
Cal-QL: 効率的なオンラインファインチューニングを実現する, 事前学習に特化したオフライン強化学習
3つの要点
✔️ オフライン強化学習 + オンラインファインチューニングの課題を実験的に調査
✔️ 調査結果の考察を元に既存手法を改良した事前学習のためのオフライン強化学習手法, Calibrated Q-Learning(Cal-QL)を提案
✔️ オフライン強化学習 + オンラインファインチューニングのシナリオで既存手法を超える性能を達成
Cal-QL: Calibrated Offline RL Pre-Training for Efficient Online Fine-Tuning
writtenby Mitsuhiko Nakamoto, Yuexiang Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, Sergey Levine
(Submitted on 9 Mar 2023 (v1), last revised 20 Jun 2023 (this version, v2))
Comments: project page: this https URL
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
導入
大規模データによって事前学習したモデルを個別の用途に合わせてファインチューニングする枠組みは, 深層学習技術を実応用する上で有効性を示しています. 画像認識や自然言語処理では, 大規模画像モデル(e.g. Imagen)や大規模言語モデル(e.g. ChatGPT)などが開発されて, 産業界の発展のみならず, 日常的な利便性をももたらしています.
そうした流れを受けて, 近年強化学習においても, 静的なデータから方策を学習するオフライン強化学習の技術を用いて事前学習を行い, 目的の環境で追加の相互作用を最小限に抑えて方策をファインチューニングする枠組みが盛んに研究されています.
こうした技術が確立すれば, 費用や危険性の面で環境との相互作用の回数が限られる自動運転や医療ロボットなどの分野で深層学習技術の活用がさらに進むことが期待されています.
本研究では, 事前学習としてのオフライン強化学習に焦点を当てています. 最初の要点に示したように, 本研究は以下の3部から構成されています. (1)実験によって既存のオフライン強化学習手法を事前学習に用いたときの性能と課題を調査. (2)調査から見えた課題を克服するシンプルな改善策を提案. (3) 提案手法の事前学習手法としての有効性を実験的に検証. 本記事では, オフライン強化学習の基礎知識を説明したのち, 上記の三点を順を追って説明します.
オフライン強化学習
オフライン強化学習では, 何らかの方策($\pi_\beta(a|s)$)から集めた環境との相互作用データ$D = \{s_i, a_i, r_i, s'_i\}_{i=1}^{n}$を基に, 追加の環境との相互作用なしに最適な方策の学習を目指します. 環境と相互作用することができないため, データにない状態行動のペアを追加的に集めることができません. そのため, 例えばデータに存在しない状態行動ペアのQ値の過大推定が起こった際に修正する手段がありません. こうした, データにない状態行動が原因で生じる問題はOut-Of-Distribution(OOD) 問題と呼ばれ, オフライン強化学習の最大の課題です. 既存のOOD問題の対策は保守的な手法と方策に制約をかける手法の二種類に大別されます. 本論文では保守的な手法を基に手法を提案しているため, こちらをより詳しく説明します.
保守的な手法
この手法は, 先に示したQ値の過大推定を防ぐために, 推定したQ値が真の価値関数の下界となるように, Q値を割り引いて推定する方法です.
Q値を過大に推定しないという意味で保守的(conservative)であるというわけでです. 保守的な手法の代表が, 本研究でも取り上げられるConservative Q-Learning(CQL)です. 以下に, 通常のQ関数を用いる手法との違いを説明します. ここではQ関数はパラメタ$\theta$によってパラメトライズされているとします.
・従来法
$$\min_{\theta} \frac{1}{2} (Q_{\theta}(s, a) - \mathrm{B}^{\pi}Q(s, a))^2$$
ここで, $\mathrm{B}^{\pi}$は方策($\pi$)の期待ベルマン作用素で, この目的関数は方策($\pi$)の価値関数の推定問題となります.
・CQL
$$\min_{\theta} \underbrace{\alpha(\mathbb{E}_{(s, a)\sim \pi}[Q_{\theta(s, a)}] - \mathbb{E}_{(s, a)\sim D}[Q_{\theta(s, a)}])}_{ペナルティ項} + \frac{1}{2} (Q_{\theta}(s, a) - \mathrm{B}^{\pi}Q(s, a))^2$$
ここで, ペナルティ項は, 方策($\pi$)のQ関数の期待値がデータ分布に対するQ関数の期待値から離れないように制約をかけます. つまりQ関数がデータにない状態行動の過大推定に対して保守的であることを要請します. CQLの論文のTheorem 3.2によって, 上記の目的関数によって推定されたQ関数の, 方策$\pi$による期待値が真の $\pi$ の価値関数の下界になることが証明されています. 興味のある方は参照してください.
方策$\pi$に制約をかける手法
この手法では, 学習対象の方策($\pi$)が, データを生成した方策($\pi_\beta$)から大きく乖離しないように制約を与えながら最適化を行います. 制約の導入方法は様々で, 代表的なものに分布間の距離を測るKL-divergenceを用いる方法があります. 方策に制約をかける手法としては, IQL, AWAC, TD3-BCなどが挙げられます.
調査

