
ByteTrack+外観特徴が最強:SMILETrack
3つの要点
✔️ ByteTrackをベースに外観特徴を考慮した追尾を実現
✔️ Attentionをベースに同一クラスの個体を頑健に識別する機構を提案
✔️ オクルージョンやモーションブラーに頑健なゲート関数を提案
SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking
written by Yu-Hsiang Wang, Jun-Wei Hsieh, Ping-Yang Chen, Ming-Ching Chang
(Submitted on 16 Nov 2022 (v1), last revised 17 Nov 2022 (this version, v2))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
やはりByteTrackにも外観特徴は必要でした!今回紹介するのは物体追尾のSoTAモデルSMILETrackです。動き情報(IoU)のみで関連付けを行うByteTrackに懐疑的でしたが、やはり外観特徴を使った方が良いとする手法が提案されました。
物体追尾は、検出器をベースに各フレーム間の検出結果を関連づけるSeparate Detection and Embedding model (SDE)と検出から追尾まで1つのモデルで行うJoint Detection and Embedding model (JDE)に分かれます。SDEは検出は検出、追尾は追尾とモデルを分けて最適化ができるため精度が高い傾向があります。一方で別々のモデルを用いるためリアルタイムな推定に課題があります。
JDEは一度の推定で検出と追尾を同時に出力できるためリアルタイムな推定が期待できますが、学習が競合してしまうため精度低下につながります。提案手法SMILETrackはSDEの手法です。動き情報のみを利用してSoTAを達成したByteTrackのアプローチを引き継ぎながら、Attentionベースの外観特徴抽出器を提案し、MOT17,MOT20でSoTAを達成しました。
SMILETtackの主な貢献は次の通りです。
- Attentionを用いて検出された個体間を明確に区別する外観特徴抽出器Similarity Learning Module(SLM)を提案した
- ByteTrackの頑健性の低さを指摘し、頑健な外観情報を加えた関連付けを実現するSimilarity Matching Cascade(SMC)を提案した
- 外観情報と動き情報を制御するゲート関数によりオクルージョンやモーションブラーに頑健な関連付けを実現した
それではSMILETrackを見ていきましょう。
ByteTrack
追尾とは前フレームまでの追尾と現在のフレームで検出された物体を関連づけることです。通常は、動き予測に基づく位置情報と物体の外観情報の2つを利用して関連付けを行います。一方でByteTrackは動き情報のみでSoTAを達成しました。外観特徴が有用でない場合に精度を悪化させる可能性があることを理由に動き情報のみを用いており、検出の信頼度が高い物体だけで関連付けを行った後と信頼度が低い物体の関連付けを行うというシンプルな2段階の関連付けでMOT17,MOT20でSoTAを達成しました。
