遺伝的アルゴリズムを用いた、ブロックベースのCNNアーキテクチャ探索手法
3つの要点
✔️ CNNのアーキテクチャの設計は、多くのドメイン知識と計算資源を要する
✔️ CNNのアーキテクチャをブロックベースで探索することで計算資源を節約しつつ、自動で探索する手法を提案
✔️ 提案手法で探索したモデルと人間が手で設計したモデル、近年のアーキテクチャ自動探索アルゴリズムで探索されたモデルを、誤り率や必要な計算資源量で比較
A Self-Adaptive Mutation Neural Architecture Search Algorithm Based on Blocks
written by (Submitted on 21 July 2021)
Comments: IEEE Computational Intelligence Magazine.
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
CNNは、AIの分野で非常に大きな成功を収めたモデルです。しかし、その設計は容易とは言えません。というのも、CNNのアーキテクチャはその性能に大きく影響しますが、そのアーキテクチャを探索するには多くのドメイン知識と計算資源を必要するからです。ドメイン知識を必要とせずニューラルネットのアーキテクチャを探索する手法をNeural Architecture Search (NAS) といい、近年多くの研究がなされています。NASは、非常に多くの計算資源を要するという問題があり、それを解決することが近年のNAS研究の大きなトピックとなっています。
この論文では、計算資源の節約のため、ある程度CNNの構造をひとまとめにしたブロックという単位でアーキテクチャを探索しています。また、NAS手法の多くは強化学習を用いて探索していますが、計算資源節約を考え、独自の工夫をした遺伝的アルゴリズムを用いて探索を行っています。
実験では、提案手法で探索したモデル、人間が手で設計したモデル、近年のアーキテクチャ自動探索アルゴリズムで探索されたモデルの三種類を比較しています。比較において、単純に誤り率のみを比較しているのではなく、そのモデルを探索するのにかかった計算資源や、そのモデルのサイズ(パラメータ数)を比較しています。
Related work
本研究では、遺伝的アルゴリズムが用いられています。遺伝的アルゴリズムの基本の流れは次のようなものです。
- 現世代にN個の個体をランダムに生成
- 評価関数で、現世代の各個体の適応度(性能)をそれぞれ計算
- ある確率で次の三つの動作のどれかを行い、その結果を次世代に保存
- 個体を二つ選択し、交叉を行う
- 個体を一つ選択して突然変異を行う
- 個体を一つ選択してそのままコピーする
- 次世代の個体数がN個になるまで上記の操作を繰り返す
- 次世代の個数がN個になったら次世代の内容をすべて現世代に移す
