
量子コンピューティング(アニーリングマシン)で時系列データクラスタリング
3つの要点
✔️ 日本国内の大学と富士通との時系列データクラスタリングについての共著論文です。
✔️ 量子コンピュータ(アニーリングマシン)を用いて、より高速、高精度な時系列データクラスタリングを実現しています。
✔️ 既存手法2つと比較し、オンライン分散データセットおよび流量測定画像データセットにおいて優れたクラスタリング特性を確認しました。
Clustering Method for Time-Series Images Using Quantum-Inspired Computing Technology
written by Tomoki Inoue, Koyo Kubota, Tsubasa Ikami, Yasuhiro Egami, Hiroki Nagai, Takahiro Kashikawa, Koichi Kimura, Yu Matsuda
[Submitted on 26 May 2023 (v1), last revised 18 Jul 2023 (this version, v3]
Comments: 13 pages, 4 figures
Subjects: Signal Processing (eess.SP); Computer Vision and Pattern Recognition (cs.CV); Fluid Dynamics (physics.flu-dyn)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
時系列クラスタリングは、クラスタに関する事前知識がない場合の時系列データに対する強力なデータマイニング手法として機能します。大規模な時系列データが大量に取得され、様々な研究分野で利用されています。そのため、計算コストの低いクラスタリング手法が求められています。
この論文の特長は量子コンピュータ(アニーリングマシン)で用いられる量子計算技術を、このクラスタリングに適用していることです。アニーリングマシンは、組合せ最適化問題を高速かつ高精度に解くという点で従来の計算機を凌駕しており、既存の手法では困難であったクラスタリングの実現が期待されます。
本研究では、アニーリングマシンを活用した新しい時系列クラスタリング手法を提案します。提案手法は、外れ値に対する頑健性を維持しつつ、時系列データを互いに近いクラスタに均等に分類することを容易にします。
さらに、この手法は時系列画像にも適用可能です。提案手法を、オンライン分散データセットをクラスタリングする標準的な既存手法と比較しました。既存の方法では、各データ間の距離はユークリッド距離メトリックに基づいて計算され、クラスタリングはk-means++法を用いて行われます。両手法とも同等の結果が得られることがわかりました。
さらに、提案手法を、S/N比が約1の顕著なノイズを含む流量測定画像データセットに適用しました。信号のばらつきが約2%と小さいにもかかわらず、提案手法はクラスタ間で重複することなくデータを効果的に分類しました。
一方、既存の標準的な手法や、流量計測データに特化した手法である条件付き画像サンプリング(CIS)手法によるクラスタリング結果では、クラスタが重複していました。その結果、提案手法は他の2つの手法よりも優れた結果を示し、優れたクラスタリング手法としての可能性を示しました。
