
SegFormer: Transformerでセグメンテーション
3つの要点
✔️ Transformerを用いたセグメンテーションモデル、SegFormerを開発した。
✔️ エンコーダには階層構造のTransformerを用いることでマルチスケールの特徴量を出力し、デコーダには各出力を組み合わせるシンプルなMLPを用いて高度な表現量を出力できるようにした。
✔️ SegFormerは従来の手法と比較して、計算コストが低いにも関わらずSOTAを記録した。
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
written by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo
(Submitted on 31 May 2021 (v1), last revised 28 Oct 2021 (this version, v3))
Comments: Accepted by NeurIPS 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
背景
セマンティック・セグメンテーションはコンピュータ・ビジョンの主要な研究分野の一つで、様々な応用例があります。通常の画像分類と異なり、ピクセルレベルでカテゴリー分けをします。現在はFCN(Fully Connected Network)を用いたモデルが主要であり、様々な派生が存在します。また、画像分類との親和性から、画像分類が進展するにつれてより良いバックボーンのアーキテクチャが研究されてきました。一方で、近年自然言語処理分野でのTransformerの成功から、Transformerを画像認識にも適用する試みがなされています。そこで本論文では、効率性・精度・頑健性を考慮した、Transformerを用いたセグメンテーションモデルである、SegFormerを開発しました。
