小規模ニューラルネットワークはネットワークをAugmentationすべき!?
3つの要点
✔️ 小規模ニューラルネットワークの精度を向上させるNetAug(Network Augmentation)を提案
✔️ ネットワークを拡張することでアンダーフィッティングを緩和する
✔️ 画像分類・物体検出タスクで一貫して性能を向上
Network Augmentation for Tiny Deep Learning
written by Han Cai, Chuang Gan, Ji Lin, Song Han
(Submitted on 17 Oct 2021 (v1), last revised 24 Apr 2022 (this version, v2))
Comments: ICLR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
深層学習の性能を向上させるための様々な正則化手法(データ増強やドロップアウトなど)は多くの成功を収めています。
しかし、これらの既存の正則化手法は、オーバーフィッティングが起こりにくい小規模なニューラルネットワークでは、むしろ性能を損なう可能性があります。本記事で紹介する論文では、小規模なニューラルネットワークの性能を高めるための手法として、データではなくネットワークを増強する手法であるNetAugを提案しました。
その結果、小規模なモデルにおいて、ImageNetで最大2.2%の精度向上を達成するなどの結果が得られました。
NetAug(Network Augmentation)
Network Augmentationの定式化
まず、学習させたい小さな(tiny)ニューラルネットワークの重みを$W_t$、損失関数を$L$とします。学習時には、$L$を最小化するように重みの最適化が行われます。
$W^{n+1}_t = W^n_t - \eta \frac{\partial L(W^n_t)}{\partial W^n_t}$
このとき、小さなニューラルネットワークは、容量の小ささにより、大規模なニューラルネットワークと比べて局所的最適解に陥りやすく、トレーニング・テスト性能が悪い傾向にあります。
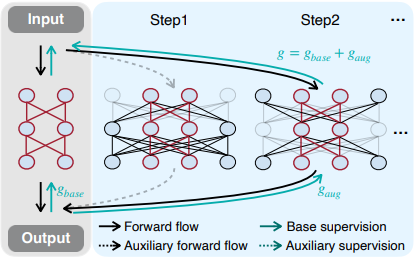
提案手法であるネットワーク増強(Network Augmentation)では、小さなニューラルネットワークの学習を支援するため、より大きなニューラルネットワークによる追加のsupervisionを導入します。
これは、ネットワークの一部のみで予測を行うドロップアウト手法とは逆であると言うことができ、学習させたい小さなニューラルネットワークの幅を拡張して巨大なニューラルネットワークを作成し、これを利用して学習を行います。
このアイディアは以下の図のようにまとめられます。
このとき、ネットワーク増強における損失関数$L_{aug}$は以下のようになります。
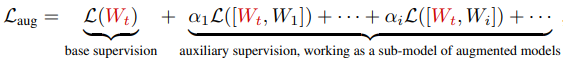
ここで、$[W_t,W_i]$は、学習させたい小さなニューラルネットワーク$W_t$と、新たな重み$W_i$を含む拡張されたモデルを表しています。
$\alpha_i$は異なる増強されたモデルの損失を統合するためのハイパーパラメータです。
