
新しい半教師ありセグメンテーション: contrastive-consistent learning
3つの要点
✔️ 半教師ありセグメンテーションで、ピクセルのconsistency propertyとcontrastive propertyの両方を考慮した初のフレームワークを開発した。
✔️ 既存の画像レベルでのcontrastive learningをピクセルレベルへ拡張した。特に計算コストと偽陰性率を下げるために新しいnegative sampling手法を用いた。
✔️ 既存のベンチマーク実験において、SOTAを記録した。
Pixel Contrastive-Consistent Semi-Supervised Semantic Segmentation
written by Yuanyi Zhong, Bodi Yuan, Hong Wu, Zhiqiang Yuan, Jian Peng, Yu-Xiong Wang
(Submitted on 20 Aug 2021)
Comments: ICCV 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
今日のディープラーニングを用いたセマンティック・セグメンテーションは、大量のラベルデータを必要としており、ラベルデータが減ると性能が大幅に低下してしまいます。しかしながら、膨大なラベルデータを生成することはコストが高く、少量のラベルデータで性能を保つ半教師あり学習が注目されています。そこで、本論文では2つの満たすべき特性を備えた半教師あり学習モデルを提案しました。1つはラベル空間でのconsistency propertyと呼ばれ、オブジェクトの色などを変えた時にセグメンテーション結果が変化しないことを示します。もう1つは特徴量空間でのcontrastive propertyと呼ばれ、モデルの特徴量が、似たピクセルを同じグループにし、似ていないピクセルを別のグループにする能力があることを示します。従来の半教師あり学習のSOTAモデルは、上述のconsistency propertyを考慮していますが、contrastive propertyはあまり考慮されてきませんでした。本論文では、両者を考慮したピクセルcontrastive-consistent半教師ありセグメンテーション手法(${\rm PC^2Seg}$)を提案しました。
手法
本手法の概略図を下図に示します。
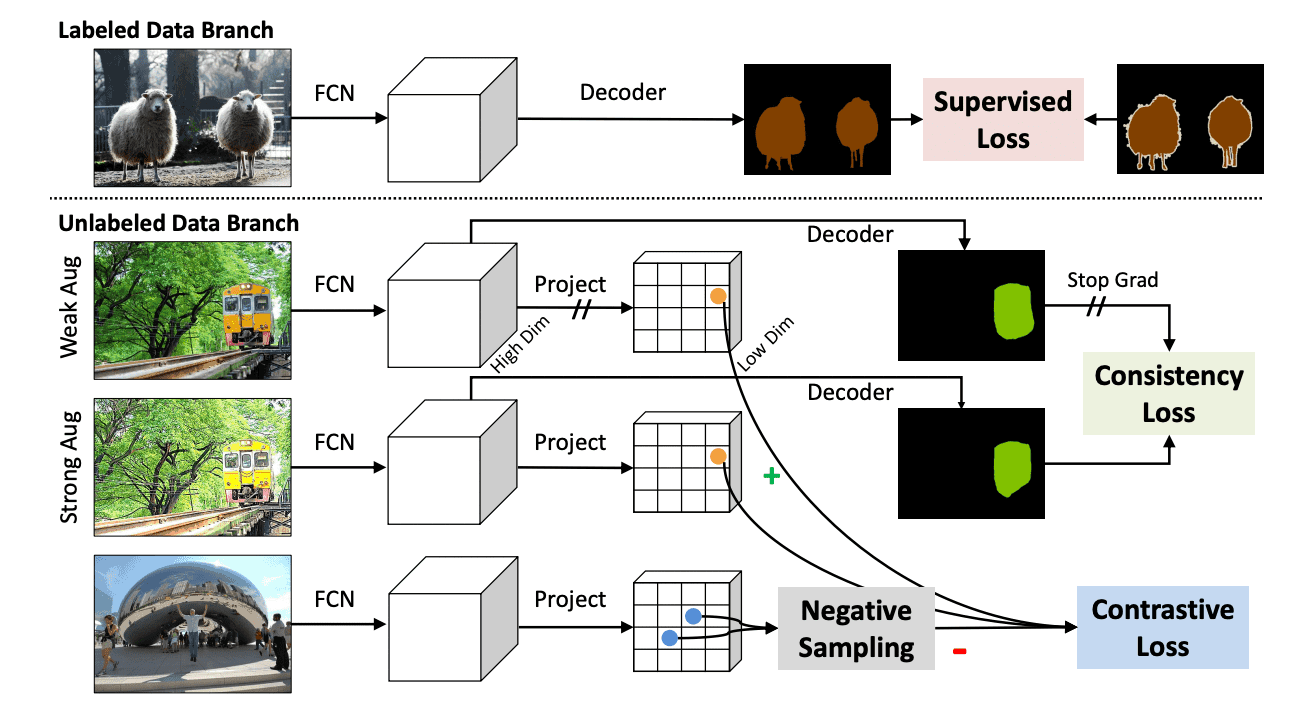
${\rm PC^2Seg}$のloss関数はラベルありデータとラベルなしデータのloss関数の総和で次のように表されます。
$${\cal L}={\cal L}^{label}(x,y)+{\cal L}^{unlabel}(x)$$
ただし$x$は画像、$y$はマスク画像です。ラベルありデータのloss関数は、通常のクロスエントロピーを用いました。ラベルなしデータのloss関数は、強弱のオーグメンテーションを掛けたデータを用いた、シャムネットワークのアーキテクチャで計算しました。最終的に、consistency loss $l^{cy}$とcontrastive loss $l^{ce}$を用いて次のように表されます。