手法
SegFormerは、下図のように(1)高分解能の特徴量と低分解能の特徴量を生成する階層Transformerのエンコーダと、(2)それらのマルチスケールの特徴量を組み合わせてセグメンテーションマスクを生成する軽量のMLPデコーダから成ります。ここで$H \times W \times 3$の画像が与えられた時、$4 \times 4$のパッチに分割します。その後これらをエンコーダへのインプットとして、元の画像サイズの{$1/4, 1/8, 1/16, 1/32$}スケールの特徴量を出力します。これらの特徴量をデコーダに入れ、最終的に$\frac{H}{4} \times \frac{W}{4} \times N_{cls}$のセグメンテーションマスクを予測します。ただし$N_{cls}$はカテゴリ数です。
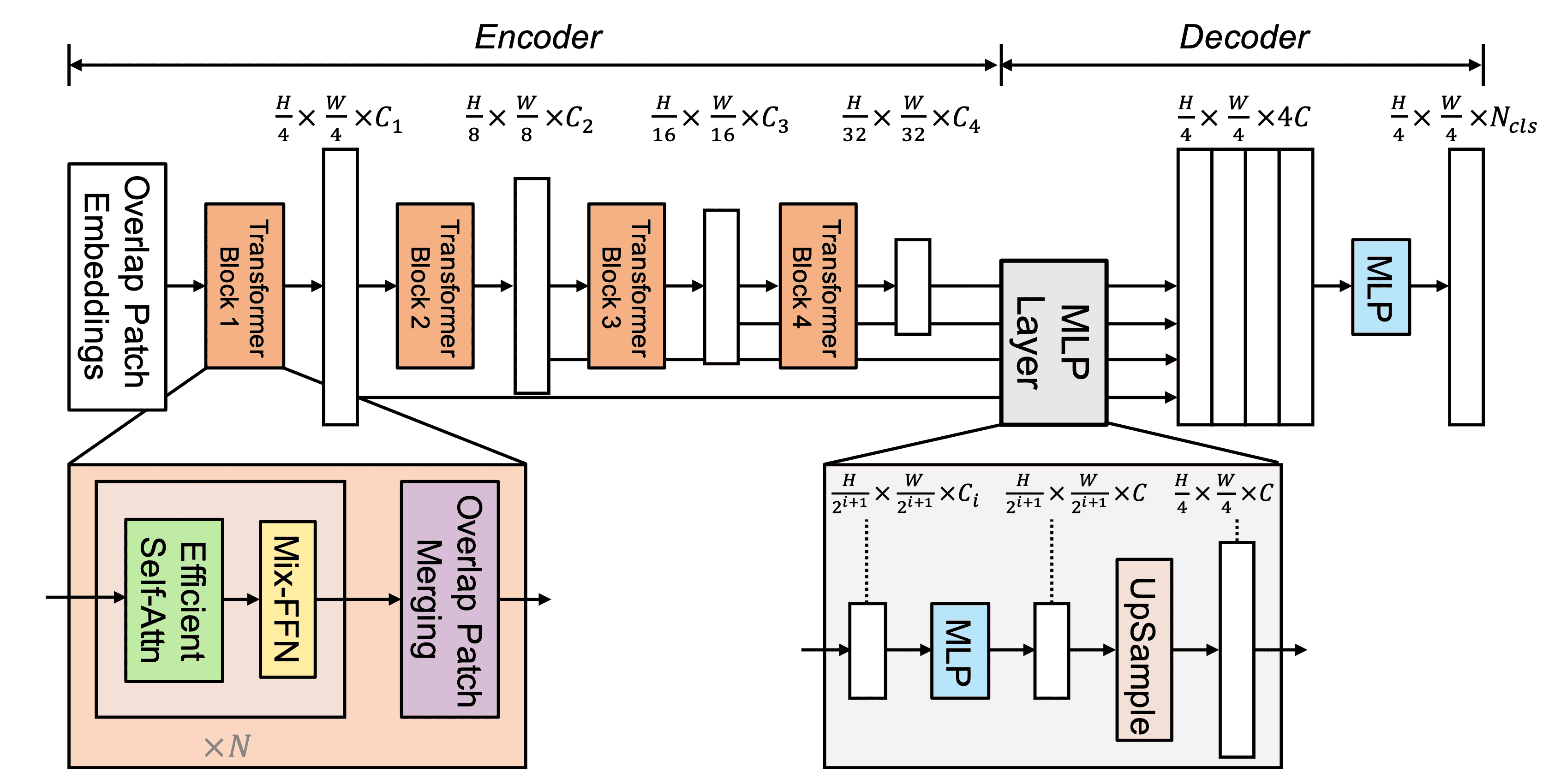
階層Transformerエンコーダ
本論文ではMix Transformerエンコーダ(MiT)のシリーズ、MiT-B0〜MiT-B5をデザインしました。これらは同じアーキテクチャですがサイズが異なり、MiT-B0は最も軽くて推測が速く、MiT-B5は最も大きくて性能が高いです。
階層的特徴量表現
単一の解像度の特徴量マップを生成するVision Transformer(ViT)と異なり、このモジュールはCNNのようなマルチスケールの特徴量を生成することを目的としています。高解像度の特徴量と低解像度の特徴量は、一般にセマンティック・セグメンテーションの性能を上げるからです。より正確には、$H \times W \times 3$の画像が与えられた時、パッチマージングを行い$\frac{H}{2^{i+1}} \times \frac{W}{2^{i+1}} \times C_i$の特徴量$F_i$を生成します。ただし$i \in \{1,2,3,4\}, \ C_{i+1}>C_i$です。