しかし本論文は外観情報を用いないByteTrackの脆弱性を指摘しています。動き情報のみで高精度を達成できたのはMOTChallengeの動きが単純だったためであり、複雑な動きでは精度が下がることや外観情報がないためIDスイッチにも対応できないことを指摘しています。
SMILETrack
上記を理由にSMILETrackはByteTrackと外観特徴抽出の双方の利点を組み合わせます。検出の信頼度を用いた二段階の関連付けにAttentionを用いた頑健な外観情報を考慮させることで高精度な追尾を実現します。全体像は下図の通りです。
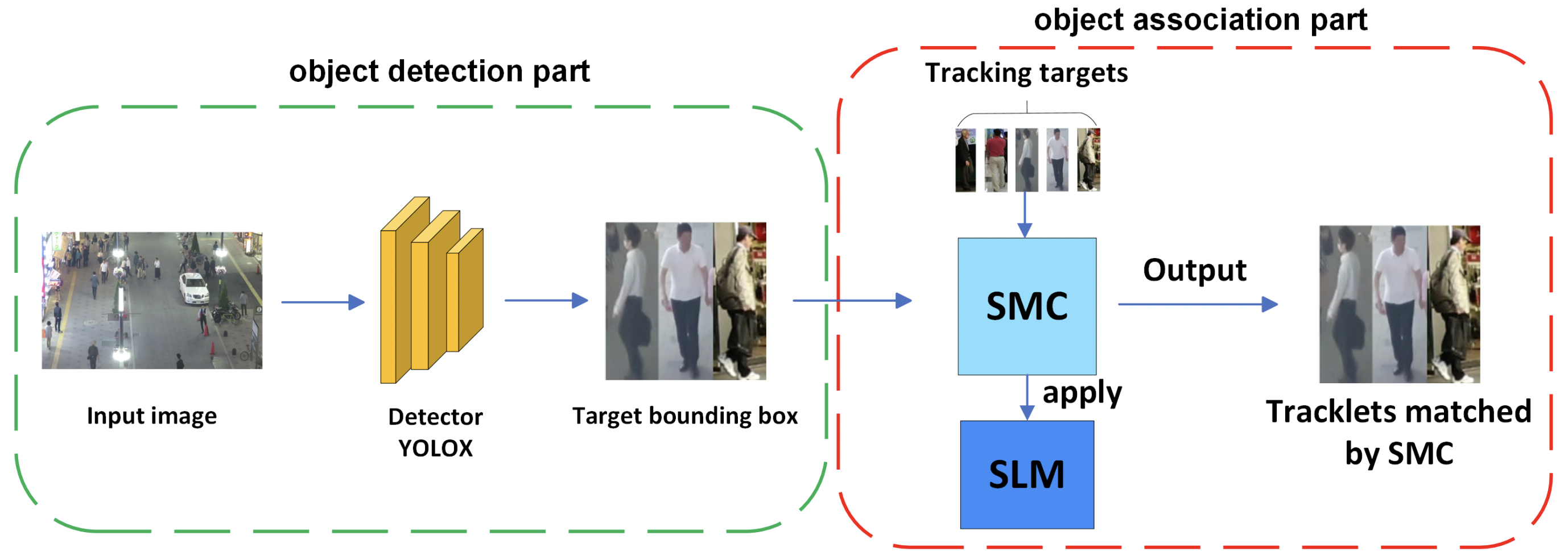
Similarity Learning Module(SLM)
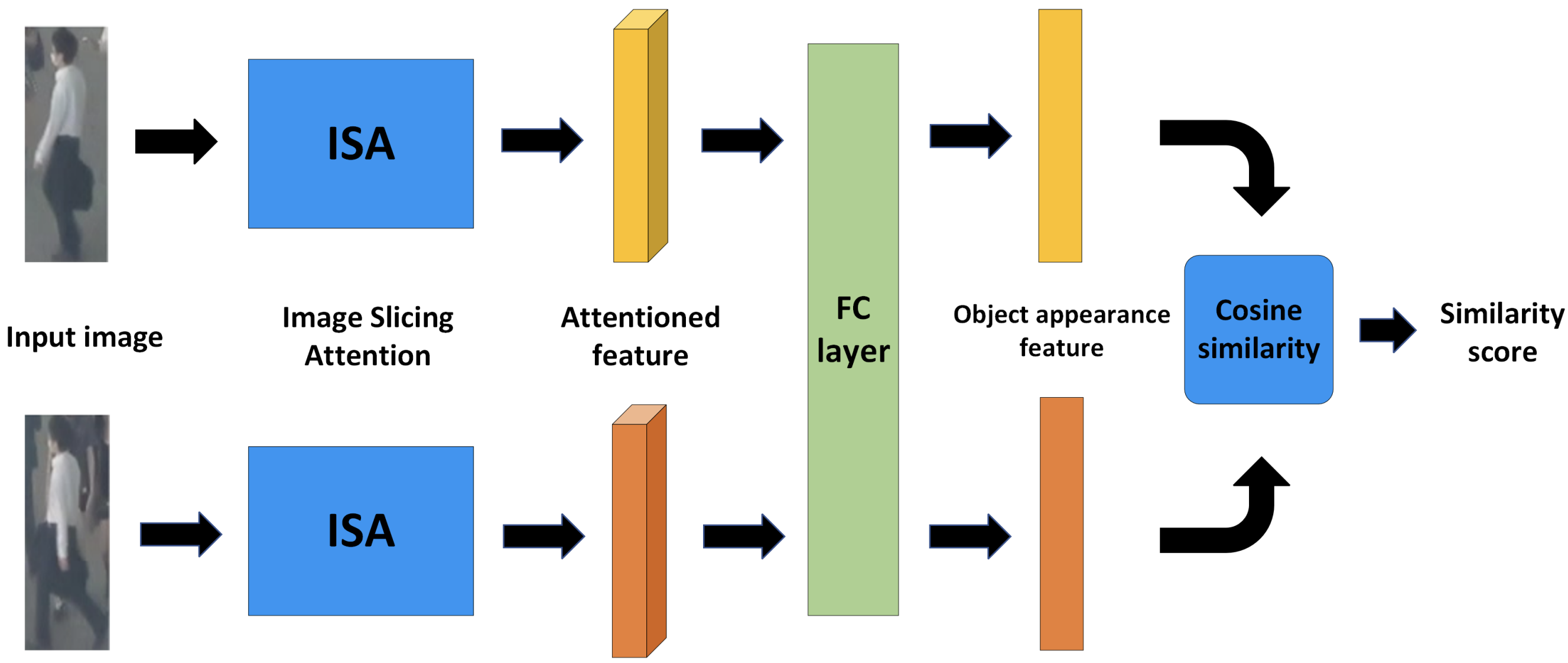
追尾で扱う物体の外観特徴は検出よりもシビアなものが必要となります。検出では異なるクラス間を識別する高レベルな特徴が重要ですが、追尾では同一クラス内の異なる個体を識別する低レベルな特徴が重要です。本論文はImage Slicing Attention(ISA) Blockで構成されるSimilarity Learning Module(SLM)という外観特徴抽出器を提案し、より識別に適した個体毎の特徴を柔軟に抽出します。
SLMは下図のシャムネットワークの機構を持ち、検出された物体間の類似度を学習・評価します。目的は同じ個体(個人)には高い類似度を与え、異なる個体には低い類似度を与えることです。ISAで抽出した個体毎の特徴が全結合層で統合され、外観特徴が得られます。その間のコサイン類似度を算出することで関連付けのためのコストが得られます。