増強されたモデルについて
ネットワークを増強するとき、増強されたモデル$[W_t,W_i]$を独立させることは、計算資源の側面から困難です。そのため、最大のモデルのサブネットワークを選択する形式により、多様な増強モデルを構築します(先述した図のStep1,Step2参照)。
このアイディアはOne-Shot NASと似ていますが、最適なサブネットワークを得ることではなく、特定の小さなニューラルネットワークの性能を向上させることに重点が置かれている点が異なります。
また、ネットワーク増強の際には、モデルの幅を大きくするように増強を行います。
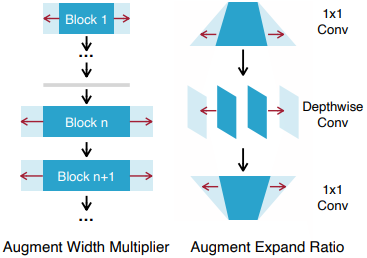
学習プロセス
増強されたネットワークを学習する際には、各ステップごとにサブネットワークをサンプリングしてモデルの更新を行います。
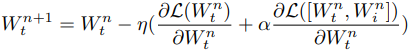
ここで、$[W^n_t,W^n_i]$は各学習ステップごとにサンプリングされたネットワークにあたります。学習させたい小さなニューラルネットワークの重みだけではなく、増強された部分の$W_i$も更新されています。
なお、ハイパーパラメータ$\alpha$は、実験では全て1.0で固定されます。
学習時・推論時のオーバーヘッドについて
まず、ネットワーク増強は学習時のみ行われるため、推論時のオーバーヘッドはありません。 学習時については、実験の結果、学習時間が16.7%長くなるのみとなりました。
これは、ネットワーク増強が小さなネットワークの学習に用いることを想定しており、学習時の計算処理よりも、データのロード・通信コストが支配的であることによります。
実験設定
実験に用いる画像分類データセットと学習設定は以下の通りです。
- ImageNet:16GPU、バッチサイズ2048で150エポック
- ImageNet-21K-P(winter21 version):16GPU、バッチサイズ2048で20エポック
- Food101:ImageNetで事前学習された重みで初期化、4GPUでバッチサイズ256で50エポックのfine-tuning
- Flowers102:Food101と同様
- Cars:Food101と同様
- Cub200:Food101と同様
- Pets:Food101と同様
また、画像検出データセットは以下の通りです。
- Pascal VOC:8GPU、バッチサイズ64で200エポック
- COCO:16GPU、バッチサイズ128で120エポック
実験結果
はじめに、ImageNetにおける結果は以下の通りです。
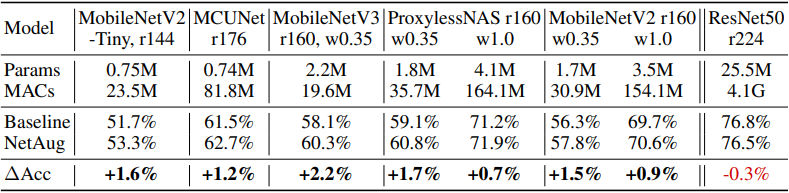
総じて提案手法は、異なるニューラルネットワークアーキテクチャについても、一貫して小さなニューラルネットワークの精度を向上させられることがわかりました。
なお、ネットワーク増強は小さなニューラルネットワークに適用することが想定される手法であるため、モデル容量が十分なResNet50では精度の向上には繋がりません。また、学習エポック数に対する精度のプロットは以下の通りです。
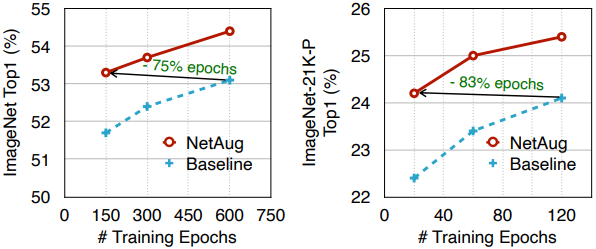
