
BERT Can Predict The Buzz Level Of A Tweet!
3 main points
✔️ Propose ViralBERT to predict the virality of tweets using tweet text features and user-based features
✔️ Our method achieves 13% better performance than the baseline on both F1 Score and Accuracy
✔️ Ablation study found that textual sentiment information and follower count are the most effective features in prediction, and that including hashtag count decreases prediction accuracy
ViralBERT: A User Focused BERT-Based Approach to Virality Prediction
written by Rikaz Rameez, Hossein A. Rahmani, Emine Yilmaz
(Submitted on 17 May 2022)
Comments: UMAP 2022
Subjects: Computation and Language (cs.CL); Social and Information Networks (cs.SI)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
first of all
In recent years, Twitter has been used around the world as a social networking service to share and spread information to users and has become important not only for individuals but also for marketing for all kinds of companies.
On Twitter, users can easily share posts they like by "retweeting" them to other users, which can strengthen the influence of the post by spreading it to more users.
Knowing how many retweets a post gets in this way, i.e. how much influence it can increase, is of great value to advertisers and influencers.
In this paper, we introduce the BERT module, which employs a method to concatenate numerical features such as hashtags and the number of followers with the tweet text, and learns by combining text and numerical features. The RoBERTa module only analyzes the sentiment of the text since the information in the text and the ability to elicit emotional responses are related to retweeting tendencies. We introduce ViralBERT, which predicts the virality (=buzziness) of tweets through the RoBERTa module, which only performs the analysis.
Historical Background and Problem Definition
Twitter is one of the world's largest social media platforms with over 300 million monthly active users. Twitter users can share text of up to 280 characters, called a "tweet," and send photos, GIFs, and videos.
If a tweet gets more interactions than other tweets and attracts attention from more users on Twitter, it has viral.
Thus virality can be used to determine the popularity and engagement of a trend or topic not only on Twitter but also in society as a whole, predicting the virality of a tweet is very important.
However, recent work on predicting virality has been limited, and these studies have focused on a specific subset of tweets or specific users rather than tweets from the entire user base, and have not generalized to users or tweets as a whole.
Furthermore, predicting virality is affected by many factors that cannot be easily quantified, such as user affinity, the creativity of content (tweets), relevance to the current social climate, etc. In addition, most tweets are never retweeted, making it difficult to create large data sets This makes it a very difficult problem to solve.
Outline of this paper
To solve these problems, in this paper, we built a sample dataset consisting of 330k tweets and tested whether we can predict the virality of tweets using the BERT architecture for this problem.
dataset
The dataset for this study was collected by Twitter API v2 using Python and is limited to eight topics: Cryptocurrencies, TV&Movies, Pets, Video Games, Cell Phones, COVID-19, Football, and K-pop.
We also collect from the original (not retweeted posts) English tweets in this study about the text, creation time, number of hashtags, number of mentions, and tweet source client, and users about the number of followers, followers, and status.
In addition, the number of retweets, likes, replies, and quotes are retrieved 24 hours after the tweet is created. (Because existing research shows that the virality of a tweet reaches its limit by this time.)
ViralBERT
The architecture of ViralBERT proposed in this paper is shown in the figure below.
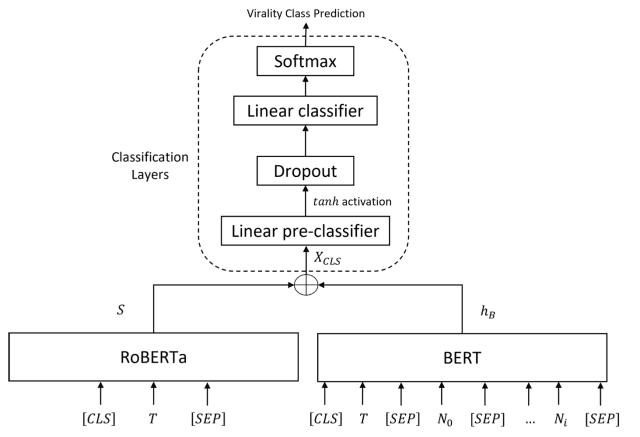
The model uses BERT to output from features that combine tweet text and its associated numerical features (hashtags, mentions, followers, status, and text length), and RoBERTa to output the probability distribution of the emotional features of the tweet text, which is then predicted virality by feeding it to the classification layer.
BERT Module
BERTweet, the pre-trained model used in BERT, is fine-tuned on a corpus of 850M tweets and optimized for a wide range of topics and languages used in tweets from users.
The concatenated tweet text T and its associated numerical features ( N0, N1,..., Ni) are input to this model and its output hB is input to the classification layer. , Ni ) concatenated together, and the output hB is input to the classification layer.
This is expressed in the equation below.
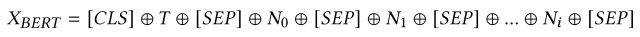
RoBERTa module
Existing studies have shown that the sentiment features of tweets directly affect the propagation of tweets, and our model employs a RoBERTa-based pre-trained model for sentiment analysis of tweet text.
