苦い教訓 — 強化学習の父からの教え
これは2019年3月13日に強化学習の生みの親と言われているRich Sutton氏が公開した記事を元に作成した解説記事です。過去の強化学習、深層学習の研究を通じて次世代の方法論となるヒントが示されています。
苦い教訓:人間のドメイン知識は有効ではない
70年にわたるAI研究から得られる最大の教訓は、膨大な計算力を活用する”汎用的な方法”が最終的には最も効果的であり、大きな差を生むということです。根本的な理由は計算コストが継続して指数関数的に低下することにあります。(ムーアの法則[2])今までのAI研究は、エージェント[3]が利用できる計算資源が一定であるかのように行われてきました(つまりこの場合、人間の”ドメイン知識[4]”を活用することがパフォーマンスを向上させる唯一の方法の1つになります)。
しかし、長く研究している中で、近年、膨大な計算資源が利用可能になりました。
短期間内での成果を求めて、研究者はドメインに関する人間の知識を活用しようとしてきましたが、長期的に重要なことはその計算リソースの活用です。これら2つは互いに対抗する必要はありませんが、実際には相反する傾向があります。そして、人間のドメイン知識を利用したアプローチは、”汎用的な方法”にはあまり適さず、方法を複雑にする傾向があります。 AIの研究者がこの苦い教訓を経験した例はたくさんありましたが、著名なものをいくつか振り返っていきます。
[2] ムーアの法則: インテル創業者の一人であるゴードン・ムーアが、1965年に自らの論文上で唱えた「半導体の集積率は18か月で2倍になる」という半導体業界の経験則。これより計算機の小型化、計算の高速化、電子デバイスの大衆化などの恩恵が得られ、現代の情報革命の基盤となっている。しかし、近年、トランジスタが原子レベルにまで小さくなり法則が限界に達するとの見方もある。
[3] エージェント: 強化学習のフレームワークの中で、行動選択をし環境から報酬をもらうプレーヤーのこと。
[4] ドメイン知識: 解析しようとしている業界や事業についての知識や知見、トレンドなどの情報。情報の分野ではあるタスクに固有な知識のことを指します。例えば、将棋では人間のドメイン知識は居飛車穴熊や金矢倉などの戦法のことを言います。しかし、AlphaGo Zeroはそのような人間が経験的に培った戦術やプロ棋士の棋譜などを学習せずに、世界チャンピオンを倒しました。
具体例1: チェス
コンピュータのチェスでは、1997年に世界チャンピオンのKasparovを破った手法は、大規模で深い探索に基づいていました。しかし、当時、この方法はチェスの特別な構造についての人間の知識を活用した方法を追求してきた大多数の研究者には幻滅されていました。特別なハードウェアとソフトウェアを使用した、より単純な探索アプローチがはるかに有効であることが判明したとき、人間知識を利用する多くのチェス研究者たちは「愚直で力任せな探索は今回に限り勝ったのみにすぎない」と負けを認めませんでした。
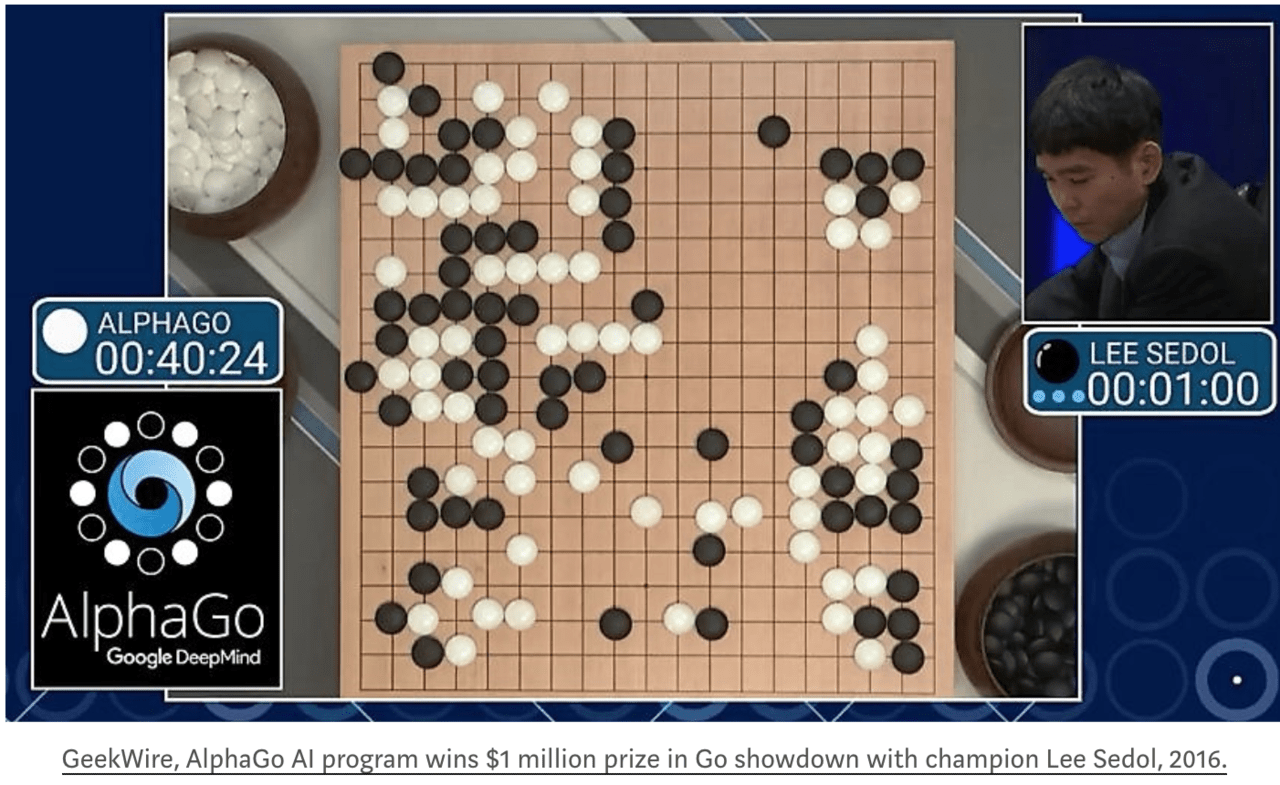
具体例2: 囲碁
チェスからさらに20年遅れ、同様のパターンの研究の進歩がコンピュータ囲碁でも見られました。人間の知識やゲームの特別な機能を利用して探索量を削減するために、多大な初期の努力が払われてきましたが、いったん探索が大規模かつ効果的に適用されると、これらの努力すべては無意味な、または悪化させていることが証明されました[5]。
チェスをはじめとする他の多くのゲームでもそうだったように、価値関数[6]の学習ために自己対戦[7]を使用することも重要でした。自己対戦による学習や一般的な学習手法は、大量の計算を必要とするという点で探索と似ています。”探索”と”学習”は、AI研究で大量の計算力を最大限活用するための2つの最も重要な概念です。このようにコンピューター囲碁においても、初期の研究、探索が少なくて済むように、人間のドメイン知識を利用することが一般的で、”探索”と”学習”を取り入れることによって成功したのは後のことです。