図の通り、増強なしの場合と比べて同等な精度を得るために必要が学習エポック数は大幅に削減されていることがわかります。
知識蒸留(Knowledge Distillation)との比較
次に、Assemble-ResNet50を教師モデルとして知識蒸留を行った場合との比較は以下の通りです。

総じて、知識蒸留手法と比べて高い精度向上が実現されています。また、提案手法は知識蒸留と組み合わせることができ、その場合はさらに精度が大きく向上していることがわかりました。
正則化手法との比較
次に、ドロップアウトやデータ増強など、大きなニューラルネットワークでは精度向上に繋がる手法との比較結果は以下の通りです。
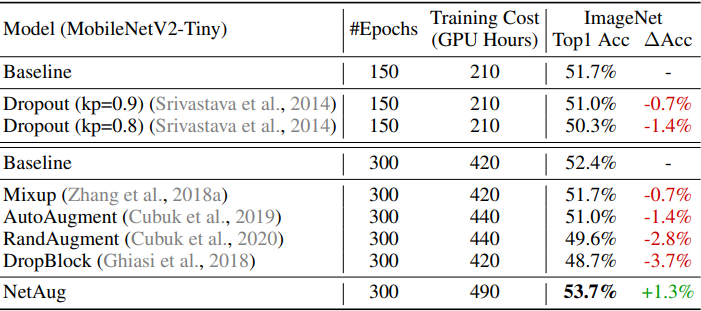
総じて、小さなニューラルネットワークはオーバーフィッティングよりアンダーフィッティングに悩まされているため、オーバーフィッティングを防ぐための手法は逆効果となってしまいます。
逆に言えば、提案手法であるネットワーク増強は、小さなニューラルネットワークのアンダーフィッティングを緩和するための手法であるため、大規模なニューラルネットワークに適用することは逆効果となります。これらは以下の学習曲線のとおりです。
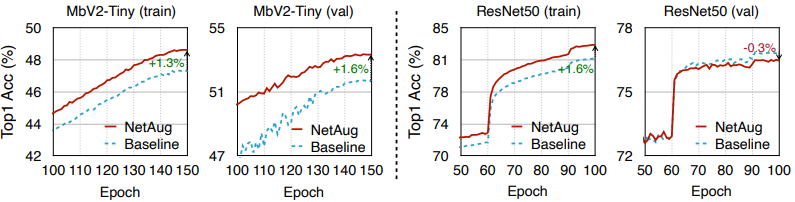
図では、小さなニューラルネットワーク(MobileNetV2-Tiny)と大きなニューラルネットワーク(ResNet50)におけるtrain/val精度のプロットが示されています。
先述の通り、小さなニューラルネットワークではtrain/val精度両方が向上している一方、ResNetではval精度は低下しており、オーバーフィッティングの兆候が見られます。
転移学習(transfer learning)における結果
最後に、ImageNetで事前学習させたモデルの転移学習を行った場合の結果は以下の通りです。
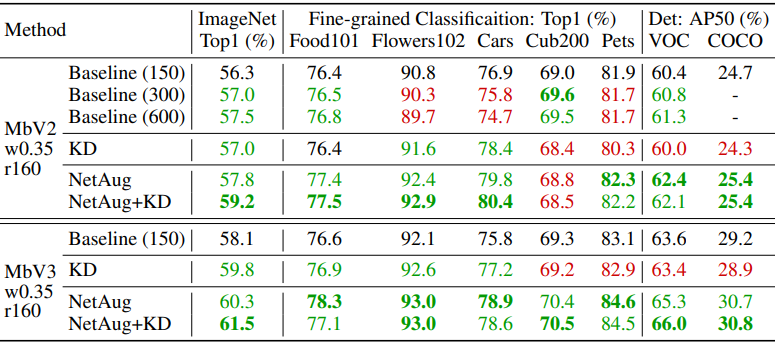
ベースライン(Baseline(150))と比べて良い結果は緑、悪い結果は赤で示されています。全体として、Network Augmentationを行った場合は転移学習時にも良好な結果を示すことがわかりました。
また、提案手法はより小さい解像度でも良好な性能を発揮できるため、推論効率の向上にも繋がります。以下の図では、異なる解像度における物体検出の結果が示されています。
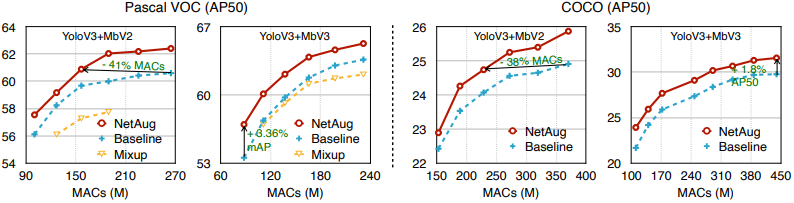
この図では、より小さい解像度で同等の性能を発揮できていることがわかります。
まとめ
本記事では、アンダーフィッティングに悩まされやすい小さなニューラルネットワークの性能を向上させるための手法であるNetwork Augmentaionについて紹介しました。この手法は、画像分類や物体検出などのタスクで一貫して精度向上に繋がることが示されました。
既存の正則化手法は主に大規模なニューラルネットワークのオーバーフィッティングに対処することを目的としていますが、小さなモデルをエッジデバイス等で使用したい場合を踏まえれば、このような小規模ニューラルネットワークに特化した改善手法も重要であると言えるでしょう。






この記事に関するカテゴリー