- 2以降の動作を最大世代数繰り返し、最終世代の中で最も適応度が高い個体を解として出力
本研究では、突然変異の方法と、交叉の方法に独自の方法を用いています。
提案手法(SaMuNet)
ここからは、本研究で提案されている、"A self-adaptive mutation network (SaMuNet)" の詳細について説明します。
SaMuNetの基本の流れ
SaMuNetの基本の流れは、基本的な遺伝的アルゴリズムと同様で、以下のようになっています。
- 現世代にN個の個体をランダムに生成
- 評価関数により適応度を計算
- トーナメント選択で親を選択
- 交叉と突然変異で子を生成
- 3~4を子がN個になるまで繰り返す
- この世代の突然変異確率を更新する(Self-adaptive mutation)
- この世代を親世代にする
- 2~7を最大世代数まで繰り返す
- 最終的に得られた解をデコードし、CNNを取得
エンコーディング戦略
遺伝的アルゴリズムでは、各個体を遺伝子で表現します。探索する対象を遺伝子に変換する操作をエンコーディングといい、このエンコーディングの方法は非常に重要です。
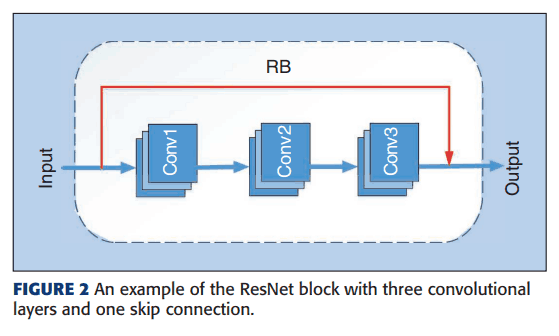
まず、CNNのアーキテクチャを表すため、ある程度の塊をブロックとして扱います。例えば、ResNet block (RB) は以下のようなものになります。
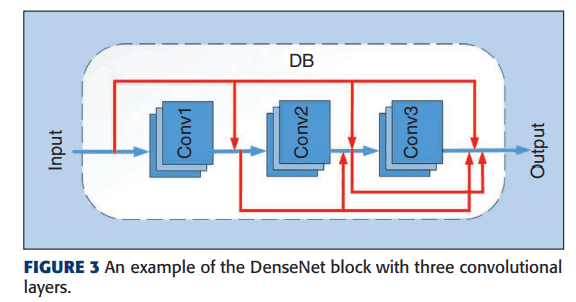
他には、DenseNet block (DB) があります。DBは以下のようなブロックです。
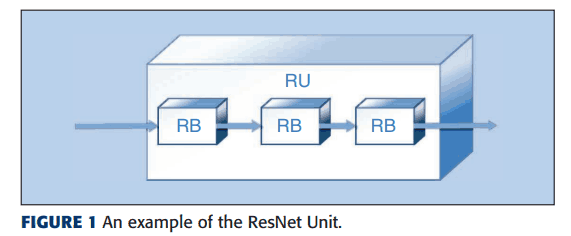
これらのブロックをある程度組み合わせたものをユニットと呼び、基本単位として扱います。ユニットの一つであるRUは、以下のようなものになります。
本研究では、CNNのアーキテクチャを表す基本単位として、このようなユニットを用います。ユニットには以下の三種類があります。
- ResNet Unit (RU)
- DenseNet Unit (DU)
- Pooling Unit (PU)
ResNet Unit (RU)
ResNet block (RB) の数を乱数を用いて決定します。また、各RBは少なくとも一つの3*3畳み込みカーネルを含みます。このようなRBを、Figure1のように接続してまとめたものをResNet Unitと呼びます。
DenseNet Unit (DU)
DenseNet block (DB) の数を乱数を用いて決定します。また、各DBは少なくとも一つの3*3畳み込みカーネルを含みます。このようなDBを、Figure1のように接続してまとめたものをDenseNet Unitと呼びます。ResNet Unit との違いは、スキップ接続の有無です。RUにはスキップ接続がありますが、DUにはありません。
