
少量データでも高性能に?Multilabel approachでPET/CTの病変誤認を改善!
3つの要点
✔️ マルチラベルモデルの有効性を実証
✔️ PET/CT の病変誤認を改善
✔️ 追加のデータだけでなく複数のラベルを組み込むことの重要性を実証
Improving Lesion Segmentation in FDG-18 Whole-Body PET/CT scans using Multilabel approach: AutoPET II challenge
written by Gowtham Krishnan Murugesan, Diana McCrumb, Eric Brunner, Jithendra Kumar, Rahul Soni, Vasily Grigorash, Stephen Moore, Jeff Van Oss
(Submitted on 2 Nov 2023)
Comments: AutoPET II challenge paper
Subjects: Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
深層学習モデルを使用した FDG-18 全身(WB) PET/CT スキャンにおける病変の自動セグメンテーションは、治療反応の判定、線量測定の最適化、および腫瘍学における治療法の応⽤の進歩に役⽴ちます。しかし、肝臓、脾臓、脳、膀胱など、放射線トレーサー (1つまたは複数の原子が放射性核種に置き換えられた化学物質) の取り込み量が増加した臓器が存在すると、これらの領域が深層学習モデルによって病変として誤認される可能性があるため、課題が⽣じます。
本論文では、この問題に対処するために、⾃動病変セグメンテーション法の性能を向上させることを⽬的として、臓器と病変の両⽅をセグメント化する新しいアプローチを提案しています。
PET/CT の現状と課題
陽電⼦放出断層撮影/コンピュータ断層撮影 (PET/CT) は、腫瘍の画像化に不可⽋なツールであり、転移病変の早期発見、代謝性⾼進腫瘍の定量化に役⽴ち、がんの診断、病期分類、治療計画、再発モニタリングに⼤きく貢献しています。