はじめに
クラスタリングは、グループに関する十分な事前知識がない場合に、データを関連するグループに分類するための強力なデータマイニング手法です。特に時系列データを扱う場合、クラスタリング技法は時系列クラスタリングと呼ばれます。時系列クラスタリングに関する多くの研究が行われており、それらはレビュー論文にまとめられています。(論文引用2,7-10)また、時系列クラスタリングのためのいくつかのライブラリがウェブ上で公開されており、広く利用されています。この文献に従って、時系列クラスタリングは、"与えられた時系列データセットを、ある特定の類似性尺度に基づいて、同種の時系列がグループ化されるように、教師なしでクラスタに分割するプロセスを時系列クラスタリングと呼ぶ "と定義されます。
時系列クラスタリングには、生データベース/形状ベース、特徴ベース、モデルベースの3つの主な手法が一般的に採用されています。これらの方法は、最初の計算手順が異なります。生データベース/形状ベースアプローチは、クラスタリングに直接生データを使用し、特徴ベースアプローチは、生データを低次元の特徴ベクトルに変換します。モデルベースのアプローチは、時系列データが確率過程モデルから生成され、モデルのパラメータがデータから推定されると仮定します。クラスタが近接している場合、モデルベース・アプローチの性能は低下するため、通常は生データベース・アプローチと特徴ベース・アプローチが使用されます。その後のステップでは、2つのデータ、特徴ベクトル、モデル間の類似度や距離を計算します。
次に、機械学習手法を用いて、測定された類似度や距離に基づいてデータをクラスタにグループ化します。時系列データに一般的に採用されているクラスタリングアルゴリズムには、パーティショニング、階層型、モデルベース、密度ベースのクラスタリングアルゴリズムがあります。分割クラスタリングアルゴリズムの中で、k-meansクラスタリングは最も広く使用されているアルゴリズムの1つです。その主な利点は、計算コストの低さにあります。しかし、この方法は、ユーザーによって事前に決定されるクラスタ数を必要とします。階層クラスタリング・アルゴリズムでは、クラスタ数を事前に決定する必要はありません。しかし、分割法や凝集法を用いて一旦分割または結合されたクラスタは、調整することができません。モデルベースのクラスタリングアプローチとして、自己組織化マップや隠れマルコフモデルなどのニューラルネットワークアプローチが使用されます。これらのアプローチでは、近いクラスタほど性能が低下するという前述の欠点に加えて、計算コストが高いという問題があります。密度ベースの手法、例えば密度ベース空間クラスタリング(Density-based spatial clustering of applications with noise:DBSCAN)は、クラスタ数を事前に決定する必要がなく、外れ値に頑健です。
しかし、これらの方法ではパラメータの適切な選択が難しく、次元の呪いに苦しむことが知られています。
提案手法
