FAS-SGTD, Which Improves The Accuracy Of Face Spoofing Detection By Learning The Spatio-temporal Information Of Depth
3 main points
✔️ Combining the Residual Spatial Gradient Block (RSGB) to characterize detailed spatial information and the Spatio-Temporal Propagation Module (STPM) to characterize its temporal variation, we propose a new framework that considers Spatio-temporal features including depth.
✔️ Introduced Contrastive Depth Loss (CDL) instead of Euclidean Distance Loss (EDL) to better learn detailed face spoofing patterns.
✔️ Achieved state-of-the-art performance on typical benchmarks.
Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing
written by Nilay Sanghvi, Sushant Kumar Singh, Akshay Agarwal, Mayank Vatsa, Richa Singh
(Submitted on 18 Mar 2020)
Comments: Accepted by CVPR2020
Subjects: Computer Vision and Pattern Recognition (cs.CV)
outline
While the adoption of facial recognition systems is increasing, the importance of spoofing detection is also rising.
There are three main types of identity theft: Print Attack, which uses a printed photo of a person's face; Replay Attack, which uses an image of a person's face displayed on an electronic device such as a smartphone; and 3D Mask Attack).
In this paper, we propose a new method to detect Print Attack and Replay Attack among the three spoofing methods with higher accuracy.
Research in the last few years has reported that using Depth information can improve the accuracy of spoofing detection. While a real face has unevenness, Print Attack and Replay Attack are displayed on paper or display with a flat surface, which does not have unevenness features, so using Depth information can detect spoofing with high accuracy.
In previous research, Depth is estimated by using spatial information from a single frame of video captured by a camera. However, in this paper, it is necessary to consider the temporal variation of spatial information from multiple frames in order to estimate depth accurately.
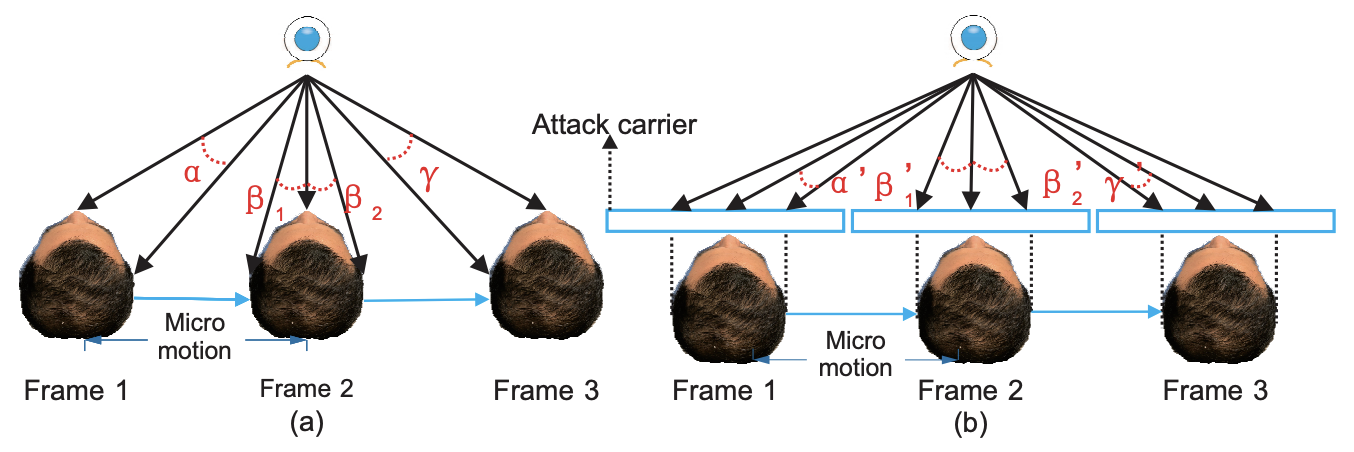
The figure below shows this explanation in an extreme but easy to understand way. (a) shows a real face being photographed and (b) shows Print Attack and Replay Attack being photographed.
Looking at (a), if the face moves to the right at each frame, the distance between the center of the nose and the ear changes. In this case, α > β2 should be true. However, in (b), if the face moves in the same way, the distance between the nose and the ear changes to α' < β'2.
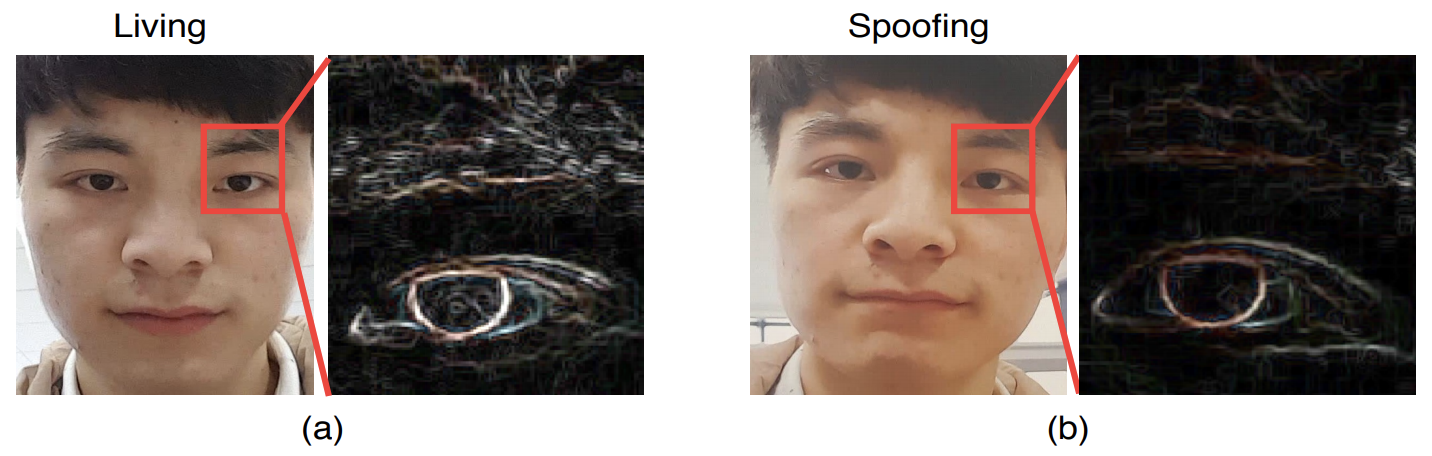
In order to obtain more detailed spatial information than before, we also use spatial gradients based on Sobel operations.
This is because there is a large difference in the spatial gradient in spoofing, as shown in the figure below.
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article






