Generating 3D Objects From Text - DreamFusion
3 main points
✔️ Proposal of DreamFusion to generate 3D objects from text only using a pre-trained Text-to-Image model (Imagen)
✔️ Proposal of SDS (ScoreDistillation Sampling)
✔️ Combining the proposed SDS with NeRF, which is specialized for 3D generation tasks, we generate high-fidelity 3D objects and scenes for a variety of texts.
DreamFusion: Text-to-3D using 2D Diffusion
written by Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall
(Submitted on 29 Sep 2022)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Machine Learning (stat.ML).
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
first of all
In recent years, many digital media such as games, movies, and simulators require thousands of 3D data. However, 3D assets are designed manually using modeling software, which requires a great deal of time and expertise.
The main approaches to solve these problems are GAN and NeRF, which specialize in generating specific objects such as faces, but do not support text. NeRF also supports the text but lacks realism and accuracy.
DreamFusion, presented in this paper, aims to lower the barrier of entry for beginners to digital media by generating 3D objects from the text while improving the workflow of veterans.

outline
DreamFusion combines NeRF, which is specialized for 3D generation tasks, with a newly proposed method, Score Distillation Sampling (SDS), to generate 3D objects.
NeRF is optimized to recover the shape of a particular scene and can synthesize a new view of that scene from unobserved angles. As such, it has been incorporated into many 3D generation tasks. However, 3D objects generated from pre-trained 2D Text-to-Image models tend to lack realism and accuracy.
To solve this problem, the authors proposed Score Distillation Sampling (SDS), which enables sampling from a Diffusion Model by optimizing the loss function. DreamFusion is achieved by combining this newly proposed SDS with NeRF, which is specialized for 3D generation tasks.
SDS(Score Distillation Sampling)
The key part of DreamFusion in this study, SDS, uses the structure of the diffusion model to provide tractable sampling through optimization so that minimizing the loss function yields a sample.
The Diffusion Model used is computationally expensive for the Jacobian terms as they need to be backpropagated. It is also trained to approximate the scaled Hessian of the marginal density, so small noise levels are insufficient.
Therefore, we found that omitting the Jacobian term of the Diffusion Model provides an effective gradient for optimizing the DIP using the Diffusion Model, which is realized by the following equation.
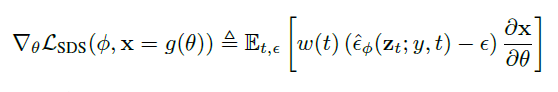
We optimize over the parameter θ, where θ is the 3D volume parameter and g is the volumetric renderer so that x = g(θ) looks like a sample from the frozen diffusion model. Here, the gradient of the probability density distillation loss is weighted by the score function learned in the diffusion model.
We named this sampling method SDS (Score Distillation Sampling). This creates a 3D model that looks like a good image when rendered from random angles.
DreamFusion
The Diffusion Model used for DreamFusion uses only a 64×64 base model and uses this trained model without any modifications.
In this section, we will explain the algorithm using an example of the flow of image generation in DreamFusion from a natural language caption "a picture of a peacock on a surfboard" to "a peacock on a surfboard that looks like it was taken with a DSLR". (see figure below)
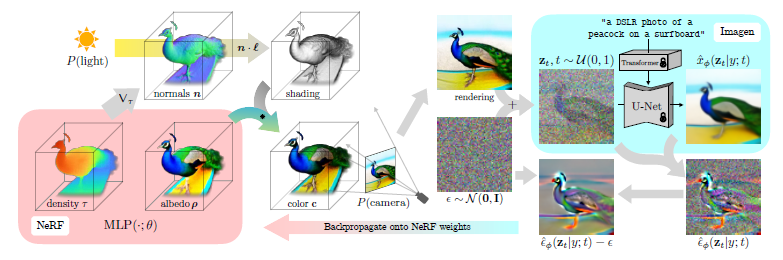
Each DreamFusion optimization iteration is performed as follows
- Randomly sampling cameras and lights
- Rendering a NeRF image from that camera and light, and shading it with that light.
- Calculate SDS loss gradients for NeRF parameters
- Use optimizer to update NeRF parameters
We will now explain these steps.
1, The scene represented by NeRF is initialized randomly and trained from 0 for each caption. The NeRF used here is parameterized by volume density and albedo (color) using MLP.
2, This NeRF is rendered from a random camera and shaded with a random lighting direction using normals computed from the density gradient. The shading reveals details that would be obscured from a single viewpoint.
3, To update the parameters, DreamFusion diffuses the rendering and reconstructs it with a conditional Imagen model to predict the added noise. This has a high variance but includes a structure to improve fidelity.
4, Also, by subtracting the added noise, a low-dispersion update direction stop grad is generated. This is back-propagated through the rendering process to update the parameters of the NeRF MLP
Thus, DreamFusion is realized by combining SDS and NeRF, which is specialized for 3D generation tasks.
Experiments and Results
In this paper, we compare existing zero-shot text-to-3D generated models and evaluate their performance to identify the key components of DreamFusion that enable accurate 3D geometry.
Comparison with multiple baselines
We evaluated CLIP R-Precision, an automatic metric for the consistency of rendered images concerning input captions.
The table below shows the results of CLIP R-Precision on DreamFusion and several baselines, including DreamFields, for oracles evaluated on pairs of original captioned images by CLIP-Mesh and MS-COCO. The figure on the right shows a visual comparison of each 3D object generated in this experiment.
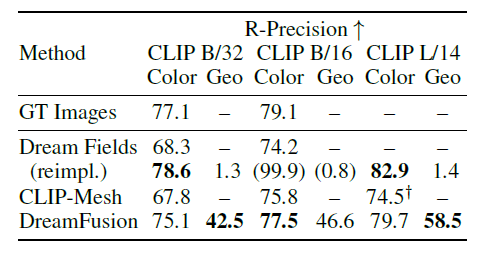