本研究では、アニーリングマシンを用いた新しい時系列クラスタリング手法を提案します。量子アニーリングやシミュレーテッドアニーリングなどのアニーリングマシンは、組合せ最適化問題を従来の計算機よりも高速かつ高精度に解くことができます。したがって、提案手法は、既存の手法では困難なクラスタリングタスクを達成できると期待されます。提案手法のユニークな特徴の一つは、外れ値に対する頑健性を維持しながら、時系列データを密接に関連するクラスタに均等に分類できることです。さらに、本手法は、周期的な時系列画像を複数の位相範囲に均等に分類するよう特別に設計されています。これは、周期に対して時系列データの継続時間が長いことを考慮し、各位相に対して十分な数の画像を想定しているためです。
クラスタリング計算には、量子に着想を得た計算技術の一つである富士通の第3世代デジタルアニーラ(DA3)を用いました。DA3は2次制約なし2値最適化(QUBO)問題を解くことができ、クラスタリング問題は等価的にQUBO問題であるイジングモデルとして定式化できます。DA3は、最大100kbitsの大規模な問題空間で解を提供します。1つは "UEA & UCR time- series classification repository "から得られたものであり、もう1つは著者らの以前のデータで得られたKármán vortex streetを捉えた流れ測定画像データから構成されています。特に流量計測データを選んだのは、一般的に高次元(~106)であり、計測ノイズを含んでいるからです。クラスタリング処理には、生データベースと特徴ベースのアプローチを採用しました。さらに、既存の標準的な手法、特にオンラインで入手可能な "tslearn "、および条件付き画像サンプリング(CIS)法(流量測定データのみ)から得られた結果と比較しました。
結果と議論
オンラインで利用可能な時系列データセットのクラスタリング
提案手法をUEA & UCRの時系列分類リポジトリから入手可能な "crop "データセットの分類に適用することを実証しました。 "tslearn "の "TimeSeriesKMeans "関数と提案手法を用いたクラスタリング結果を図1に示します。作物」データセットには24のクラスタが含まれていました。しかし、ここでは代表的な2つのクラスタの結果を示します。このデータセットでは、正しい分類が既知であり、図1に表示されています。さらに、各手法のアンサンブル平均データを計算しました。図1(a)に示すように、提案手法はデータの分類に成功しましたが、標準的な既存手法(tslearn)で得られた結果には好ましくない分類が見られました。そこで、提案手法とtslearnで得られた分類結果の平均二乗誤差(RMSE)を計算しました。図1(a)に示す提案手法と既存手法のRMSEは、それぞれ0.013と0.015でした。これにより、提案手法が標準的な既存手法を凌駕していることがさらに確認されました。一方、図1(b)に示す提案手法と既存手法のRMSEは、それぞれ0.013と0.009でした。この条件では、提案手法は既存手法に劣る結果となりました。しかし、図1(b)のように正解データの分散が大きいため、分類は本質的に困難です。したがって、提案手法は従来手法と遜色のない結果が得られると結論づけることができます。
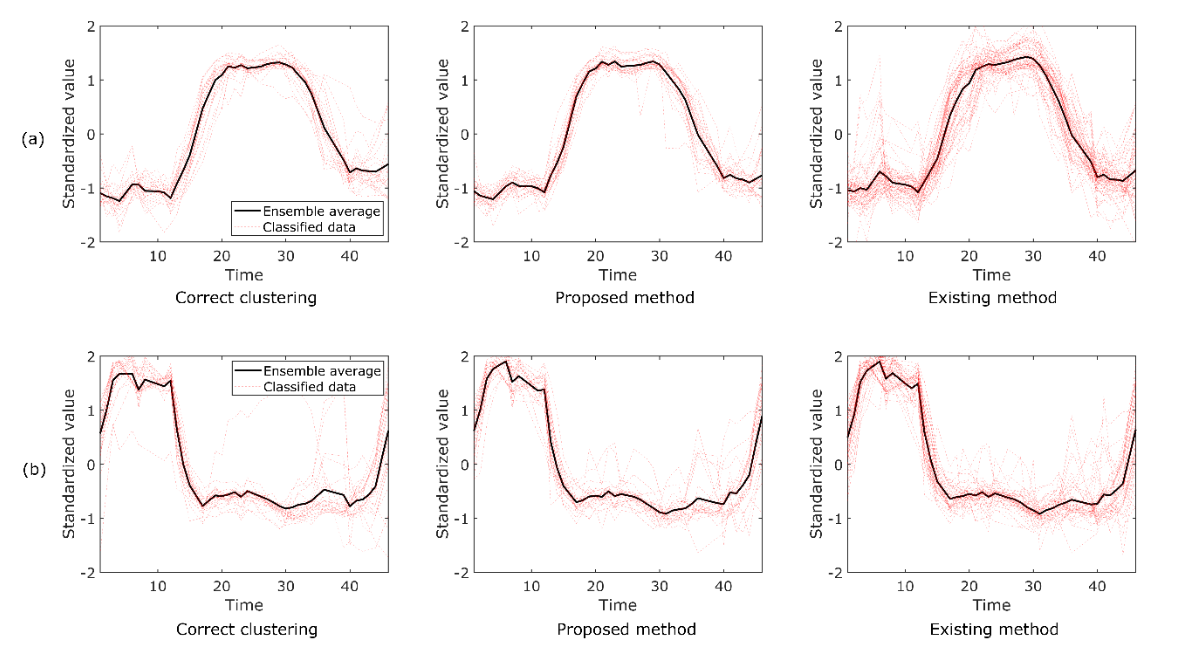
| 図1. UEA & UCR時系列分類リポジトリからの "crop "データセットに対する、提案手法と既存手法による典型的なクラスタリング結果。それぞれ(a)と(b)に、リポジトリでクラス1とクラス17とラベル付けされたデータを示す。 |
流量計測時系列データセットのクラスタリング
