最適な学習済みモデルが高精度かつ高速にわかる!?モデルの転移性を予測する指標LEEPの登場!
3つの要点
✔️ どの学習済みモデルを使用して転移学習を行えば、精度の良いモデルができるか高精度に予測する指標LEEPを提案
✔️ 学習済みモデルを用いてターゲットドメインのデータに対して、一度予測を行うだけで良いため、高速に計算が可能
✔️ 近年提案されたMeta-Transfer Learningの精度に高い相関を示した初めての指標
LEEP: A New Measure to Evaluate Transferability of Learned Representations
written by Cuong V. Nguyen, Tal Hassner, Matthias Seeger, Cedric Archambeau
(Submitted on 27 Feb 2020 (v1), last revised 14 Aug 2020 (this version, v2))
Comments: Accepted to the International Conference on Machine Learning (ICML) 2020.
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
code:
はじめに
皆様ご存じのように、深層学習モデルは従来手法に比べて非常に良い予測精度であることから、日常生活の様々な場面で使用されるようになってきています。特に画像認識・自然言語処理・音声認識の分野では従来手法を圧倒する精度を叩きだしています。深層学習モデルがこれほどまでに良い精度である理由の1つとして、予測を行うために非常に重要な特徴量を抽出する機構をモデルが獲得していることにあります。
一方で、この特徴量を抽出する機構は大量のデータで学習させることによって、獲得されるということが分かっています。つまり深層学習モデルで精度を出すためには、大量のデータが必要になるということです。この問題を解決する手法として”転移学習”が非常に有効です。転移学習は大量のデータで学習させたモデルの特徴量抽出部分を再利用することで、限られたデータ数でも精度を出すことを可能にします。一般的にはImageNetと呼ばれる1000クラスの1000万枚の画像で学習させたモデル(以後、学習済みモデル)のパラメータを再利用し、実際に予測を行う部分だけを取り換えて再学習するということが度々行われています。
