
VoxelMorph: 医用画像のためのUNetベースのレジストレーションモデル!
3つの要点
✔️ 画像組毎に解くコストの高い最適化を1回のグローバルな最適化に置き換えた
✔️ 従来手法と同等の精度で圧倒的に高速に動作
✔️ 各画像に部分的な補助データがあれば精度を向上させられる柔軟なモデル
VoxelMorph: A Learning Framework for Deformable Medical Image Registration
written by Guha Balakrishnan, Amy Zhao, Mert R. Sabuncu, John Guttag, Adrian V. Dalca
(Submitted on 14 Sep 2018 (v1), last revised 1 Sep 2019 (this version, v3))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
今回紹介するのは、2018年に提案されたVoxelMorphという非剛体レジストレーション(DIR)のためのモデルです。レジストレーションタスクは位置合わせとも呼ばれ、物体や部位の移動が見られる画像間の対応関係を把握する目的があります。医療においてはMRIやCT画像のペアなどで臨床応用が大きく期待されるタスクです。例えば呼吸により体内組織に動きが見られる肺CT画像組だったり、患者間で対象部位の症状を比較するためのMRI画像だったりと、写り込んだ様々な部位が画像間でどのように対応しているかを把握することは診断に大きく役立ちます。
対応関係は画像間で各部位がどう移動・変形したかを表す変位場を取得することで分かります。VoxelMorphが公開された2018年以前では、DIRは画像組毎に個別に最適化する手法が主流でした。1つのモデルがデータセット全体に対応した写像を行うようなパラメータを学習する深層学習モデルではなく、Demonsアルゴリズムなどで画像組毎に最適化問題を解く非学習ベースが高精度を達成していました。そんな中でVoxelMorphはDIRタスクを、「画像組を入力として変位場を出力するパラメトリックな関数」として定式化しました。つまりVoxelMorphの処理は以下の簡単な式で完結します。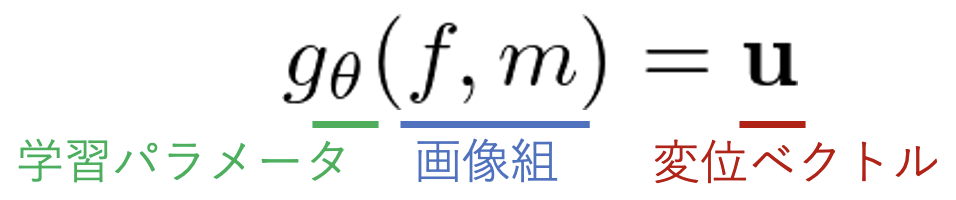
一般的な深層モデルは1枚の画像を入力しますが(ミニバッチ化はします)、VoxelMorphは画像組を入力します。こうすることで、画像組毎の個別の最適化ではなく、パラメータθをデータセット全体でグローバルに学習・最適化できるモデルを構築できます。fは変換先のターゲット画像(fixed)、mは変換を行うリファレンス画像(moving)です。
