
LATM Generates And Executes Extension Tools Using LLM
3 main points
✔️ While LLMs are being combined with external tools to extend their capabilities, we aim to extend them more broadly and flexibly by having LLMs themselves generate these tools.
✔️ LATMs have parts for tool generation, tool use, tool selection, and tool while tool generation and tool use can be powerful tools, they also raise deeper ethical, safety, and control concerns.
✔️It is hoped that appropriate steps will be taken to expand its use.
Large Language Models as Tool Makers
written by Tianle Cai, Xuezhi Wang, Tengyu Ma, Xinyun Chen, Denny Zhou
(Submitted on 26 May 2023)
Comments: Code available at this https URL
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (stat.ML)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Summary
Recent research has shown the potential to improve the problem-solving capabilities of large-scale language models (LLMs) through the use of external tools. However, prior research in this area has been limited to the availability of existing tools. This study takes a first step toward removing this limitation by proposing a closed-loop framework, called LLMs As Tool Makers (LATM), in which LLMs create their reusable tools for problem-solving. The authors' approach consists of two key phases:
1) Tool creation: LLM acts as a toolmaker to create tools for a given task (tools are implemented as Python utility functions).
2) Tool Use: The LLM acts as a tool user who applies the tools created by the tool maker to solve the problem. A tool user can be the same LLM as the tool maker or a different LLM.
Tool creation allows LLMs to continuously generate tools applicable to different requirements and to invoke the corresponding API when future requirements are beneficial for task resolution. Furthermore, the division of labor between LLMs in the tool creation tool use phases introduces opportunities to achieve cost-effectiveness without degrading the quality of the generated tools and problem solutions. For example, recognizing that tool creation requires a higher level of competence than tool use, powerful but resource-intensive models can be applied to tool creators and lightweight but cost-effective models to tool users. The authors have tested the effectiveness of this approach on a variety of complex inference tasks, including Big-Bench tasks: with GPT-4 as the tool maker and GPT-3.5 as the tool user, LATM achieved performance comparable to using GPT-4 for both the tool maker and tool user and inference costs were significantly reduced.
[Author's Note: If you check the code on github, you will see that it is very small. The framework proposed here uses existing LLMs such as GPT-4 to achieve more powerful capabilities. It seems to be a broader and more flexible way to perform tasks than the prompt engineering that has been proposed by many. it may be one of the breakthrough proposals that will also lead to AGI. If subjected to an easy-to-use UI, it is expected to have an even wider range of applications than existing LLMs in general.
Introduction.
Large-scale language models (LLMs) have demonstrated excellent capabilities in a wide range of NLP tasks and even show signs of being able to achieve certain aspects of artificial general intelligence (AGI). Furthermore, the potential for augmenting LLMs with external tools, thereby significantly improving their problem-solving ability and efficiency, has been identified. However, the applicability of how to use these tools depends largely on the availability of the right tools. According to lessons learned from human evolutionary milestones, an important turning point was the acquisition by humans of the ability to fabricate their tools to address emerging challenges.
The present study is an initial study of applying this evolutionary concept to the domain of LLMs. The authors propose a closed-loop framework, which they call LLMs As Tool Makers (LATM), that allows LLMs to generate their reusable tools to tackle new tasks. This approach consists of two main phases:
1) Tool creation: LLMs, called toolmakers, design tools (implemented as Python functions) specific to a given task
2) Use of a tool: another LLM, called a tool user (sometimes the same as a tool maker), applies the tool to process the new request
This two-stage design allows LATM to assign jobs in each stage to the most appropriate LLM. Specifically, tool fabrication processes that require advanced capabilities can be assigned to resource-intensive but powerful models (e.g., GPT-4). On the other hand, relatively simple tool-use processes can be assigned to lighter, more cost-effective models (e.g., GPT-3.5 Turbo). This approach not only increases the problem-solving capability of the LLM but can also significantly reduce the average computational cost of addressing a set of tasks.
