
眼科の専門医をAIが超える!? 眼底画像による緑内障の自動診断モデルの提案!
3つの要点
✔️ 緑内障の診断には専門知識と長年の経験が必要となるため、これらを自動化するアルゴリズムの開発が求められている。
✔️ 本研究では、畳み込みニューラルネットワーク—convolutional neural network: CNN—を用いた緑内障の自動診断アルゴリズムの構築を目指す。
✔️ 評価結果から、精度93.86%,感度85.42%,特異度100%,を達成したことが確認された。
Identification of glaucoma from fundus images using deep learning techniques
written by S Ajitha, John D Akkara, M V Judy
(Submitted on 25 Sep 2021)
Comments: Front Public Health
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
背景
深層学習は眼科の専門医を超えることができるのか?
本研究では、眼底画像に基づき深層学習を用いた、緑内障の自動診断アルゴリズムの構築を目指す。
緑内障は、眼圧の上昇により、脳への情報伝達を担う神経線維が束縛され、視神経の障害を引き起こす疾患である—これら症状により、恒久的な失明や、極度の視野障害を引き起こす。この疾患では、初期状態における自覚症状が少ない一方、周辺視野の欠損は発生している。
また、現在の医療では視神経の復元が困難であることから、一度重症化するとその後改善することが至難となる—そのため、予後改善を鑑みると早期発見・予防が重要である。一方、これら診断には、専門的な知見—専門性の高い訓練・知識—が必要となり、経験の少ない人—i.g. 患者・研修医—による評価が難解とされている。
加えて、緑内障に対する評価方法は、眼科医による細隙灯生体顕微鏡を使用した手作業の占める割合が大きく、臨床的な専門知識に依存する—そのため、検査者間のばらつきが大きく、誤診や臨床情報の浪費を招く可能性も高い。