オーバーラップパッチマージング
パッチ画像が与えられたとき、ViTでのパッチマージングプロセスは$N \times N \times 3$のパッチを$1 \times 1 \times C$のベクトルにすることでした。これを真似て$F_1(\frac{H}{4} \times \frac{W}{4} \times C_1)$を$F_2(\frac{H}{8} \times \frac{W}{8} \times C_2)$のように変換しました。このプロセスはオーバーラップしていない画像を組み合わせるようデザインされたので、局所的連続性を保持できません。そこで、オーバーラップパッチマージングを行い、カーネルサイズ、ストライド、パディングサイズを調整して同じサイズの特徴量を生成するようにしました。
Efficient Self-Attention
エンコーダ計算のボトルネックとなるのはself-attention層です。従来のマルチヘッドself-attentionプロセスでは、attentionは下記のように見積もられます。
$$Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_{head}}})V$$
ただし$Q,K,V$は$N \times C$次元のベクトル、$N=H \times W$です。この計算量は$O(N^2)$なので、大きな画像には適用できません。そこで、シーケンスの長さを削減するために、下記の処理を導入します。
$$\hat{K}=Reshape(\frac{N}{R}, C\cdot R)(K)$$
$$K=Linear(C\cdot R, C)(\hat{K})$$
ただし$K$は削減されるシーケンス、$Reshape(\frac{N}{R}, C \cdot R)(K)$は$K$をサイズ$\frac{N}{R}\times (C\cdot R)$に変換、$Linear(C_{in}, C_{out})(\cdot)$は$C_{in}$次元テンソルから$C_{out}$次元テンソルを出力する線形層を表します。$R$は削減率で、計算量は$O(\frac{N^2}{R})$に減少します。
Mix-FFN
ViTはローカル情報を取り入れるためにPositional Encoding(PE)を用います。しかし、PEの分解能は固定されているので、テストデータのサイズが異なる場合、性能が低下します。そこで$3\times 3$の畳み込み層をfeed-forward network(FFN)内で用いるMix-FFNを導入しました。
$$x_{out} = MLP(GELU(Conv_{3\times 3}(MLP(x_{in}))))+x_{in}$$
ただし$x_{in}$はself-attentionモジュールからの特徴量、Mix-FFNは各FFNに$3\times 3$の畳み込み層とMLPを組み合わせます。
軽量All-MLPデコーダ
SegformerはMLP層のみからなる軽量のデコーダを採用しています。このようなことを可能としているのは、階層Transformerエンコーダが通常のCNNより広範囲の実効受容野(ERF)を持っているからです。All-MLPデコーダは下記のような4ステップからなります。
$$\hat{F_i}=Linear(C_i,C)(F_i),\forall i$$
$$\hat{F_i}=Upsample(\frac{H}{4}\times \frac{W}{4})(\hat{F_i}),\forall i$$
$$F=Linear(4C,C)(Concat(\hat{F_i})),\forall i$$
$$M=Linear(C,N_{cls})(F)$$
ただし$M$は予測マスクです。
実験
実験にはパブリックデータのCityscapes, ADE20K, COCO-Stuffを用いました。評価指標はmean IoU(mIoU)を採用しました。