Pooling Unit (PU)
Average pooling層とMax pooling層のいずれかのタイプのプーリング層を一つだけ含みます。
遺伝子の例
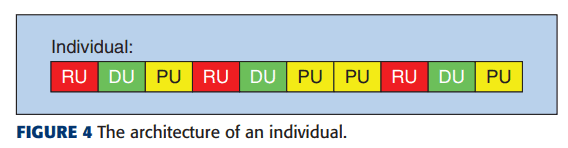
上記の基本単位(ユニット)を並べたシーケンスを以下のように個体として扱い、遺伝的アルゴリズムを実行します。
最初の世代の初期化
上の図のような遺伝子を、最初は乱数を用いて初期化します。各個体の長さは乱数によって求め、各ユニットをどこに配置するかも別の乱数を用いて決定します。ただし、個体がPUから始まるといきなり入力の情報の多くを落としてしまうことになるため、最初にPUが来ることを禁止しています。また、PUが連続し続けると出力サイズがその時点で1*1になってしまうため、そのようにならないように連続できる回数について閾値が設けられています。
各個体の評価方法
提案手法では、各個体をCNNアーキテクチャにデコードし、それを学習データと検証データで学習、テストを行っています。そのテストスコアをその個体の適応度としています。
交叉方法
提案手法では、親を選択するために二項対立戦略を用いています。この方法では、まず母集団からランダムに二つの個体を選び、そのうちの適合度の高い個体を親として選択し、交叉を行います。各個体の柔軟性を高めるため、固定長で符号化せず、可変長符号化を行います。すなわち、CNNアーキテクチャの深さが可変になるということです。このとき、交叉は以下のような一点交叉を用いて行います。
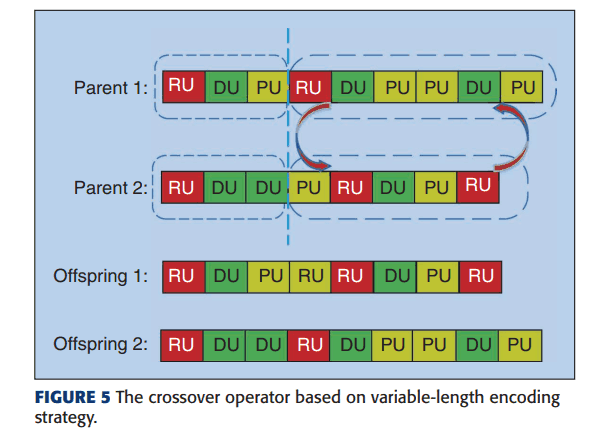
交叉後は入力チャンネルの数の調整と、ユニット番号の変更を行います。
突然変異の方法 (Self-Adaptive Mechanism)
提案手法では、一般的な遺伝的アルゴリズムにおける突然変異の部分に工夫を加えています。ここではその工夫点について説明します。
突然変異としては、追加、削除、置換の三種類を用い、この三つのどれかを突然変異の操作として実行します。追加とは個体の選択された位置にユニットを追加すること、削除とは個体の指定された位置にあるユニットを削除すること、置換とは個体の選択された位置にあるユニットをランダムに置き換えることを指します。
提案手法では、この三つの突然変異の操作からいいものを選択して実行します。具体的には、最初は等確率で三つの中から突然変異の操作を選択しますが、それぞれの突然変異後の個体の性能が親を上回った割合を用いて、次の世代での突然変異の操作の選択確率を変更します。より親を上回った操作が選択されやすいよう、確率を変更します。
次の世代の選択
