
ダイナミックな時系列データでの過学習を防ぎ予測精度を上げる正則化手法WaveBound
3つの要点
✔️ NeurIPS 2022採択論文です。時系列予測モデルにおける過学習の問題に取り組んでいます。正則化手法WaveBoundは、学習過程の各反復において、各時間ステップと特徴量に対する学習損失の適切な誤差境界を推定します。
✔️ WaveBoundは、モデルが予測不可能なデータにあまり集中しないようにすることで、学習プロセスを安定化させ、汎化を大幅に改善します。
✔️ 実世界のデータセット6組において、SOTAを凌ぐ性能を示しています。
WaveBound: Dynamic Error Bounds for Stable Time Series Forecasting
written by Youngin Cho, Daejin Kim, Dongmin Kim, Mohammad Azam Khan, Jaegul Choo
[Submitted on 25 Oct 2022 (v1), last revised 28 May 2023 (this version, v2)
Comments: Accepted by NeurIPS 2022
Subjects: Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
最近、深層学習は時系列予測においても顕著な成功を示しています。しかしながら、時系列データのダイナミクスのため、深層学習は依然として不安定な学習と過学習に悩まされています。実世界のデータに現れる一貫性のないパターンは、モデルを特定のパターンに偏らせるため、汎化が制限されるためです。本研究では、時系列予測における過学習問題に対処するため、学習損失に対する動的誤差境界を導入し、WaveBoundと呼ばれる正則化手法を提案します。この正則化手法は、各反復において、各時間ステップと特徴量に対する学習損失の適切な誤差境界を推定します。WaveBoundは、モデルが予測不可能なデータにあまり集中しないようにすることで、学習プロセスを安定化させ、汎化を大幅に改善します。広範な実験により、WaveBoundが、SOTAモデルを含む既存のモデルを、常に大差で改善することを示します。
はじめに
時系列予測は、最近深層学習ベースのアプローチ、特に変換器ベースの手法が増加しており、目覚ましい成功を示しています。とはいえ、実データには一貫性のないパターンや予測不可能な振る舞いが存在し、このような場合にモデルをパターンに適合させることを強制すると、不安定な学習を引き起こします。予測不可能なケースでは、モデルは学習においてそれらを無視するのではなく、むしろ大きなペナルティ(すなわち学習損失)を受けます。理想的には、予測不可能なパターンに対して小さな学習損失を与えるべきです。このことは、時系列予測における予測モデルの適切な正則化の必要性を示唆しているといえます。
最近、Ishidaらは、訓練損失ゼロは訓練に高いバイアスを導入し、それゆえ過信モデルと汎化の低下をもたらすと主張しました。この問題を改善するために、彼らはフラッディング(Flooding)と呼ばれる単純な正則化を提案し、学習損失がフラッディングレベルと呼ばれる小さな一定の閾値以下に減少することを明示的に防いでいます。本研究では、時系列予測における学習損失ゼロの欠点にも注目します。時系列予測では、モデルは必然的に現れる予測不可能なパターンに適合するように強制されるため、ほとんどの場合、とてつもない誤差が発生します。しかし、元のフラッディングは、主に以下の2つの主な理由により、時系列予測には適用できません。
(i)画像分類と異なり、時系列予測では予測長×特徴数のベクトル出力が必要である。この場合、オリジナルのフラッディングは、各時間ステップと特徴を個別に扱うことなく、平均学習損失を考慮する。