そんなVoxelMorphですが、学習ベースのDIRの有名なモデルの割に日本語の解説記事があまりありません。ということで今回は、シンプルで高精度で高速なDIRモデル「VoxelMorph: A Learning Framework for Deformable Medical Image Registration」を解説していきます。VoxelMorphの主な利点は以下の通りです。
- データセット全体に対してグローバルな最適化を行う深層学習モデル
- 少ないデータセットで学習可能
- 従来手法と同等の精度で圧倒的に高速
- U-Netを用いる事で特徴の正確な位置を捉える学習が可能
- 各画像の補助データがある場合は教師ありの損失を追加可能
- 2次元画像・3次元画像の両方に対応
実験では外観損失や補助データの有無、それらの重みの設定が精度に与える影響やデータセットの規模に対する精度の影響を分析しています。それではさっそくVoxelMorphの詳細を見ていきましょう。※この解説では論文発表当時の2018,19年の技術を基に解説します。
体系的位置付け
まずは本手法の体系的な位置付けから解説します。レジストレーションタスクで扱う変換は大きく剛体と非剛体に分かれます。剛体レジストレーションでは画像中の部位や物体の形状に変化が見られず、平行移動や回転のみがみられるアフィン変形を扱います。対して医用画像のほとんどは非剛体レジストレーション(DIR)です。体内組織は我々が思っているよりも自由な動きをしており、呼吸や体の動きに合わせて形状を変える非線形な変形が多く見られ、被験者によっても写りが異なります。
ただDIRも処理としてはアフィン変換と非線形変換を二段階で行う場合があります。まず第一段階としてアフィン変換により大まかな物体の移動・回転に対応させた後、二段階目に細かな変形を捉えてレジストレーションを行うというものです。VoxelMorphはDIRタスクにおいて二段階目に焦点を当てており、画像全体の移動や回転はアフィン変換により予め軽減させた画像組を対象としています。
アーキテクチャ
VoxelMorphのアーキテクチャを下図に示します。
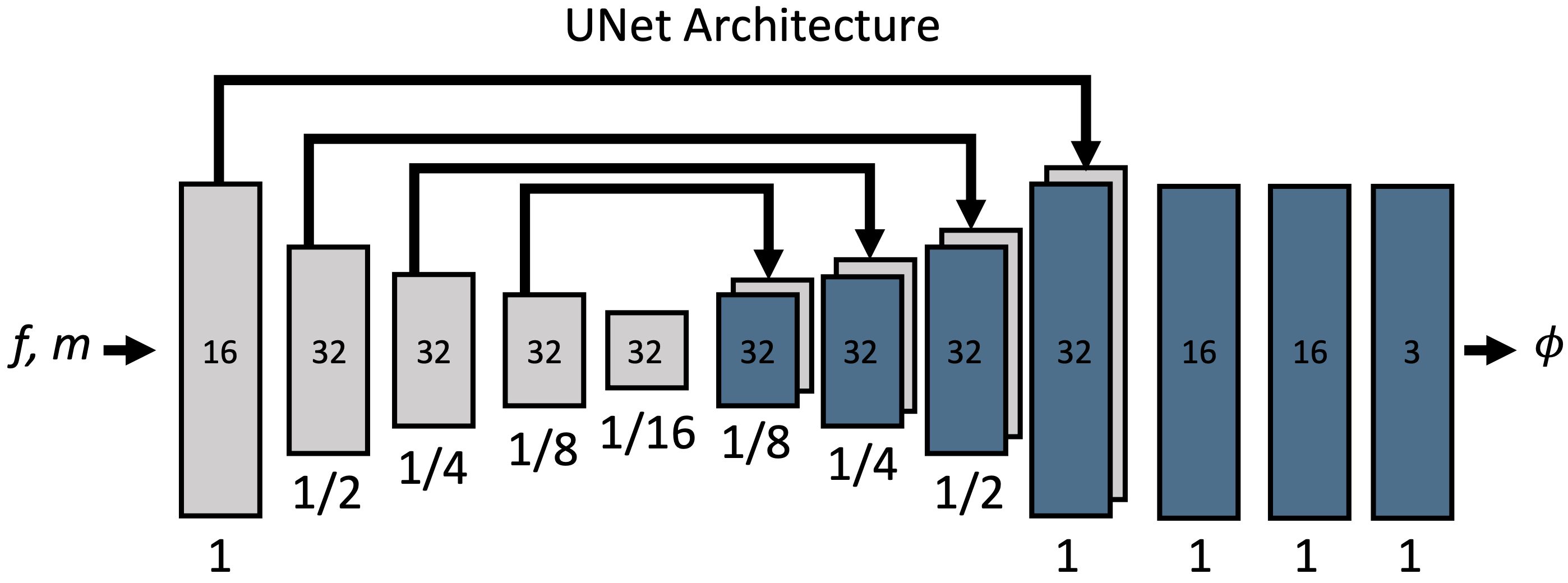