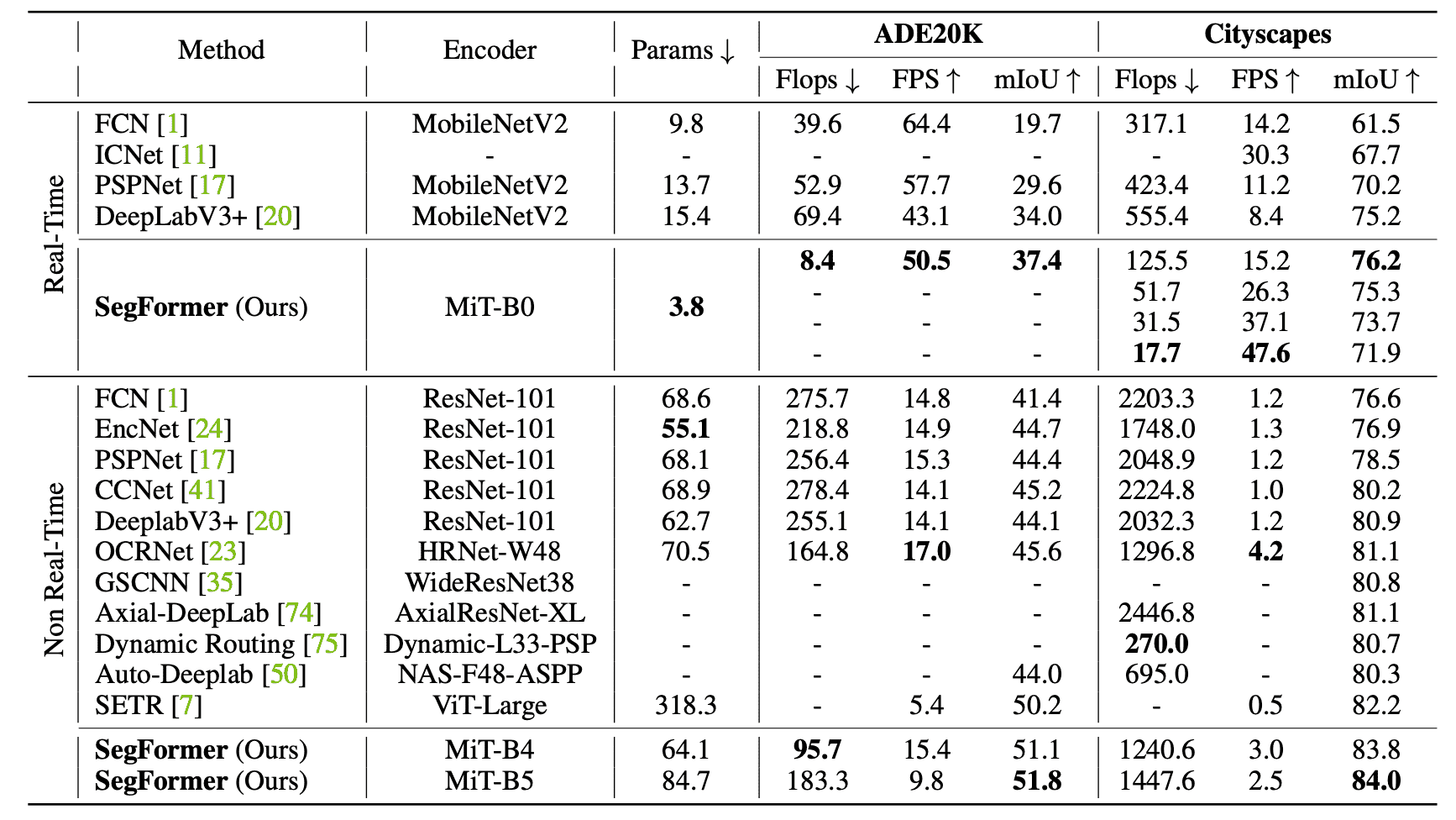
ADE20KとCityscapesでの既存のSOTAモデルとの性能比較は下表のようになりました。上側は計算速度を重視して軽い構造にしたReal-Timeモード、下側は性能を重視したNon Real-Timeモードです。
どちらのデータセットに対しても、従来のモデルと比べて少ないパラメータ数にも関わらず高い性能を示しており、計算速度と精度改善の両方を行うことができました。
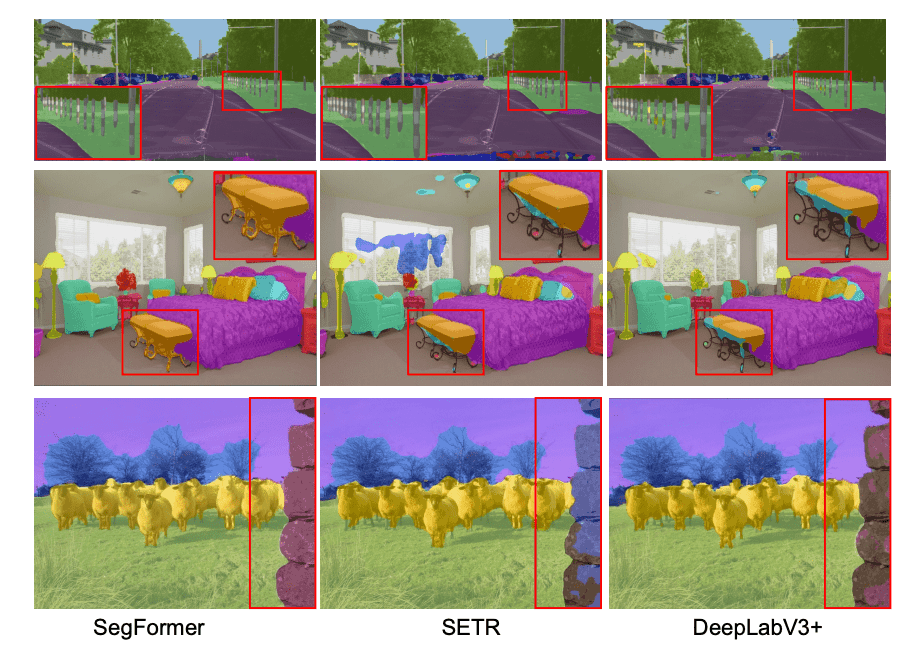
また、定性的な結果は下図のようになりました。SegFormerのエンコーダは、より高精度の特徴量を取り入れることができるため、より詳細なテクスチャ情報を保存でき、推測結果はオブジェクト境界などもより精細に予測できています。
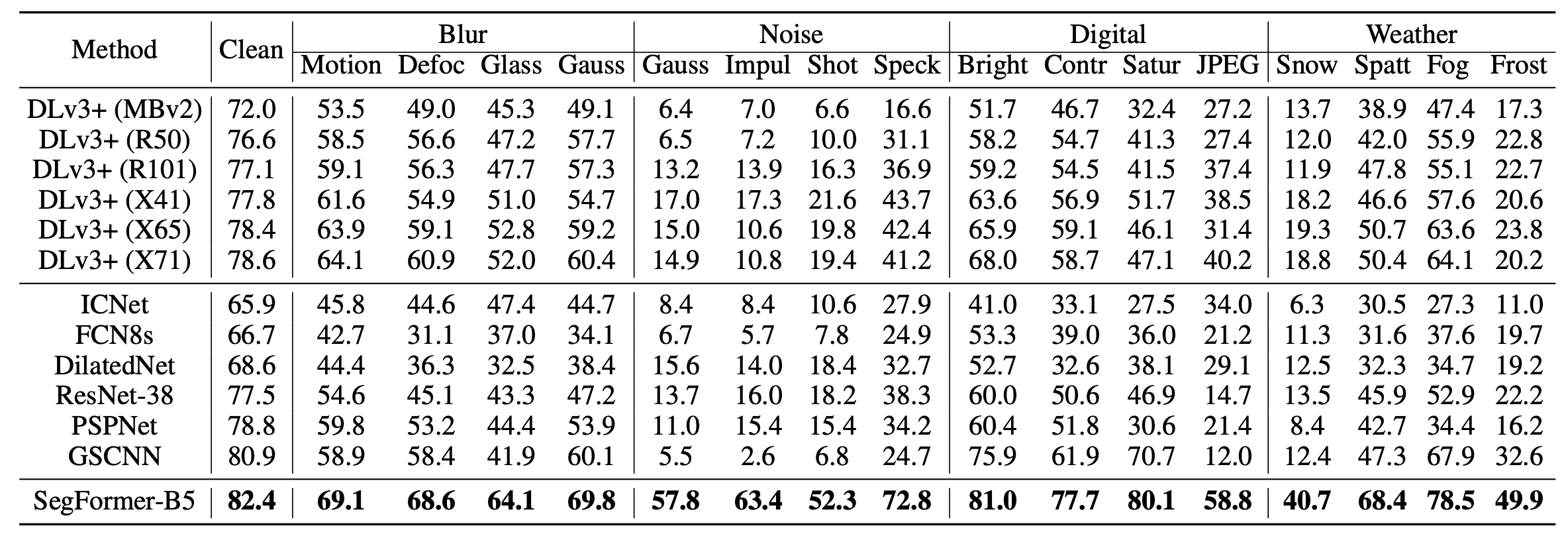
最後に、自動運転などでは頑健性が重要です。これを評価するために、Cityscapesのバリデーションデータに様々なノイズを加えたデータセットCityscapes-Cに対して実験しました。結果は下表のようになりました。
SegFormerは従来のモデルと比べて大幅に高いIoUを示しており、安全性を求められる産業への応用が期待できる結果となりました。
まとめ
本論文では、Transformerを用いたセグメンテーションモデルであるSegFormerを提案しました。既存モデルと比べ、重い計算処理部分を無くすことで、高効率に高い性能を得ることができました。また、高い頑健性があることも分かりました。パラメータ数は大幅に減ったものの、メモリ容量の少ないエッジデバイス上で働くかは不鮮明であり、これを見極めることが今後の課題です。






この記事に関するカテゴリー