(ii)時系列データでは、誤差境界は異なるパターンに対して動的に変更されるべきである。直感的には、予測不可能なパターンに対しては、より高い誤差が許容されるべきである。
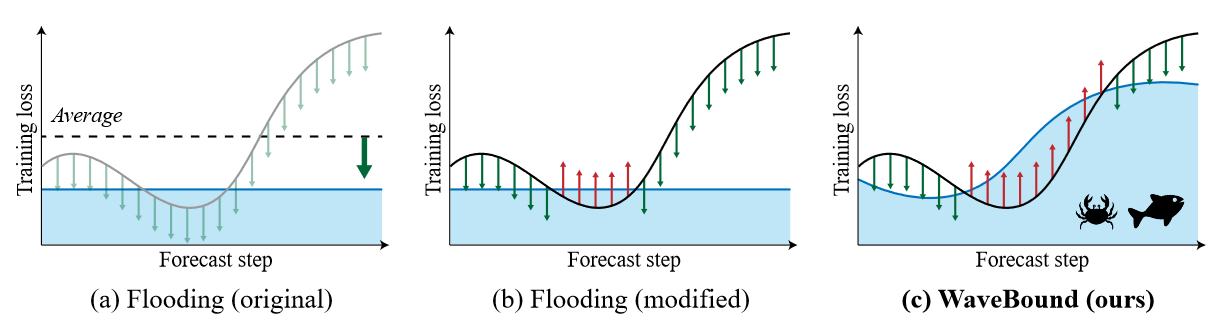
| 図1 異なる手法の概念的な例 (a) オリジナルのフラッディングは、各タイムステップと特徴を個別に考慮するのではなく、平均損失の下界を提供する。(b)各時間ステップ、各特徴に対して訓練損失の下界を提供しても、一定値の下界では時系列予測の本質を反映できない。(c)著者らの提案するWaveBound法は、各時間ステップと特徴量に対して学習損失の下界を提供する。この下限値は、学習プロセス中に、より厳しい誤差境界を与えるように動的に調整される。 |
時系列予測におけるオーバーフィッティング問題に適切に対処するためには、予測の難易度、すなわち、現在のラベルがどれだけ予測不可能であるかを学習手順において測定すべきです。この目的のために、元のネットワーク、すなわちソース・ネットワークの指数移動平均で更新されたターゲット・ネットワークを導入します。各反復において、ターゲット・ネットワークは、ソース・ネットワークに対して妥当なレベルの学習損失を導くことができる-ターゲット・ネットワークの誤差が大きいほど、予測不可能なパターンが増えます。現在の研究では、自己教師設定において安定したターゲットを生成するために、ゆっくりと動く平均ターゲットネットワークが一般的に使用されています。ターゲットネットワークの学習損失を下界に利用することで、著者らはWaveBoundと呼ばれる新しい正則化手法を導出し、各時間ステップと特徴量の誤差境界を忠実に推定します。誤差境界を動的に調整することで、提案する正則化はモデルが特定のパターンに過度にフィットするのを防ぎ、汎化をさらに改善します。図1は、オリジナルのフラッディングとWaveBound法の概念的な違いを示しています。元々提案されているフラッディングは、平均損失とそのフラッディングレベルを比較することにより、全ての点の更新ステップの方向を決定します。これに対し、WaveBoundは、学習損失の動的誤差境界を用いて、各ポイントの更新ステップの方向を個別に決定します。この研究の主な貢献は3つです:
- WaveBoundと呼ばれる、時系列予測における学習損失の誤差境界を動的に提供する、シンプルかつ効果的な正則化手法を提案する。
- 提案する正則化手法が、6つの実世界ベンチマークにおいて、既存の最新時系列予測モデルを一貫して改善することを示す。
- 広範な実験を行うことで、時系列予測におけるオーバーフィッティングの問題に対処するため、時間ステップ、特徴、パターンごとに誤差境界を調整することの意義を検証する。
前置き
時系列予測
固定ウィンドウ・サイズを持つローリング予測設定を考慮します。時系列予測の目的は、時刻tにおける過去の系列xt = {zt-L+1, zt-L+2, ..., zt : zi∈RK }が与えられたときに、将来の系列yt = {zt+1, zt+2, ..., zt : zi∈RK }を予測するフォーキャスターg: RL×K → RM×K を学習することです 。主に、入力系列xと出力系列yが基礎密度p(x, y)に由来する多変量回帰問題における誤差境界を扱います。与えられた損失関数ℓに対して、gのリスクはR(g) := E(x,y)∼p(x,y) [ℓ(g(x), y)]です。分布pに直接アクセスできないので、代わりに学習データ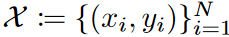 を用いてその経験版
を用いてその経験版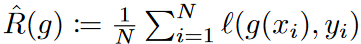 を最小化します。解析では、誤差は独立同次分布であると仮定します。目的関数として広く使用されている平均二乗誤差(MSE)損失を使用します。そして、リスクは各予測ステップと特徴量におけるリスクの和として書き換えることができます:
を最小化します。解析では、誤差は独立同次分布であると仮定します。目的関数として広く使用されている平均二乗誤差(MSE)損失を使用します。そして、リスクは各予測ステップと特徴量におけるリスクの和として書き換えることができます:
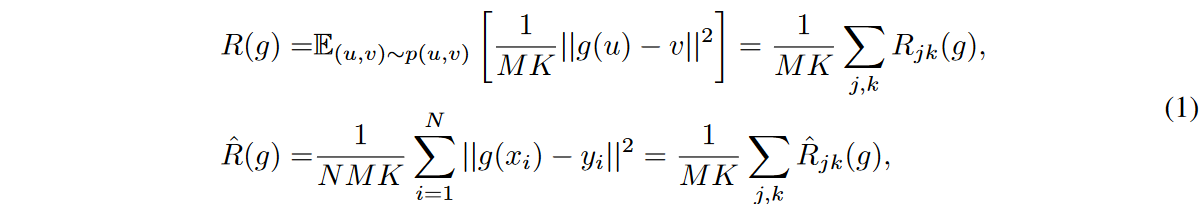
ここで、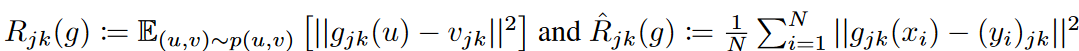
フラッディング
過学習の問題に対処するために、Ishidaらは、学習損失がある定数以上になるように制限するフラッディングを提案しました。経験的リスク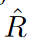 とフラッドレベルと呼ばれる手動で探索された下界bが与えられた場合、著者らは代わりに次のように定義されるフラッド経験的リスクを最小化します。
とフラッドレベルと呼ばれる手動で探索された下界bが与えられた場合、著者らは代わりに次のように定義されるフラッド経験的リスクを最小化します。
![]()
モデルパラメータに関するフラッデッド経験的リスクの勾配更新は、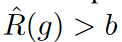 の場合は経験的リスクの勾配更新と同様に行われ、それ以外の場合は逆方向に行われます。t∈{1, 2, ..., T }のt番目のミニバッチに関する経験的リスクを
の場合は経験的リスクの勾配更新と同様に行われ、それ以外の場合は逆方向に行われます。t∈{1, 2, ..., T }のt番目のミニバッチに関する経験的リスクを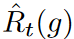 とすると、ジェンセンの不等式により
とすると、ジェンセンの不等式により
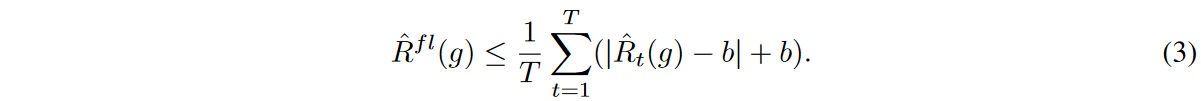
したがって、ミニバッチ最適化は、フラッディング経験的リスクの上限を最小化します。
手法
時系列予測でのフラッディング
まず、時系列予測問題に対して、オリジナルのフラッディングがどのように効果的に機能しないかを説明します。各予測ステップと特徴量におけるリスクを用いて式(2)を書き直すことから始めます:
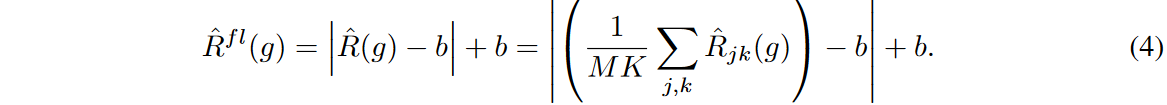
フラッディング経験的リスクは、すべての予測ステップと特徴の経験的リスクの平均の下限をbの一定値で制約します。 しかし、多変量回帰モデルの場合、この正則化は各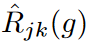 を独立に拘束しません。その結果、正則化の効果は、が学習で大きく変化する出力変数に集中します。
を独立に拘束しません。その結果、正則化の効果は、が学習で大きく変化する出力変数に集中します。
このような状況に対して、各時間ステップと特徴量に対する個別の学習損失を考慮することで、フラッディングの修正版を探索することができます。これは、以下のように、各タイムステップおよび各特徴のフラッドレベルbを減算することによって行うことができます:
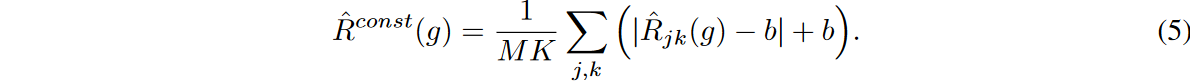
本研究では、このフラッディングを定数フラッディングと呼びます。訓練損失全体の平均を考慮するオリジナルのフラッディングと比較して、定数フラッディングは、各時間ステップと特徴量における訓練損失の下限をbの値で個別に制約します。