設定
既存のオフライン強化学習手法, CQL, IQL, AWAC, TD3-BCを用いて事前学習+ファインチューニングを行い, ファインチューニング時の性能を比較しています. 比較に用いたベンチマークは画像を入力として物体を拾い特定の場所に移動させるmanipulationタスクです.
結果
図1から以下の二点をみることができます.
- 制約ベースの手法, IQL, AWAC, TD3-BCはいずれも学習が遅い.
- 保守的な手法であるCQLは, 最終的な学習結果は良いものの, 学習初期に著しい性能の低下が見られた.
考察

本論文では, 最終的な性能が高いCQLが事前学習手法として有望であると考え, CQLの課題である, ファインチューン初期の性能の低下の原因を考察しています.
保守的な手法では, ペナルティ項によってQ値が全体的に小さく推定されます. Q関数によって行動を選ぶ場合, 値のscaleが間違っていても行動間のQ値の大小関係さえ学習できれば, 推論時には最適な行動を選ぶことができます.
しかし, オンラインファインチューニングが始まると, Q関数は実際の価値のスケールに戻ります[図2]. 実際のQ関数よりも過小に推定されたQ関数を初期値として用いると, 学習の初期段階では, onlineで実行された最適ではない行動の価値が, 単に実際のスケールに戻っただけで相対的に高く見積もられます. その結果方策が最適では無い行動をターゲットに学習してしまいパフォーマンスの低下(unlearn)が起こっていると彼らは考察しています.

この仮説を裏付ける根拠として, 彼らはCQLによって推定されたQ値の平均とパフォーマンスを事前学習とファインチューニングを通してプロットしています[図3]. ファインチューニングは50kステップから始まっていて, その付近でQ値の平均の急上昇及びパフォーマンスの急降下が起こっていることが確認できます.
手法
上に述べた実験によって保守的な手法を用いた事前学習では, Q関数のスケールが実際のものより小さくなることによって, オンラインファインチューン初期に最適ではない行動が相対的に高い価値を持ち,学習が不安定化する現象, 「unlearn」が確認されました. 本論文では, この現象を防ぐために, 実際のQ-関数に対してはconservativeでありながら, 最適では無い方策のQ-関数よりは高い値を取るようにQ関数を推定することで, より効率的な事前学習を行うことを提案しています. 上記の,「最適では無い方策のQ-関数よりは高い値を取る」Q関数は「校正されている(Calibrated)」と以下のように定義されています.
定義4.1 校正(Calibration)
ある方策に対して推定されたQ関数$Q^{\pi}_\theta$が参照方策$\mu$に対して校正されているとは, 任意の状態$s$について, $\mathbb{E}_{a\sim \pi}[Q^{\pi}_\theta(s, a)] \geq \mathbb{E}_{a\sim \mu}[Q^{\mu}(s, a)]$が成り立つということである.
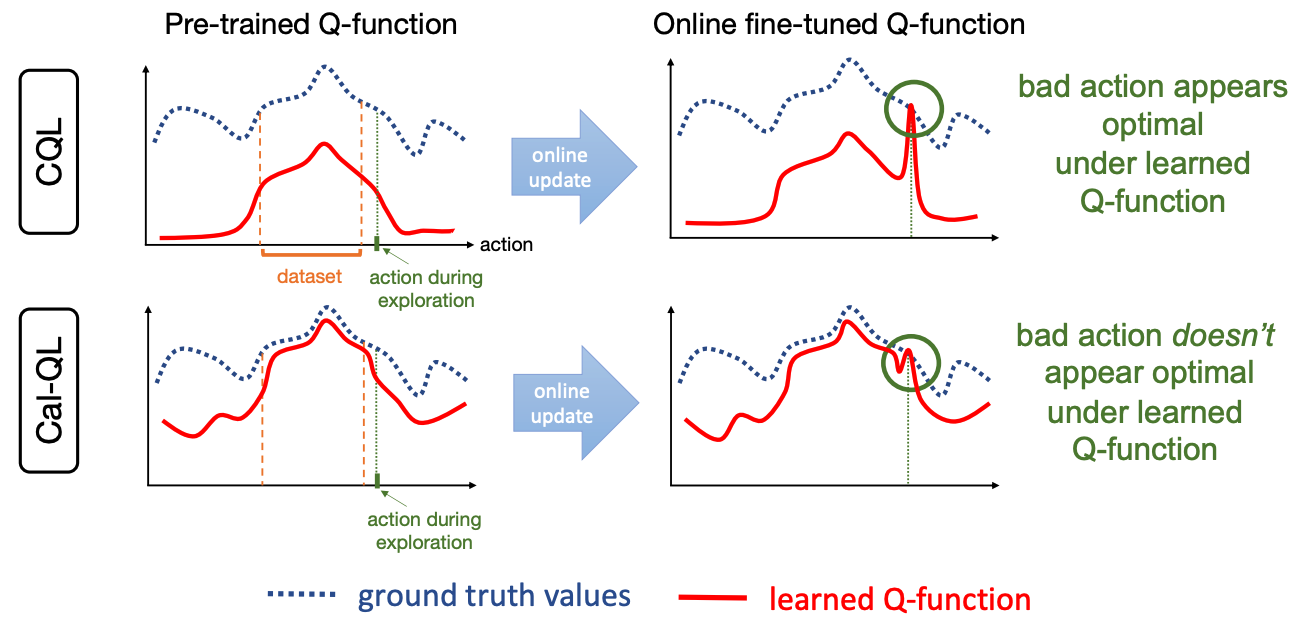
推定したQ関数が全ての最適では無い方策$\mu$について校正されていれば, Q関数は最適ではない行動をとる方策を上界することが保証されています. そのため, 最適ではない行動のQ値が事前学習で推定された最大のQ値を超えることはなく,「unlearn」を防ぐことができます.[図4].
Cal-QL
事前学習で校正を具体的に実現する実際的な方法として, ある最適ではない方策$\mu$に対して校正を行うアルゴリズムCalibrated Q-Learning(Cal-QL)を提案しています. Cal-QLでは, CQLのペナルティ項を以下のように変更します.
$$\alpha (\mathbb{E}_{s\sim D a\sim \pi}[\max(Q_\theta(s, a), V^{\mu}(s))] - \mathbb{E}_{s, a \sim D} [Q_\theta(s, a)])$$
この目的関数が$\mu$による校正とconservatismの両方を実現することを見ましょう. $\max\{Q_{\theta}(s, a), V^{\mu}(s)\}$の値は$Q_{\theta}(s, a)$と$V^{\mu}(s)$の2通りなので, それぞれの場合でペナルティが学習に与える影響を考えます.
- $\max\{Q_{\theta}(s, a), V^{\mu}(s)\} = Q_\theta(s,a )$の時, つまり$Q_{\theta}(s, a)>V^\mu(s)$で$\mu$に対して校正されている場合はペナルティ項はCQLのものと同一になり通常のconservatismが働きます.
- $\max\{Q_{\theta}(s, a), V^{\mu}(s)\} = V^{\mu}(s)$の時, つまり推定したQ値が最適ではない方策の価値関数よりも低く, 校正が達成されていない場合, ペナルティ項は$\alpha (\mathbb{E}_{s\sim D a\sim \pi}[V^{\mu}(s)]) - \mathbb{E}_{s, a \sim D} [Q_\theta(s, a)])$となります. このペナルティは$Q_{\theta}(s, a)$が$V^\mu$に「追いつき」, 校正が達成されるようなパラメタの更新を導きます.
まとめると, $Q_\theta(s, a)$が校正されている時はconservatismが働き, そうでない時には校正が実現されるようにパラメタが最適化されます. このようにCQLの目的関数の軽微な変更でconservatismと校正が両立されていることがわかります.
本論文のTheorem 6.1で, この目的関数がオンラインファインチューニング時のリグレットのオーダーを改善するということが理論的に示されています. こちらも興味のある方は参照してください.
実装の際は, 行動方策$\pi_\beta$を参照方策として, 価値関数$V^{\pi_\beta}$をリターンの経験平均によって近似します.
実験
実験では, 幅広いタスクを用いて, 既存のオフライン事前学習+ファインチューニングを志向した手法と比較を行なっています.
ベンチマーク