[5] 実際に、人間のドメイン知識を利用しないAlphaGo Zeroはプロの棋譜を学習したAlphaGoより強くなるという事実があります。
[6] 価値関数: 現在の盤面から勝率を計算する関数。棋士の大局観にあたるもの。古くから人間の手作業で盤面評価関数を設計していましたが、ニューラルネットで計算することでその手間が省けるとともに、はるかに精度が向上しました。
[7] 深層学習は学習に膨大なデータを必要とするが、一つのエージェントによる自己対戦によって、対戦データを生成し、価値関数の教師データとして利用しました。
具体例3: 音声認識
音声認識では、1970年代にDARPA[8]が後援し、初期の競争が始まりました。参加者には、人間の知識、すなわち単語、音素、人間の声道などの知識を利用した多数の特別な方法が含まれていました。一方で、より統計的でより計算を必要とする新しい方法も生まれました。これらは隠れマルコフモデル(HMM)[9]に基づいています。やはり、統計的方法は人間の知識に基づく方法を上回る結果となりました。つまり、統計と計算がこの分野を支配するようになったことを意味し、何十年にもわたって自然言語処理の全体に大きな変化をもたらしました。
音声認識における最近の深層学習の台頭は、この一貫した方向性における成果です。ディープラーニングは、人間の知識に頼ることがさらに少なく、非常に優れた音声認識システムを生み出すために、巨大な教師データで学習をし、さらに多くの計算リソースを使用します。多くの研究者は自分の頭脳に近いように働くシステムを作ろうとしましたが、大規模な計算が可能になりそれを有効に利用するための手段が見つかったときには、人間のドメイン知識に頼ることは逆効果であることが分かりました。
[8] DARPA: Defense Advanced Research Projects Agencyの略。国防高等研究計画局。先端軍事技術研究プロジェクトを指導する米国国防総省の機関。初期から積極的な投資を行い、電話会話音声認識のためのベンチマーク・データ「Switchboardデータセット」を作成しました。世界中の研究機関はこのデータを用いることで、研究技術を定量化した上で競争することができるようになりました。
[9] 隠れマルコフモデル(HMM): 確率モデルのひとつであり、観測されない隠れ状態をもつマルコフ過程です。自然言語処理や音声認識で前提とされるフレームワーク。人間の発話の中の音素や文章中の単語は、現在の状態のみが将来の状態に影響し、直接観測できない特徴量をHMMでモデル化した。
具体例4: コンピュータビジョン
コンピュータビジョンでも、似たようなパターンがあります。初期の方法は、エッジ、一般化円筒[10]を検出することやSIFT特徴[11]の観点から人間の知覚を捉えました。しかし、今日ではこれらは広くは使われいません。現代のディープラーニングのニューラルネットワークは、畳み込みとある種の不変性の概念のみを使用し、はるかに優れた性能を発揮します。
[10] 一般化円筒(Generalized Cylinder): Biederman は円筒や直方体、くさび型などのような単純な凸型の幾何学的立体の組み合わせと、それらの空間的位置関係で多くの物体の形が記述できると考えた。この考えに基づき、コンピュータビジョンでは一般化円筒の検出もパターン認識には重要だと考えられていました。
[11] SIFT(Scale-Invariant Feature Transform) : 1999年にDavid Loweによって発表された特徴点検出・特徴量記述を行うアルゴリズム。回転・スケール・照明変化等に対してロバストな特徴量を記述できるのが大きな特徴です。
