
Multimodal Emotion Recognition From Text, Voice And Vision: Sony's Proposed M2FNet!
3 main points
✔️ Achieve high accuracy in emotion recognition by leveraging text, speech, and video features!
✔️ Transformerlearns relationships between utterances and Multi-Head Attentionlearns relationships between modalities!
✔️ Video features showed the necessity of using not only "facial expressions" but also "whole scene" context.
M2FNet: Multi-modal Fusion Network for Emotion Recognition in Conversation
written by Vishal Chudasama, Purbayan Kar, Ashish Gudmalwar, Nirmesh Shah, Pankaj Wasnik, Naoyuki Onoe
(Submitted on 5 Jun 2022)
Comments: Accepted for publication in the 5th Multimodal Learning and Applications (MULA) Workshop at CVPR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Sound (cs.SD); Audio and Speech Processing (eess.AS)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction

The above figure shows the accuracy (weighted average F1) of existing methods and the proposed M2FNet in emotion recognition on both MELD and IEMOCAP datasets. The proposed method maintains high accuracy on both datasets while the existing method has biased accuracy depending on the data.
This time, we introduce M2FNet (Multi-modal Fusion Network), a model for Emotion Recognition in Conversations (ERC) task. In contrast, M2FNet is a brilliant and efficient method to handle textual data. In contrast, M2FNet successfully enables highly accurate estimation by taking advantage of useful features of all three modalities and has achieved SoTA on both of the two main ERC datasets. The main contributions are as follows
- More useful features were extracted from the video by considering multiple persons based not only on facial expression features but also on features of the scene as a whole.
- Triplet Loss with Adaptive Margin for Extracting Useful Features from Audio and Video
- Feature fusion based on Multi-Head Attention mapped useful information related to audio and visual emotion to text features
- Highest accuracy in weighted average F1 Score for MELD and IEMOCAP benchmarks, demonstrating the robustness of the proposed method
Let's take a look at M2FNet.
What is ERC?
ERC is a task that recognizes human emotions in conversation based on text, scene, and voice, and is expected to be applied to the analysis and modeling of multimedia content. Applications include user reactions to content, dialogue systems optimized for each user, AI-based interviews, and sentiment analysis.
The emotion recognition data in a conversation is shown in the figure below. The task of ERC is to estimate these emotion labels.

systematic positioning
Conventional ERC methods focus mainly on using textual information in conversations and tend to ignore the other two modalities. This limits the analysis of emotions because it does not take into account audio and visual information. Since ERC data consists of three modalities (text, video, and audio), there is no reason not to take advantage of them. This paper proposes a model with the motivation that a multimodal approach can improve the accuracy of emotion recognition. Although multimodal approaches exist in existing methods, this paper proposes several mechanisms to better extract and combine the features of each modality.
big picture
First, here is a general overview of M2FNet.

It looks complicated because of the three modalities, but if you look at them one by one, you will understand.
The data to be handled consists of a set of utterances U and an emotion label Y for each utterance. each data xi in U consists of three modalities (text, audio, and video), and an emotion label yi is given for each utterance xi. a Dialog consists of k utterances.
![]()
The model is divided into two main stages. The first half, Utterance Level, performs feature extraction for each utterance(Intra-Speaker) and each modality independently. In the Dialog Level, in the second half, features are extracted for each inter-speaker (Inter-Speaker) and contextual information is captured. After that, the relationship between modalities is extracted and the final emotion labels are estimated.
Utterance Level Feature Extraction
Before passing to the Dialog level, features for each utterance and modality are first extracted separately at the Utterance Level. Text, audio, and video are explained separately. Audio and video are important.