Since the tool creation process needs to be executed only once for a given function, the created tools can be reused in different task instances. This approach paves the way to a scalable and cost-effective solution for handling complex tasks. For example, consider the task of a user asking an LLM to schedule a meeting that is convenient for everyone (e.g., via email conversation); lightweight models such as GPT-3.5 Turbo often struggle with such tasks, which involve complex arithmetic reasoning. On the other hand, morcanmodels (such as GPT-4) can find the correct solution, even though the inference cost is much higher; LATM overcomes these hurdles by employing powerful but expensive models as toolmakers, which are then used as tool users to cost-effectively pass the model on for subsequent use. Once the tool is created, the lightweight tool user can use it to solve tasks efficiently with high performance. This paradigm can be equally applicable to repetitive tasks in a variety of workflows, such as parsing a web document into a specific data format, formulating a routing plan that meets some custom requirements, or using it to solve popular games such as Sudoku, a game of 24.
In addition, another lightweight LLM, the dispatcher, was introduced to determine if the input problem can be solved with existing tools or if a new tool needs to be created. This dispatcher adds dynamism to the framework and allows for real-time, on-the-fly tool creation and utilization.
The authors' experiments have tested the effectiveness of this approach on a variety of complex inference tasks, including several challenging Big-Bench tasks. The results show that LATM is more cost-effective while achieving performance comparable to larger models. This novel approach to LLM, which mimics human evolutionary leaps in tool creation and use, opens the possibility for communities to grow through stimulation with LLM-generated tools.
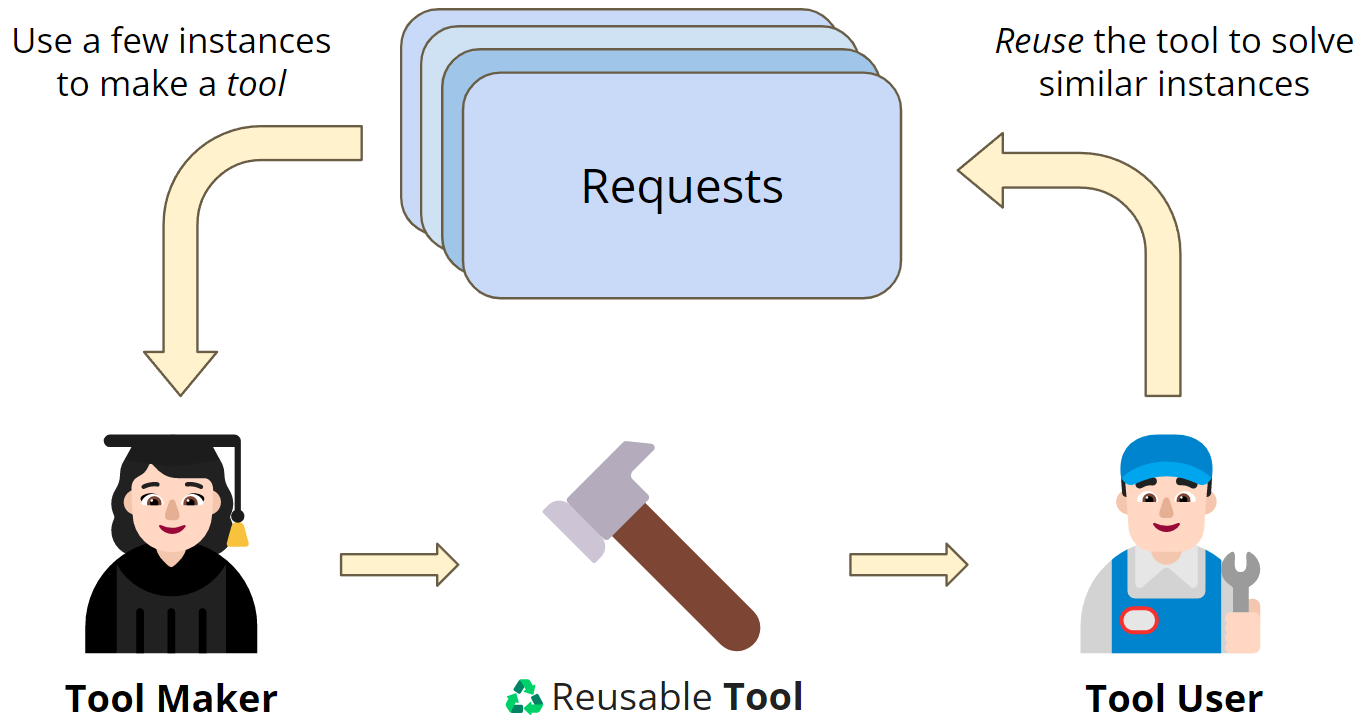
| Figure 1 LATM's closed-loop framework In situations with a large number of problem-solving requests, directly utilizing a powerful LLM to solve all instances can be expensive. On the other hand, lightweight models are cost-effective, but usually cannot handle complex tasks; LATM leverages the strengths of both models, with the powerful model as the toolmaker, generating reusable tools (implemented as Python functions) for the tasks observed in a request, and then using the next request to pass the tool to a cost-effective tool-user model to solve similar instances. With this approach, lightweight models can achieve performance comparable to strong models while maintaining higher cost efficiency. |
Related Research
Chain of Thought (CoT )