このため、緑内障の早期診断のための新しい方法—専門技術への依存が少ない手法—が必要とされている。こうした背景から、本研究では、CNNを活用した緑内障の自動診断アルゴリズムの構築を目指す。構築にあたり、4つの異なるデータセットでモデルを学習し、モデルの汎用性を向上させる。
緑内障とは?
初めに、本研究の解析対象である、緑内障について概説する。
緑内障は、眼圧の上昇のために視神経に障害が発生、視野が狭くなり、最終的に視力が低下する疾患である。発生頻度としては、40歳以上で5%、60歳以上では1割以上と加齢とともに高くなる傾向があり、発生原因は現在、不明とされている。
眼圧の上昇により、一度死滅した視神経を復元することは困難であるとされている;一方、早期発見および適切な治療により、視野・視力を維持することは可能であるため、早期発見、また、早期介入が重要である。
また、眼圧はかなり高まった状態にならないと明確な症状が発生せず、加えて、両目では視野狭窄に気付かないケースが多いため、自覚症状もなく進行することが多い。
手法
ここでは、本研究での提案モデル—下図参照—について述べる。
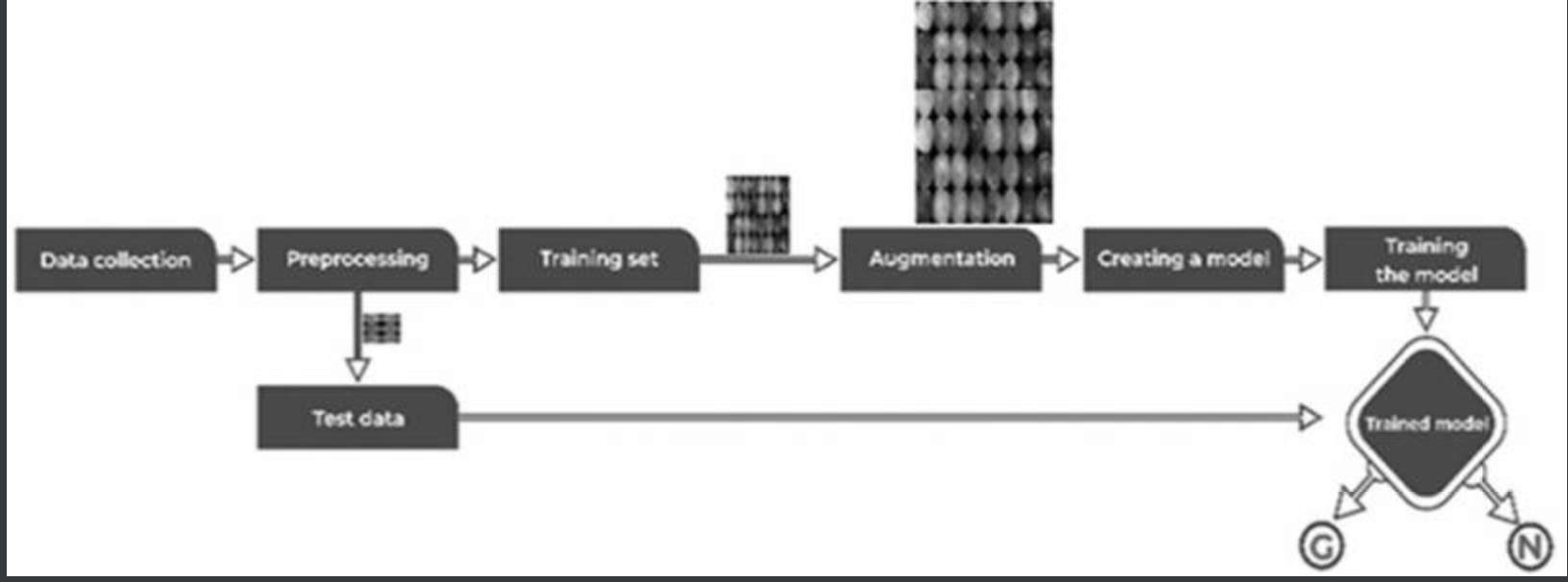

学習データセットとして、様々な民族、年齢層、照度レベルの眼底画像1113枚を対象とした:学習にあたり、共通のフォーマットとサイズに変換する前処理をおこなった:全画像を3000×2000ピクセルにリサイズし、OpenCVで色と明るさを正規化した;画像を512×512ピクセルに縮小した。また、データセットをランダムに3分割した:70%—正常462枚、緑内障317枚—をトレーニング、20%—正常132枚、緑内障88枚—を検証、残りの10%—正常66枚、緑内障48枚—をテストに用いた。
