What Is BioMetricNet, A New Face Recognition Algorithm That Does Not Require Relationships Between Facial Features?
3 main points
✔️ Proposed a new algorithm "BioMetricNet" that does not require predetermination of relationships between features such as Euclidean and angular distances
✔️ Instead, learning so that matching and non-matching follow their respective distributions, which are predetermined
✔️ Consistently higher accuracy reported than methods that achieve high accuracy in face recognition (CosFace, ArcFace, SphereFace)
The Effect of Wearing a Mask on Face Recognition Performance: an Exploratory Study
written by Arslan Ali, Matteo Testa, Tiziano Bianchi, Enrico Magli
(Submitted on 13 Aug 2020)
Comments: Accepted at ECCV2020
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
History of Facial Recognition Algorithms
Over the last five years or so, deep learning has made great strides in a variety of fields. In particular Convolutional neural networks (CNNs) have made significant contributions to the field of image recognition. Face recognition, which we present here, is one of them.
In this face recognition, the accuracy of face recognition was improved in 2014/2015 by methods that use CNN-trained features such as DeepFace and DeepID reported by Facebook and others. These models employ a distance, such as the L2 norm, as an index for discrimination between facial features to identify faces. The mechanism is that if the distance between features is less than or equal to the threshold, the two faces are classified as belonging to the same person, otherwise they are classified as belonging to different people.
Softmaxcross-entropy is often used as a loss function to compute the features. Maximizing the variance between classes and minimizing the variance within classes has been shown to improve discrimination.
Later, in 2015, Google reported FaceNet. By introducing a loss function called Triplet Loss, we evaluate the distance between features as a relative value instead of an absolute value. In this model, we introduce Anchor as a criterion for identification and Anchor and It learns to minimize the distance for Positive, which has high similarity, and to maximize the distance for Negative, which has low similarity.
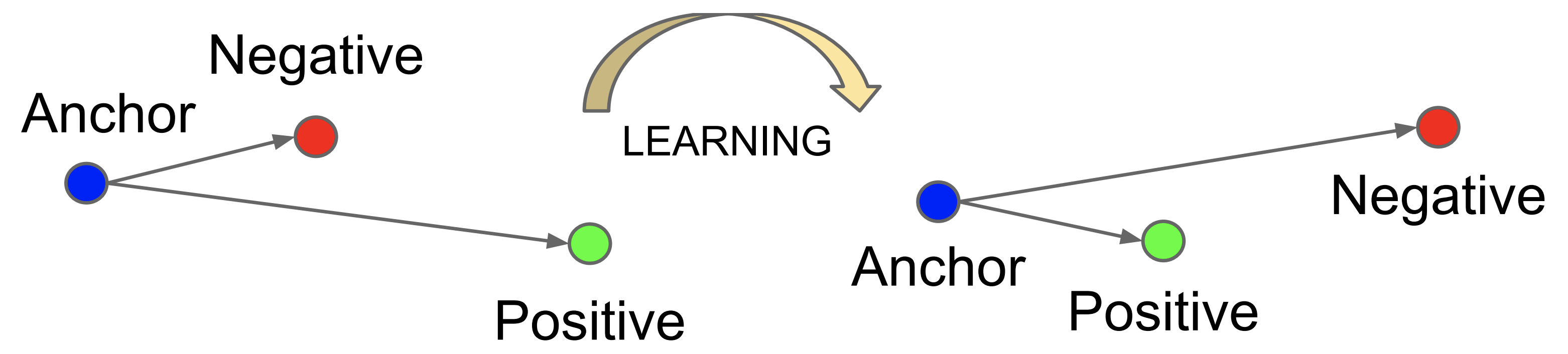
However, while they can be effective, they tend to be more complex to learn. Subsequently, new algorithms that use angles instead of distances, such as the L2 norm, have been proposed.
Around 2017, a model called Sphereface was reported, proposing a way to reduce the number of False Positives by using angular distance to increase the margin between negative features.
