マイクロソフトの強力なChatBOT、DialoGPTの紹介
3つの要点
✔️ 人間らしい会話を生成するchatBOT
✔️ Redditから約20億語の会話を集めた大規模なデータセットを使用
✔️ 自動評価と人間評価の両方で最先端の性能を発揮
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
written by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan
(Submitted on 1 Nov 2019 (v1), last revised 2 May 2020 (this version, v3))
Comments: Accepted by ACL 2020 system demonstration.
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG)
code:
はじめに
自然言語処理(NLP)の最もエキサイティングな使用例の一つがチャットボットです。チャットボットは、すでに顧客サービスのタスクに有用です。これらのチャットボットは単純なので、見知らぬ質問には簡単に混乱してしまいます。そのため、企業や業務に合わせて設計する必要があり、そのためにはコストがかかります。その場合でも、堅牢性は保証されません。GPT-2のように大規模なコーパスで学習されたトランスフォーマーは、内容の濃い流暢なテキストを生成することができます。このような大規模な言語モデルを用いれば、見知らぬ質問にも対応できる、よりロバストなチャットボットを作ることができるのではないか。

本論文では、会話型の神経応答システムの課題を解決するためにGPT-2を拡張しました。モデルはDialoGPTと呼ばれ、Redditから抽出した対話セッションの大規模なコーパスで学習されました。DialoGPTは、自動評価と人間評価の両方で最先端の性能を達成しました。DialoGPTが生成する応答は多様で、クエリに関連しています。
手法
Redditデータセット
モデルの学習には、Redditから抽出したディスカッションセッションを使用します。これは2005年から2017年までのセッションになります。Redditでは、これらのディスカッションセッションをツリーの形で整理しています。議論のテーマや質問がツリーのルートとなり、各返信がツリーの新しいブランチを形成しています。ルートからリーフへの各パスは学習インスタンスとして扱われます。抽出されたデータは、攻撃的な言葉、反復的な言葉、非常に長い/非常に短いシーケンスを除去するために厳密にフィルタリングされます。その結果、147,116,725個のダイアログインスタンス、18億語のデータが得られました。
モデル
DialoGPTは、OpenAIのGPT-2をベースにしています。GPT-2は、マスクされた多頭の自己注目層のスタックで構成された変換モデルであり、ウェブテキストの大規模なコーパスで学習されています。まず、すべてのダイアログを長いテキスト列x1,x1....xNに連結し、最後に特別なエンドオブシーケンストークンを入れます。ソース文をS = x1,x2,...xm、ターゲット文をT = xm+1,xm+2...xNとします。条件付き確率P(T|S)は次のように与えられます。

チャットボットモデルは、当たり障りのない、情報量の少ない、無関係な回答を生成しがちです。この問題を解決するために、最大相互情報量のスコアリング関数を実装しています。事前に学習させたモデルを用いて、回答からソース文を予測しますP(Source|Response)。この尤度を最大化することで、当たり障りのない回答や情報量の少ない回答にペナルティを与えます。
実験と評価
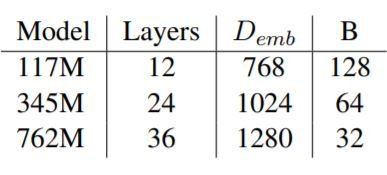
3種類のモデルをそれぞれ50,257の語彙サイズで学習しました。小規模なモデルと中規模なモデルは5エポック、大規模なモデルは3エポックで学習しました。
DSTC-7(Dialog System Technology Challenges-7 track)データセットでモデルを評価しました。このデータセットは、最初に定義されていないゴールに対して人間のような対話を行うモデルの能力をテストするものです。DSTC-7での会話は、チケットの予約や座席の予約のようなゴール指向の対話とは異なります。またモデルと、Microsoftのコグニティブサービスとして実運用されているPersonalityChatモデルを比較します。その結果を下の表に示します。
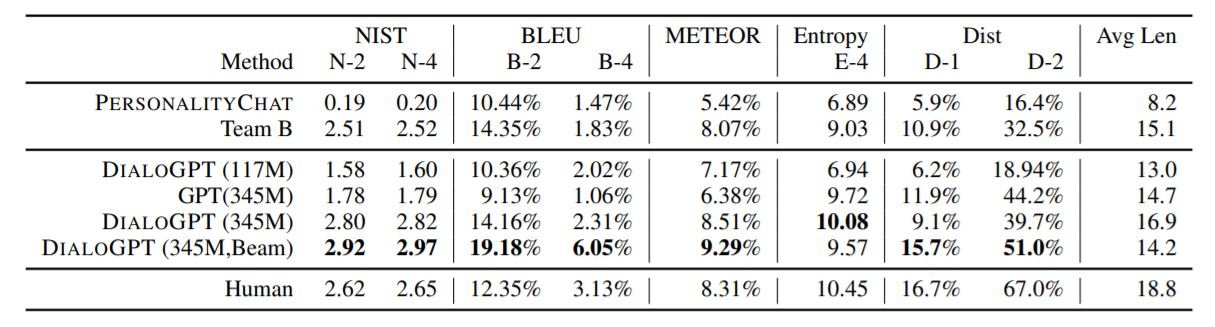
ビームサーチ(ビーム幅10)を用いた345Mのパラメータを持つDialoGPTが、他のモデルよりも優れた結果を示しています。以下に、私たちのモデルが生成した応答のサンプルをいくつか示します。


まとめ
DialoGPTは、強力なニューラル会話システムです。インターネット(Reddit)からの情報をもとに学習されているため、非倫理的、攻撃的、または偏った回答を制限しようと努力しているにもかかわらず、そのような回答を出す傾向があります。DialoGPTの目的は、チャットボットのパフォーマンスを向上させるだけでなく、研究者に、チャットボットからこのような偏りや非倫理的な回答を排除するための学習の場を提供することにもつながります。DialoGPTは人間よりも良いスコアを獲得していますが、DialoGPTが人間よりも良い会話をしていることを示すものではありません。人間の会話の不確実性に対して、まだ十分なロバスト性を持っていません。このリンクからチャットボットを自分で試すことができます。
レシピ
AxrossレシピにDialoGPTの開発レシピが公開されています。




この記事に関するカテゴリー






