
メンタルヘルスケア領域で最も精度がいいLLMはどれか:Mental-LLM
3つの要点
✔️ メンタルヘルスケアにはどのLLMが最も向いているかについて検討した論文
✔️ プロンプトの工夫によりGPTシリーズはその知識空間に十分なメンタルヘルスケアに関する知識を持っている可能性を示唆している
✔️ LLMにおけるファインチューニングに必要なデータ量も明らかにしており,少量のデータを多様性を持って集めることが重要であることを主張している
Mental-LLM: Leveraging Large Language Models for Mental Health Prediction via Online Text Data
written by Xuhai Xu, Bingshen Yao, Yuanzhe Dong, Saadia Gabriel, Hong Yu, James Hendler, Marzyeh Ghassemi, Anind K. Dey, Dakuo Wang
(Submitted on 26 Jul 2023 (v1), last revised 16 Aug 2023 (this version, v2))
Comments: Published on arxiv.
Subjects: Human-Computer Interaction (cs.HC); Computation and Language (cs.CL)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
どんな研究なのか?
メンタルヘルスケアにはどんなLLMが適しているかについて検討した研究で,比較検討されたLLMは以下の5種類です.
- Alpaca-7b
- Alpaca-LoRA
- FLAN-T5-XXL
- GPT-3.5
- GPT-4
この研究の背景として,メンタルヘルスケア領域はビジネスや組織運営のあり方に関する研究で,近年注目を浴びている分野です.しかしながら,メンタルヘルスケア領域でのLLMの性能や実際にどの程度の精度が出るかなどの包括的研究が行われていなかったため,本論文で,包括的なメンタルヘルス領域におけるLLMの可能性を調査しています.
先行研究との違い
論文では,メンタルヘルスケアに関連するLLMの調査・研究が全くなかったわけではなく,いくつかの関連研究を提示しています.しかしながら,そのほとんどの研究が本研究のような包括的なものではなく,研究のほとんどが,単純なプロンプト工学を用いたゼロショット学習であることを指摘しています.