ISAブロックは検出された物体を4分割のスライス画像にし、その間の関連性をAttentionで抽出します。まず入力を固定サイズにリサイズしResNet-18に入力します。得られた特徴マップを4分割しスライス画像とします。分割した4つの位置は線形射影したQ,K,Vに埋め込み、Q-K-V attentionに入力します。
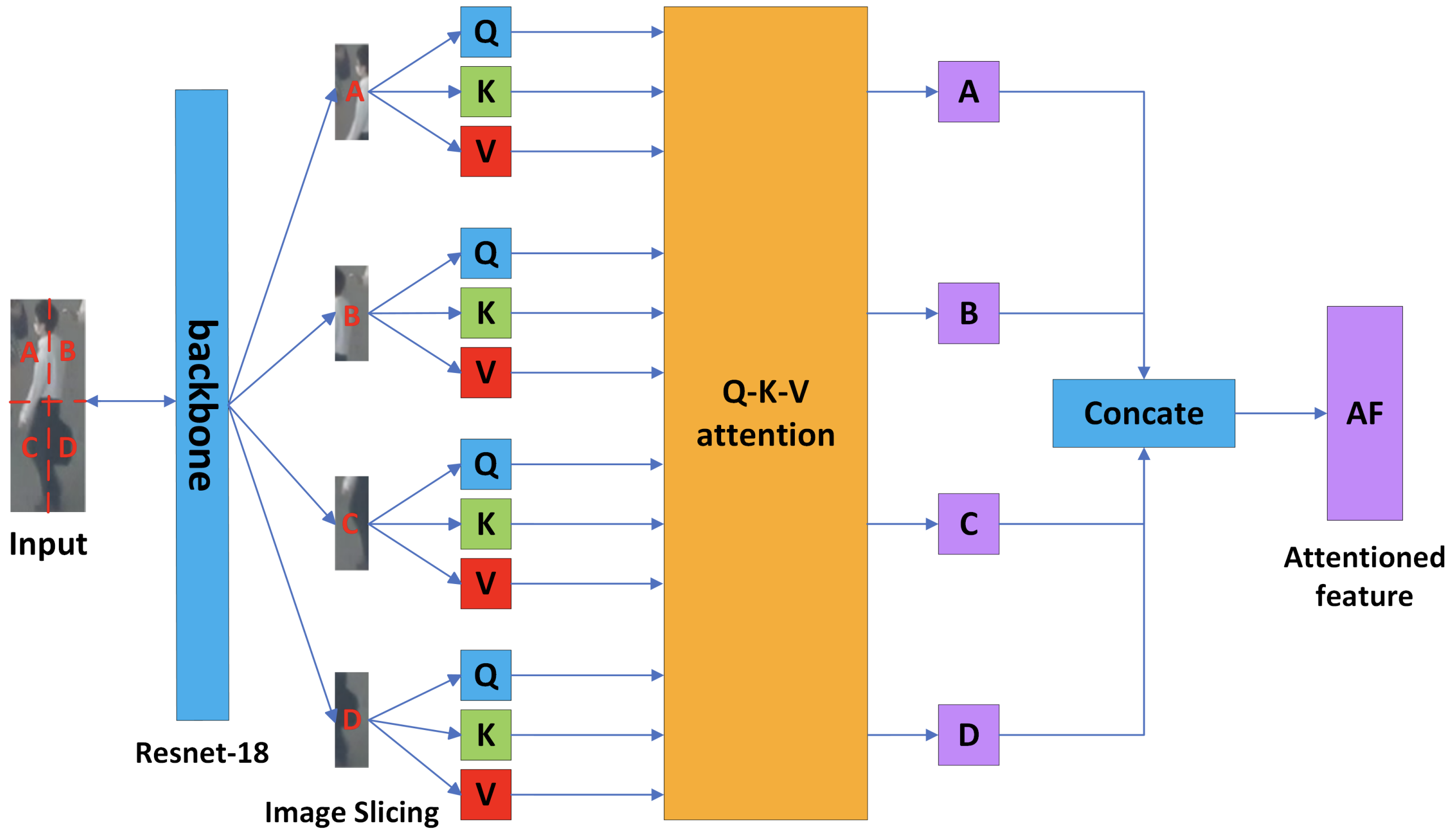
Q-K-V attentionブロックはスライス間のSelf-AttentionとCross-Attentionを算出します。得られたスライスの特徴を最後に結合することで検出物体の特徴量を得ることができます。このようなAttentionをベースとした信頼性の高い特徴で類似性を評価することで、同一クラスの異なる物体を高精度に識別可能な機構を実現します。
%2BCA(Q_%7BS1%7D%2CK_%7BS2%7D%2CV_%7BS2%7D)%0A%20%20%5C%5C%26%26%2BCA(Q_%7BS1%7D%2CK_%7BS3%7D%2CV_%7BS3%7D)%2BCA(Q_%7BS1%7D%2CK_%7BS4%7D%2CV_%7BS4%7D)%0A%5Cend%7Beqnarray*%7D&f=c&r=300&m=p&b=f&k=f)
(SMC)