CNNモデルのアーキテクチャでは—下図—10層の畳み込み層と3層の完全連結—Dense—層に基づき構成し、正規化された画像を入力とした。最後の層以外の全結合層と畳み込み層に適用されるRELUを使用し、活性化関数として、SoftMaxを活用した。また、効率的で成功するDLモデルを開発するため、データバランシングやオーグメンテーションといった正則化を適用した—特に医療データの場合、アノテーションコストからラベルのついた大量のデータセットを準備することが困難な場合があるため、こうした戦略も検討される。
提案モデルでは、合成サンプルを生成するデータバランシングメソッド—Synthetic Minority Oversampling Technique—を適用し、正常・緑内障画像が一致するようにバランシングをおこなった:その結果,12012枚の眼底画像を生成し学習をおこなった。また、最適化関数としてAdam Optimizerを用い,デフォルトの学習率0.001,バッチサイズ32として設定した.誤差の計算として、Categorical cross entropyを損失関数に適用した。
結果
このセクションでは、評価について解説する。
モデルの性能評価には,特異度,感度,精度、area under ROC curve—AUC—を対象とした:感度は、緑内障が陽性と診断される確率;特異度は、緑内障でない人が陽性と診断される確率;精度は診断による分類結果全体の確率。また、ハイパーパラメータとして、8、16、32、64、128のバッチサイズ、50エポックの条件のもと学習をおこなった—下図参照:これら曲線から、提案モデルが過学習を起こしていない—新しいテストデータに対しても同じ予測性能を維持できる—ことが示された。バッチサイズを32とした場合の精度は99.26%であった。
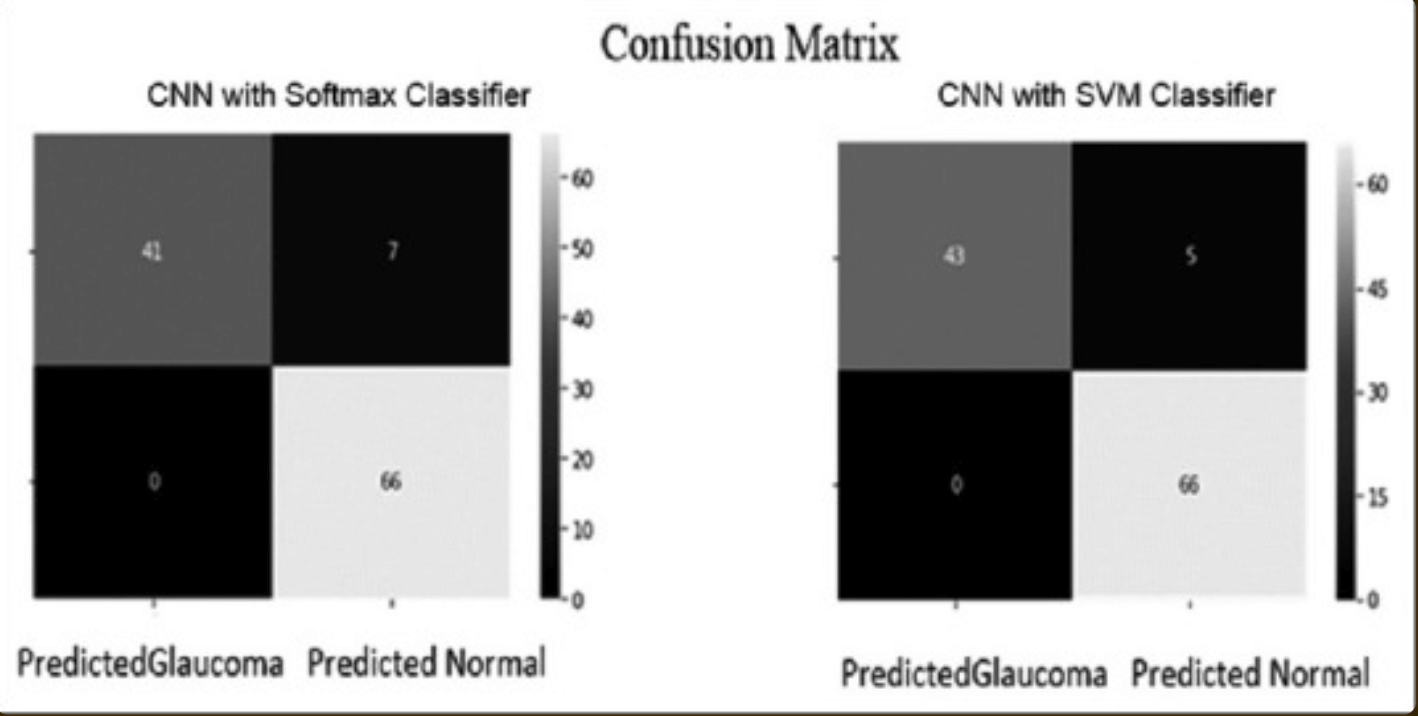
分類モデルにおける混同行列—真陽性、偽陽性、真陰性、偽陰性による予測値の正誤をまとめた表—から、SoftMax分類器、SVM分類器での性能を比較した:その結果、SVM分類器を用いたCNNがSoftMax分類器を用いたCNNを上回った—下表参照。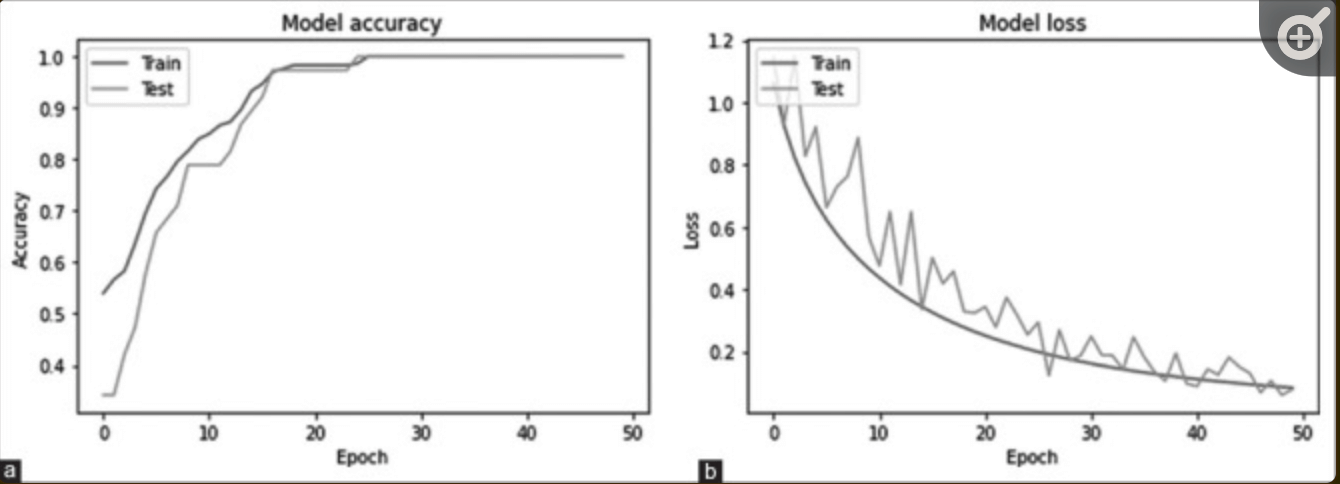
まとめ