それにもかかわらず、ミニバッチごとに異なる予測の難しさを考慮することができません。一定のフラッディングの場合、バッチごとの訓練プロセスにおいて経験的リスクの変種を適切に最小化することは困難です。式3のように、ミニバッチ最適化は、フラッディングされた経験的リスクの上限を最小化する。問題は、t∈{1, 2, ..., T }の各フラッデッドリスク項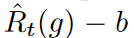 が大きく異なると、不等式の締まりが悪くなることです。時系列データには通常予測不可能なノイズが多く含まれるため、各バッチの損失が大きく変動すると、このような現象が頻繁に発生します。不等式の厳密性を保証するために、
が大きく異なると、不等式の締まりが悪くなることです。時系列データには通常予測不可能なノイズが多く含まれるため、各バッチの損失が大きく変動すると、このような現象が頻繁に発生します。不等式の厳密性を保証するために、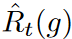 の境界はバッチ毎に適応的に選択されるべきです。
の境界はバッチ毎に適応的に選択されるべきです。
WaveBound
前述したように、時系列予測における経験的リスクを適切に抑制するためには、正則化の方法を以下の条件で検討する必要があります。
(i)正則化は、各時間ステップと各特徴の経験的リスクを個別に考慮すべきである。
(ii)異なるパターン、すなわちミニバッチに対しては、バッチごとの学習過程で異なる誤差境界を探索すべきである。
これを処理するために、各タイムステップと各特徴について誤差境界を求め、各反復で動的に調整します。反復毎に各タイムステップと特徴量について異なる境界を手作業で探索することは非現実的であるため、指数移動平均(EMA)モデルを用いて異なる予測値について誤差境界を推定します。
具体的には、学習段階を通じて2つのネットワークを採用します:ソース・ネットワークgθとターゲット・ネットワークgτで、それぞれ同じアーキテクチャを持つが、重みθとτが異なります。ターゲット・ネットワークは、ソース・ネットワークの予測に対する誤差の適切な下界を推定し、その重みはソース・ネットワークの重みの指数移動平均で更新されます:
![]()
ここで、α∈[0, 1]は目標減衰率です。一方、ソース・ネットワークは、波の経験的リスク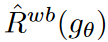 の勾配の方向に勾配降下更新を使用して重みθを更新します。
の勾配の方向に勾配降下更新を使用して重みθを更新します。
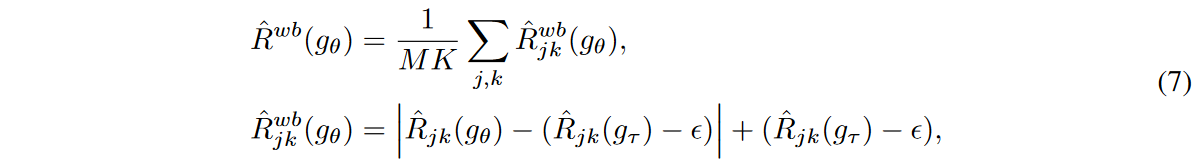
ここでεは、ソースネットワークの誤差境界がターゲットネットワークの誤差からどの程度離れていてもよいかを示すハイパーパラメータです。直感的には、ターゲット・ネットワークは、各時間ステップと特徴量に対する学習損失の下限をガイドし、ソース・ネットワークがその下限よりも低い損失に向かって学習するのを防ぎます。つまり、あるパターンにオーバーフィットします。指数移動平均モデルは、ソースネットワークをアンサンブルし、以前の反復で可視化された学習データを記憶する効果があることが知られているため、ターゲットネットワークは、主にノイズの多い入力データによって引き起こされる不安定性に対して、ソースネットワークのエラー境界をロバストに推定することができます。図2は、WaveBound法におけるソースネットワークとターゲットネットワークのパフォーマンスを示しています。
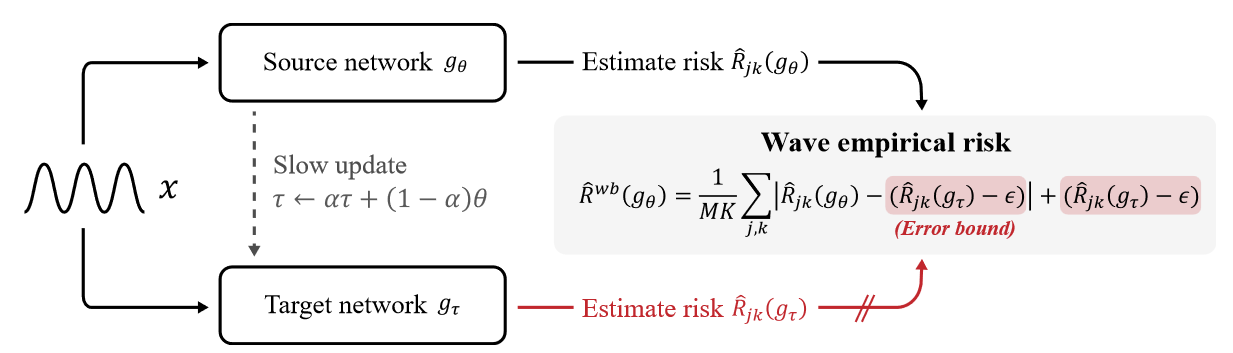
図2 WaveBound法は、ターゲットネットワークを用いて、各時間ステップと特徴量に対する学習損失の動的誤差境界を提供する。ターゲットネットワークgτはソースネットワークgθのEMAで更新される。j番目の時間ステップとk番目の特徴量において、学習損失は我々の推定した誤差境界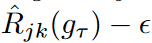 で境界される。つまり、学習損失が誤差境界を下回る場合、勾配降下の代わりに勾配上昇が実行される。 で境界される。つまり、学習損失が誤差境界を下回る場合、勾配降下の代わりに勾配上昇が実行される。 |