さらなる洞察
これらの過去の考察から大きな教訓を得れます。私たちは同じ種類の誤りを犯し続けているのですが、まだそれを徹底的には学べていません。これを認識し、効果的に阻止するためには、過ちの魅力を理解する必要があります。私たちが思考していると考える方法でAIを構築することは、長期的にはうまくいかないという苦い教訓を学ばなければなりません。
苦い教訓は、歴史的観察に基づいています。
1)AI研究者はしばしばエージェントに知識を組み込もうとしました。
2)これは短期間で役立つもので、研究者にとって個人的に満足のいくものであります。
3)しかし、長期的にはそれはさらなる進歩を頭打ちにするか、妨げる可能性があるものです。
4)画期的な進歩は、最終的には”探索”と”学習”によるスケールする計算に基づくアプローチによって達成されます。最終的な成功は苦味を帯びており、しばしば不完全消化を起こすものです。なぜなら、それは我々の好きな人間中心のアプローチよりも成功しているからです。

新しい方法論への展望
苦い教訓から学ばなければならないことの1つは、利用可能な計算資源が非常に大きくなるにつれて、拡大し続ける手法の中でも”汎用的な手法”が大きな力をもつということです。このように任意に拡大も縮小もできると思われる2つの方法は、”探索”と”学習”です。
2つ目の教訓から学ぶべき点は、実際の脳のシステムは非常に巨大で、取り返しのつかないほど複雑であるということです。私たちは、空間、物体、複数のエージェント、対称性などについて考えるときもそうですが、脳の仕組みについて考える単純な方法を探すのをやめるべきです。
これらはすべて、恣意的で本質的に複雑な外界の一部です。それらの複雑さは際限なく続くもので組み込まれるべきものではありません。代わりに、この任意の複雑さを見つけて捉えることができるメタメソッドのみを組み込むべきです。これらの方法に欠かせないのは、良い近似値を見つけること[12]ができるということですが、それらの探索は我々の知識によるものではなく、我々の方法によるべきです。我々がAIエージェントに望むことは、人間が発見したものを含まず、できる限り自分で発見できることです。人間の発見を取り込むことは、発見プロセスがどのように行われるかを理解することを難しくするだけです。
[12] ニューラルネットは浅くとも万能近似能力を持つことが示されています。コンピュータにパラメータ調整の幅を持たすことにより、任意の関数を表現できます。ここでは、近似する方法について言及していますが、これはニューラルネットを利用する手法のことです。
個人的見解 1 — 苦味の正体
苦味とは「人間の知識を利用しない」「AIが人間を超える」という点から来るものと考えます。AIといえばターミネーターが支配する世界を想像しがちであり、論理を疎かにし技術的な理解を怠り、SFの世界に流されしまうのは悲しいことです。西洋の価値観は縦型であり、最上位に神が君臨し、その下に人間、そして機械へと続きます。この枠組みでは機械が人間に歯向い反乱を起こすことが想定されることも理解できます。しかし、日本、東洋的思想では、多神教を許容し、どの神が上位だという話にもなりません。いわば横型の構造を古来より持ちます。ドラえもんがのび太に反乱しないように、ここでは人間と機械が対峙するのはなく、共存する世界が描けるのではないでしょうか。AI vs Humanではなく、AI x Humanであり、ホモ・サピエンスでなく、ホモ・サイバネティカス[13]へと移行すべきではないのでしょうか。
[13] ホモ・サイバネティカス: 暦本 純一が提唱するホモ・サピエンスの次の人類の呼称。人間と機械が融合することにより、身体・知覚・認知・存在を拡張する。