また,この研究の既存研究との違いは,プロンプトによるモデルの性能変化,ファインチューニングに必要なデータ量または注意すべき項目,ユーザーのテキストに対する推論の評価などメンタルヘルス領域におけるLLMの能力を向上させるための様々な技術を包括的に研究し,評価していることです.
本研究の結果
本研究の結果分かったことは大まかに,以下の4点です.
①メンタルヘルスケア領域において,GPT-3,GPT-4はその知識空間の中に十分な知識を蓄えていることを証明しました.
②ファインチューニングを行うことで,異なるデータセット間での複数のメンタルヘルスに特化したタスクにおいてLLMの能力を同時に複数のタスクに対して大幅に向上させることができることを明らかにしました.
③メンタルヘルスの予測タスクのためのオープンなファインチューニング済みのLLMを提供しました
④今後,メンタルヘルスケア領域における研究のためのLLM向けデータセット作成のために必要な量や質などの枠組みを提供しました.
①・②について
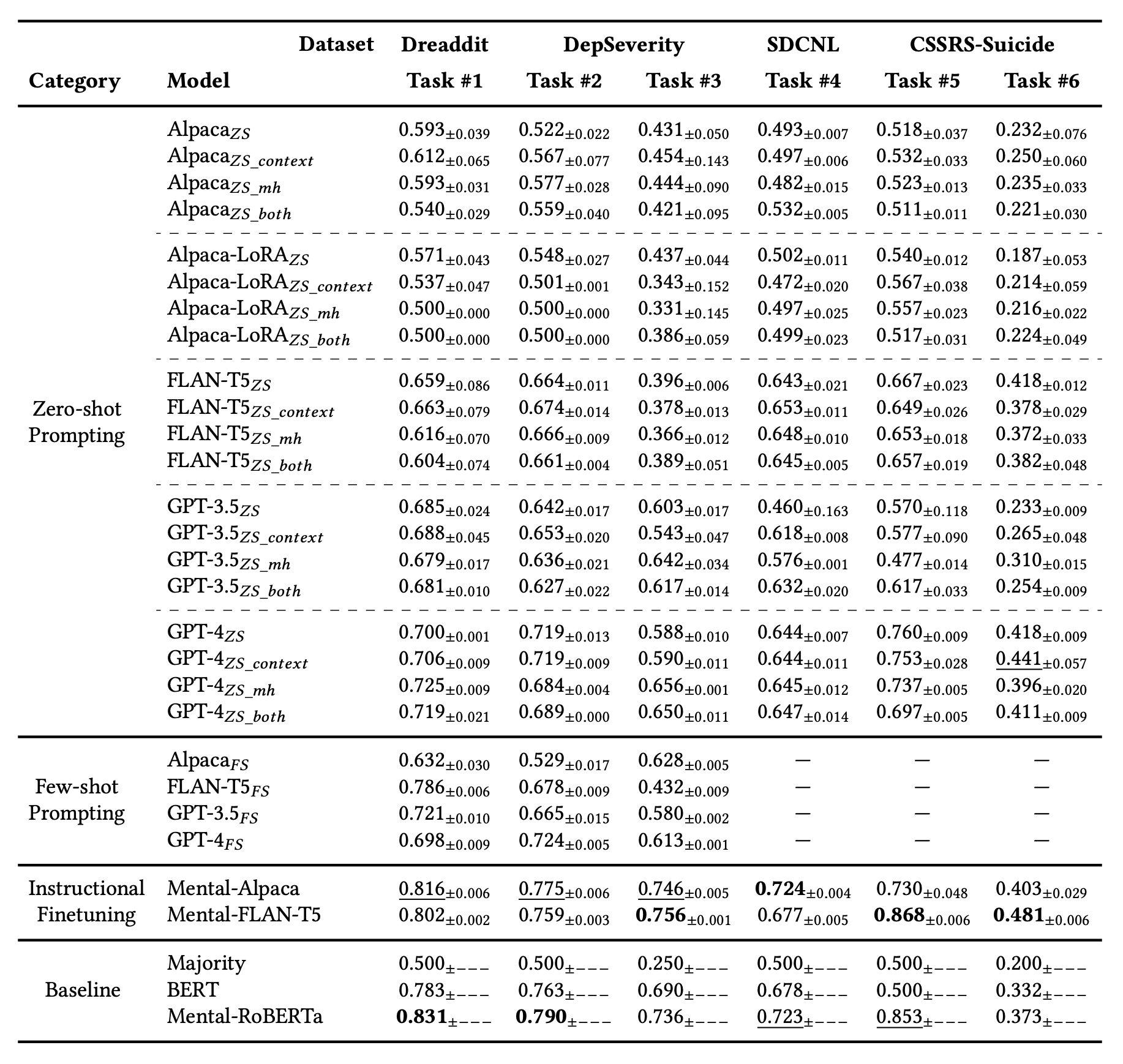
以下の表では,各モデルの結果を表しており,上段からゼロショット学習,ゼロショット学習+設問よりも多いコンテキストとの追加,ゼロショット学習+役割をLLMに与える,ゼロショット学習+設問よりも多いコンテキストとの追加+役割をLLMに与えるの結果を示しています.
その下は,Few-shotラーニングでいくつかのサンプルを提示し,回答を得るものです.
これらの結果より,TASK#1で最も性能が高いものは,驚くべきことに既存のBERTモデルのMental-RoBERTaです.他のタスクにおいてもファインチューニングを行ったモデルが既存のGPTよりも高性能であることが示されています.GPTの中で比較するとゼロショットとFew-shotの間に大きな違いは見られないことからGPTシリーズの持っている知識空間の中にメンタルヘルスに関する知識が十分に入っているということが示されました.
他には,AlpacaとFLAN-T5のファインチューニングの前後を比較すると,ファインチューニング前では,AlpacaとFLAN-T5では圧倒的にFLAN-T5の方が性能がいいことが示されています.しかしながら,ファインチューニング後を見ると,Alpacaの方が性能がFLAN-T5に追いついていることがわかります.この結果から,FLAN-T5のような初期のネットワークは,LLMベースのネットワークに対して,自然言語への理解が劣っていることが考えられます.その結果,ファインチューニングの過程でAlpacaの方がファインチューニングのデータからより多くの情報を吸収しFLAN-T5の結果へ近づいたのではないかということを本研究では主張しています.