In recent years, significant progress has been made in enhancing the problem-solving capabilities of large-scale language models (LLMs) for complex tasks. For example, CoT prompts have been proposed to enhance the reasoning capabilities of LLMs and have shown improved performance across a variety of reasoning and natural language processing tasks. CoT prompts are typically expressed through natural language, but can also be effectively expressed using programming languages. More recently, there have been proposals to use LLMs to generate structured views on documents, balancing quality and cost by ensembling extractions from multiple composite functions; LATMs follow suit, focusing on more general use cases while managing the trade-off between cost and quality. LATM follows suit, focusing on more general use cases while managing the tradeoff between cost and quality.
Extend the language model with tools
Recent studies have explored the possibility of using external tools to complement the LLM's capabilities for complex tasks; Yao et al. and Yang et al. proposed augmenting the inference trace with task-specific actions in the LLM, allowing the model to reason and act synergistically. Various studies have shown that supplementing the LLM with tools such as calculators, search engines, translation systems, calendars, or API calls to other models can solve tasks that cannot be easily addressed by the LLM alone. the LATM uses a Python executable to perform other reusable tools to address task instances. Furthermore, by separating tool creators from tool users, lightweight models can be used for most inferences, increasing the efficiency and cost-effectiveness of LATM.
Adaptive Generation in Language Models
In addition, recent research has proposed ways to adaptively control LLM decoding to improve text generation efficiency. Speculative Decoding is based on the concept of speeding up the generation of text tokens with faster but lower-performing models while using the generated tokens' LATM improves both the performance and efficiency of the LLM solving the task by transferring the newly generated tools between models instead of changing the decoding procedure.
Cascading language models
Recently, it was shown that LLMs allow for iterative interactions and that their capabilities can be further extended by combining multiple LLMs. Chen et al. also demonstrated that identifying the optimal combination of LLMs can reduce costs while improving accuracy; rather than simply cascading LLMs, LATMs use new tools generated by a larger model to better address task categories and assign individual inferences within those task categories to smaller models.
LLM as a tool manufacturer (LATM)
Create new tools and reuse them
In the LATM paradigm, the main process can be divided into two phases: tool creation and tool use. Each phase utilizes different types of large-scale language models (LLMs) to balance performance and cost-effectiveness.
Tool Creation
- Tool Proposal: In this phase, the toolmaker attempts to generate a Python function to solve a demonstration from a given task. This process provides some concrete demonstrations and writes a program in which the model produces the demonstrated behavior.
