自由自在に服を着こなせ!StyleGANを用いたファッション画像生成
3つの要点
✔️StyleGANを用いて好きな服を着せた人物画像生成
✔️元画像の服の色や雰囲気を自在に操作
✔️圧倒的高解像度の人物画像生成

上図の人物画像は全て生成された画像であり、実在する画像ではありません。
信じられますか?
ついにGANによる人物画像生成もこれほどの領域まで到達しました。
今までのGANによる圧倒的高解像度の人物画像生成は顔部分のみに限られていましたが、本論文では全身のとても自然な人物画像生成を行える手法を提案しました。
GANによる画像生成においては動物であったり、食べ物、人の顔、ベッドルームなど様々な物が生成されてきました。そして現在、GANはシンプルな画像生成だけでなく、アートやファッションに転用しようとする動きが出てきています。
それでは見ていきましょう。
概要
本論文のテーマは「服を操作可能な高解像度ファッション画像生成」となっています。今までは服を細かく種類ごとに指定しての人物画像生成や、高解像度の人物画像生成は困難でした。
しかし、本論文は近年登場したスタイルを変更できる「StyleGAN」を用いることで高解像度かつ服を細かく指定しての人物画像生成が可能になりました。
本論文はシンプルなアイデアで構築されているので、StyleGANだけ理解すればあとは簡単です。まずは、画像生成手法のStyleGANを追っていきましょう。
StyleGAN (A Style-Based Generator Architecture for Generative Adversarial Networks)

StyleGANはCVPR2019で登場しました。
StyleGANの論文では、GANのGeneratorに各生成段階(各解像度)ごとの画像特徴の挿入手法であるAdaIN(Adaptive Instance Normalization)を用いて画像生成を行うことで、高解像度かつ自然な画像生成を可能にしました※1。
以下に簡略化したGeneratorの図を示します。
※1 その他数々のテクニックや手法が提案されていますが、本記事ではこの部分のみ触れています。詳しくは日本語の解説記事や原著論文を参照してください。
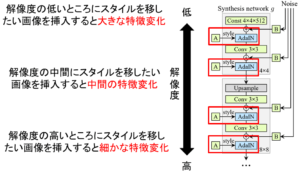
上図のようにGeneratorの各解像度ごとにAdaINを用いて画像を挿入することで、挿入画像の特徴変化の操作が可能になっています。この各解像度ごとの画像特徴の挿入が今回紹介する論文のキモになっています。
本論文のメインアイデアと貢献
メインアイデア
本論文のメインアイデアはシンプルに一つです。下に提案手法の図も示します。
- StyleGANの各解像度ごとの特徴挿入を服ごとに行うことで服の色や形状などを操作する
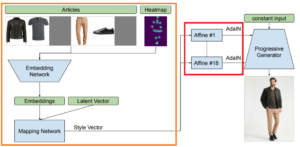
上図のオレンジの枠の部分で挿入したい画像の特徴を抽出し、赤枠の部分でAdaINを用いて特徴を挿入します。
オレンジ枠中のArticlesと書かれた部分がありますが、これは挿入したい服を表しています。また、Heatmapは今回生成したい人物のポーズを関節点(key point)を用いて指定できます。
貢献
本論文の貢献は3つあります。
- 挿入場所を工夫することで人物の服の特徴やポーズを変化させることを可能にした
- 服を組み合わせての画像生成を可能にした
- 高解像度かつ整合性の取れた人物画像生成を可能にした
貢献は実験結果を見ることで直感的なものとなります。
それでは論文の実験結果を見ていきましょう。
実験結果
今回紹介する実験結果は2つあります。1つ目が貢献1について、2つ目が貢献2についての実験結果となっています。
実験結果1:ターゲットとなる人物の特徴変化

左下のTARGETと書かれている人物の特徴を変化させる実験になっています。
まず、上の行の左2つについてです。ここにはCOLOR SOURCESと書かれていますが、これはGeneratorの高解像度部分にArticlesを挿入することで服の形のような大きな特徴は変化させずに、色だけを変えることが可能になっています。
続いて上の行の右2つについてです。ここにはPOSE SOURCESと書かれていますが、これはGeneratorの低解像度部分にHeatmapを挿入することでポーズのような大きな特徴変化を可能にしています。
色変化やポーズ変化の画像を見ても全く違和感はなく、とてもクオリティの高い人物画像生成が行えていることが確認できます。
実験結果2:好きな服を着させた人物画像生成

この実験は一番上の行のアイテムをAdaINを用いて挿入することで好きな服を着せた人物を生成することを可能にする実験です。
2行目の女性は(a)Outfit #1を着せて生成した画像、3行目は(b)Outfit #2を着せて生成した画像、最後の行は(b)Outfit #2+(a)Outfit #1のジャケットを着せて生成した画像となっています。
この図を見てわかる通り自由自在に服を着せた人物の画像生成が可能になっていることが示されています。
しかし、論文中の画像はcherry picked(いいものだけを選別することの意)の画像が使われているはずなのにも関わらず、体形がおかしくなっていたり一部色がおかしくなってしまっているものも見られます。なので、ここは今後の課題としてさらに自然な画像が生成されることが期待されます。
結論
本論文はStyleGANを用いて服を自由自在に変更できる高解像度人物画像生成の手法を提案しました。圧倒的高解像度かつ自然なファッション人物画像生成の手法として画期的であります。
今後の応用としては服の試着などを通販サイトやCtoC(consumer to consumer)のアプリを通じて行えることが期待されます。
試着の必要なく服を自由に変える時代はもうすぐそこに来ているのかもしれません。
Generating High-Resolution Fashion Model Images Wearing Custom Outfits
(Submitted on 23 Aug 2019 in Proc of arXiv)
written by Gökhan Yildirim, Nikolay Jetchev, Roland Vollgraf and Urs Bergmann
accepted by the International Conference on Computer Vision, ICCV 2019, Workshop on Computer Vision for Fashion, Art and Design






この記事に関するカテゴリー






