
アフィンの精度をまず上げろ!ViTを用いたレジストレーション:C2FViT
3つの要点
✔️ 畳み込みとMHSAでCoarse-to-Fineに位置合わせを行うC2FViTを提案
✔️ 既存手法で軽視されてきたアフィンレジストレーション単体の性能を定量的に分析
✔️ CNNベースの手法より優れた性能と汎化性能を持ち、非学習ベースの手法と同等の精度を達成
Affine Medical Image Registration with Coarse-to-Fine Vision Transformer
written by Tony C. W. Mok, Albert C. S. Chung
(Submitted on 29 Mar 2022 (v1), last revised 30 Mar 2022 (this version, v2))
Comments: Accepted by CVPR2022.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
今回紹介するのはアフィンレジストレーションの最新手法Coarse-to-Fine Vision Transformer(C2FViT)です。ViTと畳み込みの優位性を両立することでグローバルな位置合わせとローカルな位置合わせを精度良く行い、更にそれらを複数の解像度でCoarse-to-Fineにおこなっていくことで脳MRIデータで既存の学習ベースの手法を凌駕しました。提案手法の性能も重要ですが、軽視されてきたアフィンレジストレーション単体の性能評価を既存手法でも行っている点も重要です。アフィンレジストレーションのトレンドを把握するのに本論文は必須だと感じます。
主な貢献は次の通りです。
- 3D脳MRI画像において既存のアフィンレジストレーション手法の精度・頑健性・汎化性能を定量的に分析した
- 畳み込みViTでCoarse-to-Fine(荒い方から細かい方)に位置合わせを行うC2FViTを提案した
- アフィン行列を平行移動・回転・スケール・せん断それぞれのパラメータに分解して推定することで一般性を持たせた
- MNI152テンプレートへの標準化・アトラスベースのレジストレーションの2つの実験で優れた性能と一般性を示した
それでは早速C2FViTを見ていきましょう。
アフィンレジストレーション
本論文ではアフィンレジストレーションに着目しています。レジストレーションは2つの画像間で位置合わせを行うタスクです。画像のある領域が別の画像ではどこに対応するかを把握することで、医療の分野では同一患者の経過観察や異なる患者間の症状比較など幅広く応用することができます。ある画像movingを固定されているfixedと一致するよう変形する変位場Aを学習することがモデルの目標です。下に本論文で使用するデータセットやモデルのレジストレーションの例を示します。