④について
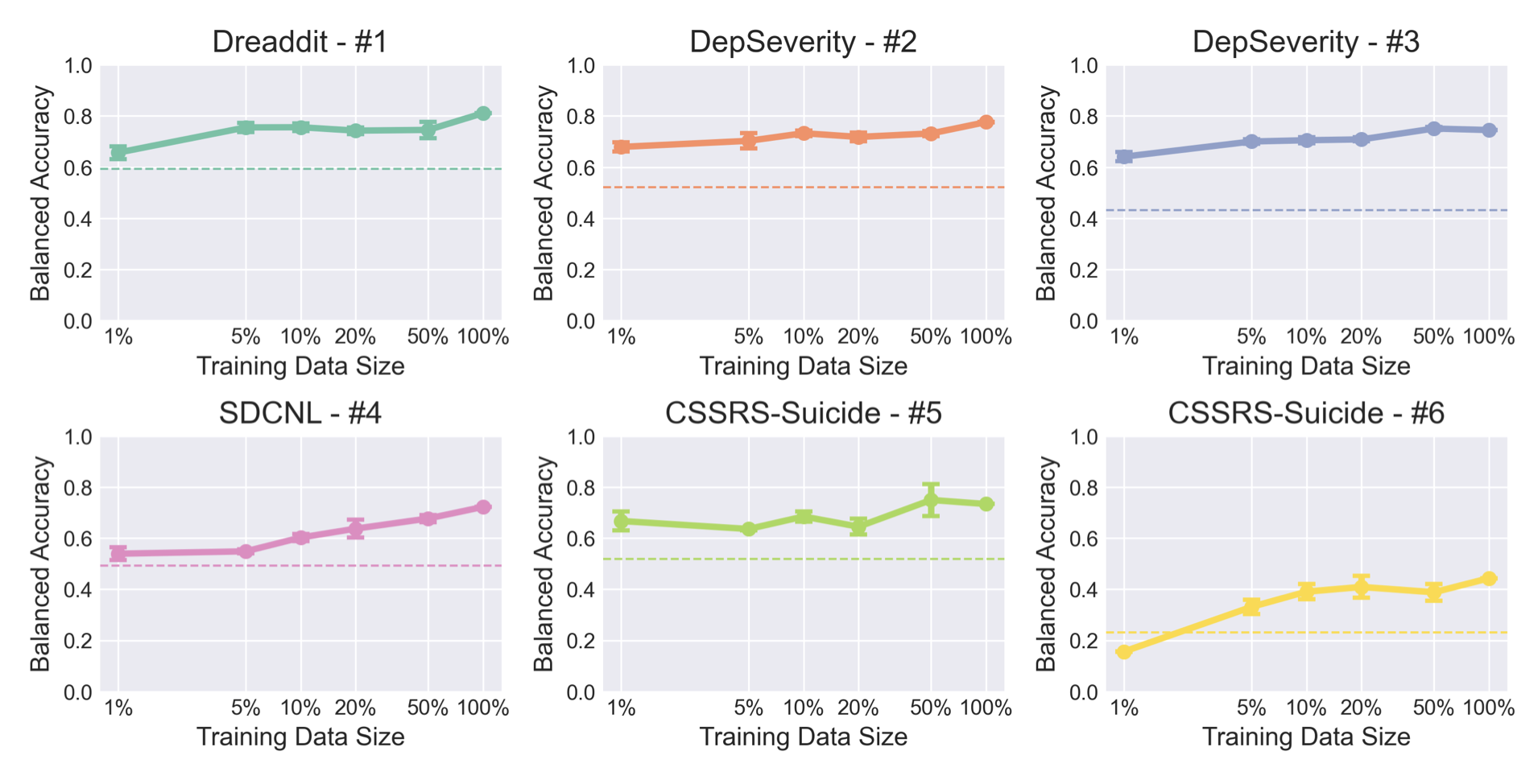
下の図は論文中のFig1ですが,訓練セットを変更した場合の③で紹介したように公開されているMental-Alpacaの精度の推移です.この結果からわかることとして,ファインチューニングを行った後はベースモデルに対して基本的には精度向上が示されます.さらに,必ずしもデータセットの大きさが制度に直結するわけではないということもわかります.このことから,LLMにおけるファインチューニングのデータセットは量的な問題よりも質と多様性が重要であることがわかります.
