
MA強化学習を使用した自律型ドローン制御による森林再生アプローチ
3つの要点
✔️ 強化学習を用いた自律型ドローンによる人の手が届きにくい場所の森林再生を行うアプローチの提案
✔️ マルチエージェント強化学習システムの通信メカニズムが部分的にだけ観測できる環境での共同作業を可能にすることの実証
✔️ 地形と森林の情報により難易度が変動するシナリオを生成するシミュレーション環境の構築
Dynamic Collaborative Multi-Agent Reinforcement Learning Communication for Autonomous Drone Reforestation
written by Philipp Dominic Siedler
(Submitted on 14 Nov 2022)
Comments: Deep Reinforcement Learning Workshop at the 36th Conference on Neural Information Processing Systems (NeurIPS 2022)
Subjects: Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Multiagent Systems (cs.MA); Robotics (cs.RO)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
昨今、デジタルツインやSim-to-Realなどの言葉をよく耳にするようになりました。これらのように、シミュレーション環境での情報を元に、現実世界でロボットやドローンを動かす取り組みが増えてきています。また、機械学習や強化学習を使うことにより、より精度を向上させ、自動化を試みています。
しかし、人工知能を使ったドローンの集団制御は、現実世界で行うには様々な問題が発生します。例えば、ドローンの制御が上手くできず、人にあたる可能性が否めません。しかし、様々な事故を想定したシミュレーション環境を使用することで、それらの事故を減らすことが出来ます。 また、利害関係を持つ人々や個人の集団は、エージェントを持つ実体と見なすことができ、現実世界では、より高い目標を達成するために協力が必要であります。これは、マルチエージェントシステムと表現することができ、デジタルツインを含めたロボットやドローンの集団行動には、強化学習がよく使用されています。

本記事で紹介する研究は、分散された環境下でのコミュニケーションを取る自立型ドローンの集団制御が、人の手が届きにくい場所の森林再生を行うアプローチを提案しています。
概要