変位場が扱う変形はアフィン変形と非線形な変形に大別されます。処理の仕方によって2つのアプローチがあります。下の表はそれぞれの概要と欠点です。

アフィン変形を捉えられない限りは位置合わせの性能は大きく低下してしまいます。多くの既存手法はまずアフィンレジストレーションにより平行移動や回転・スケールなどグローバルな位置合わせを行い、その後細かな非線形な変形を取り除くDeformable Registrationを適用する2段階処理で構成されます。このアプローチでは、前段のアフィン変換は凸最適化や適応的勾配降下など、学習無しに個別に最適化する手法を用いることが多いため、処理時間が膨大になる欠点があります。
一方で最近はアフィンも非線形も区別せずにCNNで1段階に学習・処理する手法もあります。このアプローチは高速である反面アフィン変形もCNNで捉える必要があります。一般に画像間のアフィン変形は大域的であることが多いため、カーネル内の局所変化しか捉えられないCNNのアプローチは適切ではありません。実験では、既存のCNNベースの手法は位置ずれが大きい未知の画像に対して性能が低いことが示されています。
Coarse-to-Fine Vision Transformer(C2FViT)
上記の理由から本論文では前段のアフィンレジストレーションに着目し、より精度と頑健性を高めたC2FViTを提案しています。C2FViTは既存のCNNベースのアプローチから離れ、Vision Transformerを利用した新たなアフィンレジストレーションモデルです。また畳み込み層を導入して適度な帰納バイアスを導入し、複数の解像度を用いて大域的な変動から局所的な変動を順に推定するCoarse-to-Fineな推定モデルになっています。
アフィン行列の分解
C2FViTはアフィン行列の4種のパラメータ行列を独立に推定しています。アフィン変換は次の式で表されます。この式で画像の平行移動・回転・スケーリング・せん断を行うことができます。(x,y)は適用する画像の各画素の位置、(x',y')はアフィン変換後の座標です。アフィンレジストレーションはこの行列のパラメータを推定することが目的です。
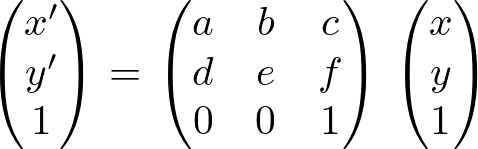
既存手法は上式を推定していることが多いですが、上式は種類の異なる4つの変換を1度に行う式のため、汎用性が低いです。アフィン変換では異なる4つの変換をそれぞれ独立に行えるので、平行移動・スケーリング・回転・せん断を独立に推定できた方がレジストレーションの幅が広がります。例えば4つの変換のうちスケーリングの行列とせん断の行列を除いて変換すれば剛体レジストレーションを行うことができます。そのためC2FViTは平行移動・スケーリング・回転・せん断のパラメータを独立に推定しています。
Attentionと畳み込みの両立
次の図の(c)が提案手法の概要図、(a)・(b)は既存のCNNベースのアプローチです。(a)のConcatenationベースではmovingとfixedを同じ1つのネットワークで処理しますが、当然カーネルサイズ以上の依存関係を捉えることができないためアフィンレジストレーションには不向きです。(b)はfixedとmovingで別々のネットワークを用意します。それぞれGlobal Average Poolingを通した特徴を最後に統合するためある程度グローバルな推定が可能ですが、逆にローカルな関係を軽視した推定になってしまいます。
一方で提案手法であるC2FViTは画像組を同時に処理しますが、MHSA層でグローバルな関係を捉えつつ、畳み込み層でローカルな特徴も両立させています。変更点はパッチ埋め込みとFeed-Forward層です。通常のViTは入力画像の局所パッチを線形射影でQ,K,Vに変換していますが、C2FViTはローカル特徴も重視するため3次元畳み込み層によるパッチ埋め込みを獲得しています。更に通常のViTはパッチごと独立にFeed-Forward層に通していますが、C2FViTはMHSA層の出力を再度3次元空間に配置し直し3次元のDepth-Wise畳み込みを適用することでモデルの局所性を更に強めます。図ではConvolutional Feed-Forwardと表記されています。

提案手法はこのConvolutional Patch EmbeddingとN個のTransformer Encoderの処理を1つのステージとして構築します。
Multi-Resolution strategy
C2FViTは複数の解像度で段階的にアフィン変形を取り除くアプローチをとっています。初めにmoving,fixedの集合M,Fについて様々なスケールでダウンサンプリングした画像ピラミッドMi,Fiを作成します。iは1~Lの範囲を取り、Mi,Fiは0.5^(L-i)のスケールでダウンサンプリングされています。つまりiが小さいほど低解像度で大域的なレジストレーションとなり、i=Lでは元の画像サイズで高解像度のレジストレーションとなります。