$${\cal L}^{unlabel}=\sum_{i}\lambda_1 l^{ce}(z_i,z_i^+, \{z_{in}^-\}_{n=1}^N)+\lambda_2 l^{cy}({\hat {\bf y}}_i, {\hat {\bf y}_i^+})$$
ただし$i$はピクセルのインデックス、$z_i$は弱オーグメントした画像のアンカーピクセル、$z_i^+$は強オーグメントした画像の正のピクセル、$z_{in}^-$は負のピクセル、${\hat {\bf y}}_i, {\hat {\bf y}_i^+}$はそれぞれのモデルの予測確率です。また、$\lambda$はバランスパラメータです。
Consistency loss
consistency loss $l_i^{cy}$は次のように定義されます。
$$l_i^{cy}=1-\cos({\hat {\bf y}_i}, {\hat {\bf y}_i^+})$$
ここで$\cos({\bf u}, {\bf v})=\frac{{\bf u}^T{\bf v}}{||{\bf u}||_2||{\bf v}||_2}$はcosine類似度です。さらに弱オーグメントした画像では勾配ストップを導入し、強オーグメントした画像でバックプロパゲーションするようにしました。
Contrastive loss
contrastive loss$l_i^{ce}$は次のように定義されます。
$$l_i^{ce}=-\log{\frac{e^{\cos({\bf z}_i, {\bf z}_i^+)/\tau}}{e^{\cos({\bf z}_i,{\bf z}_i^+)/\tau}+\sum_{n=1}^Ne^{\cos({\bf z}_i,{\bf z}_{in}^-)/\tau}}}$$
ただし${\bf z}_i\in {\mathbb R}^D$は$D$次元の特徴量ベクトル、$\tau$は温度パラメータです。
しかしながら、上式を最適化するには問題点があります。まず、特徴量ベクトルは高次元のため、計算量が膨大になります。そこで、線形写像レイヤを追加することで次元を低次元にします。また、ピクセル毎に見ているため、負サンプル数が膨大になり、誤った負サンプルに対するノイズ影響が大きくなります。そこで、新しいサンプリング手法を用いました。
Negative Sampling手法
$i$番目のアンカーピクセルに対し、$N$個の負ピクセル$z^-_{in}$が次のような離散確率分布に従うとします。
$$z_{in}^-\sim Discrete(\{z_j\}_{j=1}^M;\{p_{ij}\}_{j=1}^M)$$
$\{p_{ij}\}$について、下記の4手法を考えました。
Uniform