The output of this model is a softmax probability distribution S of negative, neutral, and positive emotions from the tweet text, which is input to the classification layer in the same way as the output of BERT described above.
classification layer
The output hBof BERTand the output S of RoBERTa are concatenated as inputs to the classification layer and the output is the following equation
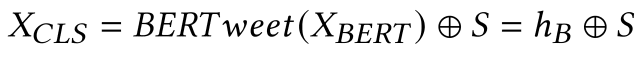
The probability of virality can be obtained by applying a softmax function to this output.
Experiments
In this paper, we compare the performance of ViralBERT with the following baseline methods developed for similar tasks in existing studies.
- Logistic Regression: We employ the Newton method for gradient optimization, and this method is used to predict popular messages.
- Support Vector Machine (SVM): employing hinge loss and SGD optimization, this method is used to predict the popularity of newly introduced hashtags on Twitter and to evaluate the ease of retweeting.
- Decision Tree Classifier: Classification without maximum depth using Gini impurity score. This method is used to evaluate the ease of retweeting.
- Random Forest (Random Forest Classifier): we use 100 trees without maximum depth. This baseline is based on existing research focusing on the temporal prediction of the number of retweets and the likelihood of retweeting.
In addition, we added two additional baselines, MLPNum, which uses only numerical features in this model, andViralBERTText, which uses only text features, to test how these features perform.
The results of the experiment are shown in the table below. (The best results are shown in bold) 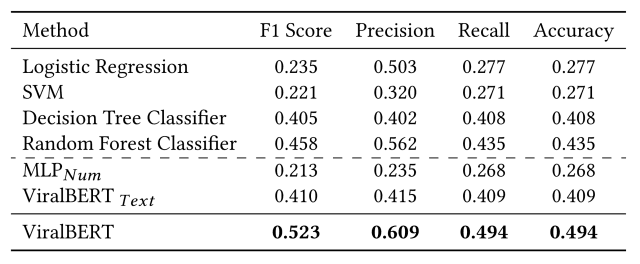
From this experiment, we know the following.
- When ViralBERT is trained with text features only, can note obtain optimal performance compared to normal ViralBERT.
- When training with only numerical features, the performance is significantly better than when using only text, indicating that numerical features are an importer in predicting virality.
- By fine-tuning ViralBERT on a concatenated input of textual and numerical features and training the classification layer, we can achieve a significantly higher evaluation metric than the baseline.
In addition, we conducted experiments to measure the importance of each feature for ViralBERT by removing features from the input and comparing the performance of the models.
The table below shows the comparison results with ViralBERT when each feature is eliminated from the input.
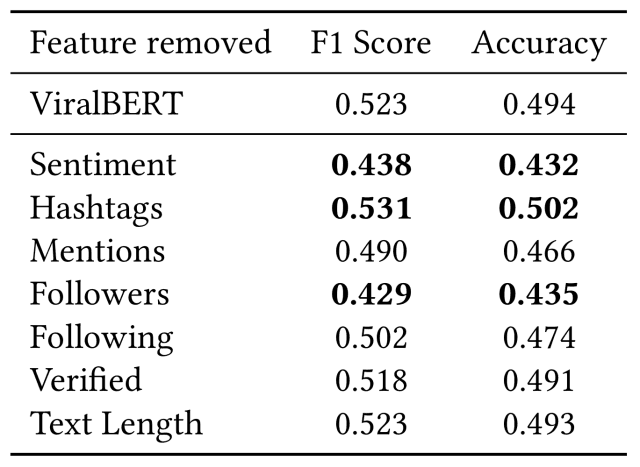
The following observations were obtained from this experiment.
- Eliminating Sentiment or Followers from the network significantly degrades the performance of the model compared to other features
- This is intuitive, as users with more followers are likely to get more attention with a single tweet
- Also, tweets that provoke a greater emotional response in users may get more retweets
- Mentions and Following are also smaller than the above two features, but they affect the performance
- This is thought to be because the more popular users tend not to follow others (higher follower/following ratio)
- Also, tweets with a high number of mentions are less likely to be retweeted because they lack readability and use space that could be used for useful information for the user
- The most surprising result is that eliminating Hashtags slightly improves the performance of the model
- This means that BERT may be learning a worse representation from the input by adding this feature since it is not related to virality
These results should be further investigated in a more comprehensive study involving larger data sets and testing the interactions between each feature, and it will be a future challenge to understand why these negatively affect performance.
summary
How was it? In this article, we introduced ViralBERT, a BERT-based method for predicting the virality of tweets using both textual and numerical features of tweets.
Although we achieved better accuracy in predicting virality than existing methods with this model, there are still some issues such as the imbalance of the dataset used in this paper, and we may be able to further improve the prediction accuracy by eliminating the class heterogeneity that exists in the dataset. We also found that the number of followers affects virality, so collecting tweets with high virality from less popular users may help to create a better dataset. In addition, there is a possibility that this model can be used for other social media to predict virality for various media, so we are very excited to see what the future holds.
The details of the architecture and dataset of the model presented in this article can be found in this paper if you are interested.



Categories related to this article