提案手法は各解像度に対する処理を1ステージとしてL(=3)ステージの段階的な位置合わせを行います。最初は最も低解像度のF1,M1の位置合わせを行います。この時得られた変位場A1は次の解像度のM2にSpatial Transformで反映させ、更に位置合わせを行います。加えて前の解像度の特徴量が次のConvolutional Patch Embeddingに加算されることで、これまでの低解像度の特徴と位置合わせを考慮したCoarse-to-Fineなレジストレーションが可能になります。
教師なし損失
位置合わせの損失は推定されたパラメータで実際にmovingを変換した画像がfixedに一致するかを評価することで得られます。本モデルではレジストレーションでよく用いられる類似度指標NCCの負の値を各解像度iで算出し、和をとっています。NCCの添字wは局所窓、Mi(Φ)は位置合わせ後の画像です。
![\begin{align*}
\mathcal{L}_{sim}(F,M(\phi))=
\sum_{i\in[1...L]}-\frac{1}{2^{(L-i)}}\mathrm{NCC}_w(F_i,M_i(\phi))
\end{align*}](https://texclip.marutank.net/render.php/texclip20230122232944.png?s=%5Cbegin%7Balign*%7D%0A%20%20%5Cmathcal%7BL%7D_%7Bsim%7D(F%2CM(%5Cphi))%3D%0A%20%20%5Csum_%7Bi%5Cin%5B1...L%5D%7D-%5Cfrac%7B1%7D%7B2%5E%7B(L-i)%7D%7D%5Cmathrm%7BNCC%7D_w(F_i%2CM_i(%5Cphi))%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
半教師あり損失
以前紹介したDIRモデルVoxelMorphはfixed,movingが代表的な幾何学的構造のセグメンテーションマスクを持っている場合は半教師あり学習を行えましたが、本モデルも同様の学習が行えます。位置合わせ後のセグメンテーションマスクの重なり具合を評価すればより直接レジストレーションを評価できるためです。教師無し損失Lsimに次のLsigを加えることで半教師あり学習に拡張できます。各解像度のセグメンテーションマスクSFi,SMiの重なり具合の負の値を算出して損失としています。Kはセグメンテーションマスクの数です。重みλ=0.5としています。
![]()
![\begin{align*}
\mathcal{L}_{seg}(S_F,S_{M}(\phi))=
\frac{1}{K}\sum_{i\in[1...K]}\left(1-\frac{2(S_F^i\cup S_M^i(\phi))}{|S_F^i|+|S_M^i(\phi)|}\right)
\end{align*}](https://texclip.marutank.net/render.php/texclip20230122235000.png?s=%5Cbegin%7Balign*%7D%0A%20%20%5Cmathcal%7BL%7D_%7Bseg%7D(S_F%2CS_%7BM%7D(%5Cphi))%3D%0A%20%5Cfrac%7B1%7D%7BK%7D%5Csum_%7Bi%5Cin%5B1...K%5D%7D%5Cleft(1-%5Cfrac%7B2(S_F%5Ei%5Ccup%20S_M%5Ei(%5Cphi))%7D%7B%7CS_F%5Ei%7C%2B%7CS_M%5Ei(%5Cphi)%7C%7D%5Cright)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
詳細設定
Convolutional Patch Embeddingの出力チャンネル数dは256に、マップサイズはflattenして4096次元と固定されています。ストライドやパディング・カーネルサイズを入力のマップサイズに合わせて相対的に決めることで常に一定次元の埋め込みを保っているようです。また通常のViTではLayer Normalizationが採用されていますが、本手法・タスクでは機能しなかったため取り除いているとのことです。
実験
実験では3D脳MRI画像の標準化タスクとアトラスベースのアフィンレジストレーションタスクで性能検証を行い、提案手法の優位性を検証しています。
タスク概要
・MNI152への標準化
MNI152は脳画像のテンプレートです。脳に関する様々な研究を統合するために各被験者の脳を標準脳(テンプレート)に合わせる標準化を行います。これにより、座標系とスケールが統一され、解剖学的な対応づけを行うことができるようになります。全人類の脳が1つの脳に統合されるのはおかしいので、標準化を行った複数人の脳の平均をテンプレートとする改良が行われました。この処理を何度か行い改良を重ね、最終的に152人の脳を標準化し、平均脳を作ったのがMNI152です。本論文ではOASISデータセットをMNI152にレジストレーションさせ、代表的なレジストレーションタスクの性能検証をします。
・アトラスベースレジストレーション
このタスクでは平均脳ではなく、データセットの各画像そのものへのレジストレーションを行います。学習ではOASISデータセットでランダムに選択したペアを選択します。テスト時にはOASISデータセットと未知のLPBAデータセットでレジストレーションさせます。同じデータセットと未知のデータセットに適用することでモデルの性能や汎化性能を検証するのが目的です。OASISから3つ、LPBAから2つをランダムにアトラスとして選び、それぞれのデータセットのテストデータをアトラスにレジストレーションさせます。
データセット
・OASISデータセット
このデータセットは414枚のT1強調脳MRI画像です。本論文ではFreeSurferを用いてリサンプリング・パディングなどの前処理を行なっています。Train:Valid:Test=255:10:149で分割しています。
・LPBAデータセット
このデータセットは40枚の脳MRI画像です。本論文では全てテストデータとして用いています。
ベースライン
全てのモデルは3つの解像度で最適化させています。提案手法ではL=3です。
・非学習ベース
従来の非学習ベースのレジストレーションではSoTAモデルとしてANTsとElastixを用います。2つとも相互情報量を用いた適応的勾配降下で最適化しています。
・学習ベース
既存手法にはConvNet-AffineとVTN-Affineの2つの手法を用いています。それぞれ論文を参考にしたアフィンネットワークのみを構築しています。学習ベースの手法は全て半教師ありに拡張し、それぞれConvNet-Affine-semi、VTNAffine-semi、C2FViT-semiと表記し、学習させます。
評価
4つの評価を行なっています。Dice similarity coefficient(DSC)、30% lowest DSC of all cases(DSC30)、95% percentile of Hausdorff distance(HD95)の3つはレジストレーションの精度指標です。4つ目に非学習ベースと学習ベースで大きく異なる実行時間をTtestで表記します。標準化では尾状核,小脳,被殻,視床の4つの皮質下構造のマスクを評価対象としており、OASISでは23の皮質下構造を、LPBAでは
initializationがよく用いられるためです。
精度と頑健性
まずはCoM initializationを行わなかった場合の結果です。位置合わせ前の状態ではいずれのデータ・タスクでもDiceスコアが低く、大きな位置ずれが生じていることが確認できます。提案手法は3つのタスク全てにおいてDSC・DSC30・HD95においてConvNet-Affine・VTN-Affineより優れており、大きな位置ずれを伴うアフィンレジストレーションで頑健かつ高精度であることが示されました。逆に既存手法のアフィンサブネットワークは大きな位置ずれに対して不十分であることが確認されました。