様々なシナリオで特定の意思決定を行うことのできる個々のエージェントからなる分散型自律システムで森林再生を行う目的としています。この研究では、最先端の強化学習アルゴリズムであるProximal Policy Optimisation (PPO)を利用し、複数のエージェントからなる集合体を制御します。MA集合体のタスクは、木の種を拾い、すでにある森林の外周に沿い森林再生に適したスポットを探し、それを植えることです。さらに、MA集合体は通信によりコミュニケーションを取ることが出来ます。また、様々な学習メカニズムを訓練し、テストするシミュレーション環境を開発しました。この環境は、地形のトポロジーと森林の疎密によって難しい可能性のあるシナリオを生成し、オープンエンド学習に対応可能です。
詳しいメソッドに入る前に、事前知識として、この研究に使用されているPPOと、グラフニューラルネットワークを簡単に説明します。
Proximal Policy Optimisation (PPO)
PPOのアルゴリズムは、主に2つの定義がなされます。
- PPOは、信頼領域を推定することにより、可能な限り大きく、かつ安全な勾配上昇学習ステップを実行する。
- アドバンテージは、特定の状態における行動が、平均的な行動と比較して、どの程度優れているかを推定する。
また、アドバンテージは、Q関数と価値関数の差として記述することもできます。
Graph Neural Network (GNN)
GNNの基本的な機能は、グラフ、ノード、エッジの分類であります。ノードとエッジの特徴や存在は、隣接するノードや既存のエッジを利用して予測することが可能です。
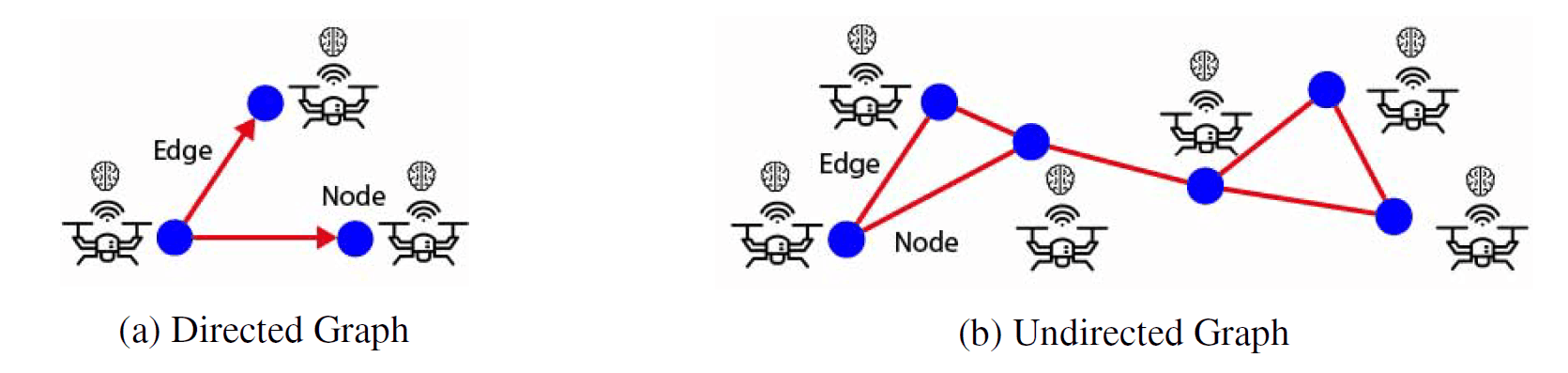 頂点(青点)と辺(赤線)からなるグラフ
頂点(青点)と辺(赤線)からなるグラフ
グラフは、ノードまたは頂点とエッジに基づくデータ構造(上図)であり、ノードとエッジのオブジェクトは、任意のタイプの特徴を任意量で保持することができます。エッジは2つのノード間の関係を表し、ノードは他のノードとの関係エッジを無制限に持つことができます。さらに、グラフ全体の分類は、ノードとエッジの特徴とグラフのトポロジーを入力として達成することができます。
メソッド
メソッドは大きく分けて、ドローンのシミュレーション環境、エージェントのセットアップ、ドローン同士の通信に分かれています。
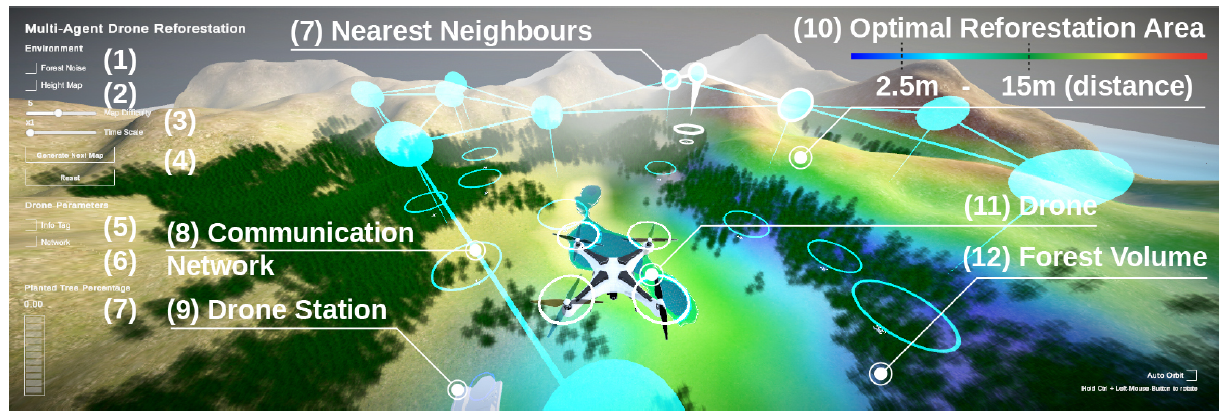
Simulation Environment

マルチエージェント(MA)ベースラインとマルチエージェント通信セットアップ(MAC)のシミュレーションと、オンライントレーニングにはUnityで開発した3Dの森林再生の環境を使用します。この環境では、エージェントがドローンステーションから木の種を取得し、木の種を植えるのに最適な場所を見つけ、木の種を落とし、バッテリーを充電して次の木の種を取得するためにドローンステーションに戻ることで問題解決とします。
環境シナリオのバリエーションは、すべて以下の要素で構成されています。