本研究では、本手法を流量計測データセットに適用し、ノイズの多いデータに対する有効性を実証した。典型的なスナップショットのデータを図2に示すが、画像からS/N比が約1と顕著なノイズが含まれていることがわかる。
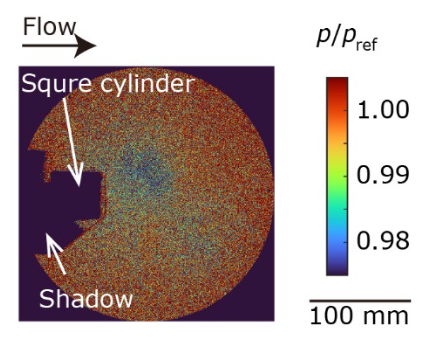
| 図2. 圧力𝑝は大気圧𝑝で規格化されている。Inoue et al. |
本研究では、提案手法である「tslearn」とCIS法を用いて、この時系列データを9つのクラスタに分類した。クラスタリング結果は図3に示すように、多次元尺度構成法(MDS)を用いてデータを2次元散布図に示した。MDSの計算では、データ𝐱𝑖と𝐱jの距離は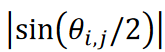 として表される、 ここで、|a| はa の絶対値を表し、
として表される、 ここで、|a| はa の絶対値を表し、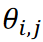 はデータベクトル𝐱𝑖と𝐱jの間の角度に対応します。ここで使用したKármán渦の通りのデータセットは最大距離が単一である周期的な現象であるため、データは半径1/2の円に沿って分布しました。図3に示すように、提案手法は重複なくデータを分類することに成功しました。
はデータベクトル𝐱𝑖と𝐱jの間の角度に対応します。ここで使用したKármán渦の通りのデータセットは最大距離が単一である周期的な現象であるため、データは半径1/2の円に沿って分布しました。図3に示すように、提案手法は重複なくデータを分類することに成功しました。
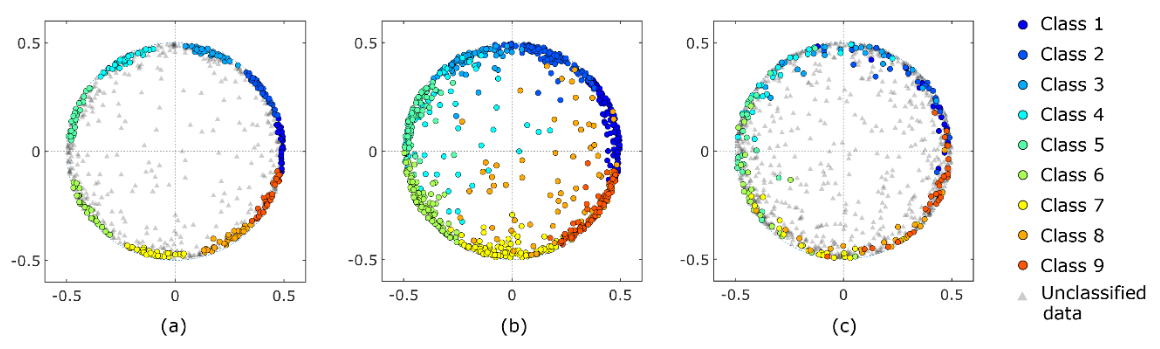
| 図3. MDSによる2次元散布図。(a)提案手法による結果、(b)既存の標準手法(tslearn)による結果、(c)CIS手法による結果。 |
データ点は各クラスタに均等に分類され、クラスタの大きさは互いに類似していました。半径1/2の円から外れたデータ点は外れ値とみなされたが、これはこれらのデータが周期的な現象から逸脱した外乱とみなされたためです。しかし、標準的な既存の方法では、外れ値はいずれかのクラスターに分類されました。これでは、データのアンサンブル平均を計算する際に不適切です。CIS法では、円上のデータのみが分類されます。しかし、いくつかのクラスターは重複領域を示し、個別のクラスターを形成しませんでした。ノイズを含むアプリケーションの密度ベース空間クラスタリング(DBSCAN)のような密度ベースの手法は、強力なクラスタリング手法として知られています。しかし、DBSCANでは円上のデータ点は1つのクラスタに分類されました。
アンサンブル平均した圧力分布を図4に示します。提案手法(図4a)とCIS手法(図4c)は、圧力変動が2%程度と小さいにもかかわらず、周期的な渦の発生をよく抽出しています。一方、標準的な手法で得られた圧力分布では、周期的な運動を正確に抽出することができませんでした。例えば、上側に位置する渦はフェーズ2からフェーズ3にかけて突然消滅し、上側に位置する渦はフェーズ5からフェーズ6にかけて流れ方向が反転しました(図4b)。この矛盾は、図3bで観察されたクラスターの重なりに起因します。渦が発生すると圧力が低下するため、渦中心での最小圧力を提案手法とCIS手法で比較しました。アンサンブル平均圧力は提案手法でp/pref = 0.982 ± 0.001、CIS手法でp/pref = 0.984 ± 0.002であり、誤差は標準偏差、pref は大気圧を表す。この差は、CIS法では、異なる位相のデータもアンサンブル平均化プロセスに含まれるため、前述のオーバーラップクラスターによって渦が弱まったことを示しています。これらの結果は、提案手法が周期現象を解析するための強力なクラスタリング手法であることのさらなる証拠となります。