続いてCoM initializationありの場合の精度です。重心を合わせることでDiceスコアがそれぞれ0.14,0.18,0.33から0.49,0.45,0.45に向上しており、平行移動だけで大まかに位置合わせが行えていることがわかります。学習ベースの手法は全てCoM initializationで大幅に精度が改善されていますが、特に提案手法は教師無しモデルC2FViTではANTs・Elastixと同等の精度を達成し、半教師ありモデルC2FViT-semiがMNI152への標準化とOASISのアトラスベースレジストレーションで最高精度となりました。

汎化性能
LPBAデータセットの精度は他2つのタスクの精度と異なっています。既存手法のConvNet-Affine・VTN-AffineはCoMの有無や-semiへの拡張でもDiceスコアがinitialの値からほぼ変わらず位置合わせが全く行えていないことが分かります。一方でC2FViTはElastixに若干劣りますが、ほぼ同程度に精度良く位置合わせができています。Elastixが個別の最適化で、C2FViTがOASISのみの学習をLPBAに適用していることを考えるとC2FViTが既存手法と比較して強い汎化性能を持っていることが分かります。
実行時間が膨大であるANTsやElastix、頑健性の低い学習ベースと比較すると実行時間・精度・汎化性能の点で大きな優位性を示す結果となりました。
アフィン行列の分解
提案手法がアフィン行列をdirectに推定する場合と先述した平行移動・回転・スケーリング・せん断に分解したdecoupleの推定の精度比較も行われています。表の通りdecoupleに推定する方が精度が良く、さらに他のパラメトリックなレジストレーションに容易に適用できる汎用性も持つことが分かりました。

まとめ
今回は3D医用画像のアフィンレジストレーションのためのCoarse-to-Fine VisionTransformer(C2FViT)を紹介しました。CNNベースのアフィンレジストレーションを用いた従来研究とは異なり、Self-Attentionによるグローバルな特徴抽出を重視しました。畳み込みによる適度な局所性とCoarse-to-Fineな位置合わせを組み合わせることでC2FViTはCNNベースの手法より優れたレジストレーション精度を達成しました。特に位置ずれが大きいデータ下で既存手法との差が大きく、未知のデータセットに対する頑健性も示しました。半教師ありのC2FViT-semiはデータセット固有の情報を利用することで非学習ベースの手法を上回り、精度・頑健性・実行時間・汎化性能の優位性を示しました。
課題として、教師なしの学習ベースの手法と従来の非学習ベースの手法との精度のギャップを上げています。タスクに特化したデータ拡張で精度向上につながる可能性があるとしています。これからの発展が楽しみです。



この記事に関するカテゴリー






