上したため,次のような疑問が浮かんできました:モデルはロバストに因果関係を推論することができるのか?この疑問を調査するために,二つの追加実験を行いました.
言い換え:下の図のように,仮説を言い換えて,再度モデルに質問します.
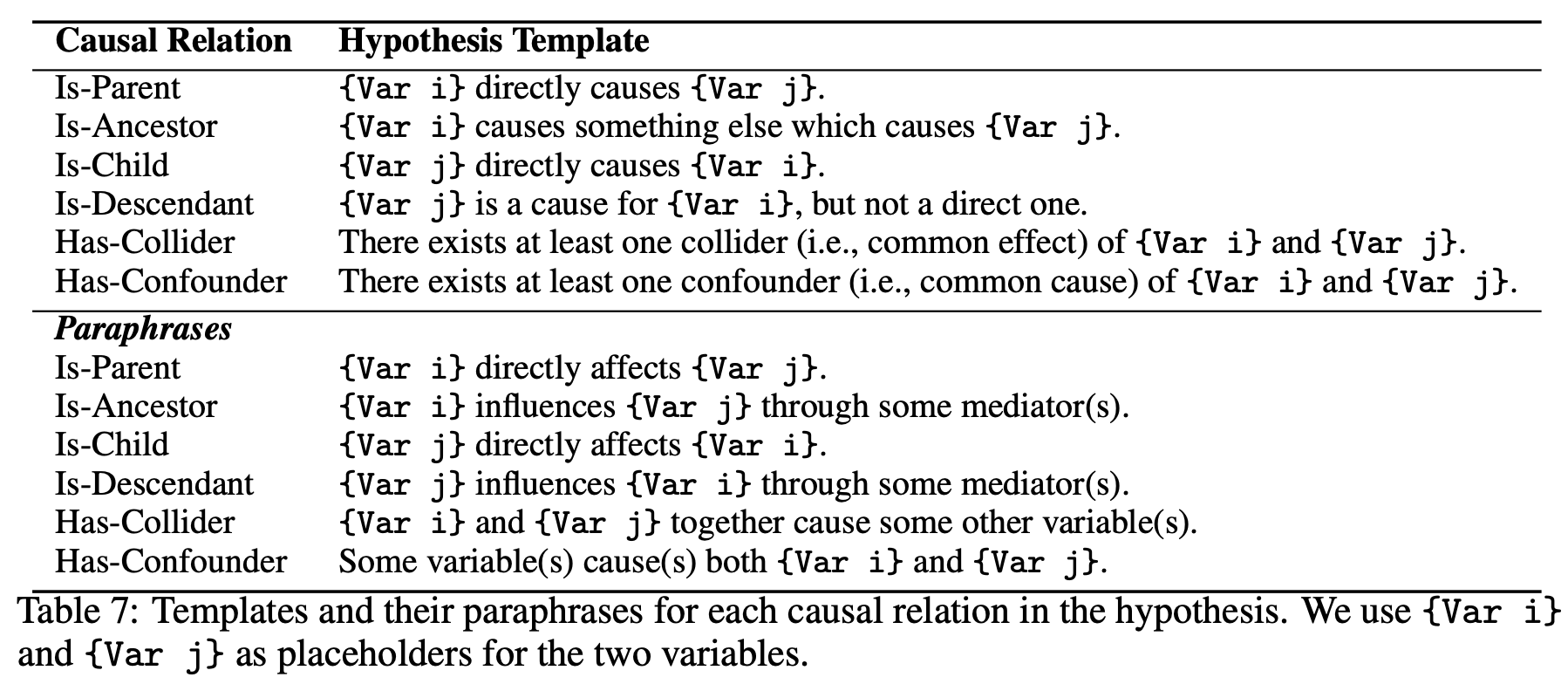
変数の置き換え:使用する変数名のアルファベットを単純にA,B,CからX,Y,Zに置き換えます.
追加実験の結果は次の表の右側(b)の部分になります.言い換えや変数の置き換えをすると,どのモデルもパフォーマンスが大幅に減少することがわかります.学習データの分布外のデータには汎化できていないことがわかります.
議論
本論文では,因果関係の推論能力を調査するためのデータセットCORR2CAUSEを提案しました.このデータセットは40万以上ものサンプルからなる大規模なデータセットです.元のLLMの学習に使われてはいないため,因果推論能力を調査するには適切なデータセットです. 限界として,ノードの数が2から6個と限られている点や,隠れた共通の原因を想定していない点などがあります.
このデータセットを使用した実験により,既存のLLMは因果推論に苦戦することがわかりました.fine-tuningにより性能向上が見られる一方で,少し表現を変えただけで性能が下がる現象も見られるため,今後の研究でより詳細な調査が必要となるでしょう.
まとめ
今回は,LLMの因果推論能力を調査するためのデータセットCORR2CAUSEを提案した論文を紹介しました.現状のLLMはまだ因果推論の性能が低いようです.どのような工夫をすれば,LLMの因果推論能力を向上させることができるでしょうか.引き続き,研究が必要でしょう.






この記事に関するカテゴリー