単純にミニバッチ内のアンカー以外の全てのピクセル$M$からサンプルします。しかし、同一画像内のピクセルは同じカテゴリーに属するものが多いので、多くの偽陰性を取ります。
$$p_{ij}=\frac{1}{M}$$
Different Image
偽陰性を減らすために、アンカーと異なる画像からサンプルします。$I_i, I_j$をアンカー、負サンプルの候補画像のIDとすると、次のようになります。
$$p_{ij}=\frac{{\bf 1}\{I_i\neq I_j\}}{\sum_{k=1}^M{\bf 1}\{I_i\neq I_k\}}$$
Pseudo-Label Debiased
${\hat y}_i, {\hat y}_j$をそれぞれピクセル$i,j$の予測ラベルとします。これらを擬ラベルとして、アンカーと異なるクラスに予測されるピクセルからサンプルします。
$$p_{ij}=\frac{P({\hat y}_i\neq{\hat y}_j)}{\sum_{k=1}^MP({\hat y}_i\neq{\hat y}_k)}=\frac{1-{\vec{\bf y}_i^T}{\vec{\bf y}_j}}{\sum_{k=1}^M1-{\vec{\bf y}_i^T}{\vec{\bf y}_k}}$$
Different Image + Pseudo-Label Debiased
上記2手法を組み合わせることで、より偽陰性を減らすことができます。
$$p_{ij}=\frac{{\bf 1}\{I_i\neq I_j\}\cdot (1-\vec{{\bf y}}_i^T\vec{{\bf y}}_j)}{\sum_{k=1}^M{\bf 1}\{I_i\neq I_k\}\cdot(1-{\vec{{\bf y}}_i^T}{\vec{{\bf y}}_j})}$$
本論文ではこの手法を用いました。
結果
パブリックデータセットのVOC 2012, Cityscapes, COCOに対して性能評価しました。結果はそれぞれ下表のようになりました。
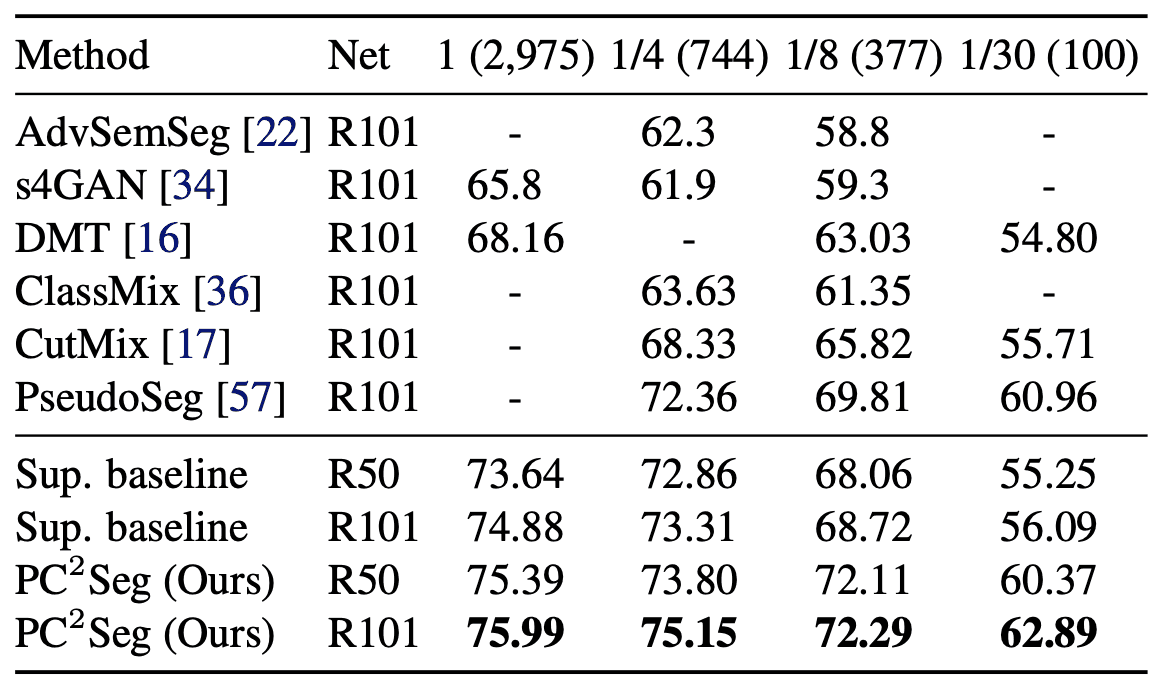

ここで$1/N$の列はラベルデータを全体の$1/N$のみ用いています。表から、全てのデータセットで本手法($PC^2Seg$)がSOTAを記録しています。特に、Cityscapesでは、全データを使った場合と1/4を使った場合で0.84%しか異なりません。また、ResNet50でもResNet101と遜色ない性能を示しており、少量のデータではアーキテクチャをそこまで深くする必要がないことを示唆しています。
まとめ
本論文では、ピクセルcontrastive-consistent learningと呼ばれる、新しい半教師ありセグメンテーション手法を提案しました。また、効率的にcotrastive lossを学習するために、新しいnegative sampling手法を用いました。本手法は既存のベンチマークでSOTAを記録し、半教師ありセグメンテーションを改善する有力な方法であることが分かりました。






この記事に関するカテゴリー