さて、ここで1つの疑問が出てきます。自分が持っているデータセットに適した学習済みモデルは何であるのか、ということです。ここでは元となる学習済みモデルを学習させるデータは固定とします(上記のImageNetなどです)世の中では多くの研究者達がGithub上で、様々な学習済みモデルを公開しています。例えば、深層学習モデルの勾配消失問題を解決したResNetであったり、CPUでも動作するMobileNetなどが挙げられるでしょう。
もちろん、計算リソースに余裕があれば、ありとあらゆるモデルを用いて再学習を行い、その中で最も精度の良いものを選べばよいでしょう。しかし、一般企業はそのような潤沢な計算リソースは持っておらず、限られた計算リソースの中で良いと思われるモデルを選択し、再学習を行うしかありません。仮に少ない計算量で準最適なモデルを見つけることが出来れば、企業にとっては非常に有益です。まさに今回紹介する研究は、学習済みモデルとターゲットとなるデータセット(再学習を行うデータセット)が与えられれば、少ない計算量でターゲットデータセットで良い精度を出す、準最適な学習済みモデルを選ぶことを目標としています。その指標としてLEEPを提案し、従来手法に比べて、高い精度で最適なモデルを選択することに成功しています。それでは、LEEPとはどのような手法なのか順を追ってみていきましょう。
関連研究
メタ転移学習
メタ転移学習とは、2018年に提案された非常に新しい研究分野です。メタ転移学習の目標は、ソースとなるタスクからターゲットとなるタスクへの転移方法を学習するというものです。文字で表されても、いまいちピンとこないかと思いますが、これは人間が日常的に行っていることが教育心理学の研究で明らかになっています。例えば、チェスが上手な子供を考えてみましょう。その子供はチェスで得た経験は、実は数学やパズルなどにも活かすことが出来ると学びます。成長するにつれ、その子供はいろんな経験をするでしょう(工具を使って机を作る、友達と仲良く遊ぶ、などです)そして新しい未知のタスクAに直面したときに、これまで学んできたことを活かして、どのようなタスクBをどのように活用すれば、タスクAを解決するのに役立つのか判断できるようになります。つまり、タスク間の転移方法を学習しているのです。下記の図は、転移学習・マルチタスク学習・継続学習とメタ転移学習の違いを表したものです。LEEPはこのメタ転移学習の精度を測る良い指標であることが実験で明らかになりました。
![]()
Task space representation