提案手法では、次の世代の選択方法も一般的な遺伝的アルゴリズムに工夫を加えています。一般的には二項対立戦略を用いる場合、ランダムに選択された二つの個体を競わせ、性能が高いほうが次の世代に残されます。このようにすると、性能の高いもの同士が比較されてしまった場合に性能の高いものが次の世代に残ることができなかったり、性能の低いもの同士が比較された場合に性能の低いものが次の世代に残ってしまうという問題点があります。
これを解決するため提案手法では、乱数を生成してその数分の適応度上位の個体を次の世代に残します。その後、残りの個体については二項対立戦略を用いて次の世代に残す個体を決定します。このようにすることで、二項対立における問題点を解決しています。
実験
この論文では、分類の誤り率、パラメータ数(=モデルの大きさ)、アルゴリズム実行にかかる計算機資源(GPU/days)を用いてアルゴリズムの性能を評価します。
提案手法で探索されたモデルの性能
CIFAR10とCIFAR100でそれぞれの手法を比較した結果が以下のようになります。
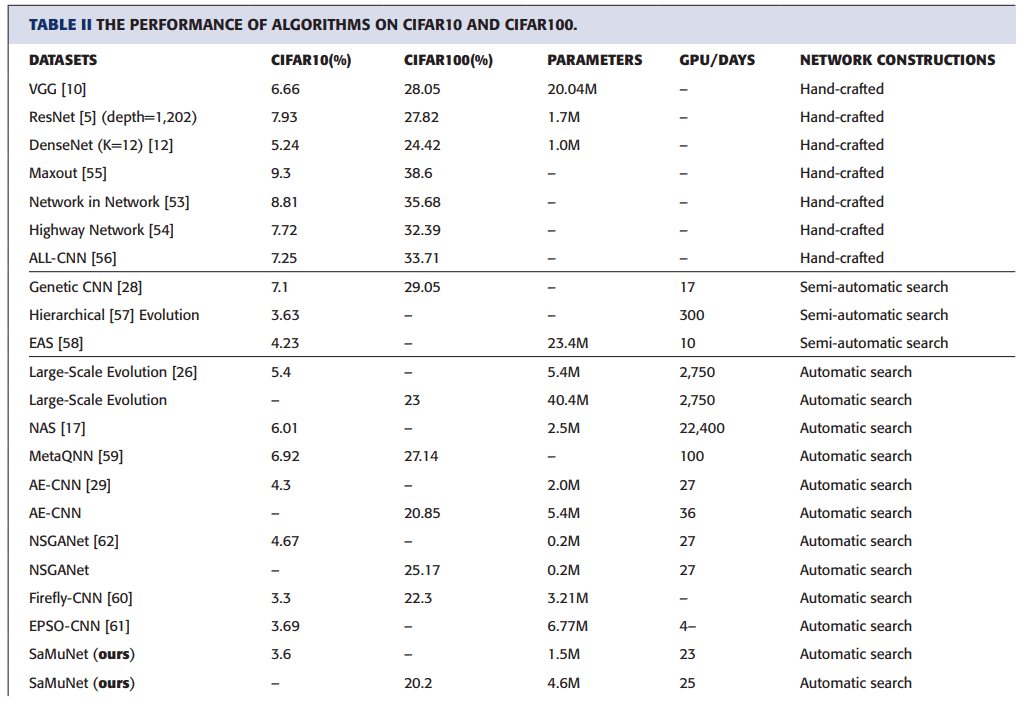
2,3列目はCIFAR10とCIFAR100での誤り率を示しています。4列目は最終的なモデルのサイズを示しており、5列目は各アルゴリズムで消費されたGPU/daysを示し、6列目はモデルの構成方法を示しています。
この表を見ると、ResNetとDenseNetを含む純粋なハンドメイドのモデルと比較して、CIFAR10におけるSaMuNetの分類精度は、Firefly-CNNより少し高い二番目に低い誤り率を達成していることが分かります。さらに、その時のモデルのサイズはFirefly-CNNよりもはるかに小さいことが分かります。GPU/daysも、ほかの自動探索アルゴリズムと比較して小さいことが分かります。
提案手法の工夫が有効かどうか
提案手法では、一般的な遺伝的アルゴリズムに、突然変異の選択手法の変更と、次世代の選択方法の変更を行いました。ここではその手法が有効であるかどうかを検証した結果を示します。
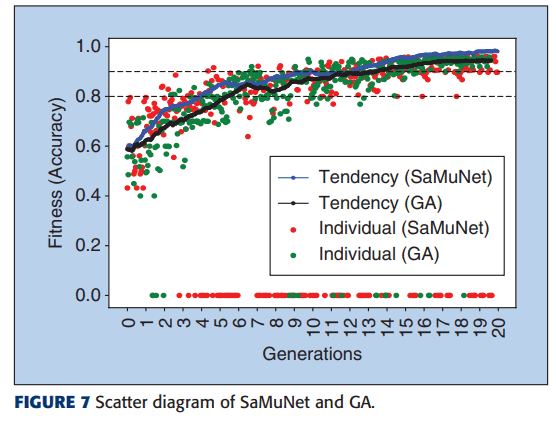
この図は、一般的な遺伝的アルゴリズム(GA)と提案手法で探索した時の探索結果のモデルの精度と、世代の関係をプロットしたものです。この図を見ると、一般的な遺伝的アルゴリズムよりも、提案手法の方が同じ世代において高い性能のモデルを探索することができていることが分かります。
まとめ
この論文では、NASにおける必要な計算資源の削減を目標として、遺伝的アルゴリズムを用いた探索と、探索空間をブロックベースにすることで小さくするという工夫を行い、必要な計算資源の削減を達成しつつ、比較的高い分類精度を持つモデルを探索することに成功しました。著者らはさらに計算資源の削減を目標としている旨を最後に述べていたので、今後どれくらい削減できるか非常に興味深いです。






この記事に関するカテゴリー