ミニバッチ最適化
t∈{1,2,...,T}に対して,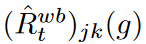 と
と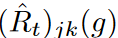 は,それぞれt番目のミニバッチに対するj番目のステップとk番目の特徴における波の経験的リスクと経験的リスクを表すとします。ターゲット・ネットワークg*が与えられると、Jensenの不等式により
は,それぞれt番目のミニバッチに対するj番目のステップとk番目の特徴における波の経験的リスクと経験的リスクを表すとします。ターゲット・ネットワークg*が与えられると、Jensenの不等式により
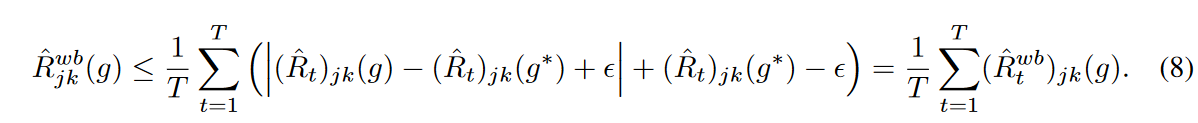
したがって、ミニバッチ最適化は波の経験的リスクの上限を最小化します。
gがg*に近い場合、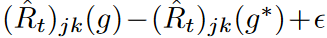 の値はミニバッチ間で類似しており、Jensenの不等式に厳しい境界が与えられることに注意してください。この条件が満たされるようにEMA更新が機能し、ミニバッチ最適化における波の経験的リスクに厳しい上限が与えられることを期待します。
の値はミニバッチ間で類似しており、Jensenの不等式に厳しい境界が与えられることに注意してください。この条件が満たされるようにEMA更新が機能し、ミニバッチ最適化における波の経験的リスクに厳しい上限が与えられることを期待します。
MSE縮小
適切なεが与えられた場合、著者らの提案する波の経験的リスク推定量のMSEが経験的リスク推定量よりも小さくなることを示します。
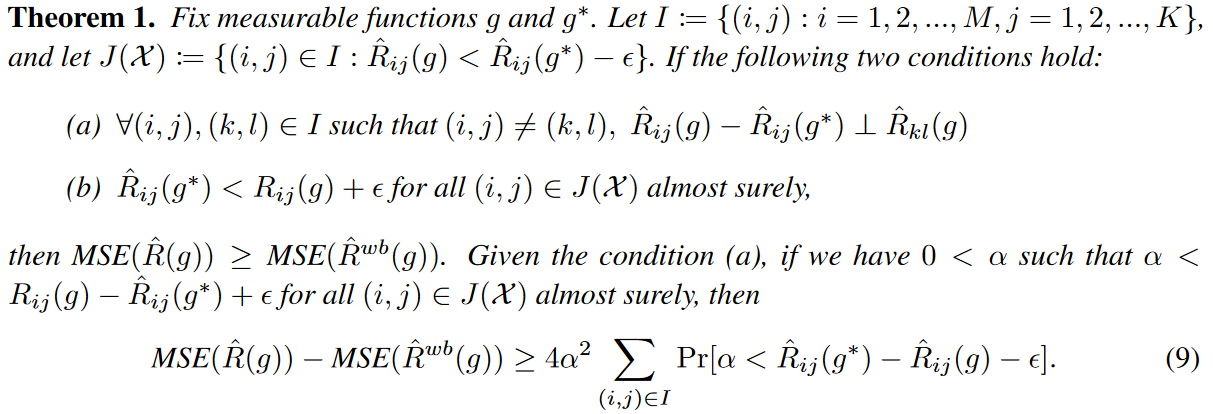
直観的には、定理1は以下の条件が成立するとき、経験的リスク推定量のMSEを小さくできることを述べています:
(i) ネットワークg*は十分な表現力を持ち、各出力変数におけるgとg*の損失差はgの他の出力変数における損失と無関係である。
(ii) ˆ Rij(g∗) - εはˆ Rij(g)とRij(g)の間にある可能性が高い。
EMAモデルの学習損失がモデルのテスト損失を容易に下回らないので、g*をgのEMAモデルとすることが望ましいです。そして、εは、各出力変数におけるソースモデルの学習損失が、その変数におけるテスト損失以下に密接に束縛されるように、固定された小さな値として選択することができます。
実験
予測モデルによるWaveBound
ベースラインとして、多変量設定では、Autoformer、Pyraformer、Informer、LSTNet、TCNを選択しました。単変量設定では、ベースラインとしてN-BEATS [15]を追加します。
データセット は6つの実世界ベンチマークをもちいます。
(1) 電力変圧器温度(ETT)データセットには、中国の2つの別々の郡から、電力変圧器から収集された1時間レベル(ETTh1、ETTh2)と15分レベル(ETTm1、ETTm2)の間隔の2年間のデータが含まれています。
(2) Electricity (ECL) データセットは、321クライアントの2年間の1時間ごとの電力消費量からなります。
(3) Exchange データセットは、1日単位で8カ国の特徴を収集したものです。
(4) Trafficデータセットは、California Department of Transportation が提供するサンフランシスコ湾の様々なセンサーの1時間毎の統計データです。
(5) Weatherデータセットには、米国の約1,600のランドマークで収集された21の気象指標の4年間(2010-2013)のデータが記録されています。