- Tool validation: Unit tests are generated using validation samples and run on the proposed tool. If any of these tests fail, the toolmaker records the error in its history and attempts to correct the problem within the unit test; the self-debugging capabilities of LLM have been effectively demonstrated in recent studies. Within the LATM pipeline, however, the verification stage is used a little differently.
1) Provide an example showing how to convert a natural language question into a function call
2) Verify the reliability of the tool and ensure that the entire process can be fully automated
It is.
- Tool Packaging A tool creation stage is considered failed if execution or validation fails beyond a predefined threshold. Otherwise, the tool maker is ready to package the tool for the tool user. In this stage, the function code is packaged to provide a demonstration of how to convert a task into a function call. These demonstrations are extracted from the tool validation step of converting questions into unit tests. This final product will be available to tool users. An example of word sorting is cited below.
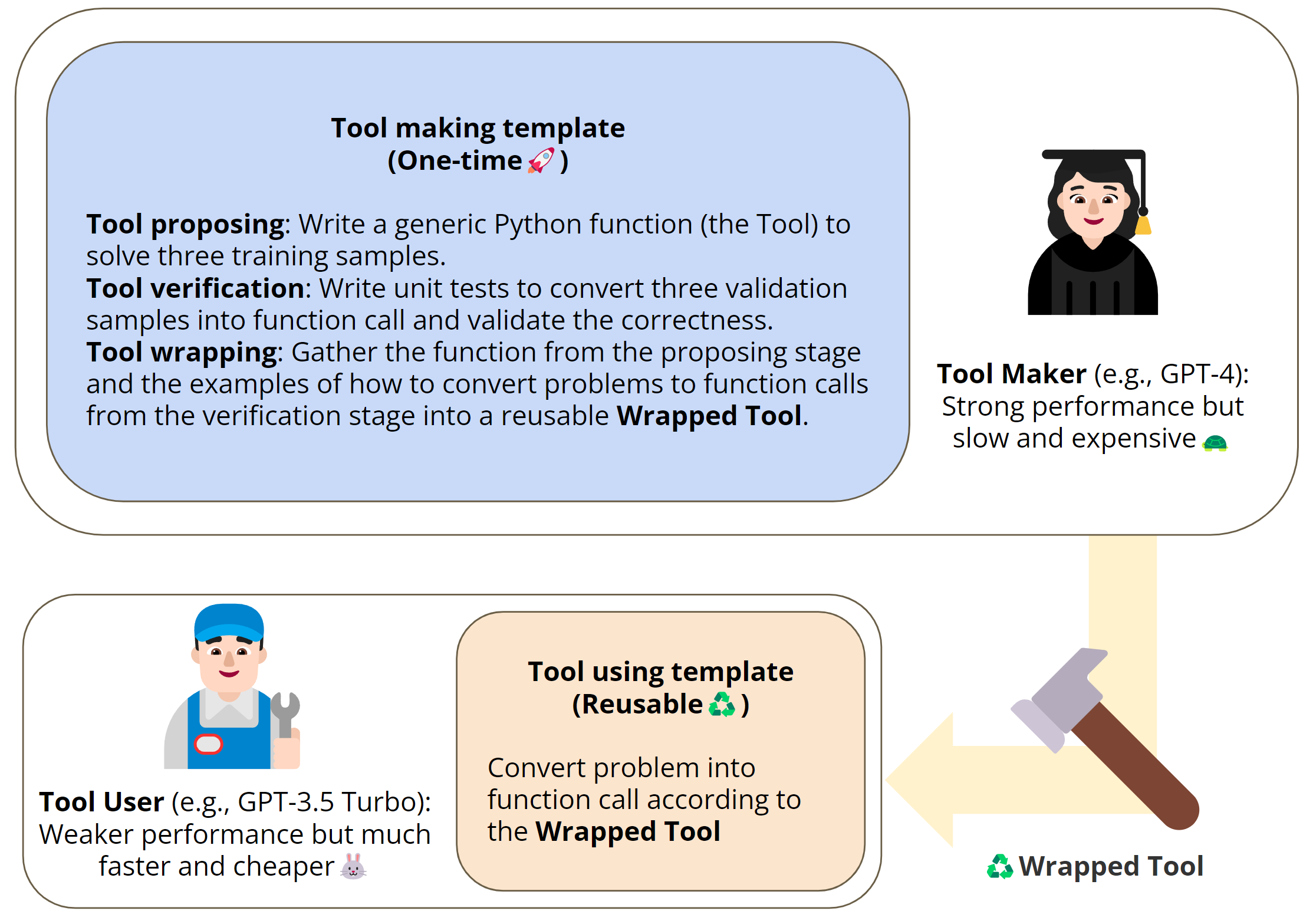
| Figure 2 LATM Pipeline LATM can be divided into two stages: 1) tool creation: a powerful but expensive model serves as a tool maker that generates generic and reusable tools from several demonstrations; 2) tool use: a loose weight and inexpensive model serves as a tool used that generates generic and reusable tools from a task Act as a tool user that uses the tool to solve various instances of. (i) Tool proposal: the toolmaker attempts to generate a tool (Python function) from some training demo, and if the tool fails to run, reports an error and generates a new one (to fix the problem with the function); (ii) Tool validation: the toolmaker performs a validation test on a sample of unit test and if the tool does not pass the test, report an error and generate a new test (fix the function call problem in the unit test); (iii) Tool packaging: packaging the function code and a demonstration of how to convert a question from a unit test to a function call, the tool user Prepare the tool for use by the tool user. |