Task space representationとはタスクという非常に曖昧なものをベクトルで表現しようという試みです。例えば、TASK2VECと呼ばれる手法が有名でAI-SCHOLARでも記事となっています。これはタスクをベクトルで表現し、そのベクトル間の距離を計測することによって、どのデータセットで学習されたモデルを使って転移学習すれば良いか判断することができます。しかし、TASK2VECはprobe networkと呼ばれる大規模なモデルを学習し、それをターゲットとなるデータに適用することで、タスクの表現を得ていました。つまり、潤沢な計算リソースが必要という欠点があるということです。 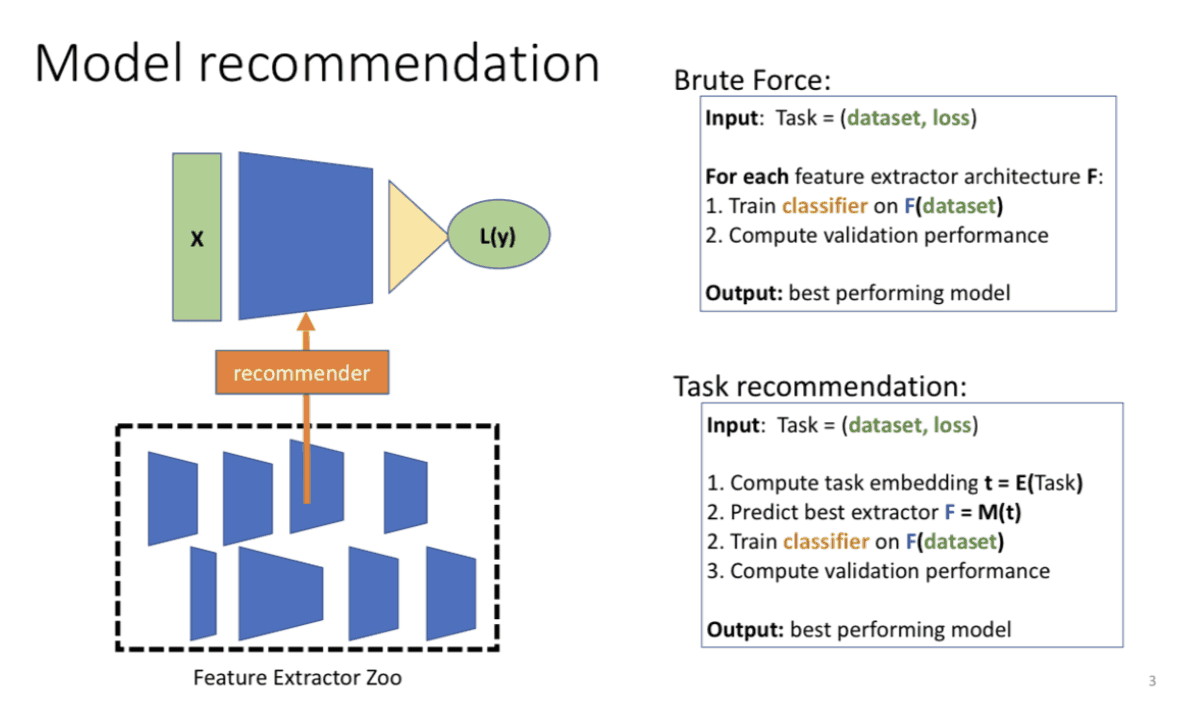
提案手法
では、ここから提案手法を見ていきます。提案手法は3つのステップで構成されています。
① ターゲットデータセットのダミーラベル分布を学習済みモデルで計算する
② ダミーラベルzに対する条件付き確率$P(y|z)$を計算する
③ ダミーラベル分布と$P(y|z)$からLEEPを計算する
それぞれのステップについて詳細に見ていきます。
① ターゲットデータセットのダミーラベル分布を学習済みモデルで計算する
学習済みモデルを$θ$とします。例えば、$θ$はImagenetで学習されたモデルです。このモデルの出力はzを表します。また、ターゲットデータセットをD={(x1,y1),(x2,y2)・・・(xn,yn)}と表します。ここで、$θ$を用いて、ターゲットデータセットのダミーラベル分布$θ(xi)$を計算します。もちろん、学習済みモデルには何の変更も加えてないため、$θ(xi)$はターゲットデータセットのラベルとは意味的に関係がありません。
② ダミーラベルzに対する条件付き確率$P(y|z)$を計算する
ダミーラベルzに対する条件付き確率$P(y|z)$を計算するために、まずyとzの同時確率分布を計算します。計算式は以下の通りです。
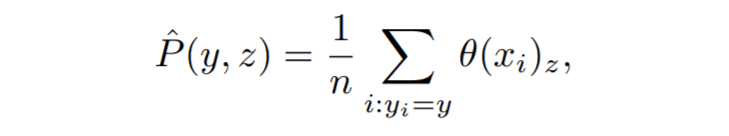
yとzの同時確率分布を計算するために、yi=yを満たすすべてのダミーラベル分布の和を取っています。つまり、yというラベルが付与されているデータの分布を計算していることになります。
同時確率分布が計算できれば、あとはベイズの定理に従って条件付き確率$P(y|z)$を計算していきます。ベイズの定理から、条件付き確率$P(y|z)$は以下の通りに計算できます。
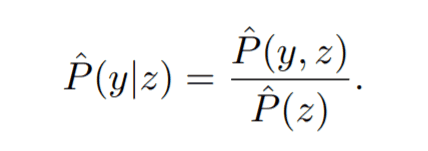 ここで、分母は以下のように同時確率分布から計算できます。