(6) ILI データセットには、2002年から2021年までの、疾病管理予防センターが毎週報告しているインフルエンザ様疾患患者のデータが含まれており、全体の患者数に対するILIで受診した患者の比率が記述されています。
・多変量結果
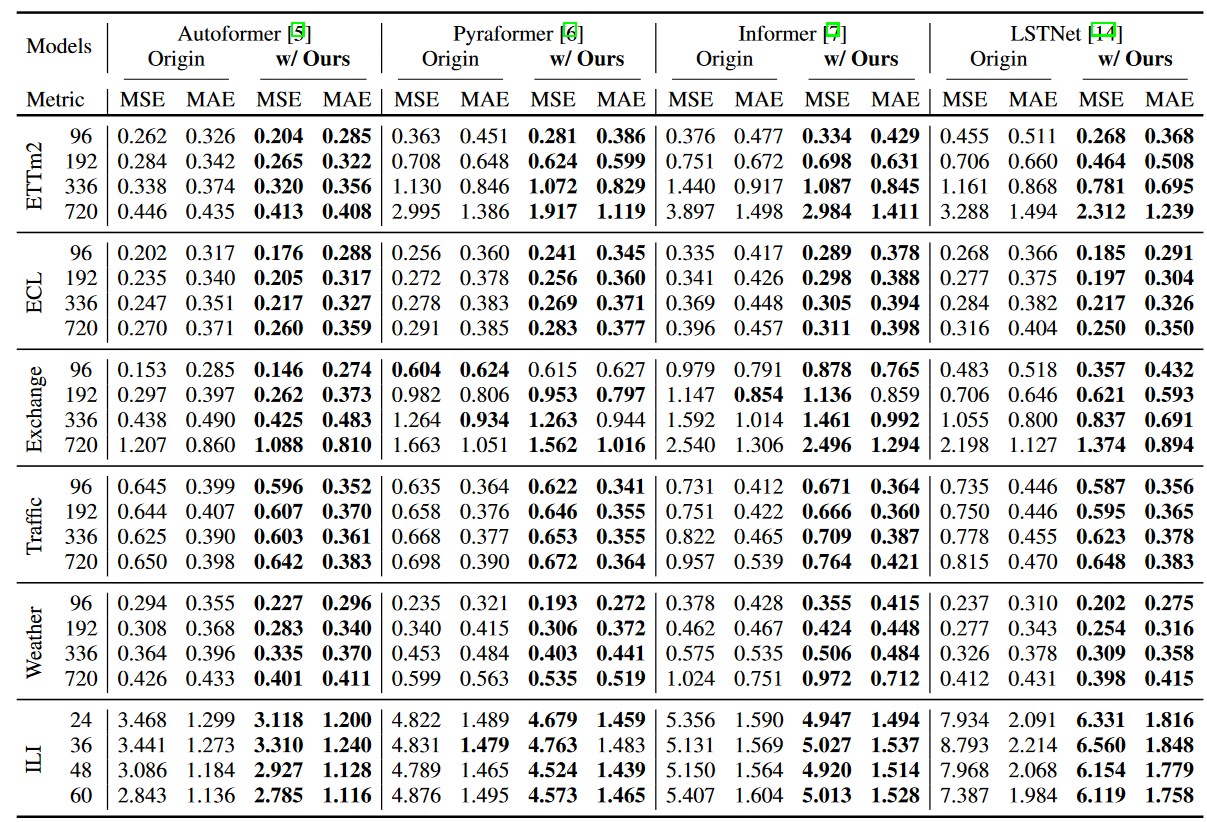
表1は、多変量設定における平均二乗誤差(MSE)と平均絶対誤差(MAE)の観点から手法の性能を示しています。著者らの手法は、最新の手法を含む様々な予測モデルに対して一貫して改善を示していることがわかります。特に、WaveBoundは、ETTm2データセットのMAEとMSEの両方を、M = 96の場合、MSEで22.13% (0.262 → 0.204)、MAEで12.57% (0.326 → 0.285)改善する。特にLSTNetの場合、MSEで41.10% (0.455 → 0.268)、MAEで27.98% (0.511 → 0.368)性能が向上しています。長期ETTm2予測設定(M = 720)では、WaveBoundはAutoformerの性能をMSEで7.39% (0.446 → 0.413)、MAEで6.20% (0.435 → 0.408)向上させます。全ての実験において、著者らの手法は様々な予測モデルで一貫して性能向上を示しています。
| 表1 多変量設定におけるWaveBoundの結果。結果はすべて3回の試行の平均値。 |
・単変数結果
表2に報告されているように、WaveBoundは一変量設定においても優れた結果を示しています。特に、一変量時系列予測用に特別に設計されたN-BEATSにおいて、著者らの手法は、M = 96のとき、ETTm2データセットの性能をMSEで8.22% (0.073 → 0.067)、MAEで5.05% (0.198 → 0.188)向上させました。ECLデータセットの場合,WaveBoundを用いたInformerは,M = 720のときに,MSEで40.10%(0.631 → 0.378),MAEで24.35%(0.612 → 0.463)の改善を示します。
| 表2 単変量設定でのWaveBoundの結果。すべての結果は3回の試行の平均。 |
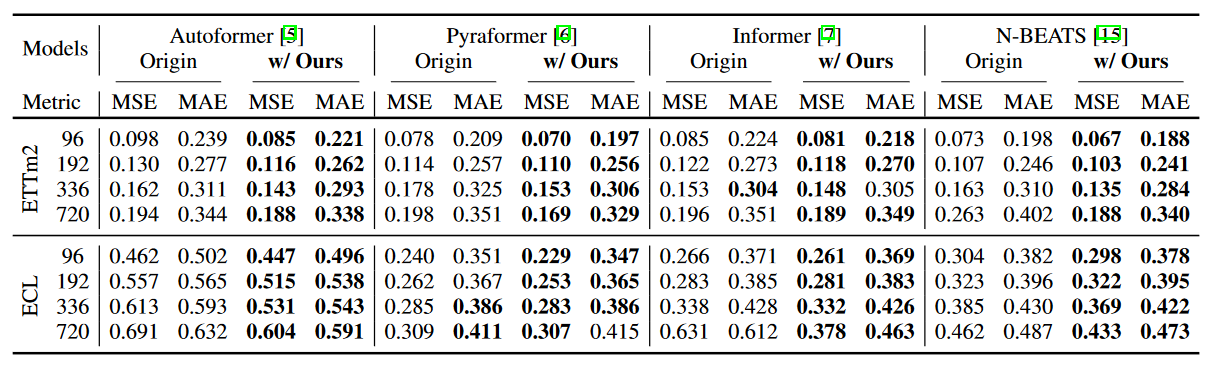
・汎化ギャップ
オーバーフィッティングを識別するために、訓練損失とテスト損失の差である汎化ギャップを調べることができます。著者らの正則化が本当にオーバーフィッティングを防いでいることを検証するために、図3にWaveBoundを使用したモデルと使用しなかったモデルのトレーニング損失とテスト損失の両方を示します。WaveBoundを使用しない場合、テスト損失は急激に増加し始め、高い汎化ギャップを示しています。対照的に、WaveBoundを使用すると、テスト損失が減少し続けていることが観察され、これはWaveBoundが時系列予測におけるオーバーフィッティングにうまく対処していることを示しています。
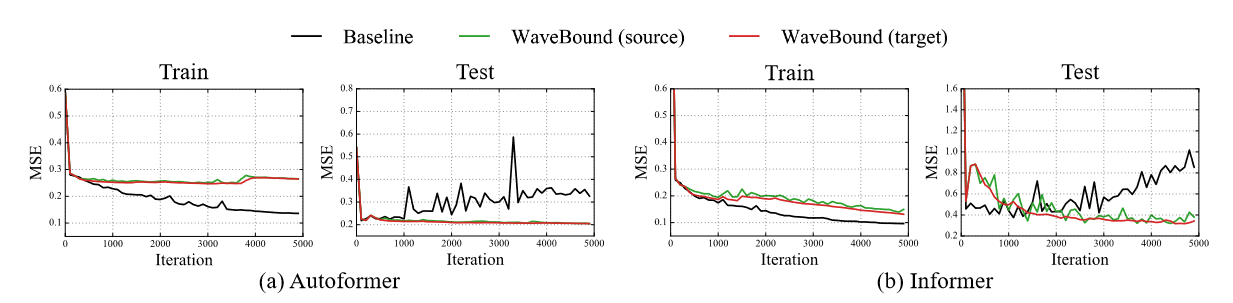
| 図3 ETTm2データセットにおけるWaveBoundの有無によるモデルの学習曲線。WaveBoundを使用しない場合、両モデルの学習損失は減少するが、テスト損失は増加する(黒線参照)。対照的に、WaveBoundを使用したモデルのテスト損失は、さらに多くのエポックを学習した後も減少し続けています。 |
エラー境界を動的に調整する意義
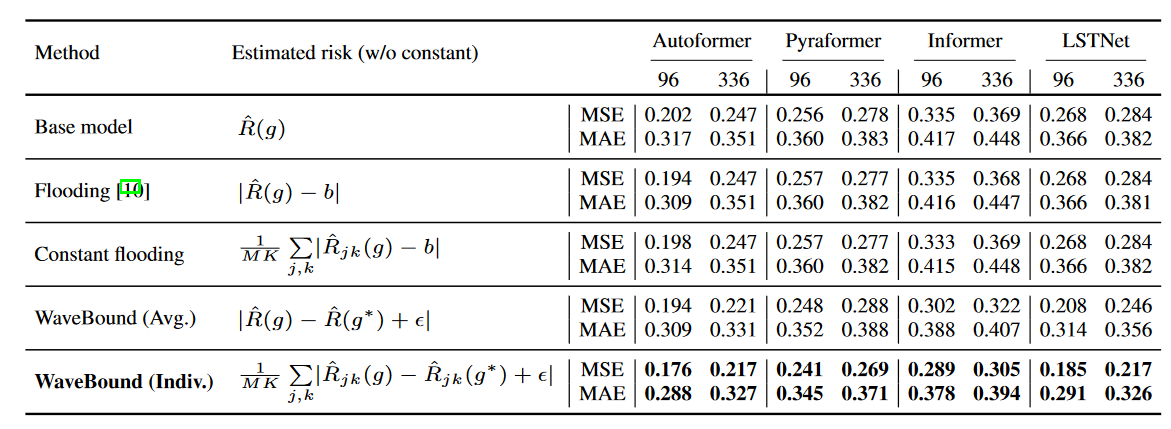
WaveBoundでは、誤差境界は各反復において、各時間ステップと各特徴に対して動的に調整されます。このようなダイナミクスの重要性を検証するために、WaveBoundをオリジナルのフラッディング、およびフラッディングレベルに一定値を使用するコンスタントフラッディングと比較します。