実験の詳細
プロンプトに関してですが,コンテキストを入れない,類似の情報をコンテキストに含める,モデルに専門家としての役割を与えるの3パターンと後半二つの組み合わせの計4パターンで実験し,文章からメンタル状態のラベルを予想するタスクを解き性能を比較する実験を行っています.
この結果,先ほども紹介したように,プロンプトの情報の有無にかかわらず,GPTシリーズは良好な結果を示し,知識空間に基本情報としてメンタルケアに関する知識が埋め込まれているものと判断しています.
それぞれのプロンプトの設計はゼロショット,Few-Shotそれぞれ下記のように示されています.
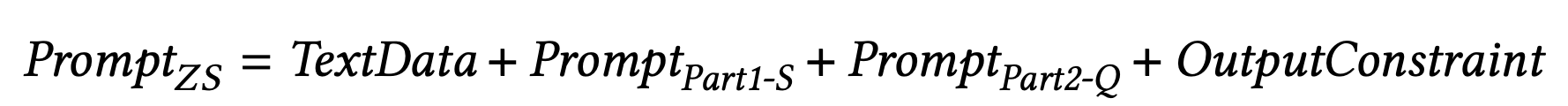
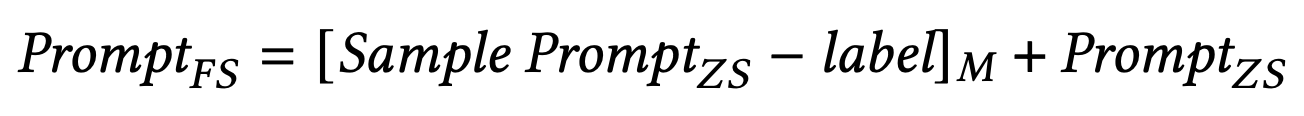
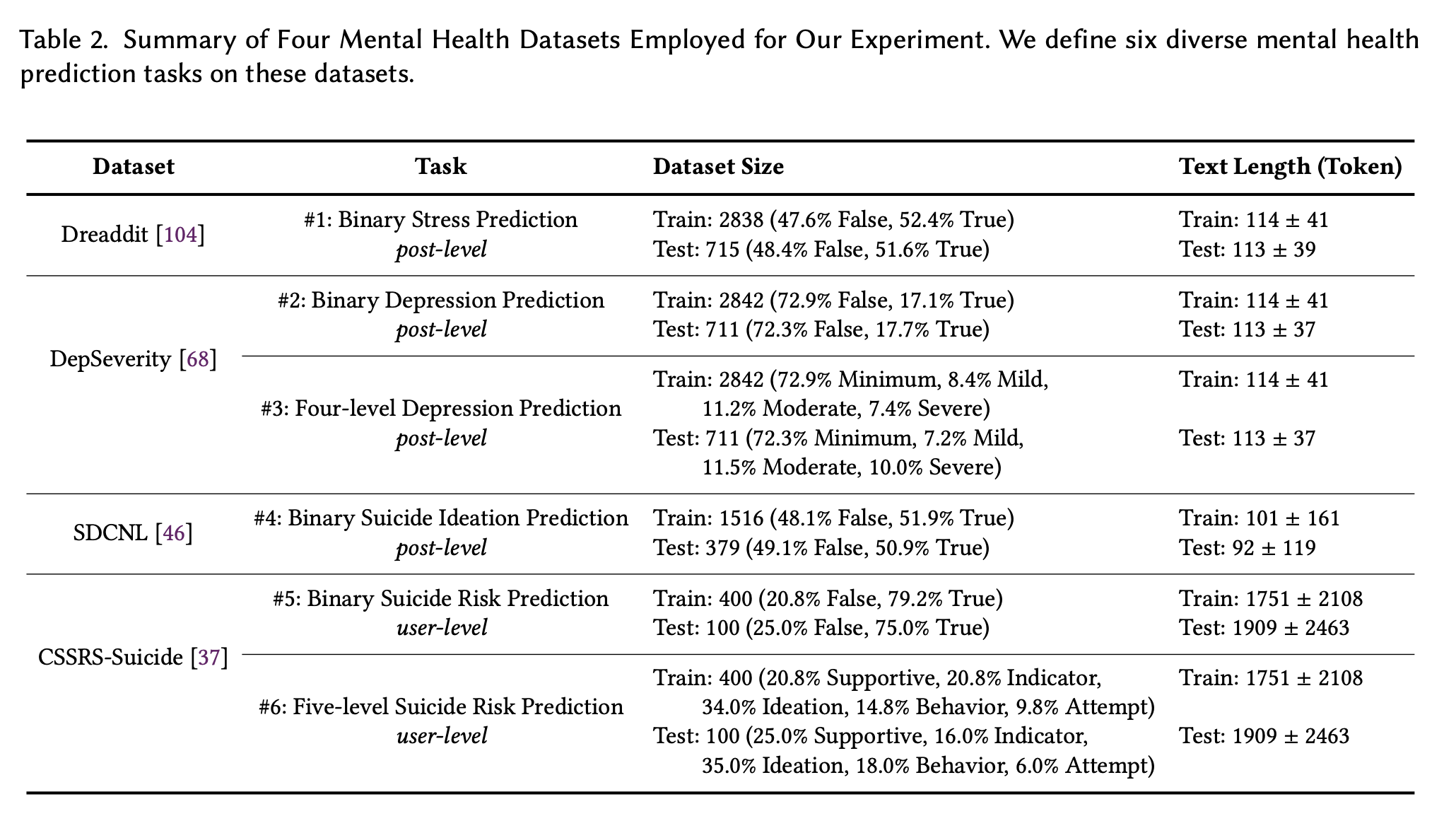
次に,実験に用いたデータセットですが,Dreaddit,DepSeverity,SDCNL,CSSRS-Suicideです.それぞれのデータセットを簡単に下記に紹介します.
Dreaddit
DreadditデータセットはReddit(米国でよく使われているSNS)から投稿を収集したもので,5つの領域(虐待,社交界,不安,PTSD.金融)の10のサブRedditが含まれています.複数の人間のアノテーターが,文節が投稿者のストレスを示しているかどうかを評価し,アノテーションを集約して最終的なラベルを生成したものです.このデータセットを,ポストレベルのバイナリストレス予測(タスク1)に使用しています.
DepSeverity
DepSeverityデータセットは,Dreadditで収集されたのと同じ投稿を活用していますが,うつ病に焦点を当てた点が異なります.2人の人間のアノテーターがDSM-5に従って,投稿を4つのうつ病のレベル:最小,軽度,中度,重度に分類しています.このデータセットを2つの投稿レベルタスクに採用しています.①バイナリうつ病予測(すなわち,投稿が少なくとも軽度のうつ病を示すかどうか,タスク2)②4レベルうつ病予測(タスク3).