Φは変位場を指します。移動や変形が無い部分も値は0ではなく恒等写像(Id)であるべきなので、厳密にはuではなくΦ=Id+uになります。Φとf,mは同じサイズです。画像組を入力として変位ベクトルを出力するg(f,m)=uを実現できていることが分かります。ブロック内の数字はチャンネル数、その下は入力サイズに対するスケールです。詳細な設定を下記に示します。
- 実装では単純にチャンネル数2の画像として扱っています
- 図では3次元画像の例を示しているため、出力の変位場は3チャンネルとなっています
- 各畳み込み層は3x3カーネルとストライド2がデフォルトですが、CNNのため想定される変位の大きさに合わせて変えるべきと主張されています
- 各畳み込み層後にはα=0.2のLeakyReLUが適用されます
しかし何故この機構で上手く画像間の変位場を出力するパラメータθを学習できるのでしょうか?肝はUNetにあります。
UNet
一般的な回帰タスクでも多次元の出力は想定できますが、このタスクではg(f,m)=uを出力する必要があります。つまり画像サイズが256x256ならば、出力は2次元の移動を考えて256x256x2次元である必要があり、各ボクセル毎の変形を網羅的に捉えられている必要があります。
しかしCNNは特徴の局所性を仮定しており、層が深くなるにつれてグローバルな特徴を捉える構造になっています。これではいくらDecoderが優れていても層の深さに従って特徴の位置は曖昧になり、正確な変位場を出力できなくなってしまいます。そこでUNetが活躍します。
UNetはEncoderとDecoderからなるニューラルネットです。Encoderは畳み込みとMax-pooling,Decoderは畳み込みとUpsamplingから成ります。ここでただ直接に繋ぐのではなく、Encoderの特徴マップを保持しておき、Decoderの同じサイズの特徴マップに接続させるSkip-Connectionを行います。こうすることで、Encoderで捉えた局所的で低レベルな特徴を、Decoderの洗練された特徴と両立させて出力させることができ、正確な位置情報と特徴の質を保った特徴マップを得ることができます。その繋ぎ方がUの字に見えるので(上図だと見えないですが...)UNetと呼ばれます。
UNetはセグメンテーションタスクで主に用いられますが、VoxelMorphはその優位性をDIRに応用します。リファレンス画像m,ターゲット画像fそれぞれで抽出した様々な粒度の特徴を基に追加の何層かの畳み込みで変位場を出力させます。
Spatial Transformer Networks(STN)