表3は、経験的リスクに対する様々な代用値を用いたフラッディング正則化の性能を比較したものです。オリジナルのフラッディングは、経験的リスクを定数でバウンディングし、定数フラッディングは、各特徴と時間ステップのリスクを独立にバウンディングします。正則化手法のフラッディングレベルbを{0.00, 0.02, 0.04, ...0.40}の空間で一定値bで探索しました。予想通り、固定された定数値を用いた場合、改善を達成することはできませんでした。各出力変数の誤差を個別に束縛して学習させたモデルは、他のベースラインを大きく上回り、著者らの提案するWaveBound法の有効性を具体的に示しています。各時間ステップにおける異なる手法のテスト誤差を図4に示します。すべての時間ステップにおいて、WaveBoundは、オリジナルのフラッディングやコンスタントフラッディングと比較して、改善された汎化を示しており、これは時系列予測における誤差境界を調整することの重要性を強調しています。
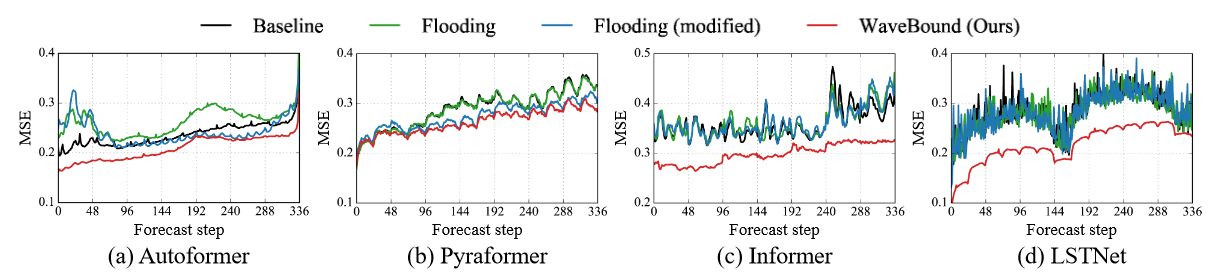
| 図4 ECLデータセットにおける異なる正則化手法で学習したモデルのテスト誤差。オリジナルのフラッディングやコンスタントフラッディングと比較すると、WaveBoundのテスト誤差は全ての時間ステップで一貫して低く、これは著者らの手法が予測の範囲に関係なく汎化を改善することに成功していることを示している。 |
| 表3 ECLデータセットにおけるフラッディング正則化のバリエーションの結果。異なるサロゲートを用いてソースネットワークを訓練した場合の予測精度を経験的リスクと比較する。全ての結果は3回の試行の平均であり、定数値bは{0.00, 0.02, 0.04, ...0.40}の中で忠実に探索されている。 |
損失ランドスケープの平坦性
損失ランドスケープの視覚化は、モデルがどの程度適切に汎化されているかを評価するために導入されます。モデルの損失ランドスケープが平坦であるほど、ロバスト性と汎化性が高いことが知られています。WaveBoundを使用した場合と使用しない場合のモデルの損失ランドスケープを示します。図5はAutoformerとInformerの損失ランドスケープの図です。フィルタ正規化を用いて損失ランドスケープの可視化を行い、公正な比較のために各モデルのMSEを評価します。WaveBoundを使用したモデルは、オリジナルモデルと比較して、より滑らかな損失風景を示すことが観察できます。言い換えれば、WaveBoundは時系列予測モデルの損失ランドスケープを平坦化し、学習を安定化させます。
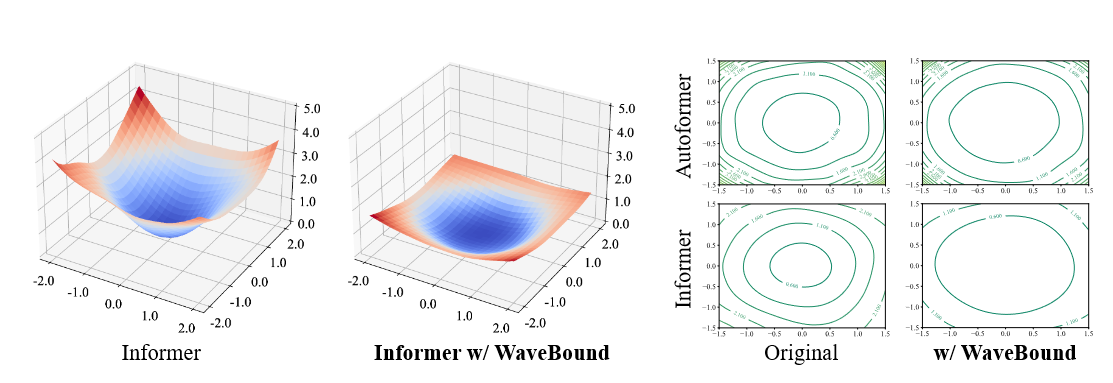
| 図5 ETTh1データセットにWaveBoundを適用した場合と適用しない場合のAutoformerとInformerの損失ランドスケープ。WaveBoundは両モデルの損失風景を平坦化し、モデルの汎化性を向上させる。 |
関連研究
時系列予測
時系列予測タスクのために、様々な原理に基づいて様々なアプローチが提案されてきました。統計的アプローチは、理論的な保証だけでなく、解釈可能性を提供することができます。自己回帰積分移動平均やプロフェットは、統計的アプローチの最も代表的な手法です。時系列予測のもう一つの重要なクラスは、状態空間モデル (SSMs)です。SSMは構造的仮定をモデルに組み入れ をモデルに組み込み、時系列データの潜在的なダイナミクスを学習します。しかし、長距離予測におけるその優れた結果から、深層学習に基づくアプローチが主に時系列予測の有力なソリューションとして考えられています。時系列データの時間依存性をモデル化するために、リカレントニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)が時系列予測に導入されています。