ここで、分母は以下のように同時確率分布から計算できます。
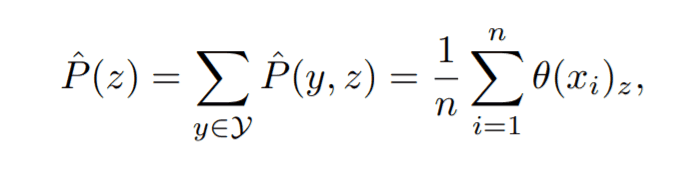 ③ ダミーラベル分布と$P(y|z)$からLEEPを計算する
③ ダミーラベル分布と$P(y|z)$からLEEPを計算する
ここまで計算してきた$θ(x)$と$P(y|z)$を使って、xのラベルを予測する分類器を考えてみましょう。まず、ダミーラベル分布からラベルzを計算します。そして、そのラベルzを用いて$P(y|z)$からyを計算します。これは、$P(y|x,θ,D)$ = $ΣP(y|z)θ(x)$という確率分布からyを計算していることと等価です。(Σはすべてのzについて計算しています。そうすることで、関係のないzの影響を消すことができます)これをExpected Empirical Predictor(EEP)と呼びます。LEEPはこのEEPのlogをとり、ターゲットデータセットで平均したもので定義されます。
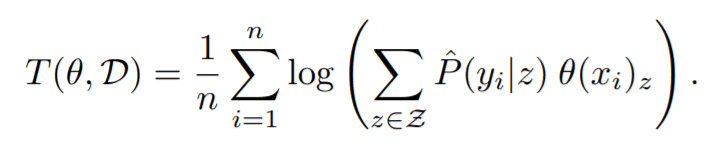
直感的には、LEEPは学習済みモデル$θ$とターゲットデータセットDで計算されており、どれだけ$θ$とDが近いか測る指標となっています。LEEPの理論的な性質を見ることで、この部分がどれだけ正しいか見てみましょう。
理論的考察
まず、$θ$を特徴量抽出機構$ω$と分類器$h$に分解します。つまり、$θ$=($ω$,$h$)です。次に分類器部分のみを取り換えて、Dで再学習することを考えます。この中で、最適な分類器を選ぶ問題を考えます。これは、下記の数式で表すことが出来ます。
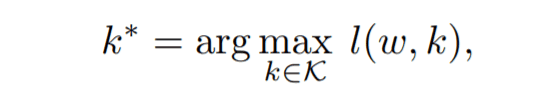
ここで、$l$はDにおける平均log尤度、$K$は分類器kの集合を表します。$K$がEEPを含んでいることを仮定すると、T($θ$,D)≦$l($ω$,k*)$ー特性(1)が導かれます。これは$l($ω$,k*)$が平均log尤度の最大値であり、かつT($θ$,D)は$K$に含まれるので、特性(1)が成立します。つまり、LEEPは平均log尤度の最大値の下限であるということです。
次の特性は、近年発表された転移性を測る指標negative conditional entropy (NCE)とLEEPを関係を示すものです。NCEは転移性を測る良い指標ということが分かっています。NCEの計算はターゲットデータセットDのすべての入力xiに対して、ダミーラベルzi=argmax$θ(xi)$を計算します。Y=(y1,y2・・・yn)、Z=(z1,z2・・・zn)としたときに、下記のように計算されます。
