言語データセットには多量の重複文が潜んでいる!
3つの要点
✔️ 現在のデータセットには、学習データとテストデータに重複がある
✔️ モデルが重複データをそのまま記憶してしまう
✔️ 重複データを削除する事でモデルも良くなる
Deduplicating Training Data Makes Language Models Bette
written by Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, Nicholas Carlini
(Submitted on 14 Jul 2021)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
はじめに
ここ数年で言語データセットの大規模化が進みましたが、人手でのレビューがされていないため、品質が低くなって来ている事が指摘されています。幾つかの一般的な言語データセットには、重複した例と、長く繰り返される文字列が多数含まれている事が分かっています。
ナイーブな重複排除は簡単ですが、大規模に完全な重複排除を実行することは、計算が難しく、高度な技術が必要です。(そして、今回取り上げるようなデータセットでは、既に何らかのナイーブな方法での重複排除は実行されています)
現在のデータセットには学習データとテストデータに重複があり、学習モデルの精度が過大評価されている疑いがあります。また学習モデルが、データセットに頻出する文をそのまま記憶し、出力する事も確認されています。
この研究では、重複したデータを検出して削除するための2つの手法を提案し、一般的な言語データセット(C4、Wiki-40B、LM1B)の重複コンテンツを調査します。
提案手法
重複する文を見つける最も簡単な方法は、全てのペアで文字列照合を実行する事ですが、計算量の観点からお勧め出来ません。その為2つの補完的な方法を紹介します。
まずsuffix arrayを使用して、重複する部分文字列が複数の例で逐語的に発生する場合、それらをデータセットから削除します。
次にMinHashを使用します。これは、コーパス内の例のすべてのペア間のn-gramの類似性を推定するための効率的なアルゴリズムであり、他の例とn-gramの重複が多い場合は、データセットから例全体を削除します。
ExactSubstr
人間の言語は多様であるため、一方の表現が他方からコピーしたか、両方が共有ソースから引用しない限り、同じ情報が複数の文書で同一に表現される事はめったにありません。完全な部分文字列の一致を見つければこのような重複は削除出来ます。このアプローチをExactSubstrと呼びます。
suffix arrayは部分文字列クエリの効率的な計算を可能にし、線形時間で重複したトレーニング例を特定することを可能にします。効率的なTF-IDF計算や文書クラスタリング等の自然言語処理タスクで広く利用されています。
繰り返される全ての文字列を見つけるには、suffix arrayを最初から最後まで線形にスキャンして、シーケンスを探す必要があります。閾値を超える長さの共通prefixを持つ文字列を記録します。このアルゴリズムは並列実行可能であるため、データセットを効率的に処理できます。今回は一致する部分文字列の閾値として50トークンに設定します。
NearDup
この方法はNearDupと呼ばれ、特にWeb文書の場合、テンプレート部分が同一であるという非常に一般的なケースを処理するため、おおよその重複削除を実行します。
MinHashは、大規模な重複削除タスクで広く用いられる近似マッチングアルゴリズムです。文書のn-gramのjaccard係数が十分に大きい場合、文書はほぼ一致している可能性が高いです。2つの文書が一致すると見なされた場合にその間に辺を作成し、グラフにします。こうして、類似した文書のクラスターを構築していきます。
ExactSubstrとNearDupで検出した重複の割合を示します。
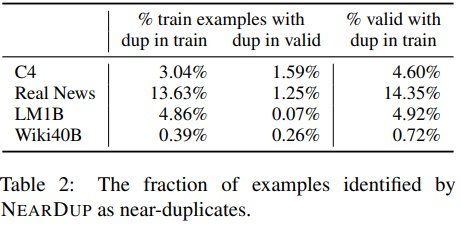
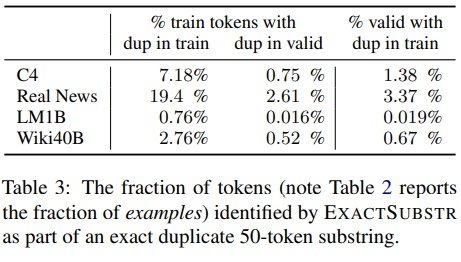
ExactSubstrを使用すると、平均して、NearDupを使用した場合よりも多くのコンテンツが削除されます。例外はLM1Bで、ExactSubstrはNearDupの8分の1のデータを削除します。調査の結果、これはLM1Bドキュメントが大幅に短い事が原因だと分かりました。