VoxelMorphにより変位場は出力できましたが、実際にその正確さを評価するには変位場に基づいてmを変形させ、fと一致するかを評価する必要があります。そこでVoxelMorphはSpatial Transformer(STN)を用いています。Attentionでお馴染みのTransformerとは別物で、単純に変位場に基づいて空間を変換させるネットワークです。ボクセルpに対して以下のように変換させます。

式の通り、実際にはmを変形させているというより、ボクセルpの値に変形後のボクセルp'の値を代入する処理になっています。その際にはp'は直接参照はできないためその8方向で一番近い近傍画素qで重み付けをしています。VoxelMorphが出力するuは整数とは限らないため、画素と画素の間に位置する場合は近傍画素で補間する必要がある為です。|p'-q|は8近傍間の距離のため最大1です。qが偶然整数の場合は中心座標のみ重みが1で他は0になり、それ以外では距離に応じた値で重みづけ、加算されます。
この様に推定された変位ベクトルに従ってmをSTNで変換した上で、損失や評価を取ることになります。
損失関数
VoxelMorphの損失関数は各画像に教師ありと教師なしで2種類存在します。教師なし損失でも十分な精度を出しますが、各画像に解剖学的な構造を示すセグメンテーションデータがある場合は、それらの一致を課す教師あり損失を加えることで精度を向上させることができます。
教師なし損失
教師なし損失はDIRでは一般的な損失です。変換後の画像組の視覚的な一致を課す外観損失と変位ベクトルの局所的な変化を抑える正則化項から成ります。外観損失には微分可能な任意の誤差関数を設定可能であり、論文ではMSE(Mean Squared Error)とNCC(Normalized Cross Correlation) Lossを用いています。MSEは単純なピクセル間の二乗誤差ですが、NCCは部位の構造と無関係な輝度値的な差異に対してはロバストに評価できる指標です。

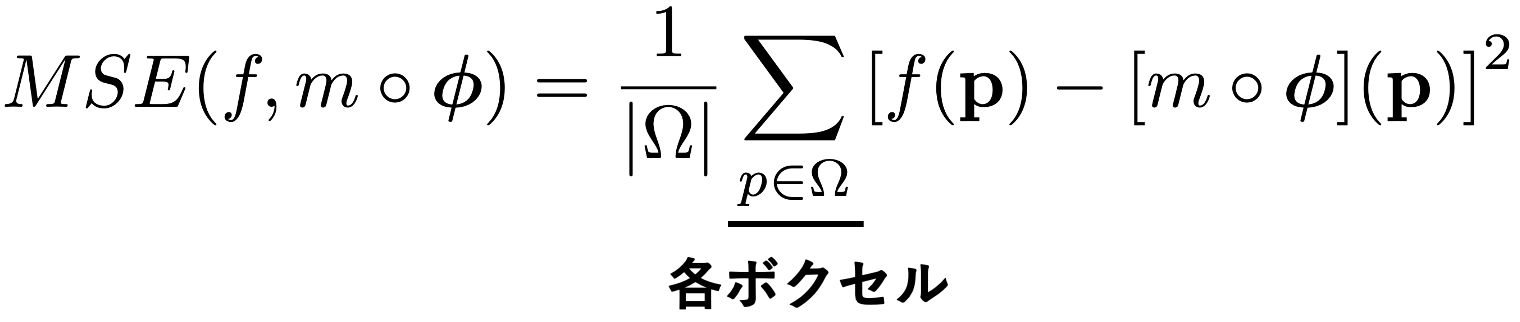

しかしこれだけでは外観を無理やり一致させる不自然なベクトルを出力しません。実世界の画像を対象としている限りは、ベクトルは局所的な部分では同じ大きさで同じ方向に流れるのが自然です。実験でもそのような正則化を行った方が精度高い事が確認されています。正則化項は次の式で表されます。uの勾配の大きさを損失とすることでベクトルが局所的に急激に変化することを抑えることができます。
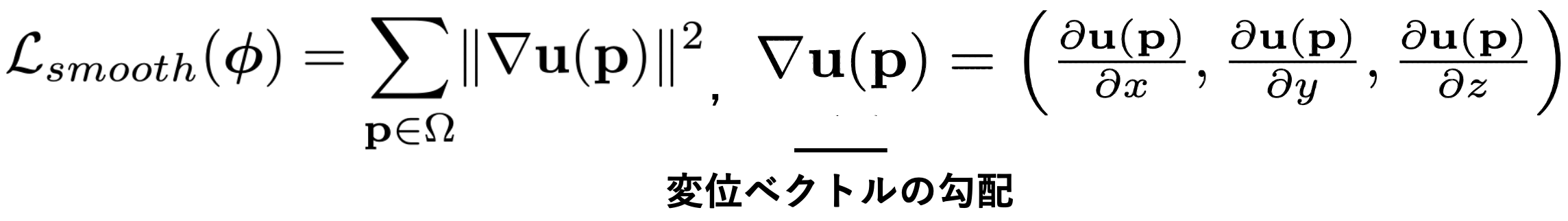
教師あり損失