それと同時に、深層学習アルゴリズムの進化は医療画像分野に⾰命をもたらし、取得された画像内の癌性病変のより正確かつ効率的なセグメンテーションを促進しました。これらのアルゴリズムは、病変の複雑さや変動性、そして微妙さのために従来の⽅法論ではセグメンテーションに失敗する状況にあっても、腫瘍の境界を⾃律的に描写するという驚くべき能⼒を備えています。
しかし、放射性トレーサーの取り込みには患者間でばらつきがあり、放射性トレーサー固有の性質により、脳などの代謝活性の⾼い正常な器官や、肝臓、腎臓、膀胱などの浄化器官への蓄積量が⾼まる可能性があります。そのため、自動病変セグメント化アルゴリズムでは、放射性トレーサーの取り込みについて、それらの臓器での正常な取り込みであるのか、もしくは本当の病変であるのかを区別することが難しく、大きな課題となっています。
仮説と検証
本論文では、自動病変セグメント化アルゴリズムが抱える問題を解決するために、放射性トレーサーの取り込み量が多い臓器を病変に沿ってセグメント化することで、その臓器が病変であるのかないのかという識別⼒をモデルに組み込むことができるのではないかと仮説を⽴て、いくつかの方法で検証を行っています。
方法
データと前処理
本論文ではデータとして、AutoPET challenge II 2023 によって提供された 1,014 件の研究を含む、900 人の患者からの全身 FDG-PET/CT データが使用されています。また、本論文で提案されたアルゴリズムの堅牢性と一般化可能性を評価するためのテストデータセットとして、150 件の研究で構成される保持データセット (そのうち 100 件はトレーニングデータベースと同じ病院からのもので、50 件は同様の取得プロトコルで別の病院から得られたもの) が使用されています。