This evaluation is based on CLIP, where DreamFields and CLIP-Mesh have an advantage because they use CLIP during training. Among them, DreamFusion outperforms the baseline performance on color images and approaches the performance of true images.
When geometry (Geo) was evaluated with textureless rendering, DreamFusion matched the caption 58.5% of the time.
Identification of key components
To identify the key components of DreamFusion that enable accurate 3D geometry, we checked geometry quality by measuring CLIP R-Precision on a baseline albedo render (left), a full shaded render (middle), and a textureless render (right) (see the figure below). (see figure below)
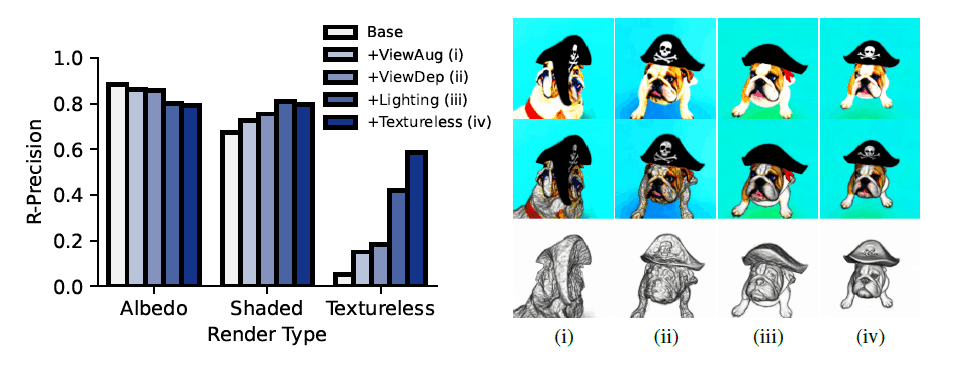
We found that restoring accurate geometry requires view-dependent prompting, illumination, and textureless rendering.
summary
In this study, it was shown that the combination of the newly devised SDS (Score Distillation Sampling) and NeRF, which is specialized for 3D generation tasks, can generate 3D objects and scenes with high fidelity for a wide variety of texts. Although this approach was taken from NeRF, it is expected that courses from GANs will be taken in the future. In addition, DreamFusion uses a 64×64 Imagen model, which tends to lack detail in the generated objects. It is expected that this problem will be solved in the future to enable high-resolution and easy-to-handle 3D synthesis.
In this way, new methods may emerge in Image-to-Image by taking multifaceted approaches such as Text-to-Image. We hope that this technology will become even more realistic and play an active role in digital twins and robotics in the future.



Categories related to this article