Summary Of Image Caption Generation Techniques From Attention To GAN-based Methods
3 main points
✔️ Survey paper on image caption generation
✔️ Presents current techniques, datasets, benchmarks, and metrics
✔️ GAN-based model achieved the highest score
A Thorough Review on Recent Deep Learning Methodologies for Image Captioning
written by Ahmed Elhagry, Karima Kadaoui
(Submitted on 28 Jul 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
first of all
Image captions include such as automatic indexing of images. various uses. Human annotation is very costly. Therefore, there is an increasing demand for technologies that automatically generate captions. A lot of research has already been done in this area and survey papers have been published but none of them cover some important models of recent years. We present this paper to highlight some of the most relevant recently published papers, compare the performance of their models and explain how they work. Today, the use of attention is one of the most important techniques in image captioning: since the introduction of Transformer, many tasks such as machine translation and language modeling have achieved significant performance gains thanks to it. The same is true for image caption generation, which is used in a variety of models as presented in this paper. Another technique that has caught the attention of researchers is deep reinforcement learning. It is particularly well suited for unusual images such as "Bed in the Woods."
technique
Updown
The most common techniques using visual attention today are top-down (macro to micro). In these models, a partially completed caption is given at each time step to get context. However, there is a problem regarding which areas of the image to focus on. By trying to focus on salient, easily understandable objects, it is possible to generate captions as if they were created by a human.
Given these problems, we propose a model called "Up-down", which combines a visual bottom-up approach with a task-specific contextual top-down approach. The former gives suggestions about salient object regions, and the latter computes the distribution of attention for them using the context. As a result, it can direct attention to important objects in the input image.
We present an implementation of Up-down. The bottom-up part uses the object detection model of Faster R-CNN, which is enclosed by bounding boxes, initialized with Resnet-101, and pre-trained on the Visual Genome dataset. The top-down part uses visual attention LSTM and language attention LSTM, where the attention LSTM is given the output of the previous language LSTM, the words generated at time t-1, and the average pooled image features to determine which region to focus on. It then computes a conditional distribution over the output words using the captions generated up to that point, yielding a distribution over the captions.
OSCAR
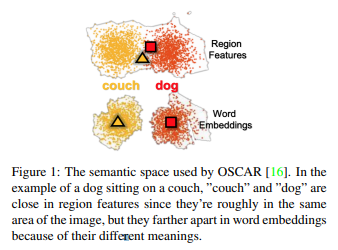
Vision-language pre-training (VLP) is widely used for learning cross-modal (image-language) representations. However, VLP has two problems: difficulty in discriminating words due to overlapping regions in each image and misalignment between words and their corresponding image regions. OSCAR is proposed here, which solves these problems by using object tags as "anchor points". It uses three types of input: image features, object tags, and word sequences (captions). This allows us to supplement the information with other information if one of them is incomplete or noisy.
We present an implementation of OSCAR, which uses Faster R-CNN to detect object tags and obtains two
- Linguistic semantic space contains tokens of tags and captions and visual semantic space contains image regions (Figure 1)
- Image modality including image features and tags and language modality including caption tokens
VIVO
In the nocaps challenge, only MS COCO is allowed as a dataset for image caption generation, so the VLP method is not applicable. Therefore, we devise VIVO (VIsual VOcabulary pre-training) here. This is a joint embedding space of tags and image regions and defines a "visual vocabulary" such that vectors of semantically close objects (e.g., an accordion and an instrument) are nearby (Figure 2).
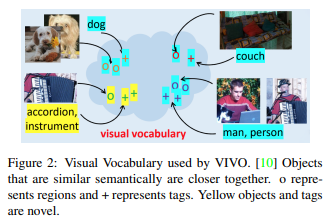
After pre-training the vocabulary, the MS COCO dataset is used for fine-tuning the model on image-caption pairs; the difference between VIVO and other VLP models is that VIVO is pre-trained on image-tag pairs and does not use the caption dataset until fine-tuning is done. until fine-tuning is performed. Tags are more likely to be generated automatically than captions, thus reducing the cost of annotation. In addition, they are very useful because of the huge number of tags that can be used.
This section introduces the implementation of VIVO. A multi-layer Transformer is used to align tags with their corresponding image regions. Then we use linear layers and softmax. In the pre-training, an up-down object detection model is used to extract image regions from the input image and input them to the Transformer along with a set of image-tag pairs. The model makes predictions on the other masked tags and image regions. fine-tuning, as introduced earlier, takes three inputs: image regions, tags, and captions, and learns that some of the caption tokens are masked and the model will predict them.
Meta Learning
One of the drawbacks of reinforcement learning is overfitting the reward function, where the agent finds ways to maximize the score without generating better quality captions. For example, when using the CIDEr optimization, captions that are too short are punished. So when short captions are generated, redundant phrases are added to make them longer, resulting in unnatural sentence endings such as "a little girl holding a cat in a." Here we introduce meta-learning, which can optimize and adapt to several different tasks. With this method, the model optimizes the reward function (the task of reinforcement learning) and performs supervised learning in both directions simultaneously. This results in human-like captions.
This section introduces the implementation of Meta Learning. We use the up-down architecture established above. The tasks that this model optimizes this time are the reinforcement learning task and the maximum likelihood estimation task of supervised learning. We will use a self-updating method called "meta update" for the parameter θ. In this way, we can learn the parameter θ that optimizes the two tasks.
Conditional GAN-Based Model
In contrast to the overfitting of the reward function, which was a problem in Meta Learning, this method uses a discriminator to determine whether the caption is generated by a human or a machine (model). We call it IC-GAN (Image Captioning GAN) because the original paper did not give a name to the method.