時間的因果関係をモデル化するために、時間畳み込みネット ワーク(TCN)も検討されています。SSMとニューラルネットワークを組み合わせたアプローチも提案されています。DeepSSMはRNNを用いて状態空間パラメータを推定します。線形潜在ダイナミクスはカルマンフィルターを用いて効率的にモデル化されており、非線形状態変数をモデル化する方法論も提案されています。その他の最近のアプローチとしては、ラオ・ブラックウェル化粒子フィルターを用いたSSMや、継続時間スイッチングメカニズムを用いたSSMがあります。
最近、長距離依存性を捉えることができるため、時系列予測にトランスフォーマーベースのモデルが導入されています。しかし、セルフアテンションメカニズムを適用すると、シーケンス長Lの複雑さがO(L)からO(L2)に増加します。この計算負荷を軽減するために、LogTrans、Reformer、Informerなどのいくつかの試みがあり、セルフアテンションメカニズムをスパースバージョンに再設計し、トランスフォーマーの複雑さを軽減しました。Haixuらは、Autoformerと呼ばれる自己相関機構を備えた分解アーキテクチャを提案し、直列的な接続を提供しています。異なる範囲の時間依存性をモデル化するために、Pyraformerではピラミッド型アテンションモジュールが提案されています。しかし、これらのモデルは、実データに現れるすべての矛盾したパターンに適合するようにモデルを強制する学習戦略のため、依然として汎化に失敗しています。本研究では、学習過程においてモデルが特定のパターンに過剰適合するのを防ぐために、適切な誤差境界を与えることに主眼を置きました。
正則化手法
過学習は、オーバーパラメータ化された深層学習ネットワークの重大な懸念事項の1つです。これは汎化ギャップ(学習損失とテスト損失の間のギャップ)によって特定することができます。過学習を防ぎ、汎化を改善するために、いくつかの正則化手法が提案されています。重みパラメータの減衰、早期停止、ドロップアウトは、深層学習ネットワークの高いバイアスを回避するために一般的に適用されています。これらの手法に加えて、時系列予測用に特別に設計された正則化手法も提案されています。最近では、学習損失ゼロを明示的に防ぐFloodingが導入されています。Floodingは、Flooding levelと呼ばれる学習損失の下限を提供することで、モデルが学習データに完全に適合しないことを可能にし、モデルの汎化能力を向上させます。本研究では、時系列予測における学習損失ゼロへの取り組みも試みます。しかし、時系列予測における平均損失は、期待されたほどうまくいかないことがわかりました。時系列予測では、各特徴と時間ステップに対して適切な誤差境界を注意深く選択する必要があります。また、一定のFloodingレベルは、ミニバッチ学習プロセスの反復ごとに予測の難易度が変化する時系列予測には適さないかもしれません。このような問題に対処するために、著者らは時系列予測の性質を十分に考慮した新しい正則化を提案したのです。
まとめ
本研究では、時系列予測のためのWaveBoundと呼ばれるシンプルかつ効果的な正則化手法を提案ました。WaveBoundは、緩やかな移動平均モデルを用いて、各時間ステップと特徴量に対して動的な誤差境界を提供します。実際のベンチマークを用いた広範な実験により、著者らの正則化スキームが、最新モデルを含む既存モデルを一貫して改善し、時系列予測における過学習に対処することを示しました。また、過パラメータ化したネットワークの学習におけるWaveBoundの効果について議論するために、汎化ギャップと損失ランドスケープの検証を行いました。著者らの手法の大幅な性能向上は、正則化を時系列予測に特化して設計すべきことを示していると考えています。






この記事に関するカテゴリー