SMCは得られた外観情報(SLM)とカルマンフィルタを用いた動き情報(IoU)を用いて関連付けを行います。下図が全体像です。水色で示されているFirst Association, Second AssociationがByteTrackにもある二段階の関連付けです。
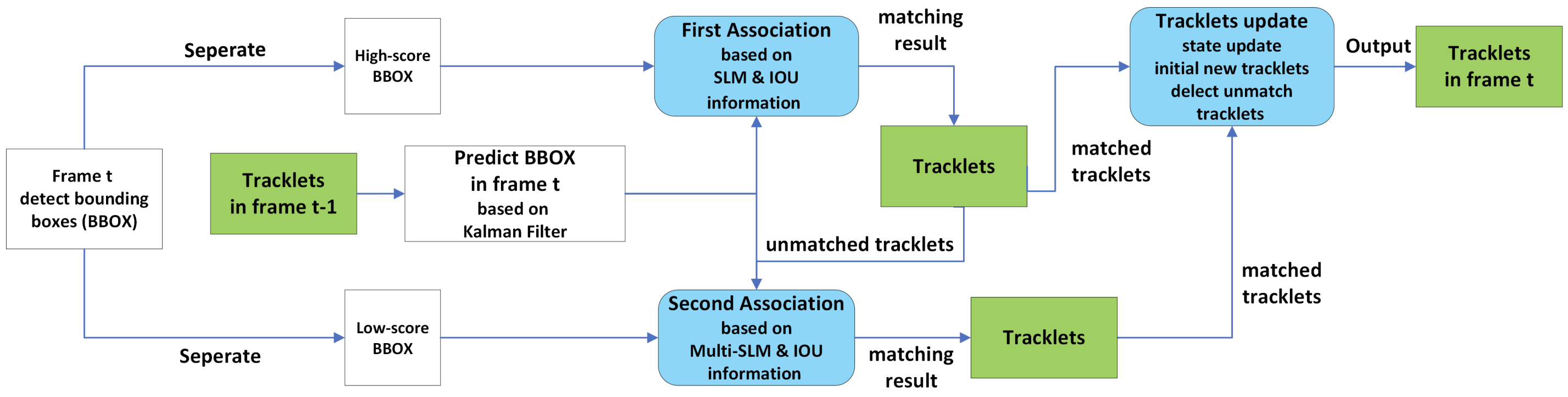
まず検出器で現在のフレームtの検出結果(BBOX)を信頼度に従って3つに分けます。まず信頼度0.1を下回った検出は背景やノイズと見做し関連付けには用いません。それ以上の信頼度の検出は閾値thresで二分します。BBOXを信頼度の低い順に並べた上で、前半半分のBBOXの信頼度の平均をthresとします。この値より高いBBOXをHigh-score BBOXに、低いBBOXをLow-score BBOXに分類します。
・ステージ1
ステージ1ではHigh-score BBOXを優先して関連付けに用います。t-1フレームまでの追尾結果(tracklet)とHigh-score BBOXを外観情報(SLM)・位置情報(IoU)で結びつけます。これにより質の高い情報のみで信頼性の高い追尾が期待できます。
・ステージ2
ステージ1ではステージ2で結び付けられなかったtrackletをLow-score BBOXと関連付けます。ただここではSLMに少し変更を加えたMulti-template-SLMを用います。理由は信頼度の低い検出に対応するためです。
信頼度の低い検出はオクルージョンやモーションブラーなどで特徴抽出が難しいことが考えられます。そのためtracklet側は1つのフレームのみを用いるのではなく追尾した複数のフレームを用います。各フレームのBBOXを特徴バンクとして保持しておき、それぞれLow-score BBOXとSLMに入力し類似度を得ます。この時類似度の最大値を最終的な外観情報のコストに用います。これを本論文ではMulti-template-SLMと表現します。