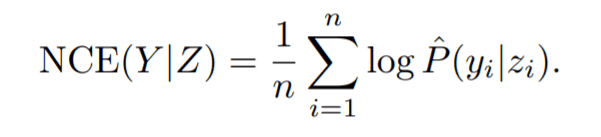
このNCE(Y|Z)とLEEPの間には、T($θ$,D)≧NCE(Y|Z)+$Σlogθ(xi)$/nー特性(2)が成立します。(照明は元論文のAppendixをご覧ください)特性(1)(2)から、LEEPはDにおける最適なモデル($ω$,k*)における平均log尤度とNCE(Y|Z)+$Σlogθ(xi)$/nの間の値となります。平均log尤度はモデルの精度と相関があることがわかっており、さらにNCEよりも平均log尤度に近いことが証明されているため(NCEの研究で証明されています)、LEEPはモデルの精度とある一定の相関があることが証明できます。
実験
LEEP vs. Transfer Accuracy
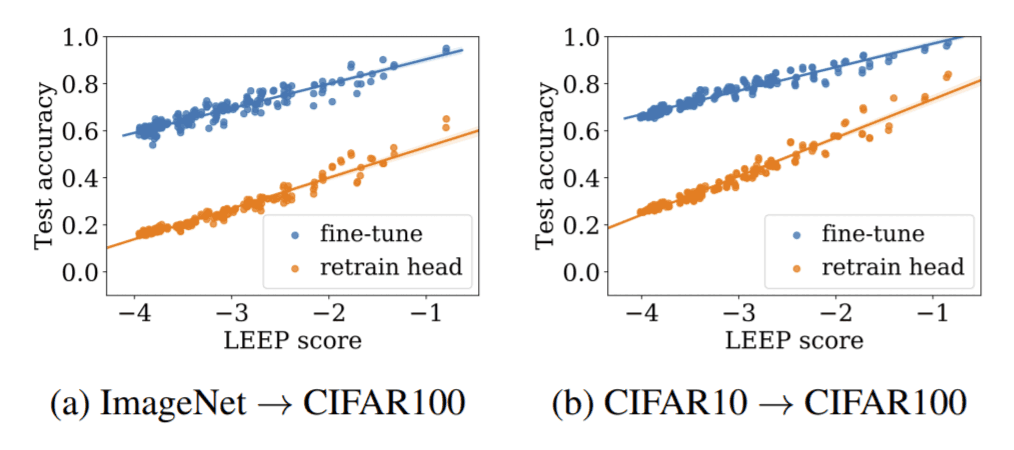
この実験では、学習済みモデルとしてImageNetで学習されたResNet18とCIFAR10で学習されたResNet20を用います。この2つのモデルをCIFAR100に転移学習します。この実験では、200の異なるタスク(CIFAR100からランダムに2~100のクラスを選択し、それを繰り返して200の異なるデータセットを構築しています)で転移学習されたモデルの精度とLEEPを比較しています。ここでは、Re-train head(分類器のみを取り換えて分類器部分のみを再学習)とFine-tune(分類器を取り換えて、モデル全体を再学習)の2種類で実験を行っています。下記の図をご覧ください。どちらの学習済みモデルにおいても、LEEPと再学習したモデルの精度は非常に高い相関を示していることが分かります。
LEEP vs. Convergence of Fine-tuned Models
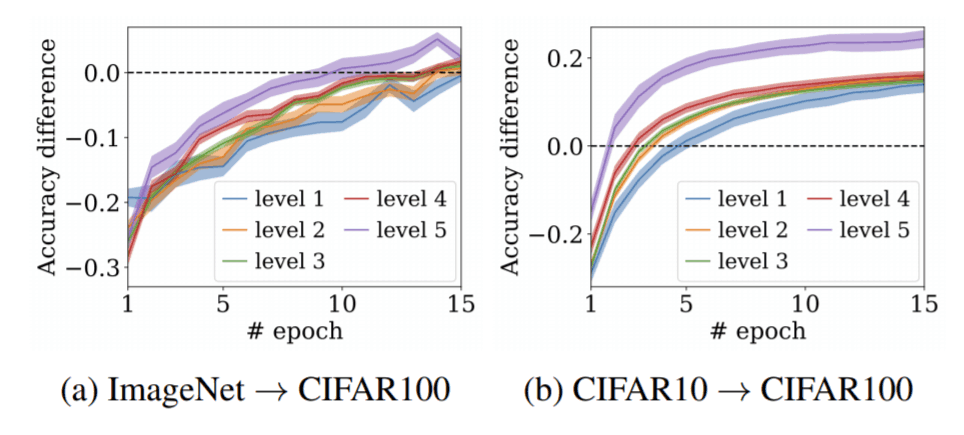
次の実験では、Fine-tuneされたモデルの収束の早さをLEEPで予測するという実験を行っています。Fine-tuneされたモデルの収束の早さを測定するために、Referenceモデルとしてデータセットからランダムに5クラス選択し、そのクラスに含まれるサンプルをすべて用いて、スクラッチで学習したものを使用しています。Fine-tuneモデルはCIFAR100から上記と同じ5クラス選択して、それぞれのクラスは50枚の画像を用いて学習します。下記の図をご覧ください。図中の黒の点線(0.0)はスクラッチモデルとFine-tuneモデルの精度の差分が0となった部分です。なお、level1~5というのは、LEEPの値を5つのレベルに分けたもので、レベルが大きくなるとLEEPの値が大きくなったことを示しています。下記の図からLEEPの値が大きくなるにつれて、収束が早くなることを示しています。
