
AgentVerse, A Multi-agent Framework For Simulating Cooperative Human Behavioral Processes, Is Now Available!
3 main points
✔️ Propose AgentVerse, a framework to facilitate collaborative work by multi-agent groups
✔️ Dynamically adjust the composition of agent groups through a modular structure that simulates a problem-solving process
✔️ Comparative experiments The results show that AgentVerse outperforms single-agent systems.
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors in Agents
written by Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chen Qian, Chi-Min Chan, Yujia Qin, Yaxi Lu, Ruobing Xie, Zhiyuan Liu, Maosong Sun, Jie Zhou
(Submitted on 21 Aug 2023)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
With the advent of GPT-4, autonomous agents based on Large Language Models (LLMs) such asAutoGPT, BabyAGI, and AgentGPT have made significant progress, allowing them to make effective decisions and perform a wide range of tasks.
In the real world, on the other hand, cooperation between individuals is necessary to efficiently perform complex tasks such assoftware development, consulting, and game playing.
Despite this fact, existing research has not attempted to simulate the cooperative behavior that is structured in human groups when performing complex tasks (referred to in technical terms as the problem-solving process ).
In this paper, we propose AgentVerse, a framework to simulate human cooperative behavior and promote collaboration among multiple agents in task solving, and demonstrate that collaborative work by a multi-agent group outperforms single-agent performance through experiments. The paper demonst rates that collaborative work by a multi-agent group outperforms that of a single agent.
AgentVerse Framework
The aforementioned problem-solving process is a series of processes that occur in human groups in which "the group determines the degree of disagreement between the current state and the desired goal, dynamically adjusts the group composition to facilitate cooperation in decision making, and then implements informed action. The process is a series of processes that occur in human groups.
AgentVerse proposed in this paper simulates the problem-solving process to increase the task execution rate of autonomous multi-agent groups, and consists of four modules as shown in the figure below: Expert Recruitment, CollaborativeDecision-Making, Action Execution, and Evaluation.
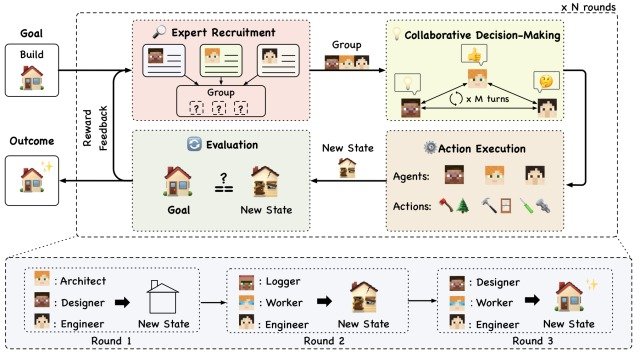
A series of executions of these four modules is represented by a unit called Round, and the group configuration of the agents is dynamically adjusted by repeating Round 1, Round 2, Round 3, and so on.
Let's take a look at each of these modules.
Expert Recruitment
This module plays an important role in determining the configuration of a multi-agent group and in determining the upper limit of the group's task execution capacity.
Recent research suggests that just as humans employ experts (Experts) to form teams, designating specific roles to autonomous agents can improve their performance.
On the other hand, which roles to assign to autonomous agents depended on human knowledge and intuition, and had to be assigned manually based on an understanding of the task.
In this regard, AgentVerse employs the following automated approach to assigning roles to agents
- Generate a set of expert descriptions for task completion based on predefined expert descriptions (role-detailed prompts)
- The agents generated by this form a multi-agent group to complete a given task
- Dynamically adjust the configuration of multi-agent groups based on feedback from Evaluation (described below)
These mechanisms allow AgentVerse to configure the most effective multi-agent groups based on the current state.
Collaborative Decision-making
This module involves collaborative decision making by the generated agents.
Many studies have examined the effectiveness of various communication structures between agents in facilitating effective decision making, and this paper focuses on two typical communication This paper focuses on two typical communication structures: Horizontal Communication and Vertical Communication.
Horizontal Communication is horizontal communication and encourages mutual understanding and cooperation among agents, with each agent taking equal responsibility and actively sharing decision-making.
This structure makes Horizontal Communication effective for tasks that require creative ideas or active collaboration, such as brainstorming, consulting, and cooperative game playing.
Vertical Communication, on the other hand, is a vertical communication structure in which responsibilities are divided so that one agent makes decisions and the remaining agents act as reviewers and provide feedback.
This structure makes Vertical Communication useful for tasks that require iterative refinement of decisions toward a specific goal, such as software development.
Action Execution
This module performs specified tasks based on the communication structure determined in the Collaborative Decision-making described above.
Evaluation
This module is the last part of the Agentverse and will play an important role in adjusting the group composition and improving it in the next Round.
This module provides feedback with constructive suggestions on how to improve in the next Round by assessing the difference between the current state and the target task. (This feedback can be defined by a human or automatically by the model, depending on the implementation.)
If the task is then deemed unaccomplished, the suggested feedback is sent to the initial stage of the Expert Recruitment module, where the agent group composition is adjusted based on the feedback, and Round is repeated in a series of steps until the task is completed.
Experiments
To demonstrate that AgentVerse can perform a task more efficiently than a single agent, a quantitative experiment with a benchmark task was conducted. (This experiment was based on GPT-3.5-Turbo and GPT-4.)
The following benchmarks were used in this experiment to measure Conversation,Mathematical Calculation, Logical Reasoning, andCoding.
- Conversation: using the FED and Commongen-Challenge datasets, which are dialogue response datasets
- Mathematical Calculation: using MGSM, a dataset containing elementary math problems
- Logical Reasoning: using the Logic Grid Puzzles dataset from an existing study called BigBench
- Coding: using the Humaneval dataset, a code completion dataset
In the experiment, the single agent generated responses directly using the given prompts, while AgentVerse generated responses through the collaborative work of the constructed multi-agent group.
Vertical Communication was also employed because these benchmark tasks benefit from a communication structure in which a single agent iteratively refines its own responses.
The results of the experiment are shown in the figure below.
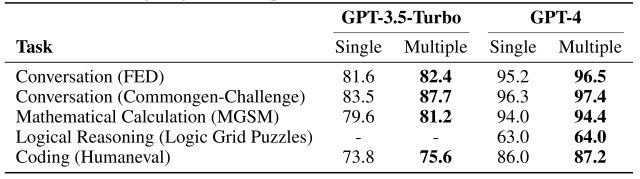
As the figure shows, multi-agent groups with AgentVerse consistently outperform single agents in both GPT-3.5-Turbo and GPT-4.
Thus, the results of this experiment demonstrate that collaborative work by a multi-agent group outperforms the performance of individual agents.
Summary
How was it? In this article, we proposed AgentVerse, a framework for simulating human cooperative behavior and facilitating collaboration among multiple agents in task solving, and demonstrated through experiments that collaborative work by a multi-agent group outperforms that of a single agent. The paper was described.
While the results of this experiment demonstrate the effectiveness of collaborative work by multi-agent groups, on the other hand, this study did not use advanced agents such as AutoGPT or BabyAGI, but used LLMs with basic conversational memory.
The authors state that future research will integrate more powerful performance agents into the AgentVerse framework, extending and improving it to handle a wider range of tasks, and we are very much looking forward to future progress.
The details of the AgentVerse architecture and experimental results presented here can be found in this paper for those interested.



Categories related to this article