・ゲート関数
第一・第二段階ともに関連付けの際にゲート関数というものを用います。これは外観情報と動き情報の制御を行うための機構です。一般的な手法では外観情報のコストとIoUのコストを均等に重みづけています。下の式におけるα=0.5です。
![]()
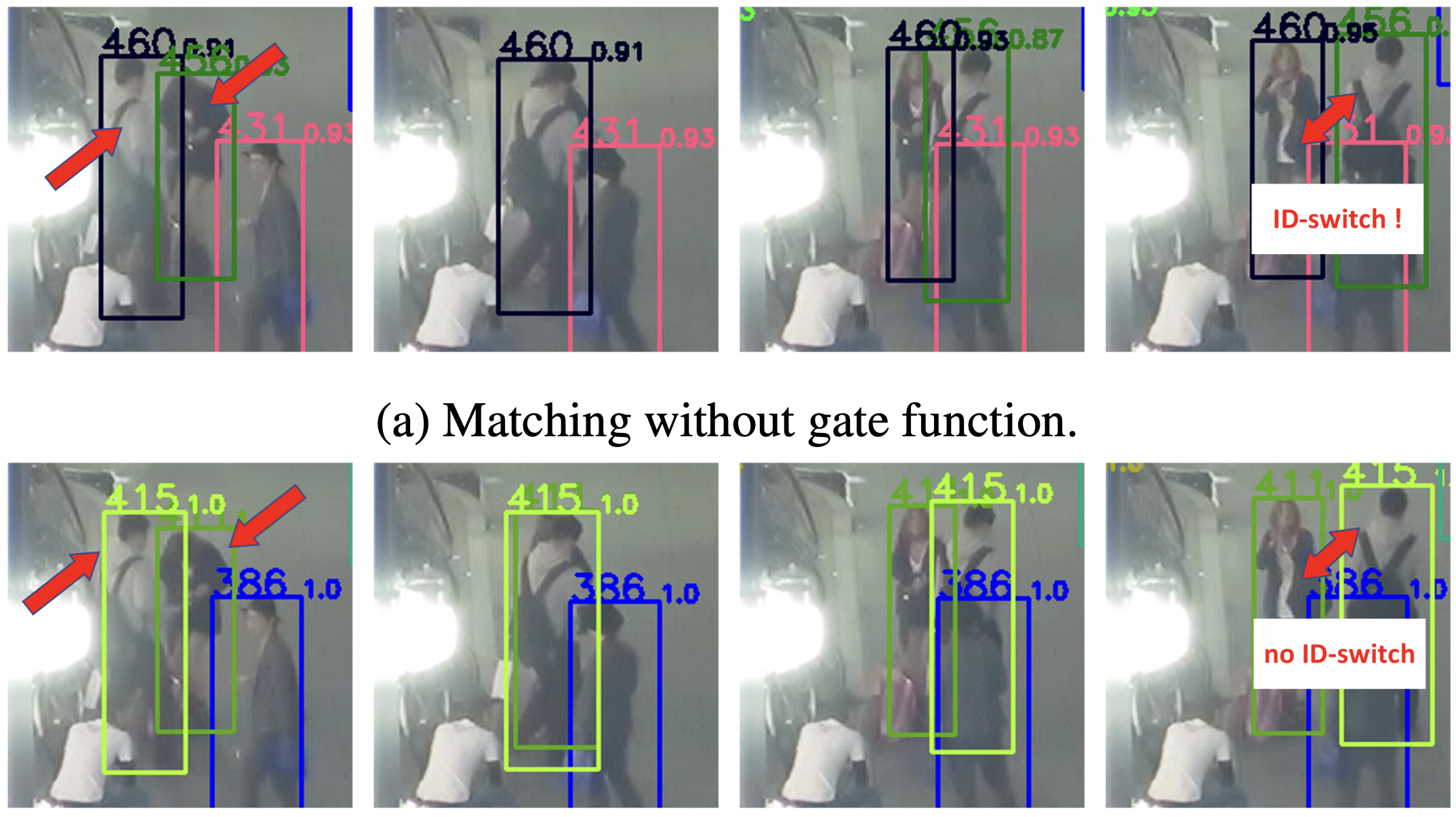
しかしこれでは、異なる二人の歩行者間でIoUが外観特徴の類似度を大きくに上回る場合に問題が生じます。つまり外観情報からして異なる個人である事が分かっても、位置的に大きく重なっている場合にはIoUが高くなり、結果異なる人に関連づけてしまうIDスイッチが生じてしまう問題が生じてしまいます。
本論文はそこでゲート関数を提案します。IoUが高くても外観情報の類似度が0.7より低いマッチングを拒否する関数です。これにより外観が異なっていても重なってさえいれば良くなるような誤ったマッチングを減らす事ができます。
実験
実験ではMOT17データセットの精度でSoTAモデルとの比較・アブレーションスタディを行っています。アブレーションではMOT17の学習用データの前半部分をTrainに、後半部分をValidationに使用します。SoTAモデルとの比較ではMOT17・CrowdHuma・ETHZ・Citypersonを組み合わせて学習させています。
実装