We introduce the implementation. We experiment with two types of discriminator architectures: a CNN with all coupling layers and a sigmoid function, an RNN (LSTM) with all coupling layers, and a softmax function. We also experiment with an ensemble of four CNNs and RNNs, respectively. In our method, we consider the caption generation as a generator. We have experimented with several architectures for the generators, but in this article, we focus on the results obtained using the up-down architecture. In all cases, both generators and discriminators need to be pre-trained before fine-tuning.
valuation index
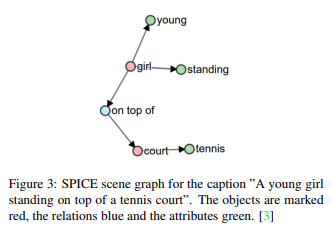
Several metrics are used to compare the generated captions with the teacher data. The most commonly used are CIDEr, SPICE, BLEU, and METEOR. CIDEr is an image classification metric that uses TF-IDF to measure the degree of agreement with humans, while SPICE is a graph-based semantic representation of scene graphs (Figure 3). It is an evaluation index for captioning based on a novel semantic concept.
Benchmark
nocaps uses the Microsoft COCO Caption dataset, but also the OpenImages object detection dataset to introduce new objects not seen in the former. nocaps uses the OpenImages OSCAR and VIVO are evaluated on the nocaps validation set. Karpathy splits are used to evaluate Meta Learning and IC-GAN. Finally, Up-down is evaluated on both benchmarks.
result
MS COCO Karpathy Splits Benchmark
The methodology and corresponding evaluation indicators are in Table 1.
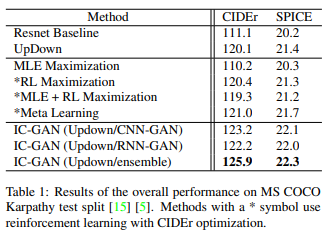
We experiment with Resnet as a comparative baseline model for the UpDown method: we observe that UpDown improves performance on both CIDEr and SPICE. The results show that adding bottom-up attention has a positive impact on the image caption generation task. Comparing the model with meta-learning to maximization by maximum likelihood estimation, reinforcement learning, and the situation where the gradients of MLE and reinforcement learning are simply added, we obtain the highest index for both metrics. It also performs slightly better than the UpDown method, which does not use meta-learning. On the other hand, IC-GAN performs significantly better than the other methods for all three models. Note that CNN-GAN scores better than RNN-GAN, but RNN-GAN has a shorter training time. IC-GAN also avoids word overlaps and logical breakdowns such as "a group of people standing on top of a clock" seen in traditional reinforcement learning methods and produces more human-like captions.
nocaps Benchmark
OSCAR outperforms the UpDown method in all subsets of in-domain, near-domain, and out-of-domain. Furthermore, the addition of Constrained Beam Search (CBS) and Self Critical Sequential Training (SCST) dramatically improves the performance. This is especially true for out-of-domain. However, VIVO performs better than OSCAR: VIVO+SCST+CBS outperforms human captioning in the in-domain and near-domain CIDEr scores.
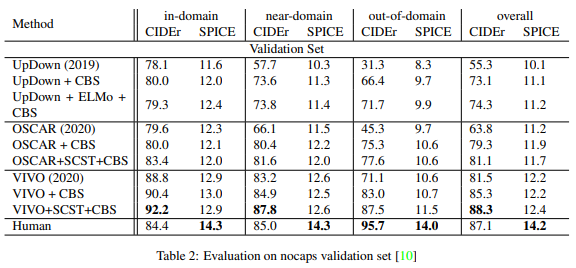
summary
Our current research on image caption generation is heavily focused on deep learning. This is because this task combines both computer vision and natural language processing and is very complex, and thus requires a "power" technique that can handle that level of complexity. Faster R-CNN is a popular architecture along with LSTM, and in particular, the UpDown model has been used as a basis for recent papers.
In this paper, we have presented state-of-the-art methods and their implementations. Among the presented UpDown, OSCAR, VIVO, Meta Learning, and GAN-based methods, we found that GAN based method has the best performance, UpDown has more impact and OSCAR and VIVO are more useful.
reference text dedication
*Only papers related to the technology introduced in this article
[1] P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson,S. Gould, and L. Zhang. Bottom-up and top-down attention for image captioning and VQA. CoRR, abs/1707.07998,2017.
[2]X. Li, X. Yin, C. Li, P. Zhang, X. Hu, L. Zhang, L. Wang, H. Hu, L. Dong, F. Wei, et al. Oscar: Object-semanticsaligned pre-training for vision-language tasks. In EuropeanConference on Computer Vision, pages 121–137. Springer,2020.
[3]H. Agrawal, K. Desai, Y. Wang, X. Chen, R. Jain, M.Johnson, D. Batra, D. Parikh, S. Lee, and P. Anderson. nocaps: novel object captioning at scale. CoRR, abs/1812.08658,2018.
[4]X. Hu, X. Yin, K. Lin, L. Wang, L. Zhang, J. Gao, and Z. Liu.Vivo: Visual vocabulary pre-training for novel object captioning, 2021.
[5]N. Li, Z. Chen, and S. Liu. Meta learning for image captioning. Proceedings of the AAAI Conference on ArtificialIntelligence, 33:8626–8633, 2019.
[6]C. Chen, S. Mu, W. Xiao, Z. Ye, L. Wu, and Q. Ju. Improving image captioning with conditional generative adversarialnets. Proceedings of the AAAI Conference on Artificial Intelligence, 33:8142–8150, 2019.



Categories related to this article