- AntMaze: 四足歩行ロボットがゴールを目指す迷路課題[図5].
- Franka Kitchin: キッチンで作業を行う環境[図5].
- Adroit: 物体の把持やドアの開閉を行うmanipulation課題[図5].
比較手法
- 既存のOffline RLで事前学習+SACでファインチューニング
- Offline RL手法: IQL, CQL
- オフライン強化学習 + オンラインファインチューニングの既存手法
結果

上図は, 各ベンチマークでのファインチューン時の性能比較です. Cal-QLによってオンラインファインチューン時の収束のスピード及び最終的な性能が多くのタスクで向上していることがわかります.
「unlearn」を完璧に防ぐためには全ての最適でない方策に対して校正を行う必要がありますが, 上の実験では行動方策に対してのみ校正を行っていて, それだけでも学習の安定化と効率化が行えているのがわかります. また彼らは, 価値の推定を経験平均ではなくニューラルネットワークによって行なった場合でも大きな性能の低下が見られないことを確認しており,性能が参照方策の価値関数の推定誤差に対して敏感ではないと述べています.
まとめ
今回は,事前学習としてのオフライン強化学習にスポットを当て, 効率的なファインチューニングを可能にするオフライン強化学習手法を提案した論文を紹介しました. アイデアが実験に裏付けられている点, 実装がシンプルで効果が実験で確かめられている点で実応用が期待できますね. オフライン強化学習+オンラインファインチューニングは実応用性の高いホットなトピックで, 日々研究が進められています. 今後も是非このキーワードを注視してみてください.



この記事に関するカテゴリー