- octaves、persistence、lacunarity-based noiseを使用したプロシージャル生成地形
- 一定の高さ領域に配置された木(森)と、ランダムなノイズマップを組み合わせ、肥沃な土地にのみを表示(ここでは緑の芝生)
- ヒューマンユーザーインターフェースでは、森林再生に最適で報酬が最も多く得られる地域を表示することができる
- ヒューマンユーザーインターフェースにのみ表示される高さのヒートマップ。
- ヒューマンユーザーインターフェースにのみ表示されるシアン色で動的に表示される最近傍を定義するネットワーク
Agent Setup
エージェントのセットアップとして、以下の項目を設けています。
Goal:各エージェントは、ドローンをドローンステーションまで誘導し、そこで自動的にサービスを受け、木の種を拾いバッテリーを充電することを学びます。その後、ドローンを操作し、バッテリー残量を確認しながら、木の種を落とすのに最適な場所を探し、ドローンステーションまで戻ります。
Reward Function: エージェントの報酬機能は、複数の部分から構成されています。種を所持していない場合は、距離と関係なくドローンステーションに近づくと報酬が増加し、合計+20まで累積します。また、木の種を落とす場所に応じて+0~+30の報酬が得られます。
Vector Observations: すべてのベクトル観測は正規化されます。最終的なベクトル観測の空間サイズは30であり、15個の記述された観測の2スタックからなります。
Visual Observations: 視覚観測は、各ドローンに取り付けられた120~256セルの視野を持つ下向きカメラで撮影された16x16のグレースケールグリッドで、それぞれ[0-1]の範囲のfloat値で表示されます。この結果、合計の観測空間サイズは286です。
Continuous Actions:各エージェントは、-1~1の範囲の値を持つ3つの連続アクションを持ち、連続したアクションはドローンの動きを制御します。アクション0は前後進、アクション1は回転と左右、アクション2はドローンの上下の動きを制御します。また、ドローンの移動速度は、1タイムステップあたり1mです。
Discrete Actions:離散的な行動の空間サイズは2であり、[0, 1]の値を持つ2つのツリーとして記述することができます。離散アクション0は値1でツリーの種を落とし、アクション1は値1でメモリにロケーションを保存します。どちらの動作も、値が0であれば何もしません。
Multi-Agent Communication
この学習メカニズムでは、エージェントがグラフ構造化されたデータを受け取ることができます。ドローン同士の距離が200メートル以内にいる場合、メッセージの交換が可能です。また、マルチエージェント通信設定(MAC)において近くにいる3体に対応し、合計3つのメッセージを受信することができます。近いドローンが2つしかない場合は、それぞれ2つのメッセージしか送受信されません。メッセージの送受信にはコストがかからず、負または正の報酬を得ることはありません。