解剖学的構造を表すセグメンテーションデータが存在する場合は、外観損失だけでなく構造の一致を損失に取ります。その際はセグメンテーションマスクのDice係数を損失として取ります。Dice係数は2つのマスク間の重なり具合を取る指標です。画像組にK個のセグメンテーションデータがある時の損失は次の様に表されます。
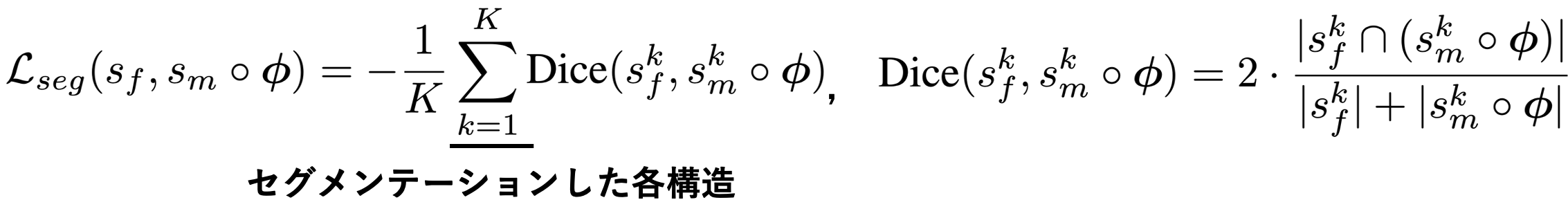
これを教師なし損失に重み付けて加算することで精度向上に繋げることができます。この時は制約項のλと教師あり損失のγの2つの重みをハイパーパラメータとして持ちます。
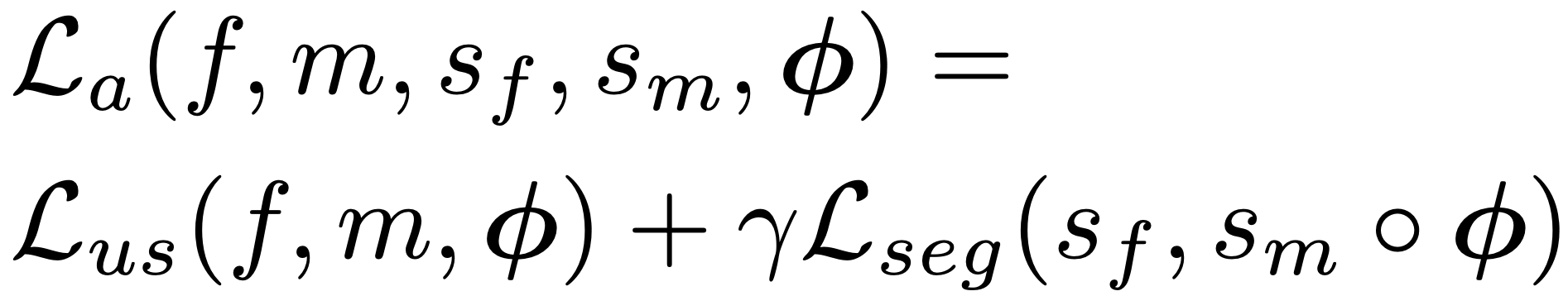
VoxelMorphはこのような構造と損失を取ることでグローバルな最適化を行います。
実験
実験ではVoxelMorphの精度検証を、先述した損失の選択や重みの様々な設定の下で行なっています。全ての実験で第一段階にアフィン変換を行い線形な変形を捉えている事を前提にしています。様々な分析を行なっていますがここでは代表的な実験のみを示します。
設定
比較手法
比較手法は2019年当時最先端だったSymmetric Normalization(SyN)とNiftyRegというDIRを行うフリーソフトを採用しています。SyNは画像間の相互相関を最大化させる変位場をオイラーラグランジュ方程式で求める手法のようです。NiftyRegは第一段階にアフィン変形を捉え、第二段階でFree-form-deformation(FFD)により非線形な変形を捉えるようです。
VoxelMorphはAdamを使用して学習させますが、バッチサイズを1としています。
データセット
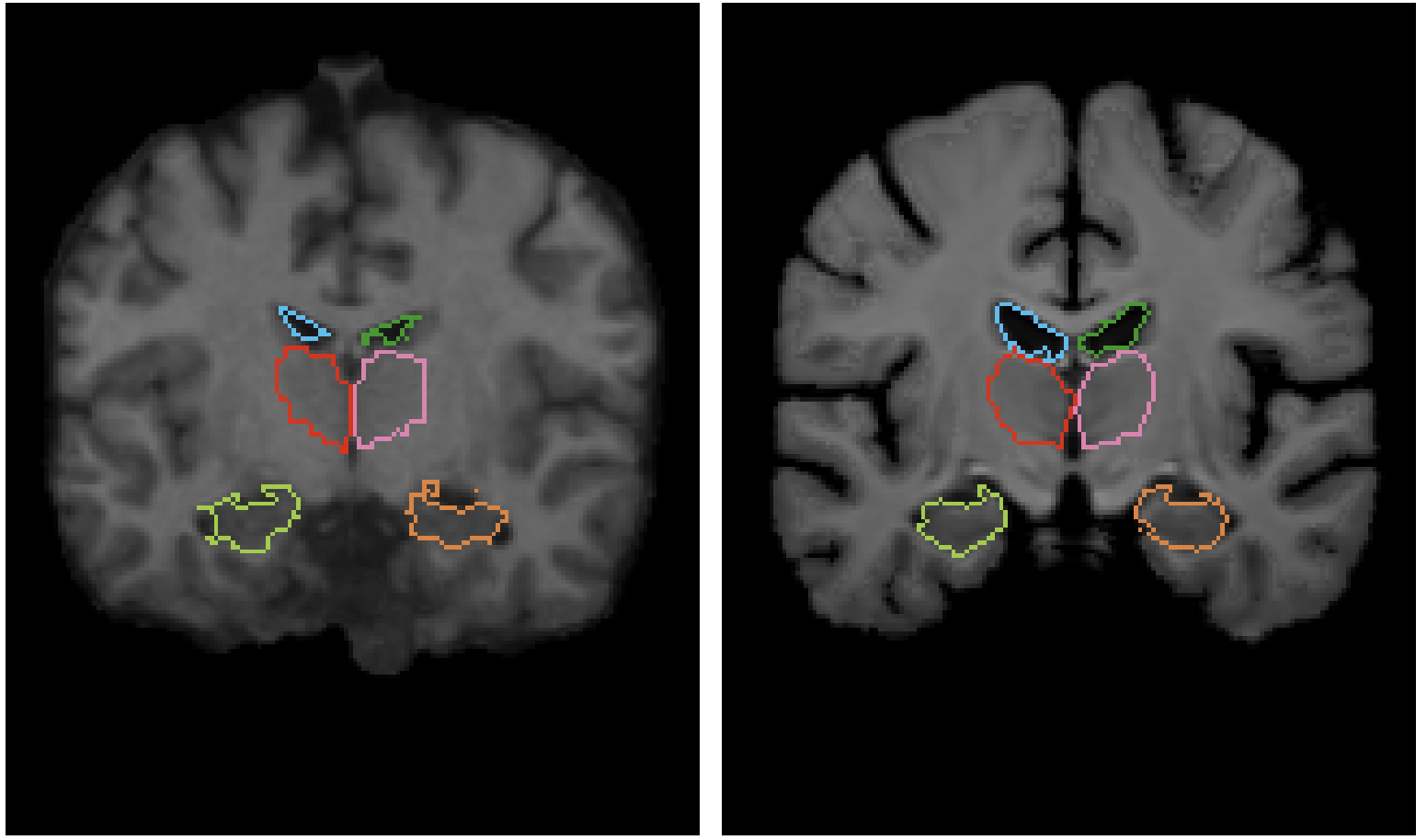
8つのデータセットから成る3,731枚の頭部MRI(T1強調)画像で実験を行なっています。補助データの有効性を確かめるため、各データセットにはFreeSurferというツールを用いてセグメンテーションデータを取得し(後述)、アフィン変換も適用しています。8つのうちBuckner40というデータセットだけは完全に未知且つ手動のセグメンテーションデータでの精度検証としてテストのみ用いられています。得られた30種類の解剖学的構造についてのセグメンテーションデータを用います。Train:Valid:Test=3231:250:250で分割されています。
評価指標