前処理として、CT データを PET 解像度に合わせて再サンプリングし、正規化しています。また、2 人の専門家がそれぞれトレーニングデータとテストデータにラベルを付け、ハイブリッドイメージング (2 つ以上の異なる画像モダリティを組み合わせることで、身体の内部構造や機能をより包括的に把握できるようにする医療画像技術) で 10 年の経験を持ち、テュービンゲン大学病院での機械学習研究の経験を持つ放射線科医と、ミュンヘンの LMU 大学病院でハイブリッドイメージングで 5 年の経験を持ち、機械学習研究の経験を持つ放射線科医が、それぞれすべてのデータにラベルを付けています。
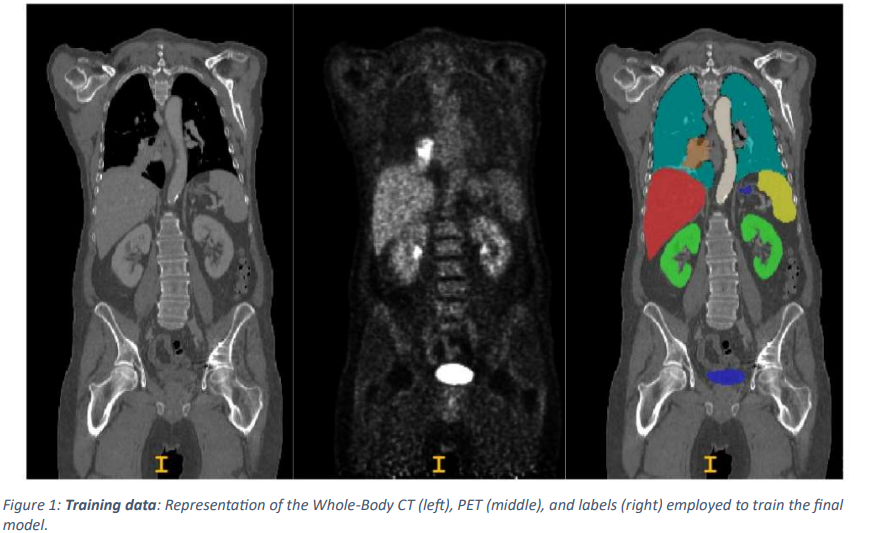
本論文では、トレーニングデータをランダムに 5 分割し、nnUNet フレームワーク内で 3D UNet モデルをトレーニングして、複数の臓器と病変をセグメント化しています。
複数のラベルとデータを追加した場合の影響
提案手法の評価方法として、まずトレーニングデータを 2 つのグループ (1 つは 819 件の研究を含み、もう 1 つは 195 件の研究を含む) に分割して実験を行った上で、病変をセグメント化する際のモデル性能に、より多くのラベル (肝臓、脾臓、腎臓、膀胱) とより多くのデータを追加した場合の効果を評価する研究を実施しています。
本論文では、病変セグメンテーション用に設計された 2 つの異なる 3D UNET モデルに特に焦点を当て、5 分割交差検証法を利用した徹底的なモデルのトレーニングと評価プロセスを実施しています。
1 つのモデルは病変を分離するために作成され (単一ラベル)、もう 1 つは他の高摂取臓器と組み合わせて病変をセグメント化するために作成されます (マルチラベル)。ただし、高摂取臓器のラベルは、公開されている totalsegmentator を使用して導出されます。まず 819 件の研究からなるデータセットで両方のモデルをトレーニングし、195 件の異なる医学研究からなる別のデータセットでそれらの性能を厳密に評価しています。この評価により、現実世界の状況におけるモデルの有効性を評価できるようになります。