text characteristic
Text features are extracted by fine-tuning modified RoBERTa, a large-scale natural language model. Text features are extracted not strictly for each utterance, but for all utterances including those before and after the utterance, separated by a Separate token <S>. The resulting text features are DT dimensional.
![]()
Feature Extractor Module
It uses a proprietary model for audio and video feature extraction instead of existing models. It is a learning mechanism by Triplet Loss with Adaptive Margin.
 This mechanism is based on the Triplet Loss of FaceNet, a face recognition model. What we want to obtain are features that can discriminate various facial expressions, scenes, and sounds of each person. First, we prepare an image feature (Anchor), a set of samples with the same label (Positive), and a set of samples with different labels (Negative). In ERC, useful features are obtained by bringing samples with the same emotion labels closer together and moving the others apart. The Triplet Loss of the proposed method is as in Eq.
This mechanism is based on the Triplet Loss of FaceNet, a face recognition model. What we want to obtain are features that can discriminate various facial expressions, scenes, and sounds of each person. First, we prepare an image feature (Anchor), a set of samples with the same label (Positive), and a set of samples with different labels (Negative). In ERC, useful features are obtained by bringing samples with the same emotion labels closer together and moving the others apart. The Triplet Loss of the proposed method is as in Eq.
![]()
The first item is the Triplet Loss by Adaptive Margin, the second item is the variance term of the feature, the third item is the covariance term, and λ is the respective weight.
Triplet Loss selects samples from a large set of samples that are particularly useful for training. Samples that are suitable for training are those with Dap-Dan>0 (Hard), where the distance Dap between the Anchor and the Positive is larger than the distance Dan between the Negative and the Positive. If Dap is smaller than Dan from the beginning, optimization is not very meaningful. In this case, Triplet Loss has some margin m, and if Dap-Dan-m>0, it is also learned (Semi-Hard). However, since FaceNet has a fixed value for the margin, if the Positive and Negative are at the same distance from the Anchor, the loss is close to 0 and learning does not proceed. Therefore, M2FNet proposes Adaptive Margin-based Triplet Loss, which uses an adaptive margin based on the distance between features.
![]()
Let the adaptive margin be determined from the similarity/dissimilarity based on the distance between features as follows. This allows for more flexible learning of features related to emotion labels from audio and video.
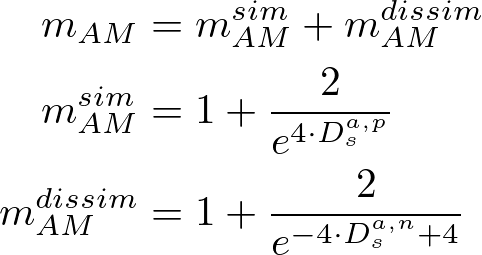
The second term is a dispersion term to prevent mode collapse, and the third term is a covariance term to reduce the correlation between dimensions.
%3B%5C%3BZ_k%3DZ_a%2CZ_p%2CZ_n%5C%3B%5Cleft(L_%7BVar%7D(Z_k)%3D%5Cfrac%7B1%7D%7Bd%7D%5Csum_%7Bj%3D1%7D%5Ed%201-%5Csqrt%7BVar(Z_%7B%3A%2Cj%7D)%2B%5Cepsilon%7D%5Cright)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
%3B%5C%3BZ_k%3DZ_a%2CZ_p%2CZ_n%5C%3B%5Cleft(L_%7BCov%7D(Z_k)%3D%5Cfrac%7B1%7D%7Bd%7D%5Csum_%7Bi%5Cneq%20j%7D%20Cov(Z_%7Bk%7D)_%7Bi%2Cj%7D%5ET%5Cright)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
Audio and video are handled a little differently, so let's take a closer look.
Voice Features
In a 2021 ICCV paper, it was shown that emotion recognition using speech data is more accurate when the signal itself is treated as an image rather than a mel-spectrogram of plotted frequency characteristics. Inspired by this, M2FNet also treats speech as an image for feature extraction. First, time warp and Additive White Gaussian Noise (AWGN) is applied before converting to a mel spectrogram.
The mel-spectrogram is a feature plotted in RGB with time on the horizontal axis and frequency on the vertical axis by setting up local time windows and applying the short-time Fourier transform (STFT) to each of these windows. This is passed through the feature extractor described earlier to obtain speech features for each utterance i. DA is the dimension of the speech features obtained.
![]()
Video Features
Video features are obtained by extracting features from each frame of the video corresponding to each utterance and combining them across frames, and M2FNet proposes a Dual Network that uses not only the facial expressions of the person but also the entire frame to capture the context to extract more emotion-related features.