評価は上記で作成したセグメンテーションマップのDiceスコアで行っています。またそれとは別に自然なベクトルを生成できたか評価するためにヤコビ行列を用いています。ヤコビ行列が正である場合は微分同相とみなすことができ、つまり変位場が滑らかであることを証明できます。ここではヤコビ行列が0以下となるボクセルの数を数えることで、少ないほど良い変位場である評価指標として用います。ヤコビ行列は次の様に表されます。
![]()
教師なし損失の精度検証
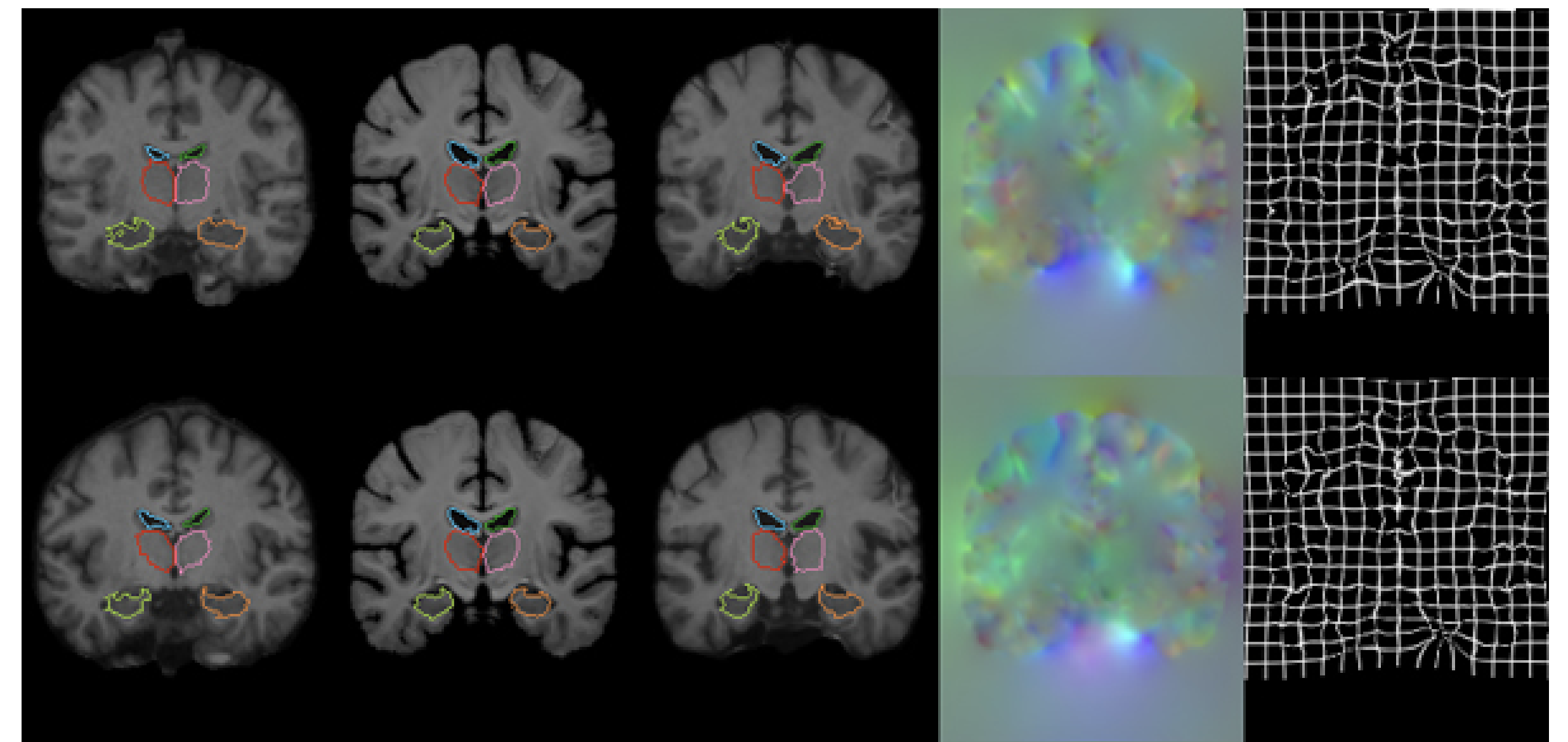
全データセットに対する結果を示します。括弧内は標準偏差です。上から順にアフィン変換のみ、既存手法(共にCCを使用)、VoxelMorph(CCとMSE)です。適用例を更に下図に示します。VoxelMorphはアフィン変換より精度を向上させており、SyNやNiftyRegと同等のDiceスコアを達成しています。その上でCPUの計算速度を見るとVoxelMorphが圧倒的に高速であることが分かります。VoxelMorphはSyNの約150倍、NiftyRegの約40倍の速度です。既存手法は画像組毎の最適化を行うため、データの変形の程度によって実行時間が大きく変動してしまうことが関係しています。対してVoxelMorphは学習時にグローバルな最適化をおこなっているため圧倒的に高速です。GPUバージョンについては非公開のため比較できなかったとのことです。

ヤコビ行列が0以下のボクセル数が示されていますが、適用結果を見ると正則化項がうまく働き滑らかな変位場を生成できていることが分かります。
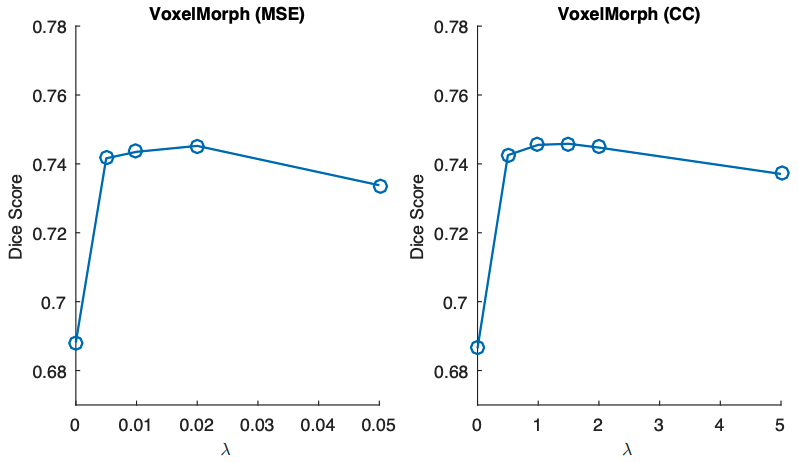
正則化項の重みλに対する感度分析
ここではλの値を変えた際のDice係数の変動を分析しています。まず分かるのは正則化があることで外観損失だけの場合(λ=0)よりも精度が向上することです。またその変動についても頑健性があり、λの選択に対しての感度が低いことがMSE、CC共に分かります。
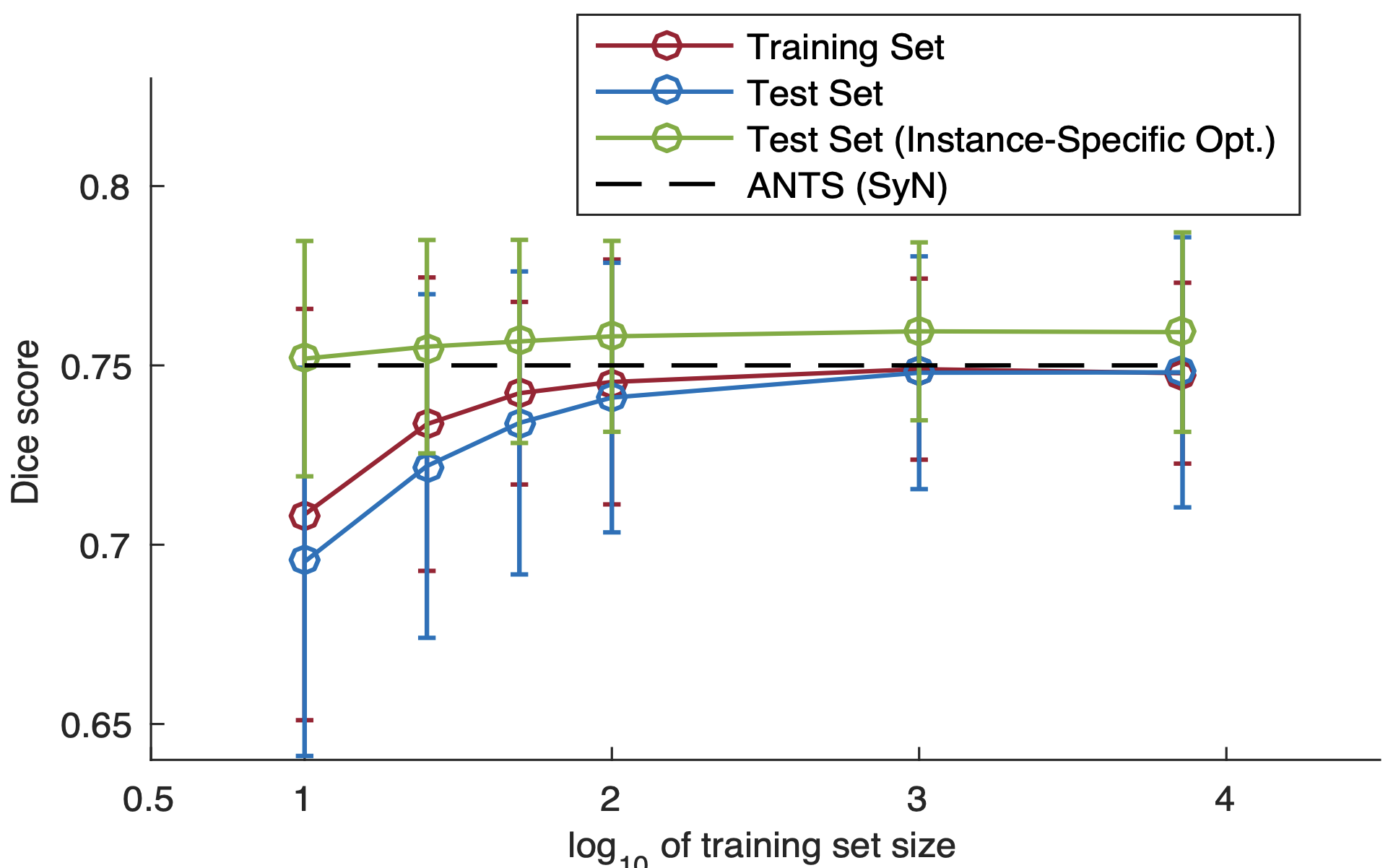
データセットの規模や個別最適化の分析
続いて最適化の際のデータセットの規模の影響です。1回のグローバルな最適化だけで済むとはいえ、あまりに大規模なデータセットが必要な場合には応用範囲が狭まってしまいます。そこでこの実験では学習に用いるデータを10,100,1000,10000と変化させた際の精度の変化を分析しています。表の横軸は常用対数です。比較として破線でSyNを示しています。データが10しかない場合は少なすぎて精度が出ていませんが、100組あればDice係数がそれ以上でほぼ変わらず同等の精度を出せることが分かります。また緑の線はテストデータに対して更に個別に学習させた際の精度を示しています。VoxelMorphのグローバルな最適化の後、従来のように個別に最適化させた場合は精度が更に向上することが分かります。この場合はデータセットの規模はあまり関係がありません。