Tool Use
In this second phase, a lightweight, cost-effective model such as the GPT-3.5 Turbo assumes the role of the tool user. The role of the tool user is to use the validated tool to solve a variety of tasks. This phase involves the use of a packaging tool that includes a function to solve the task and a demonstration showing how to convert the task query into a function call. This demonstration allows the tool used to generate the necessary function calls in an in-context learning fashion. The function call is then executed and the task is resolved. Optionally, post-processing can be performed to transform the output to match the required format of the task (e.g., choices in a multiple-choice question).
The tool creation phase, which includes tool proposal, validation, and packaging, only needs to be performed once for each type of task. The resulting tool can then be reused for all instances of that task. This makes LATM significantly more efficient and cost-effective than using only powerful models. In addition, the Python function tool is a more general form than the Chain-of-Thought one and can be used to solve problems that involve algorithmic reasoning capabilities, increasing the overall utility and flexibility of the LLM.
To illustrate this method, Figure 3 shows a concrete example of how a toolmaker solves the logical reasoning task of BigBench by creating a tool (Python function), and how a tool user uses the tool. The task requires the user to reason about the order of five objects and answer a question. The requirements include both the relative positions of certain object pairs and the absolute positions of some objects, as shown in the "Toolmaker Input" block in Figure 3. To solve this task, the toolmaker (e.g., GPT-4) generates a generic program that solves the task by extracting constraints from the question and searching all permutations against the results. Tool users (e.g., GPT-3.5 Turbo) can use this program to solve the task with a function call that simply extracts the relevant information from the natural language instance of the task.