50トークン未満の文は、シーケンス全体が一致したとしても、ExactSubstrでは一致と見なされません。NearDupとExactSubstrの両方は同じコンテンツを削除する事があります。NearDupがC4から削除する学習データの77%には、ExactSubstrによって検出された長さ50以上の一致があります。
RealNewsとC4の作成者は、データセットの構築中に重複削除を明示的に試みましたが、インターネット上で見られる様な微妙なタイプの重複文字列を捉えるには手法が不十分でした。
C4およびWiki-40Bでは、ほぼ重複していると識別されたテキストの多くが自動的に生成されていると思われます。場所、会社、製品、日付などの名詞を除いて、テキストは同じです。これらの例は一度に数語だけ異なることが多いため、完全な文字列照合に依存する重複削除戦略では、一致を識別できません。
ニュースサイトから派生したRealNewsとLM1Bの場合、同じニュースがわずかに異なるフォーマットで複数のニュースサイトに表示されるため、多くの重複が発生する事が分かります。
モデル学習への影響
15億パラメータを持つXLモデルで、それぞれC4-Original、C4-NearDup、C4-ExactSubstrデータでトレーニングしました。C4 validation セット等、ほぼ重複が無いデータの場合は、全てのモデルが同等の複雑さを持ちます。
ただし、重複削除されたデータで学習されたモデルは、元のデータで学習されたモデルよりも、かなり高い複雑さを持っています。ExactSubstrは、NearDupよりも大きなperplexity をの差をもたらします。この傾向は、XLサイズのモデルにも当てはまります。
これはExactSubstrにより、学習セットでのモデルの過剰適合が最も少なくなることを示唆している可能性がありますが、これらの手法は両方とも別々の閾値を使用しており、閾値の選択が異なると結果が変わる可能性があることに注意してください。
重複削除されたデータセットは小さいため、学習が高速であるにもかかわらず、重複削除はモデルの複雑さを損なうことはなく、場合によっては改善されます。 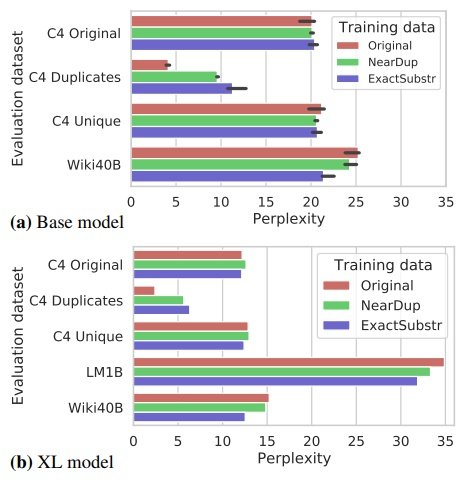
テキスト生成
データ重複は、学習モデルを特定のタイプの例に偏らせる効果があります。これにより、生成された文章が学習データからコピーされる可能性が高くなります。
最初に、モデルがプロンプトシーケンスなしでテキストを生成した場合の記憶傾向を評価します。100000個の例を生成し、その長さは最大512トークンです。
XL-Originalでは、生成されたトークンの1%以上が、記憶されたサブシーケンスに含まれます。これは、XL-ExactSubstrまたはXL-NearDupよりも10倍多くの暗記です。
まとめ
今回は英語のみを対象とましたが、他の言語でも同様の問題はあると考えられます。最近の研究では、問題のあるデータセットから発生する可能性がある潜在的な危害にも注目を当てています。しかしこの研究は、一般的なデータセット内の重複コンテンツの量、学習済みモデルの複雑さに対する重複削除の影響、重複削除による学習済みモデルの記憶コンテンツの削減に焦点を合わせています。重複削除によって削除されたり、記憶されたりするデータの性質には焦点を当てていません。
暗記はプライバシーに重大な影響を与える可能性があるため、将来の作業にとって重要なテーマです。重複削除は、パスワードや医療記録など使用してはならないプライバシー保護データを削除するのにも役には立ちません。
モデルが記憶した文章は多くが無害と考えられましたが、この研究の範囲を超えているため、そのリスクを体系的には評価していません。
今のところ重複削除は利点のみを確認していて、悪影響については調査していません。一部の言語タスクでは、文書の取得や本の質問応答など、明示的に暗記が必要です。
暗記が言語モデルに望ましい特性であるかそうでないかは、暗記されたテキストの性質とアプリケーションの両方に依存します。用途に応じて特定の文章を記憶したり忘れたりする技術を開発することは、有望な将来の研究です。
宣伝
cvpaper.challenge主催でComputer Visionの分野動向調査,国際発展に関して議論を行うシンポジウム(CCC2021)を開催します.
世界で活躍している研究者が良い研究を行うための講演や議論が聴ける貴重な機会が無料なので,みなさん貴重な機会を逃さないように!!




この記事に関するカテゴリー