SDCNL
SDCNLデータセットも,r/SuicideWatchやr/Depressionを含むRedditから投稿を収集したものです.手作業によるアノテーションを通じて,各投稿が自殺願望を示しているかどうかをラベル付けています.このデータセットを投稿レベルのバイナリ自殺念慮予測(タスク4)に採用しています.
CSSRS-Suicide
CSSRS-Suicideデータセットには15のメンタルヘルス関連サブレディットの投稿が含まれます.4人の現役精神科医がColumbia Suicide Severity Rating Scale (C-SSRS)のガイドラインに従い,500人のユーザーを5つのレベル:支持、指標、イデア、行動、未遂の自殺リスクについて手動でアノテーションを行いました.このデータセットを2つのユーザーレベルのタスクに活用しています:バイナリ自殺リスク予測(すなわち、ユーザーが少なくとも自殺指標を示したかどうか、タスク5)と5レベルの自殺リスク予測(タスク6)です.
また,訓練データとテストデータの分割比率とそのデータ数は下記の画像のとおりです.
これらの結果は先ほど紹介したとおりです.
まとめ
ファインチューニングのためのデータと計算資源が利用できない場合,タスク解決に焦点を当てたLLMを使用することで,より良い結果が得られる可能性があります.十分なデータと計算資源がある場合は,対話ベースのモデルを微調整する方が良い選択となることが示されています.
一方,Alpacaのようなモデルは対話会話機能を備えており、エンドユーザー向けの精神的な健康支援など,下流のアプリケーションにより適合する可能性があることも指摘されています.
今後の課題として,以下の2点が指摘されています.
- 実用化に近づけるためには,より多くのケーススタディを行う必要がある.
- 複数のデータセット,より多いLLMでの検証が必要である






この記事に関するカテゴリー