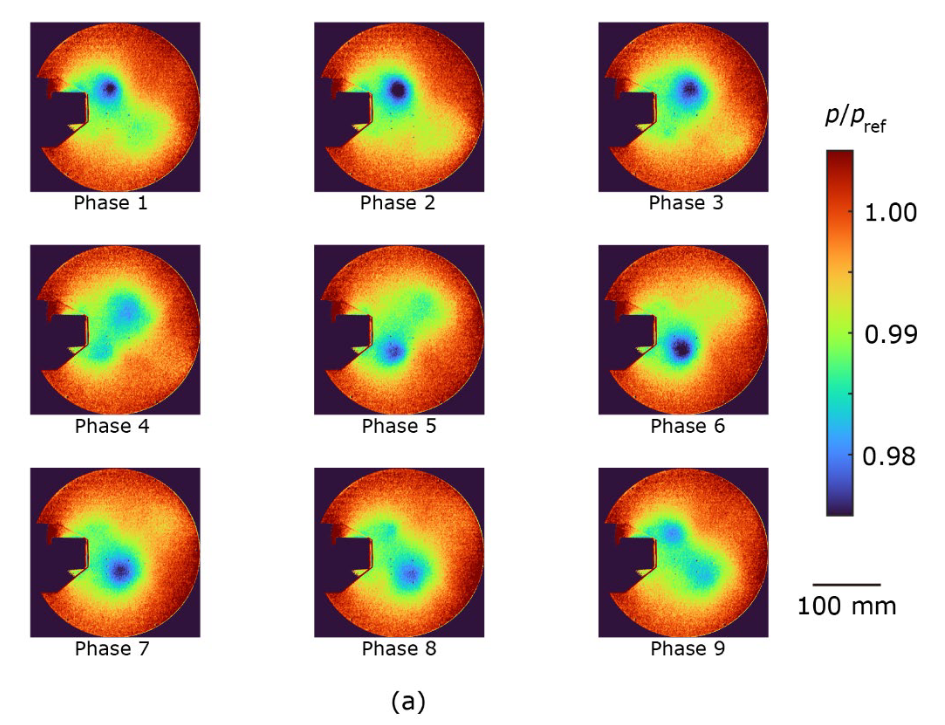
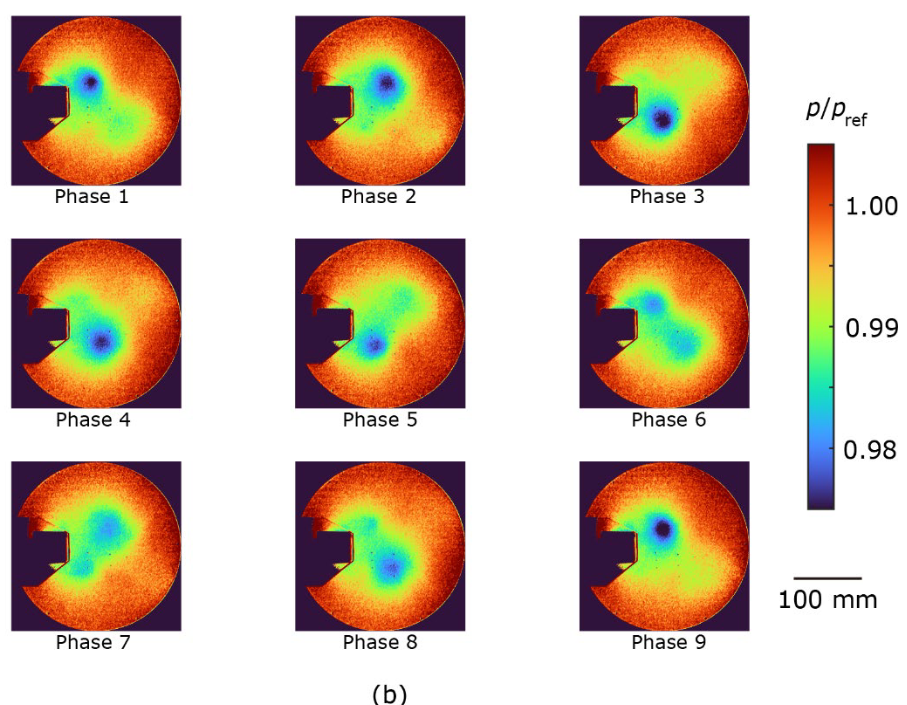
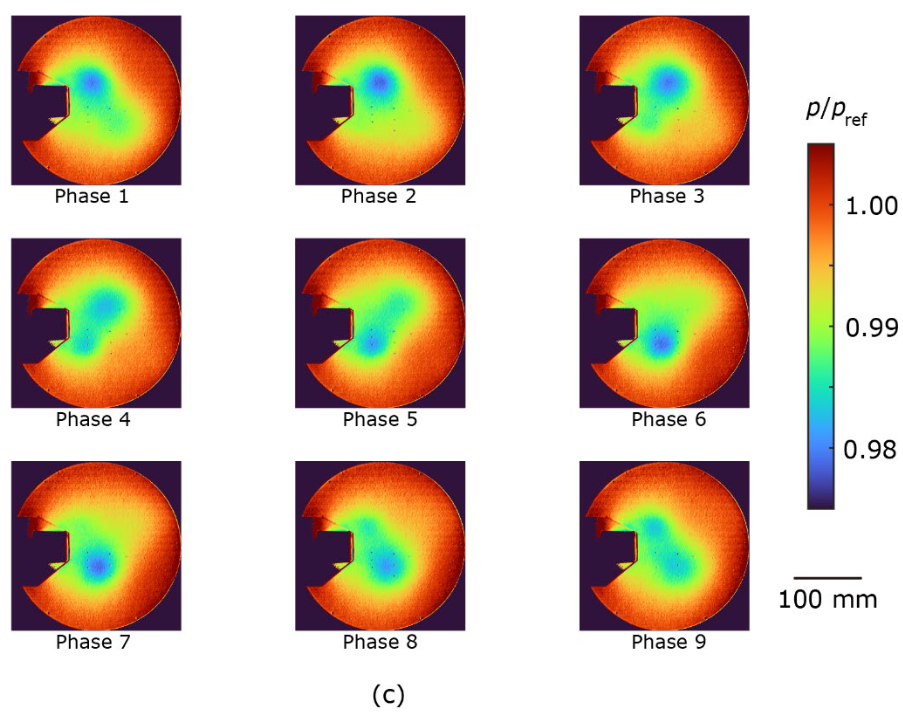
| 図4. (a)提案手法、(b)既存の標準手法(tslearn)、(c)CIS手法のアンサンブル平均圧力分布。圧力pは大気圧prefで正規化。 |
資料と手法
時系列クラスタリングの提案手法
アニーリングマシンを用いた新しいクラスタリング手法を提案する。我々は、時系列データ分析における生データベースと特徴ベースのアプローチに注目した。 クラスタリング問題のハミルトニアンは以下のように記述されます:
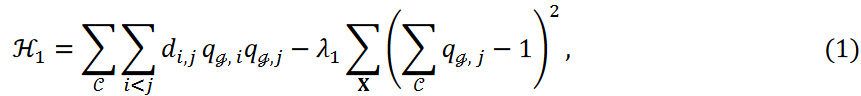
ここで

𝐱iと𝐱𝑗の距離の類似度または逆数を𝑑𝑖,𝑗と表し、λ1をハイパーパラメータとします。和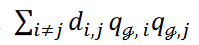 はクラスタに属する2つのデータ点間の類似度または距離の逆数の和を表します。総和∑𝒞は式1の第1項の全クラスタにわたる総和を表します。クラスタリングは
はクラスタに属する2つのデータ点間の類似度または距離の逆数の和を表します。総和∑𝒞は式1の第1項の全クラスタにわたる総和を表します。クラスタリングは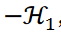 と最小化され、
と最小化され、
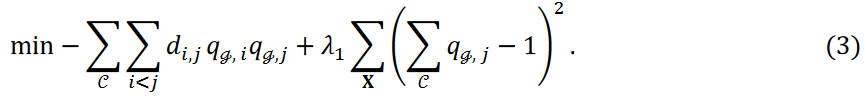
式3の第2項は、データ点が1つのクラスターにのみ属することを保証する制約項を表します。 値𝜆1はこの制約の厳しさを決定し、値が小さいほど、いくつかのデータ点が外れ値として扱われ、どのクラスターにも割り当てられない可能性があります。本研究では以下の最小化問題を検討しました:
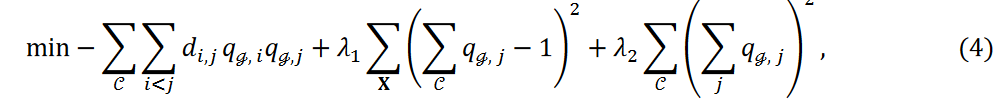 ここで、式4の第3項である新しい項は、各クラスタに分類されるデータ点の数を調整します。表記を簡単にするために
ここで、式4の第3項である新しい項は、各クラスタに分類されるデータ点の数を調整します。表記を簡単にするために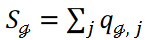 と表し、クラスタCℊに属するデータ点の数を示します。そして、式4の第3項は次のように書かれます。
と表し、クラスタCℊに属するデータ点の数を示します。そして、式4の第3項は次のように書かれます。
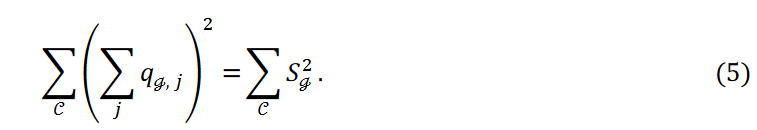
各クラスタに属するデータ点の平均数と分散は、それぞれ𝜇と𝜎2で表されます。式5は次のように書かれます。
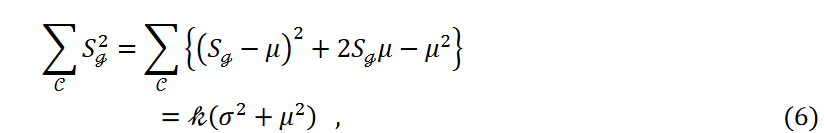