さらに、データセットのサイズがモデルの性能に及ぼす影響を調査するために、元の 819 件の研究から 100 件の研究のサブセットをランダムに選択し、同一のセグメンテーション目的 (病変のみのセグメンテーション: 単一ラベルモデル、病変および高摂取臓器のセグメンテーション: マルチラベルモデル) で 2 つの別々のモデルをトレーニングしています。そして、これらのモデルを同じ 195 研究の保持データセットを使用して評価し、データセットのサイズがセグメンテーション機能にどのような影響を与えるかを理解できるようにしています。
AutoPET Ⅱ Challenge
AutoPET II チャレンジでは、1,014 件の研究のトレーニングデータをすべて使用してマルチラベルモデルをトレーニングしています。公開されている totalsegmentator package を使用して、8 つの追加の臓器 (肝臓、腎臓、膀胱、脾臓、肺、脳、心臓、胃) を導出し、トレーニングデータセットに追加しています。
モデルのアーキテクチャ
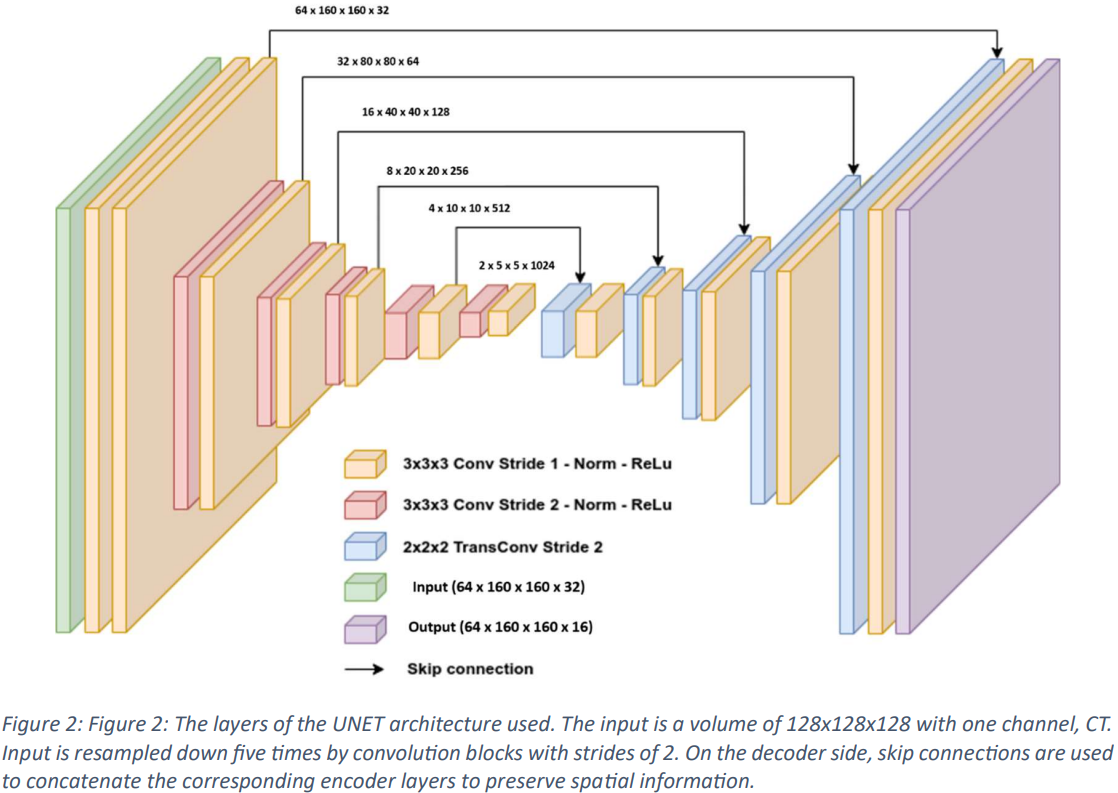
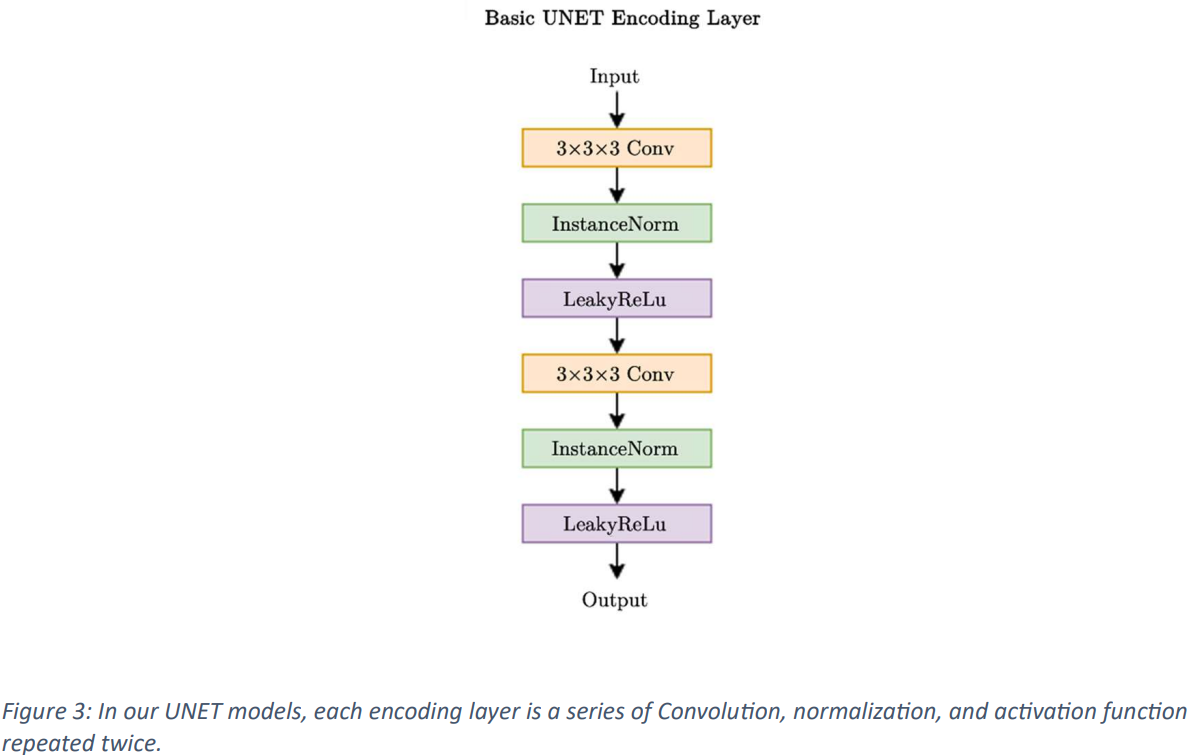
本論文では、Fig.2 と Fig.3 に示すように、トレーニング用の skip connection を組み込んだ、標準バリアント 3D UNet モデルが利用されています。入力画像の寸法は、単一チャネルで 128x128x128 に設定され、入力データとして CT スキャンが利用されます。入力は、5 つのステージを通じて 2x ストライドの畳み込みブロックによって段階的にダウンサンプリングされ、デコーダ側では skip connection を利用して対応するエンコーダ層を結合し、空間情報を保存します。ネットワーク層には InstanceNorm が組み込まれており、LeakyReLu が利用されています。
