エージェントはいつ探索すべきか?
3つの要点
✔️ 従来は探索の量のみを考慮していたが、いつ探索するのかにも着目
✔️ 変数を増やすことで柔軟な探索設計を可能に
✔️ 各変数の及ぼす影響について実験
When should agents explore?
written by Miruna Pîslar, David Szepesvari, Georg Ostrovski, Diana Borsa, Tom Schaul
(Submitted on 26 Aug 2021 (v1), last revised 4 Mar 2022 (this version, v2))
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
ボードゲーム、ビデオゲーム、ロボット制御などいくつかの分野で大きな成功を納めてきた強化学習ですが、探索に関する問題はいまだ中心的な課題として残り続けています。
強化学習で考慮すべき基本的事項に探索(explode)と搾取(exploit)のバランスというのがあります。今分かっている情報の中で最も良い選択肢を取るか、それともより良い選択肢を探すために情報を集めに行くか、のバランスをどう取って行くかという問題です。
中でもどれほど探索すべきかという探索の「量」の問題に関しては、DQNでも採用されているε-greadyやSACなどのエントロピー最大化強化学習などこれまでにも研究が盛んでした。しかし、探索を「いつ」すべきかという時間に関する問題についてはあまり研究がなされていなかったのが現状です。そこで今回はこの「いつ探索すべきか」という問題に切り込んだ論文を紹介します。DeepMindの研究チームが書いたもので、2022ICLR採択論文になります。
手法
探索方式
まず前提として探索モードと搾取モードがあるような手法を考えます。例えばε-greedyなどが相当しますが、搾取モードは今持っている価値関数の中で最もよい行動をとるもので、探索モードはより良い行動を見つけるために行動します。ここで探索モードにおいて二種類の探索手法を本論文では考慮しています。1つが一様探索(uniform exploration)というもので名前の通り完全にランダムに行動を選択します。ε-greedyなどの探索がこの場合に相当します。もう1つが内発動機付け探索で、これはRNDで採用されている手法になります。
探索の粒度
次に探索の粒度について考えていきます。これは以下の四パターンに分類されます。
ステップレベル(C)
最も一般的な設定で、毎ステップ探索するかどうか決定します。顕著な例としてはε-greedyがあります。
実験レベル(A)
全ての振る舞いを探索モードで決定し、方策オフ型で学習します。これもよく見られる手法で、内発報酬を使用するものが相当します。
エピソードレベル(B)
エピソード毎に探索するかどうかを選択します。
intra-episodic(D,E,F,G)
ステップレベルとエピソードレベルの中間にあたる手法です。探索は数ステップ継続して行われるものの、エピソード全体には及びません。最も研究されてこなかった設定であり、本研究はこの設定を主に取り扱います。
これらの各手法をイラストで示したのが次の図になります。左はピンクが探索モード、青が搾取モードを表しています。右図は探索の量と探索の長さの関係性を示しています。pxは全ての行動の中に探索がどれほど含まれているかを示しており、medxは一度探索モードに入ったらどれほど連続で探索を続けるかを示しています。肌色で囲まれた部分がintra-episodicに対応しており、ここからわかるようにかなり自由度の高い手法であることがわかります。