教師あり損失の精度検証
続いて補助データを使用した教師あり損失を加えた場合の精度の比較です。 教師なしではMSE、CC共に同程度の精度だったため、ここではλ=0.02のMSEを用いています。補助となるセグメンテーションデータは4つのパターンを想定しています。セグメンテーションデータはアノテーションの負担が大きく、都合の良いデータが常に得られていることを想定するのは非現実的です。そこで作成した解剖学的セグメンテーション30種類のうち一部のみ得られている場合を3パターン、セグメンテーションが荒いデータを1パターン想定します。
- One Observed:「海馬、大脳皮質、大脳白質、脳室」のうち1種の構造のみ得られているデータ
- Half Observed:30種類の構造から15種類ランダムに得られているデータ
- All:全ての構造が得られているデータ
- Coarse Segmentation:30個の細かなアノテーションを白質、灰白質、脳脊髄液、脳幹の4つの荒いセグメンテーションに大別したデータ
1から3パターンではセグメンテーションの量の影響、4パターン目はセグメンテーションの荒さが及ぼす細かな構造の推定制度への影響を分析します。それぞれ教師あり損失の重みγを変化させています。1から3パターンではセグメンテーションデータが得られている構造をObserved、そうでない構造をUnobservedとしています。FreeSurfer(FS)でアノテーションした7つのデータセットに対する精度、手動でアノテーションしたBuckner40に対する精度を下図に示します。
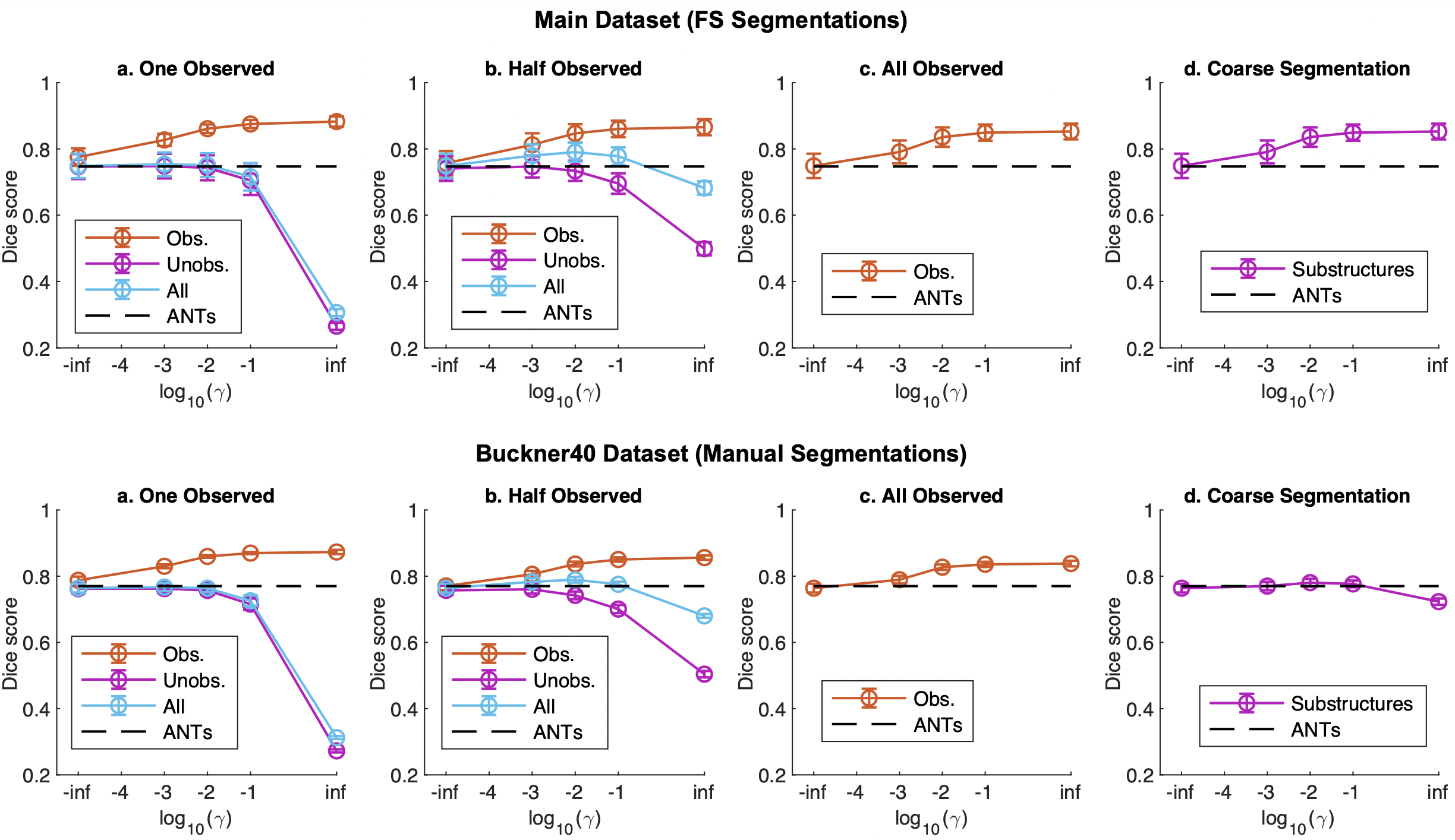 横軸は常用対数のため、-infは教師なし損失、infは教師あり損失のみを意味します。γが大きすぎるとObservedに過学習するためUnobservedの精度が低下してしまいますが、適度に調整すれば教師なし損失やANTs(SyN)を上回ることが分かります。全ての構造が得られているAll Observedではより高い精度が得られますが、特に重要なのは構造が得られていないUnobservedデータに対しても寄与があることです。Corase Segmentationでは粒度が荒いですが教師なしと比較して精度が高いことが分かります。Buckner40も同じような傾向がありますが、Coarse Segmentationについては元からDiceスコアは高いため上がり幅が小さくなってしまったようです。