提案手法の検出器にはPRBというモデルを用います。COCOデータセットで事前学習をした後、MOT16とMOT17でfine-tuningさせています。SLMの学習にはMOT17の学習セットから切り出した独自のデータセットで学習を行っています。30フレーム以上関連付けをできなかったtrackletは削除され、multi-template-SLMの特徴バンクは50フレームまで保持します。
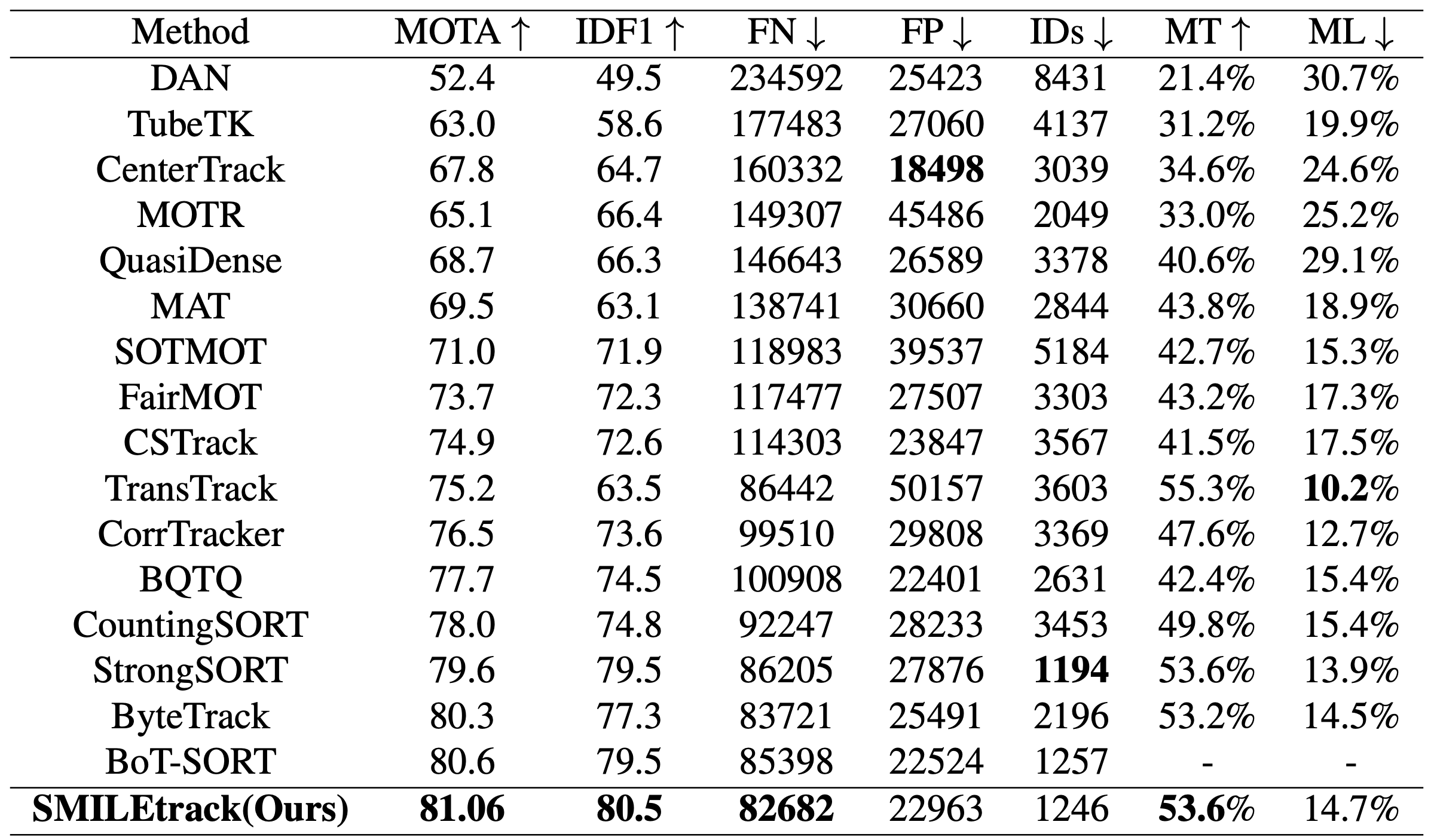
SoTAモデルとの比較
MOT17テストセットの精度です。動き情報のみ用いたByteTrack、DeepSORTの改良手法であるStrongSORT、検出も追尾もTransformerベースに構築したTransTrackなどSoTAモデルとの精度を比較しています。SMILETrackはMOTAが81.06、IDF1が80.5と全ての手法の中で最高精度を達成する事ができました。これは次のアブレーションスタディで最高精度となった設定で実験しています。
アブレーション
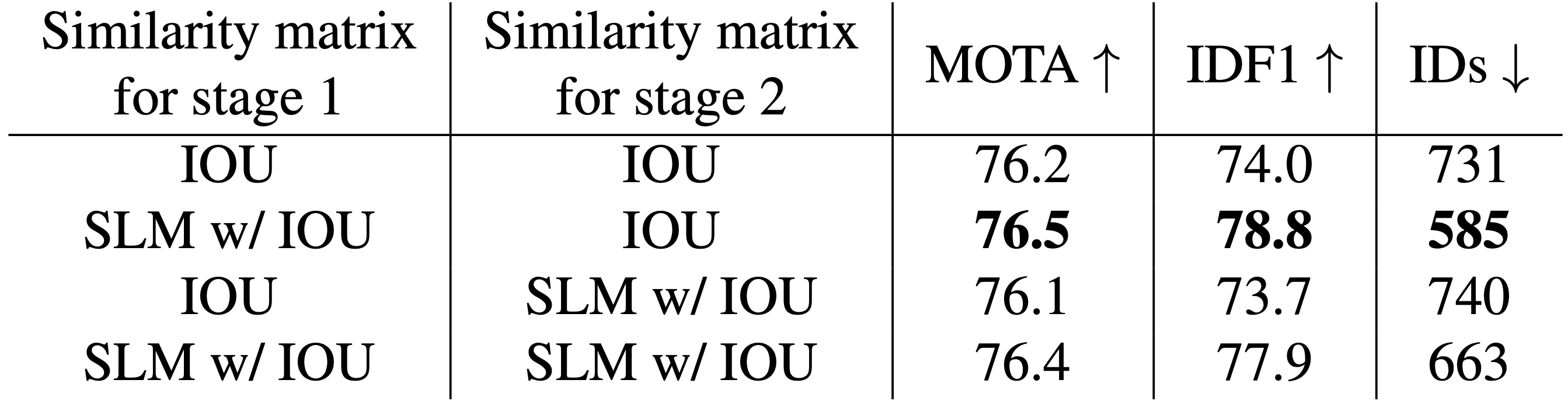
まずはSLMの有効性です。関連付けのステージ毎に外観情報(SLM)を採用するか否かで精度を比較しています。ステージ2にもMulti-template-SLMではなく通常のSLMを用いています。そのため下の表のように信頼度の高いステージ1のみSLMを用いたモデルが最い精度となっており、信頼度を基にした外観情報の活用が適切である事がわかります。