切り替え手法
では次に探索モードと搾取モードの切り替えについて見ていきます。アルゴリズムには大きく二つ考えられます。
ブラインドスイッチング
最もシンプルな手法で、状態を考慮せず切り替えの頻度だけを考えます。例えば、カウンタを用意し一定数で切り替える手法や、ε-greedyのような確率的に選択する手法が考えられます。
インフォームドスイッチング
より高度な意思決定を行うために、エージェントの内部状態を用いる手法です。2つのコンポーネントからなります。まず、毎ステップスカラー値のトリガ信号がエージェントから発せられます。次に、その信号を元にモード切替の意思決定を行います。実際の例として、本論文では予測価値差分(value promise discrepancy)という次の式で表される量をトリガ信号として使います。
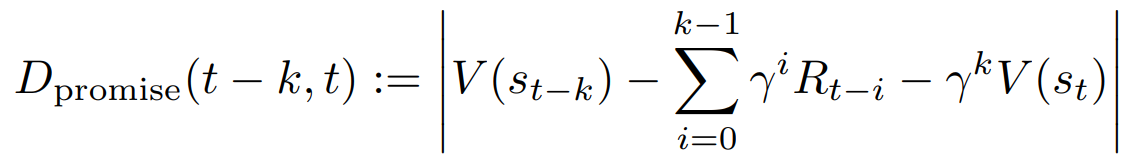
これはkステップ前の予測と実際に行動した後の実現値の差分を表しており、この値が大きい、つまり、予測が上手くいっていない場合に、探索モードに切り替えるような手法になっています。
また、エピソード開始時の初期モードをどうするかというのも重要な問題です。もちろん、適応するタスクにはよりますが、多くの場合において搾取モードから始めるのが有効であるとされています。これは初期状態近傍は訪れている回数が他の状態に比べて相対的に多くなるため、予測の正確度が高いことからきています。
実験
セットアップ
Atariのゲーム7つを使用します。中でも Montezuma’s Revenge など難易度が高いものを中心に選択しています。
大元の強化学習アルゴリズムにはR2D2を選択しています。これは、Q関数の表現にRNNを用いた分散型のDQNです。このR2D2をベースに、上で紹介した探索の粒度・モード切替アルゴリズムを組み込んだものを比較します。もちろんモード切り替えを行うのは学習時のみで、評価時にはgreedy方策を使用しています。
ベースライン
intra-episodicを他の手法と比較するため次の4つのベースラインを考えます。
- 全て探索モード (experiment-level-X)
- 全て搾取モード (experiment-level-G)
- ε-greedy ε=0.01 (step-level-0.01)
- バンディットメタコントローラで選択しエピソード間で固定する (episode-level-*)
上記それぞれに対して、一様探索(X_U)と内発動機付け探索(X_I)の探索モードを用意します。

これらベースラインと提案手法であるintra-episodic(赤実線)を比較した図になります。左二つが一様に探索の場合、右二つが内発動機付け探索の場合を示しています。どちらの場合もintra-episodicが優れていることが見てわかります。
intra-episodicのバリエーション
intra-episodicと言っても、多くのバリエーションを考えることができます。次に列挙します。括弧内の表記はその方法を示す記号に対応しています。
- どのように探索するか:一様探索(XU)、内発動機付け探索(XI)
- 探索期間:固定(1,10,100)、バンディットで適応的に選択(*)、探索モードへの切り替えと同様のアルゴリズムで扱うか(=)
- スイッチング: ブラインド、インフォームド
- 搾取モードを継続する期間:
- ブラインドスイッチングの場合。固定(10,100,1000,10000)、確率的(0.1,0.01,0.001,0.0001)、バンディットによる適応的選択(n*, p*)
- インフォームドスイッチングの場合。ターゲットレートを選択する。固定(0.1,0.01,0.001,0.0001)、バンディットによる適応的選択(p*)
- 開始時のモード :搾取(G)か探索(X)
これらを踏まえて一つの手法を次のように表現します。

これは、一様に探索を行い、探索モードは100ステップ継続、バンディットで選択した確率的にブラインドスイッチング、初期モードは搾取、であることを示しています。
性能
では、このintra-episodicのバリエーションがどのように探索性能に影響を与えるかを見ていきます。次の図は、エピソードが進むにつれ探索量がどのように変化していったかを表しています(1,3列目)。上二つが一様探索を行った場合であり、下二つが内発的動機づけ探索を行った場合になります。1,3列目の各図は、横軸がエピソードの長さで正規化した探索モードの継続長さの最頻値を示しており、縦軸が全ステップにおける探索モードの割合を示しています。また訓練開始時は正方形、終了時は×印で表現されています。興味深いのは、一様探索と内発動機付け探索では大きく探索の方式が異なるのにもかかわらず、これら二つの図は似通ったものになっているということです。