Comparison of LEEP, NCE, H scores, CNAPS
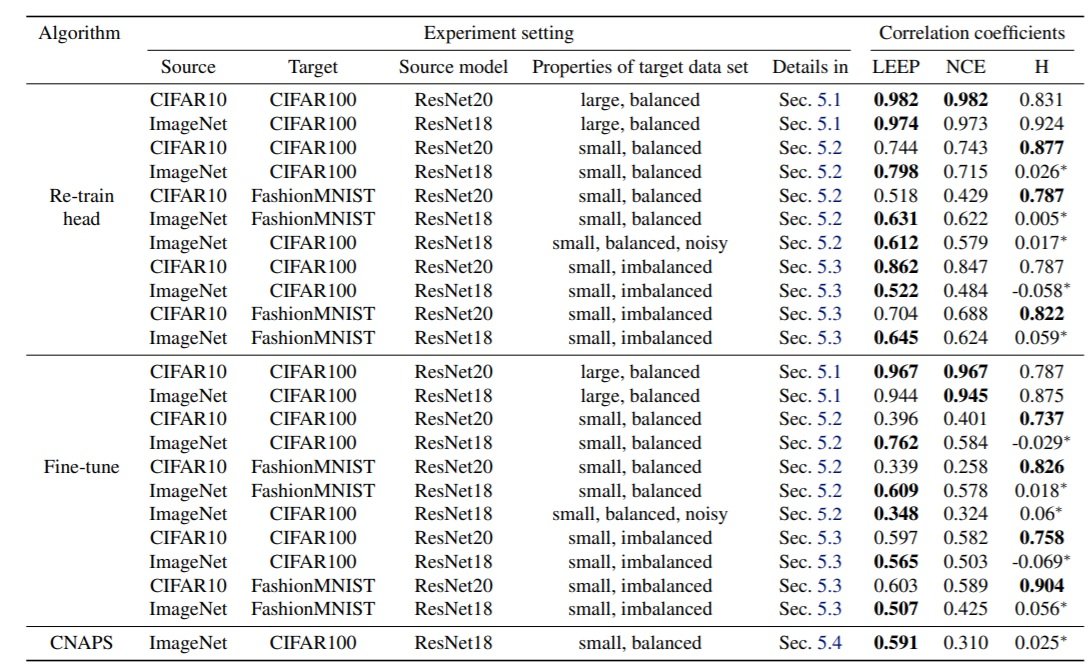
次の実験では、最新の転移学習の測定指標(NCE、H scores)およびメタ転移学習の最新手法であるCNAPSとLEEPの値の相関を調べています。この実験では、ターゲットデータセットDに制限を加えています。largeはデータセットをすべて用いて再学習、smallはデータセットの一部のみを用いて再学習、imblancedは各クラスに含まれるサンプル数を30~60と変化させた場合を示しています。下記の図から、最新手法と比較してLEEPは高い相関を示していることが分かります。
LEEP for Source Model Selection
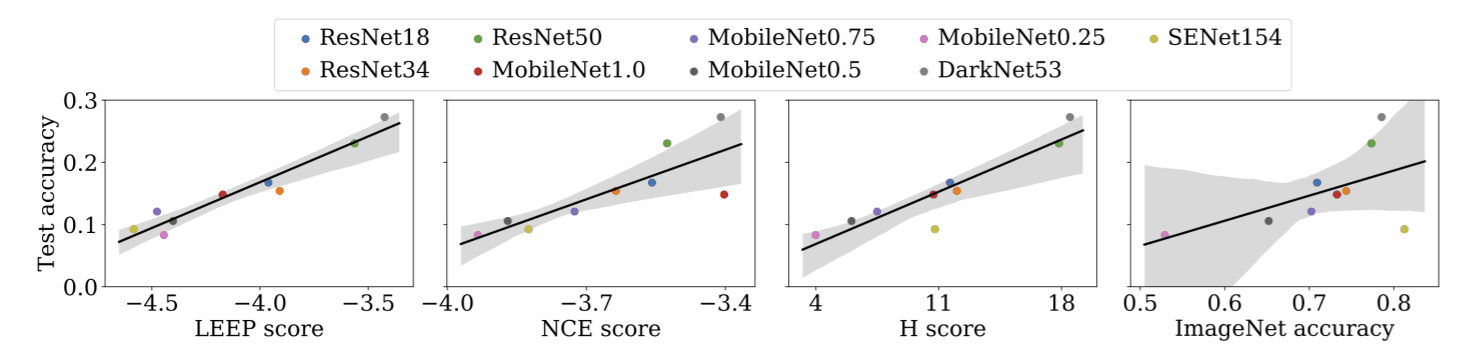
ここからがこの論文の主題です。LEEPを用いてモデル選択を行うというものです。使用した学習済みモデルはResNet・MobileNet・SENet・DarkNetです。下記の図をご覧ください。LEEPは他の手法と比べてモデルの精度を正確に予測できています。つまり、モデル精度とLEEPの値が高い相関を示しているため、LEEPの高い値を示したモデルを用いれば、再学習したモデルの精度が高いことが予測されます。(例えば、NCEではMobileNet1.0を上手く予測できていません。)
まとめ
今回紹介した研究は、最適な学習済みモデルを効率良く、そして高精度に予測する指標LEEPを提案しています。実験の結果、9種類のモデルのLEEP値が、それぞれのモデルで再学習した精度と高い相関を示しています。つまり、LEEPを用いることで限られた計算リソースで準最適なモデルアーキテクチャを選択することが出来ます。このように、深層学習モデルを使用するにあたって、転移学習は非常に重要な技術です。この転移学習において、どの学習済みモデルを選択するのが良いのか、訓練することなしに予測することができるこのような技術は非常に有益だと考えられます。非常に面白い研究分野ですので、皆様も動向をチェックしてみていかがでしょうか。





この記事に関するカテゴリー