最後にゲート関数とMulti-template-SLMの有無を比較です。ステージ1・ステージ2共に動き情報(IoU)と外観情報(SLM)を使うモデルをベースとして、ステージ2をMulti-template-SLMに変えた場合や両ステージにゲート関数を採用する場合と比較しています。ゲート関数やMulti-template-SLMを採用した場合に精度が向上する事が確認できます。両方を採用したモデルがアブレーションで最高精度を達成し、本手法の優位性を実証できました。

所感
これまでもいくつか追尾手法を紹介してきましたが、今回のSoTAモデルはかなりシンプルな機構に見えます。カメラブレの補正などの前処理や追尾の途切れを補正するグローバルリンクなどの後処理について触れられていません。にも関わらずSoTAを達成したのはByteTrackのアプローチとAttentionベースのシャムネットワークが機能したのか、あるいは検出器PRBの性能が良いからなのか、検証する必要があるように思います。
まとめ
今回はSMILETrackというMOTChallengeのSOTA手法を紹介しました。検出の信頼度で二段階の関連付けを行うByteTrackの優位性を引き継ぎ、Attentionを用いたシャムネットワークによる頑健な外見特徴を抽出し、精度を高めました。信頼度の低い関連付けの際に問題となる外観特徴に対してMulti-template-SLMとゲート関数を使用することで適切に処理し、精度の低下を抑えました。
課題として本手法はSDEモデルのためJDEモデルより動作が遅くなることを挙げています。このトレードオフを改善できるアプローチを検討する方針だそうです。今後の発展が楽しみです。




この記事に関するカテゴリー