写真の原理による初期の投影像であるカメラ・オブスキュラの登場は、肖像画家の職を奪うと思われていましたが、むしろカメラを利用し自身の絵画における遠近法や透視図法の精度を高めた画家がいましたし、写実的でなく人間の感性に注目し描く印象派が、今日でも圧倒的人気を得ているもの事実です。産業革命時期のラッダイト運動で職人の反乱が起きましたが、今でも産業革命以前に戻ることを切望している人は少ないでしょう。2016年に策定されたアメリカの国家科学技術会議の人工知能研究開発戦略でも、第二項目の目標に「人間とAIの効果的な強調手段の開発」を掲げています。チェスなどのゲームにおいても、KasparovはCyber Chessと言われる人間とコンピュータが協力して戦う競技を提案しています。両者の共生チームは、コンピュータ、人間単体よりも強いことがわかっています。世界中の棋士はコンピュータ将棋を利用して自己の訓練をしています。このようにAIを前提として、人間の能力拡張や訓練を考えると、その苦味がむしろ心地良いように感じるのではないでしょうか。

個人的見解2 — 探索と学習
Sutton氏の述べるように、探索と学習は非常に重要な概念であると考えます。まず、探索については「探索と搾取のジレンマ」というものが知られています。新しいものの価値を推定するとき、実際にその行動を選択して経験してみないことにはその価値は知り得ません。一方で、現在の報酬を最大化するには今知っている情報の中で最善の行動をすべきです。これらは一般に相反するものです。もし、あなたが駄菓子屋でアイスキャンディを買うとき、企業である業種に新規参入を考えているとき、あるいは、人生において大きな意思決定を考えている時など、いかなる場面においても、リスクをとって探索するか、安全に保険を掛けるのか選択に迫られます。AIエージェントがこの岐路に立たされた時、人間の認知バイアスを含む知識をあてにするのではなく、”汎用的な手法”に基づいて行動選択する方が優れた成果を得ることができます。自分に置き換えると、ただ他の人のアドバイスを聞くのも、自分を盲目的に信じるのもナンセンスに感じます。自分の探索空間を見極め、取りうる行動を列挙し、合理的に行動することがエッセンスとして得ることができます。学習についても、神経科学的にfMRIで脳の活性部位を調べると、人間の中に行動を選択する部分と、それを評価する部分が分かれて働いていることがわかるようです。学習のフィードバックサイクルも我々が生来より行なっている機能です。この探索と学習はもちろん大切ですが、実行するために膨大な計算を要するため、実際の問題解決では困難がありました。しかし、そのデスバレーをムーアの法則で突破した現在では、さらに探索と学習の概念の重要性が高まっています。
個人的見解 3— まとめ
AlphaGo Zeroは人間のドメイン知識を必要とせずに、世界最強まで上り詰めました。むしろ、人間の知識を使うとAIが弱くなることまでわかりました。Sutton氏が繰り返して言っていることは、人間のドメイン知識や人間中心に固執し、カオスに呑まれてしまわないことです。そして、シミュレーションによる”探索”と勾配伝播のイテレーションによる”学習”に基づく、General Purposeを最適化するメタ的な方法論が重要だということです。この方法はシンギュラリティ時代に要求され、人生の岐路に立って何か行動選択を行う際に役立つものです。今後、詳しく説明していなかった”汎用的な手法”の具体的なアルゴリズムについて、書きたいと思います。
最後にSutton氏がWeb上で公開している強化学習のバイブル的な教科書を紹介します。全て英語ですが、良本として知られているので詳しく勉強したい方は[14]を参照してください。
[14] Richard S.Sutton and Andrew G. Barto, “Reinforcement Learning:An Introduction”, MIT Press, Cambridge, MA, 1998, A Bradford Book.



この記事に関するカテゴリー