初期アーキテクチャでは 32 個の特徴マップが採用されており、エンコーダでの各ダウンサンプリング操作中に 2 倍になり、デコーダでの転置畳み込み中に再び半分になるまでに最大 1024 個の特徴マップに達します。デコーダ出力は入力と同じ空間次元を維持し、その後 1x1x1 畳み込みを行ってシングル チャネル出力を生成し、これが SoftMax 関数で処理されます。トレーニング中、モデルは、Duce Sorensen Coefficient (DSC) と重み付けされた交差エントロピー誤差を組み合わせた損失関数を使用して、過学習を起こさないようにするために 5 倍にわたってトレーニングされます。
また、モデルの堅牢性を高めるために、ランダム回転、ランダムスケーリング、ランダム弾性変形、ガンマ補正、ミラーリング、弾性変形などの拡張技術が採用されています。 5 つのモデルはそれぞれ、学習率 0.01 の SGD オプティマイザーを使用して、バッチサイズ 8 で 1,000 エポックにわたってトレーニングされます。性能評価には、セグメンテーション方法のさまざまな側面を評価するための Dice Similarity Coefficient (DSC) や Normalized Surface Dice (NSD) などのメトリックが含まれます。
検証結果
複数のラベルとデータを追加した場合の影響
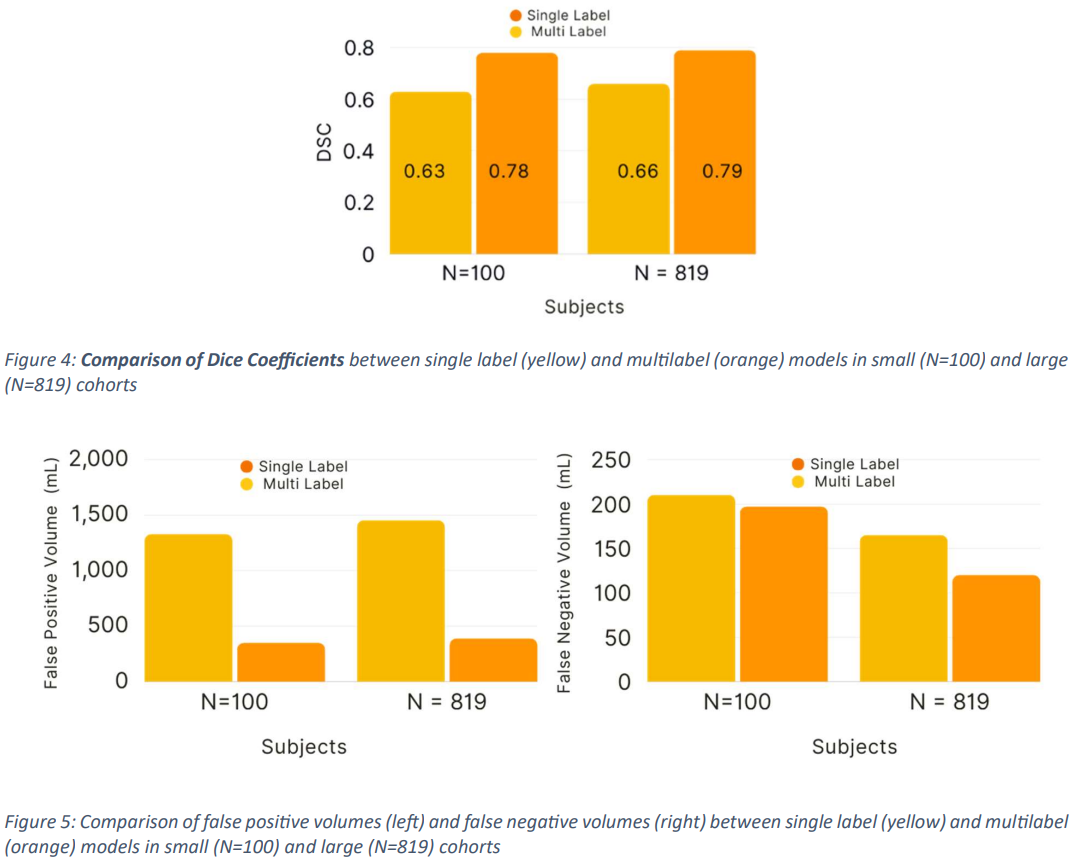
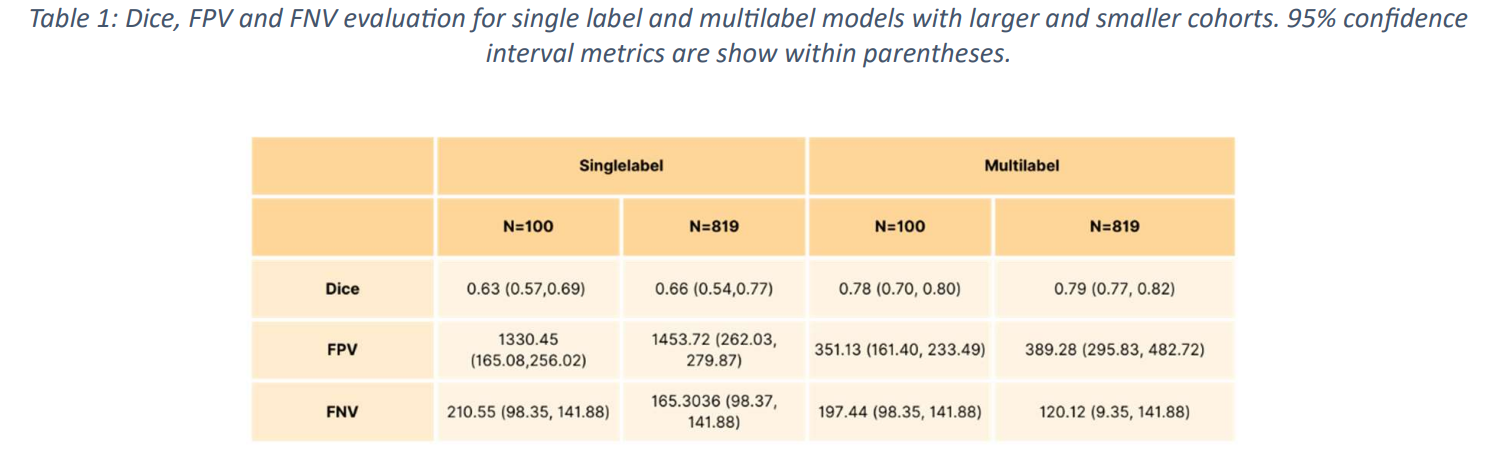
本論文では評価方法として、Dice Similarity Coefficient (DSC)、False Positive Volumes (FPV)、False Negative Volumes (FNV) が使用されています。
100 研究のサブセットを使用してトレーニングされたモデルは、単⼀ラベルセグメンテーションの場合、DSC 0.63+/-0.04 (95% 信頼区間 (CI): 0.57, 0.69)、FPV 1330.45 (95% CI: 165.08, 256.02)、FNV 210.55 (95% CI: 98.35, 141.88) であったのに対して、マルチラベルセグメンテーションの場合、DSC 0.78+/-0.02 (95% CI: 0.7, 0.80)、FPV 351.13 (161.40, 233.49)、FNV 197.44 (95% CI: 98.35, 141.88) を達成しています。