横軸は常用対数のため、-infは教師なし損失、infは教師あり損失のみを意味します。γが大きすぎるとObservedに過学習するためUnobservedの精度が低下してしまいますが、適度に調整すれば教師なし損失やANTs(SyN)を上回ることが分かります。全ての構造が得られているAll Observedではより高い精度が得られますが、特に重要なのは構造が得られていないUnobservedデータに対しても寄与があることです。Corase Segmentationでは粒度が荒いですが教師なしと比較して精度が高いことが分かります。Buckner40も同じような傾向がありますが、Coarse Segmentationについては元からDiceスコアは高いため上がり幅が小さくなってしまったようです。
その他
他にもλとγを両立するパラメータの探索や部位毎の精度比較などを行なっています。興味のある方は論文を参照してみてください。
所感
外観損失は様々なものを試してみる価値がありそうです。SSIM Lossは輝度値・分散・構造の3つの視点で領域ベースに差異を捉えてくれるため、MSEとは違った挙動になりそうです。
個人的にアフィン変換に対する有効性が気になりました。一段階目にアフィン変換を適用した後の処理に注力していましたが、アフィン変換を適用せずend-to-endに処理をした際にどれほど有効かが気になります。手元でMNISTに適用してみましたが、かなり大きなアフィン変換にも対応できていました。
まとめ
UNetベースのDIRモデルVoxelMorphを解説しました。従来手法と同等の精度で高速に動作し、少ないデータセットで学習可能なVoxelMorphは柔軟性が高く、補助データで更なる精度向上が見込めます。また以下のことが主張されています。
- 実験では1種類の補助データのみを試したがモダリティが異なっている場合でも機能し、セグメンテーションではなく特徴点など様々な補助データを利用できる
- VoxelMorphの汎用性は高く、心臓MRIや肺CTなど他のレジストレーションにも有用である
このモデルは2019年度のものですが、最近VoxelMorph++という改良手法が提案されています。DIRではGANベースの手法も強いですが、処理の早さを考えるとまだ可能性のある実用的な手法ではないでしょうか。



この記事に関するカテゴリー