The first step is the facial expression feature ( Weighted Face Model ). First, each of the 15 consecutive frames corresponding to utterance i is input to a Multi-task Cascaded Convolutional Network (MTCNN) to detect faces. Since there are multiple faces detected, the weighted sum of each facial feature obtained by the feature extractor described above is used as the feature value. The area of the bbox is used as the weight. By normalizing the area and keeping it within the range of [0,1] as a weight, the facial expressions emphasized in each frame are given more weight. The expression features for each utterance i are obtained by passing Max-pooling through the expression features of the 15 frames.
%3D%5Csum_%7Bj%5Cin%20%5Cmathrm%7BMTCNN%7D(x_v%5Ei)%7D%20%5Cmathrm%7BFaceModel%7D(x_%7Bvj%7D%5Ei)%5Ccdot%20%5Cmathrm%7BArea%7D(x_%7Bvj%7D%5Ei)_%7B%5Cmathrm%7Bnormalized%7D%7D%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f) Next is Scene Embedding. Scene features are simple: each frame is passed through a feature extractor and 15 frames are compressed using Max-Pooling. The features obtained from these two networks are combined to form the final video features. Thus, if we dare to formulate the equation, it is as follows.
Next is Scene Embedding. Scene features are simple: each frame is passed through a feature extractor and 15 frames are compressed using Max-Pooling. The features obtained from these two networks are combined to form the final video features. Thus, if we dare to formulate the equation, it is as follows.
![\begin{align*}
F_{IV}^i=\mathrm{Concat}\left(
&\mathrm{Maxpool_{15frames}}(\phi_{Scene}(x_v^i)),\\
&\mathrm{Maxpool_{15frames}}(\phi_{WF}(x_v^i))
\right)\;|\;i\in[1,k],\; \forall F_{IV}\in\mathbb{R}^{k\cdot D_v}
\end{align*}](https://texclip.marutank.net/render.php/texclip20221227205222.png?s=%5Cbegin%7Balign*%7D%0A%20%20%20%20F_%7BIV%7D%5Ei%3D%5Cmathrm%7BConcat%7D%5Cleft(%0A%20%20%20%20%26%5Cmathrm%7BMaxpool_%7B15frames%7D%7D(%5Cphi_%7BScene%7D(x_v%5Ei))%2C%5C%5C%0A%20%20%20%20%26%5Cmathrm%7BMaxpool_%7B15frames%7D%7D(%5Cphi_%7BWF%7D(x_v%5Ei))%0A%20%20%20%20%5Cright)%5C%3B%7C%5C%3Bi%5Cin%5B1%2Ck%5D%2C%5C%3B%20%5Cforall%20F_%7BIV%7D%5Cin%5Cmathbb%7BR%7D%5E%7Bk%5Ccdot%20D_v%7D%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
The text, audio, and video features for each utterance i obtained in this way are now used in the Dialog Level feature extractor.
Dialog Level Feature Extraction
From this point on, we will extract the relationship between the k utterances, i.e., on a Dialog-by-Dialog basis.
Learning relationships between utterances
First, we learn the relationship between utterances for each modality. The k- and D-dimensional features FIT, FIA, and FIV for each modality are input to multiple Transformer Encoders.
 In order not to ignore low-level features, the Transformers are connected by skip-connection. In the paper, this is described in the equation below.
In order not to ignore low-level features, the Transformers are connected by skip-connection. In the paper, this is described in the equation below.
![\begin{align*}
F_T^i=Tr_{N_T}(...(Tr_{N_2}(Tr_{N_1}(F_{IT}^i)))),\\
F_A^i=Tr_{N_A}(...(Tr_{N_2}(Tr_{N_1}(F_{IA}^i)))),\\
F_V^i=Tr_{N_V}(...(Tr_{N_2}(Tr_{N_1}(F_{IV}^i)))),\\
\mathrm{where},\;i\in[1,k]
\end{align*}](https://texclip.marutank.net/render.php/texclip20221227210826.png?s=%5Cbegin%7Balign*%7D%0A%20%20%20%20F_T%5Ei%3DTr_%7BN_T%7D(...(Tr_%7BN_2%7D(Tr_%7BN_1%7D(F_%7BIT%7D%5Ei))))%2C%5C%5C%0A%20%20%20%20F_A%5Ei%3DTr_%7BN_A%7D(...(Tr_%7BN_2%7D(Tr_%7BN_1%7D(F_%7BIA%7D%5Ei))))%2C%5C%5C%0A%20%20%20%20F_V%5Ei%3DTr_%7BN_V%7D(...(Tr_%7BN_2%7D(Tr_%7BN_1%7D(F_%7BIV%7D%5Ei))))%2C%5C%5C%0A%20%20%20%20%5Cmathrm%7Bwhere%7D%2C%5C%3Bi%5Cin%5B1%2Ck%5D%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
Learning and combining relationships between modalities
Then, for the Dialog Level features, relationships between modalities are extracted and combined. First, the three features are input into the Fusion Attention Module consisting of Multi-Head Attention. Note that Ft uses features from the previous layer, but Fv and Fa remain unchanged.
Finally, by combining the mapped text features with Fv and Fa, the video and audio features are used directly in addition to the relationship extraction described earlier. This yields the final features for the entire utterance and the entire modality.