本研究では、眼底画像に基づき緑内障に対する自動診断モデルの構築を目指した。モデルの構築では、1113枚の網膜画像からなる複数のデータセットを使用し、データセットの約70%をTrain、20%をValidation、10%をテストに使用した:テストでは114枚—48枚が緑内障、66枚が正常—のデータを用いた。深層学習を活用したモデルでの評価性能は下記のようになった:SoftMax分類器では、精度93.86%、特異度100%、感度85.42%、AUC 0.927;SVM分類器では、精度95.61%、感度89.58%、特異度100%、AUC 0.948。これら結果から、専門医と同等もしくはそれ以上の精度で緑内障の分類モデルを生成することが可能であることが示唆された。
本研究の強みとして、CNNから構成されたシンプルなアルゴリズムから構成されている一方、正常なケースを高精度で検出できる点が考えられる。SoftMaxとSVM分類器では、高い特異度を達成している。また、陽性例においても89.58%が分類されている。そのため、緑内障および健常者の両方—特に健常者—を高い精度で分類できることが示唆される。
一方、課題として、下記の点が挙げられる:アノテーションのコスト;深層学習におけるブラックボックス性。高い推定精度を持つモデルの構築にあたり、網膜画像のアノテーション—ラベル付与—された大規模なデータセットを準備する必要がある—これらアノテーションでは、現在、専門医による診断が必要となり、画像に対するラベル付与から学習コストが大きくなる傾向がある。
解決策として、転移学習などの事前学習モデルの活用、もしくは、弱教師学習といった少数ラベルに適したアルゴリズムの導入が考えられる;後者の課題では、深層学習におけるブラックボックス性—どのような基準でモデルが判断しているか—が不明瞭な傾向が高い点である。解決策としては、Grad-CAMといったヒートマップを活用し、画像常におけるモデルの診断基準の明確化を活用し、臨床的な意義を付与することが考えられる。



この記事に関するカテゴリー