また、819 研究のデータセット全体を使⽤してトレーニングされたモデルは、より⾼い DSC スコア、具体的には単⼀ラベルセグメンテーションの場合、DSC 0.66+/-0.08 (95% CI: 0.54, 0.77)、FPV 1456.72 (95% CI: 262.03, 279.87)、および FNV 165.30 (95% CI: 98.37, 141.88)、マルチラベルセグメンテーションの場合、DSC 0.79+/-0.02 (95% CI: 0.77, 0.82)、FPV 389.28 (95% CI: 295.83, 482.72)、および FNV 120.12 (95% CI: 98.35, 141.88) を達成しています (Fig.4 および Fig.5) (Tab.1)。
以上より、本論文の提案手法であるマルチラベルセグメンテーションによって、従来手法の精度を上回る結果を得られていることが分かります。
AutoPET Ⅱ Challenge
本論文の提案手法による検証結果は、xxダイス、yy FPV、およびzz FNV を達成することで、AutoPET Ⅱ Challenge でランキングトップを達成しました。
まとめ
本論文では、医療画像データ内の病変をセグメント化することを目的として、病変のセグメント化のみに焦点を当てるようにした単一ラベルモデルと、病変に加えて他の解剖学的構造をセグメント化するようにしたマルチラベルモデルの 2 つの異なる深層学習モデルのトレーニングと評価を実施した結果から、マルチラベルモデルの明らかな有効性を示しています。
また、深層学習モデルの病変セグメンテーション機能を強化する上で、追加のデータだけでなく複数のラベルを組み込むことの重要性も示しています。
Multilabel approach はその有効性に加えて汎用性もあるため、今後さらなる発展が期待されます。






この記事に関するカテゴリー