ここで、データ点の数𝑛とクラスタの数kは固定で、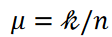 は定数です。そして、分散が小さくなるにつれて、つまり式4の第3項が小さくなるにつれて、データポイントは各クラスタに均等に分類されます。
は定数です。そして、分散が小さくなるにつれて、つまり式4の第3項が小さくなるにつれて、データポイントは各クラスタに均等に分類されます。
デモ用時系列データセット
提案するクラスタリング手法を2つの時系列データセットに適用しました。データセットの一つは "crop "と名付けられ、UEA & UCRの時系列分類リポジトリから入手しました。
これらの時系列データは、FORMOSAT-2衛星が撮影した画像から得られたものです。データセットは農業土地被覆マップに対応する24のクラスで構成され、各データはその時間的変遷に対応します。本研究では、"tslearn "の "TimeSeriesKMeans "関数を用いました。この関数のパラメータは、クラスタ数は24、メトリック(各データ間の距離)はユークリッド、初期化方法はk-means++、その他のパラメータはデフォルト値を採用しました。これは標準的な時系列クラスタリング手法です。提案手法では、ユークリッド距離もメトリックとして使用し、式4の第1項を最小化するためにメトリックの逆数を使用しました。このデータセットでは全てのデータ点がいずれかのクラスタに属する必要があるため、パラメータ𝜆1は𝜆2の約100倍としました。この条件では、すべてのデータ点がいずれかのクラスタに属する(式4の第2項が0)という解が得られました。
本研究で使用した2つ目のデータセットは、感圧塗料(PSP)法を用いた測定で得られたフロー画像データです。PSPは、PSPコーティングに組み込まれた色素から放出される燐光の酸素消光に基づく圧力分布測定技術です。測定されたデータは、四角い円筒の背後にあるKármán渦の通りによって引き起こされる圧力分布でした。データサイズは780×780の空間格子です。流速は50m/s、レイノルズ数は1.1×105でした。燐光強度の変動が小さいため、圧力差はPSP法を検出するには小さすぎました。そして、測定された圧力には顕著なノイズが含まれており、データからノイズを減らす必要があります。カルマン渦が周期的な現象であることはよく知られています。ノイズを減らし、時系列クラスタリングの目的の一つである有意なパターンを抽出するために、データはいくつかの位相グループに分類され、これらのグループ内で平均化しました。渦の位相情報に着目したため、データ間の類似性を評価するために余弦類似度尺度を使用しました。PSPデータは2つの空間次元と1つの時間次元を持つ時系列画像データであるため、圧力分布データは列ベクトルに再整形されました。その結果、時系列PSPデータは𝑛時系列データ𝐱 = {𝐱1,𝐱2 ⋯ , 𝐱𝑛}と書かれ、𝐱𝑖は再形成された圧力分布に対応するベクトルです。測定されたPSPデータには大きなノイズが含まれているため、類似度の計算にはノイズ除去されたデータが使用されました。文献に従い、ノイズの少ないデータセットは、切断特異値分解(SVD)を考慮することで得られます。ここでデータ行列Yはベクトル𝐱𝑖を時系列に並べることで得られます。SVDで表すと:

ここで行列 𝐔 と𝐕 はユニタリー行列であり、上付き文字 ⊤ は転置を示します。行列Σは特異値を降順に並べた対角行列です。データが以下のように切り捨てられたSVDで近似できることはよく知られています:

ここで 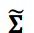 は最初の対角行列で 𝑟 × 𝑟 は切り捨てランクです。行列
は最初の対角行列で 𝑟 × 𝑟 は切り捨てランクです。行列 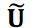 と
と 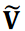 は に対応する縮小行列です。そして、ノイズを低減した時系列データ行列
は に対応する縮小行列です。そして、ノイズを低減した時系列データ行列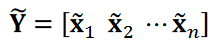 、または時系列データ
、または時系列データ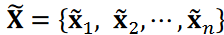 を得ます。ここでは、よく使われる切り捨て値である r = 5 とします。その後、余弦類似度cos 𝜃𝑖,𝑗を以下のように計算しました:
を得ます。ここでは、よく使われる切り捨て値である r = 5 とします。その後、余弦類似度cos 𝜃𝑖,𝑗を以下のように計算しました:

ここで、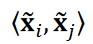 は
は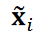 と
と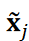 の内積、
の内積、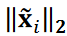 は
は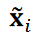 のℓ2ノルムです。本研究では、計算コスト削減のため、角柱背後の圧力分布のみを考慮しました。式4に
のℓ2ノルムです。本研究では、計算コスト削減のため、角柱背後の圧力分布のみを考慮しました。式4に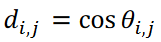 を代入し、DA3を用いてクラスタリングを計算しました。パラメータλ1はλ2の数10倍とし、式4の各項が同程度の大きさになるようにしました。この条件では、いくつかのデータが外れ値として分類されました。同じクラスター内の画像をアンサンブル平均し、有意なパターンを抽出しました。ここで、パターンを抽出するために元の画像データ Xは平均化され、
を代入し、DA3を用いてクラスタリングを計算しました。パラメータλ1はλ2の数10倍とし、式4の各項が同程度の大きさになるようにしました。この条件では、いくつかのデータが外れ値として分類されました。同じクラスター内の画像をアンサンブル平均し、有意なパターンを抽出しました。ここで、パターンを抽出するために元の画像データ Xは平均化され、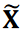 のデータセットは使用されなかったことに注意。
のデータセットは使用されなかったことに注意。
cos 𝜃𝑖,jが-1から1の範囲にあることを考慮し、0から1の範囲にある以下の関係式𝑟𝑖,𝑗を導入しました:

ここで、i = i(同じデータ)の時、1 - ri,j = 0となります。そして、データ間の距離メトリックを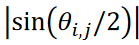 と定義し、|𝑗|は𝑗の絶対値を表し、θi,jはデータベクトル間の角度を表します。この距離メトリックでは距離の最大値はユニティです。この距離尺度はデータシートの計算に使用されました。
と定義し、|𝑗|は𝑗の絶対値を表し、θi,jはデータベクトル間の角度を表します。この距離メトリックでは距離の最大値はユニティです。この距離尺度はデータシートの計算に使用されました。
時系列データは、前述の "tslearn "の "TimeSeriesKMeans "関数によっても分類されました。さらに、PSP測定に特化したCIS法を用いました。CIS法では、PSPよりもサンプリングレートの高いポイントセンサーである圧力トランスデューサーセンサーによって測定された圧力データに基づいて、時系列データをいくつかのフェーズグループに分類しました。言い換えれば、CIS法はクラスタリングのために追加のセンサーを必要とします。この余分なセンサーへの依存は、CIS法の限界の1つと考えることができます。
結論
アニーリングマシンを用いた新しいクラスタリング手法を提案しました。各クラスタに分類されるデータ数を調整する新しい項をQUBOモデルに追加しました。一つはUEA & UCRの時系列分類リポジトリから入手可能な "crop "データセットであり、もう一つは我々の以前の研究で得られた流量測定画像データセットです。また、"crop "データセットのクラスタリングには、"tslearn "として配布されている既存の標準的な手法を採用しました。この手法では、各データ間の距離はユークリッド距離に基づいて計算され、クラスタリングはk-means++アルゴリズムによって計算されます。提案手法と既存手法の結果を比較すると、提案手法の方が既存手法よりもデータ点のばらつきが小さいことが確認されました。このデータセットでは、正しいクラスタリング結果が得られました。次に、アンサンブル平均されたデータを計算し、正しいデータとアンサンブル平均されたデータの間の平均二乗誤差(RMSE)を比較しました。その結果、両手法はこのデータセットに対して同様の結果を提供することがわかりました。
次に、提案のクラスタリング手法を、カルマン渦によって引き起こされる時系列の圧力分布からなる流れ計測画像データセットに適用しました。このデータセットには周期性が見られました。このデータのもう一つの特徴は、このデータセットには顕著なノイズが含まれており、そのS/N比はおよそ1です。比較のために、このデータセットを標準的な既存の手法と、流量計測データ用に特別に設計された条件付き画像サンプリング(CIS)手法でも分類しました。提案手法は、圧力変動が約2%と小さいにもかかわらず、クラスタ間の重複なくデータを分類することに成功しました。一方、既存の手法とCIS手法は、いずれもクラスタの重複が見られ、離散的なクラスタを形成することができませんでした。既存手法ではクラスター間の重なりが大きく、アンサンブル平均した圧力分布において、あるときは突然渦が消滅し、あるときは逆流を示しました。また、CIS 法で求めたアンサンブル平均圧力分布では、渦が弱まることがわかりました。これらの結果は、提案手法が周期現象のクラスタリングにおいて優れた性能を持つことを強調しています。






この記事に関するカテゴリー