スイッチング
次にスイッチングについて比較します。

左、中央の図はそれぞれブラインド・インフォームドでモードの切り替えを行った際に搾取(青)・探索(赤)がどのように分布しているかを示したものです。インフォームドの場合は探索の密度にばらつきがあることがわかります。右の図はそれぞれの手法のリターンを示したものであり、インフォームドの方が最終的に高い性能を発揮しています。
開始時のモード
次にエピソード開始時のモードの影響について見ます。
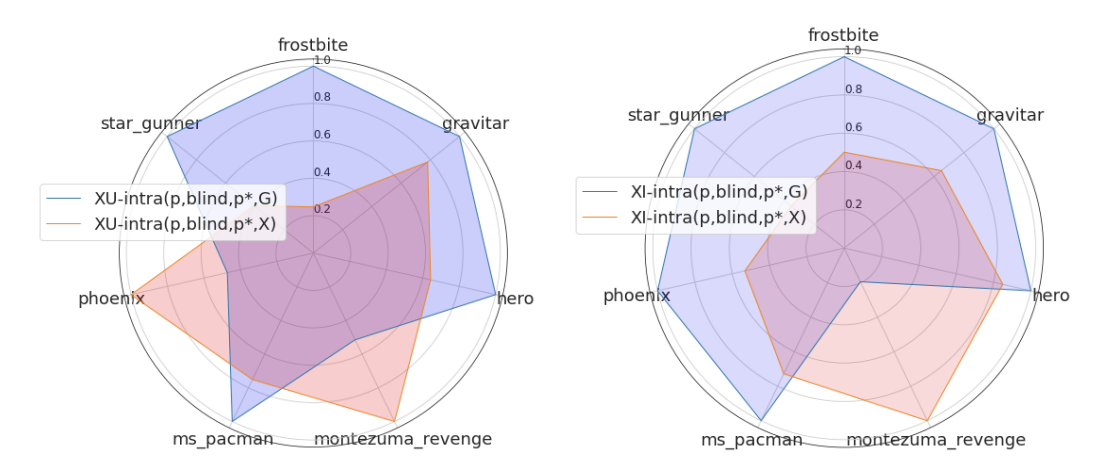
上の図は7つのゲームについて、それぞれ探索スタート(赤)・搾取スタート(青)の場合のリターンを示しており、左が一様探索、右が内発動機づけ探索の場合です。基本的には、搾取スタートの場合の方が良いことがわかります。これは、エピソード開始時の状態は訪れる回数が多く、予測が安定しているからだという解釈ができます。ただMontezuma’s Revengeのような長期間の探索を要求されるゲームでは探索スタートの方が性能が高く、適応する環境についてはよく把握しておく必要があるでしょう。
ブラインドスイッチングにおけるモード切り替え
最後にブラインドスイッチングにおけるモード切り替え手法について、カウント式と確率式を比較します。
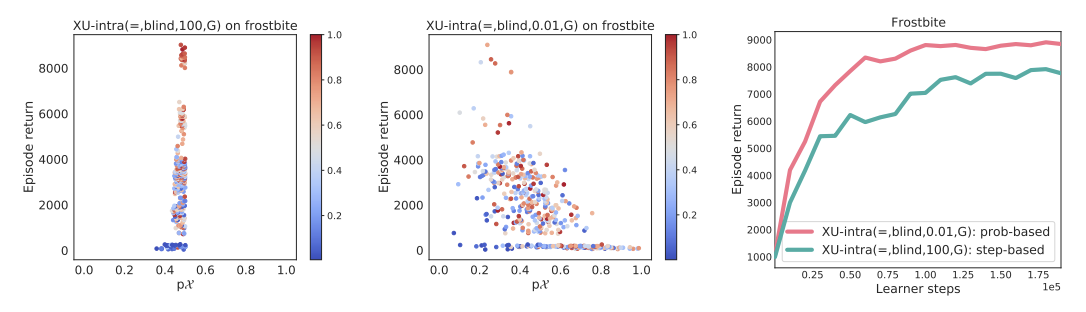
左2つの図は各エピソードにおける、探索量とリターンの関係を示しています。訓練が進むにつれ、点の色を青から赤へと変化させています。左(カウント式)はエピソード間で探索料に大きな変化はなく、エピソードを経るに連れ順当にリターンを上昇させていることがわかります。中央(確立式)はエピソード間で探索料のばらつきが多く、また探索が増えるとリターンが落ちることが読み取れます。右の図はこれらの手法のリターンを示しており、確率式の方が性能が高いことがわかります。
まとめ
今回はエージェントの探索について「いつ」という観点から踏み込んだ論文を紹介しました。本論文の筆者らが提案したintra-episodicという区別によって、これまでよりもより柔軟にエージェントの探索についてデザインできるようになりました。しかし、これは明確に探索モード・搾取モードの区別がある場合に限定されているのが課題です。現状、連続値制御で主流なのはSACなどのエントロピー最大化強化学習をベースとした手法であり、これらのアルゴリズムはモードの切り替えを行わず、ある種常に探索してると言えるでしょう。このintra-episodicの概念を発展させ、SACなども包含できるようにする今後の研究が期待されます。






この記事に関するカテゴリー