The algorithm we have mentioned so far uses a predefined metric (distance/angle) to map the relationship between two features in space, and designs and trains the loss function to minimize the distance between features with high similarity while maximizing the distance between features with low similarity. The choice of which metric is chosen is important in the design of the model. In the above model, we have found that using angular distances rather than Euclidean distances significantly improves the performance of the model. Nowadays, the models Arcface and Cosface are well known for their high accuracy. In this paper, we propose these different methods. We do not predefine the indicators of mapping between features as in the above algorithm. The only thing we define a priori in this paper is how we want the output values from the model to behave depending on whether the features are matched or non-matching pairs.Specifically, we normalize the model's output values to follow two different statistical distributions for matching and non-matching pairs. In other words, not only do we learn the features with high discriminative power, but we also learn the mapping indices at the same time so that matching pairs with high similarity are mapped to one distribution and non-matching pairs with low similarity are mapped to another distribution.
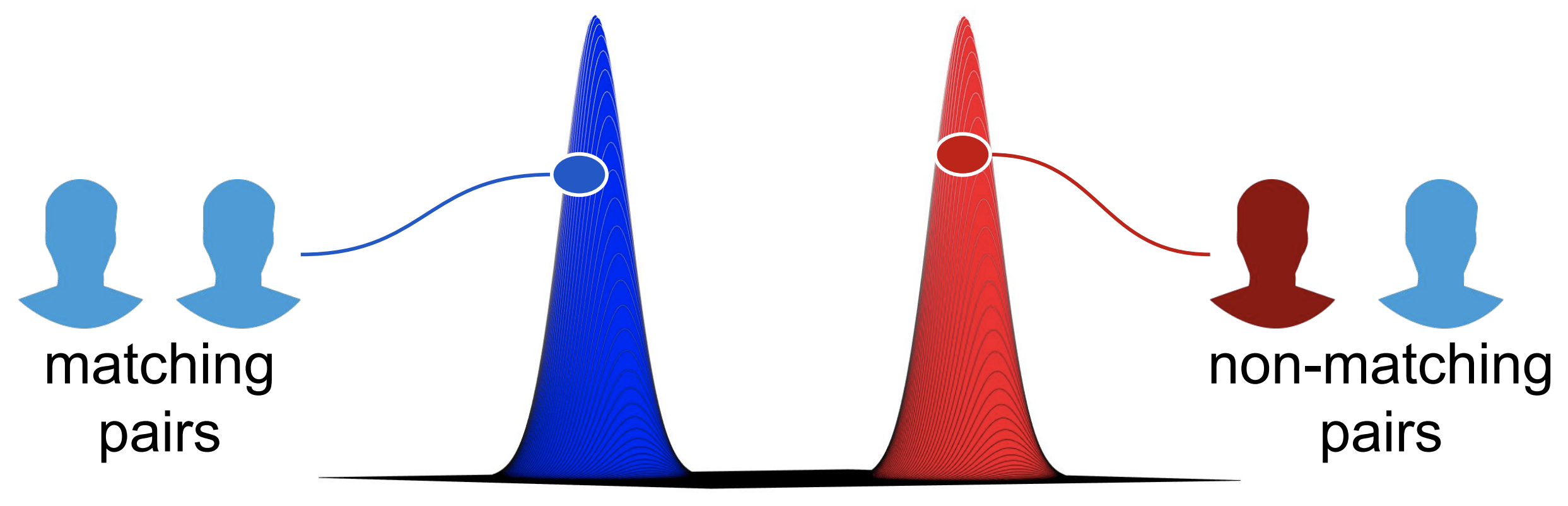
With the proposed method, BioMetricNet, the distribution of the output values is known and the thresholds can be easily adjusted so that the FAR (False Acceptance Rate) and TAR (True Acceptance Rate) of the model are ideal. It also shows higher accuracy than traditional models, even for very difficult data sets, as discussed below. Although this paper applies BioMetricNet to facial recognition, the paper states that the method is generic and can be applied to other biometric information and data types as well.
What is BioMetricNet?
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article


![[Swin Transformer] T](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