Finally, the emotion labels are output by passing through all the two coupling layers. The loss is cross entropy, assuming there are k utterances per M dialogs and one emotion is assigned from C emotion labels.
%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
experiment
The experiment compares ablation and SoTA with MELD and IEMOCAP as benchmarks for ERC. Both are multimodal data sets consisting of text, video, and audio data.
data-set
MELD consists of over 1,400 conversations and 13,000 utterances from the TV series "Friends". Each utterance is assigned one of seven emotion labels: anger, disgust, sadness, joy, surprise, fear, and neutral. The pre-prepared Train/Valid is used as is.
IEMOCAP is a conversational database of about 12 hours; there are 6 emotion labels happy, sad, neutral, angry, excited, frustrated, and in the experiment, 10% of the data randomly selected from the training data were used for tuning the hyperparameters The database is based on a random selection of 10% of the training data.
setting (of a computer or file, etc.)
AdamW is used for training. Unless otherwise mentioned, the number of Transformer Encoders NT, NA, and NV for Dialog Level are empirically set to 1 for MELD, 5 for IEMOCAP, and 5 for both MHAF layers m.
The feature extractor is trained on the mel-spectrogram for each dataset for the audio data mechanism and is pre-trained on the CASIA web face database for the video data. The coefficients λ1, λ2, and λ3 of the Triplet Loss are set to 20, 5, and 1 for both audio and video data, respectively.
valuation index
Accuracy and weighted average F1 Score for the estimated sentiment labels.
ablation
The ablation examines the contributions of multimodality, Transformer Encoder, and Fusion. First, the modalities. The table below shows the accuracy of the three modalities (Text, Visual, and Audio) when using only one, combining two, or combining three. In particular, the bottom one is not just a combination, but a combination using the Fusion Attention Module, which is part of the proposed method. As the table shows, the accuracy is better when all three modalities are used, and the accuracy is greatly improved by using the Fusion mechanism of the proposed method.

Next is the video feature. Since only the video features were based on a rather complex mechanism that uses both scene features and facial expression features, the ablation confirms the effectiveness of this Dual Network. As shown in the table, the proposed method has the highest accuracy in the comparison of three methods: scene features only, facial expression features, and the proposed method that combines both. The fact that each embedding by itself does not improve accuracy shows that both contextual information from the scene and facial expression features are important for emotion recognition.

The number of Transformer Encoders before Fusion is also verified in NA=NV=NT. As a result, it was found that the MELD and IEMOCAP have high accuracy when one and five layers are used, respectively.

The last step is to verify a few meters of the Fusion mechanism. Here we see that the accuracy is best when 5 layers are employed. Unless otherwise mentioned, these parameters are set at the highest accuracy during ablation.

Comparison with SoTA
The paper has M2FNet compared to text-based and multimodal SoTA models to demonstrate its superiority. First, the text-based model. It outperforms conventional methods on both datasets, with MELD outperforming conventional EmotionFlow by 0.21% and IEMOCAP outperforming conventional DAG-ERC by 1.83%. While many methods achieve high accuracy on IMOCAP but lower accuracy on MELD, the proposed method achieves high accuracy in both cases.

Next is the multimodal method, which achieved higher accuracy than conventional methods for both MELD and IEMOCAP. The improvement in accuracy of the MELD method is particularly remarkable.

The experiment showed that M2FNet successfully utilized the features of multimodality and improved the accuracy of emotion recognition.
impression
The paper was a good example of the superiority of this method, which fully utilizes the three modalities. I felt that in practical use, there is greater demand for text-based methods. For example, in the analysis of SNS and word-of-mouth, accuracy should be demanded only for text features. It seemed to me that there is only a limited amount of data where video, audio, and text are all available. Even so, as long as the data is available, the robustness of the method, which achieved high accuracy in the two benchmarks, is demonstrated, so I felt that this is a method with high expectations.
We look forward to the application of emotional recognition, which is unique to Sony, a company that claims to be creative.
summary
This time, we introduced M2FNet, which has achieved high accuracy in ERC for emotion recognition in conversation. To fully utilize the features of the three modalities of speech, text, and video provided in the ERC dataset, feature extraction for each modality of speech, feature extraction between utterances, and feature extraction between modalities are performed in stages. We showed that it is important to use not only facial expressions but also whole-scene features for video features. In our experiments, we compared text-based and multimodal methods and successfully achieved SoTA on both benchmarks. We look forward to future developments.



Categories related to this article