実験
実験では、4種類のセットアップを学習させました。
 実験環境
実験環境
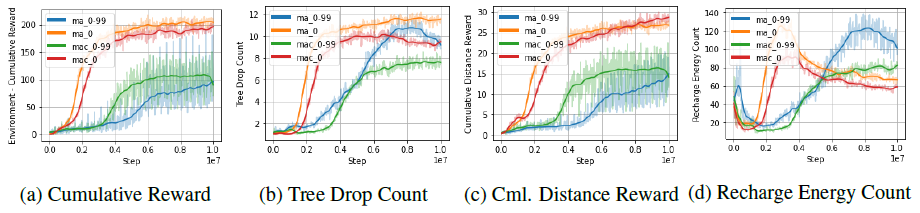 Trainingグラフ
Trainingグラフ
ベースラインとして通信機能を持たないマルチエージェントセットアップします。Experiment1とExperiment 2は、通信機能を持たずに訓練します。Experiment 1はランダムシード0の地形シナリオで、Experiment 2は0から99までのランダムシードを連続させた地形シナリオで訓練しました。 また、通信機能を持つマルチエージェントの設定でも実験を行います。Experiment 3とExperiment 4は、コミュニケーション能力を持つように訓練されます。Experiment 3はランダムシード0の地形シナリオで、Experiment 4はランダムシードが0から99の範囲で連続する地形シナリオで訓練される。 その後、すべての実験が、ランダムシード111の未見の地形シナリオでテストされます。
結果
その結果、マルチエージェントによる通信が、通信を行わないマルチエージェントのベースライン設定を上回っていることがわかりました。
 実験結果
実験結果
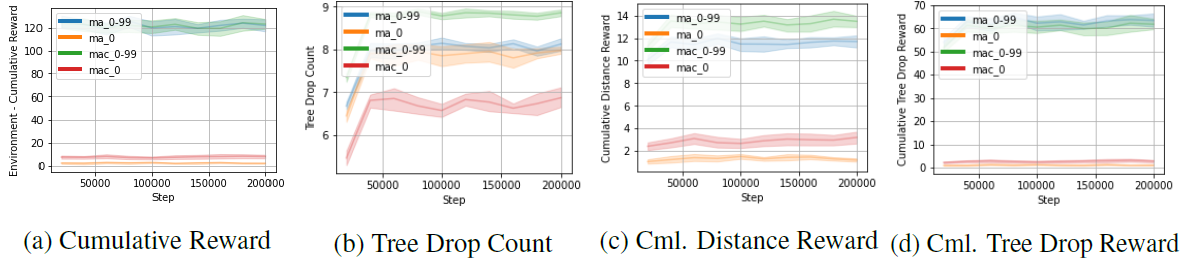 Testグラフ
Testグラフ
ランダムシードが0~99の地形シナリオで訓練されたMA 0-99セットは、累積報酬に関して、非常に良いパフォーマンスとなります。複数のシナリオで訓練されたエージェントは、単一の地形シナリオで訓練されたエージェントと比較し、大きい差でより良いパフォーマンスを発揮しました。さらに、MAC 0-99セットは、通信により、最も高いツリードロップ数を達成し、探索のために最も遠くまで移動することが観察されました(下図)。
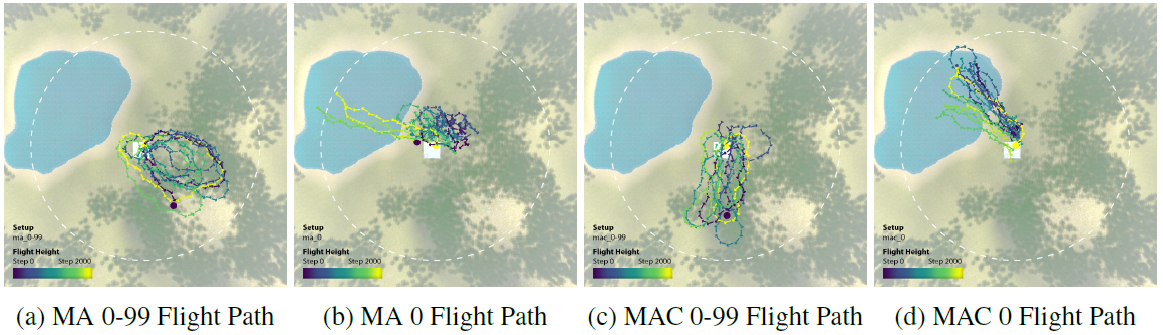
まとめ
この研究では、グラフニューラルネットワーク(GNN)の通信層を備えたマルチエージェント強化学習(MARL)を用いて、自律型ドローンによる森林再生のアプローチを探りました。その結果、未知の地形にも対応でき、通信機能がマルチエージェント集団の性能を向上させることが分かりました。また、シミュレーション環境と実世界とのギャップはまだ多くあります。
今後、このようなデジタルツインに関連する研究が進めば、メタバースなど仮想環境の用途の幅が広がることが期待出来ます。仮想環境の良さを活かし、現実にそれらを組み込む仕組みが出来れば、新しい技術発展へとつながると考えます。




この記事に関するカテゴリー