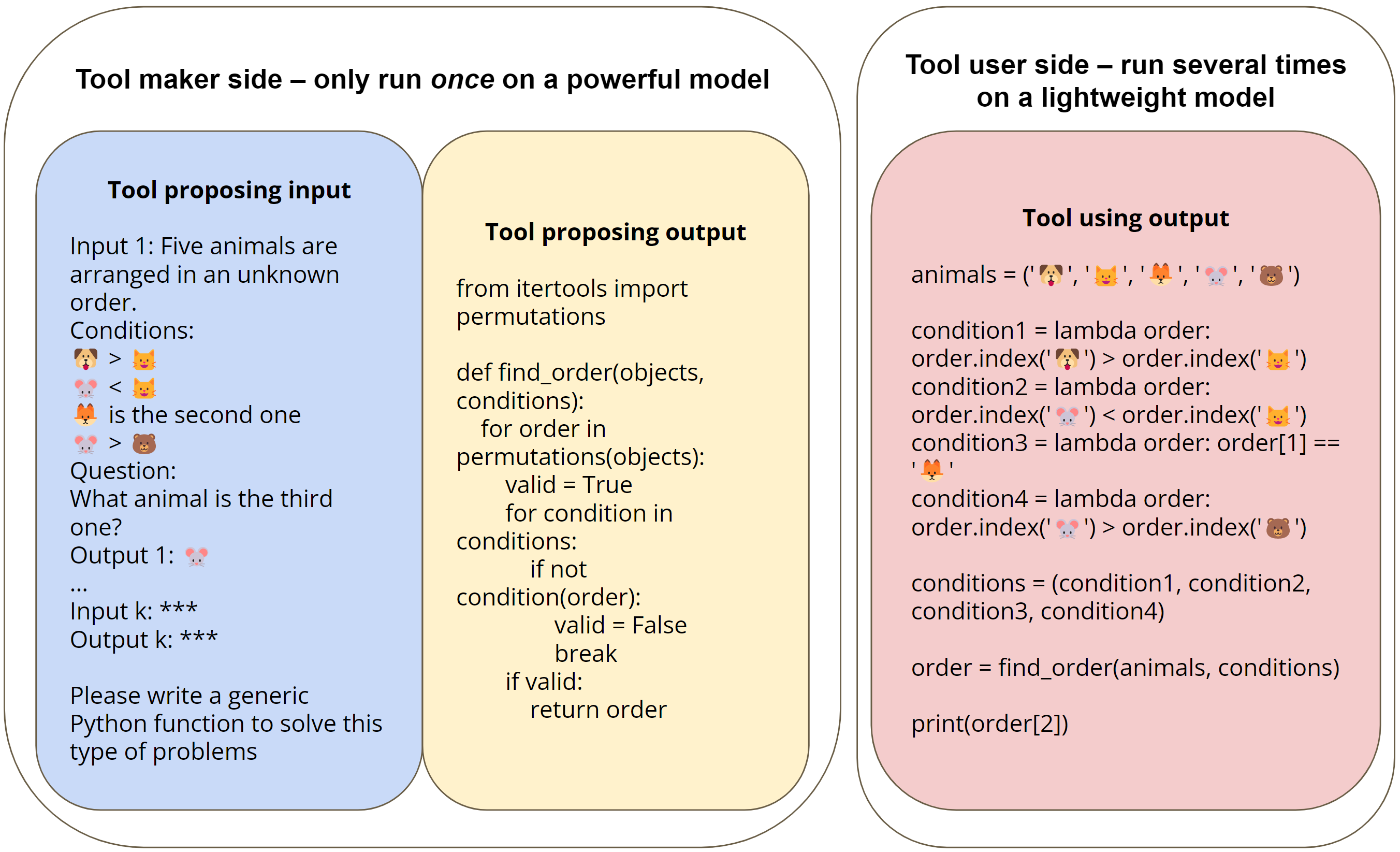
| Figure 3 Illustration of the tool proposal and tool use stages of the LATM pipeline for the logical reasoning task [Srivastava et al, 2022] The task requires determining the order of the five objects based on some given conditions. In the tool proposal stage, a toolmaker (e.g., GPT-4) formulates a generic Python function that can solve k demonstrations provided by the task (k=3 in the authors' experiments). The toolmaker generates a search algorithm that enumerates all possible sequences and verifies each against the provided conditions. In the tool use phase, the tool user translates each natural language question into a set of conditions and generates function calls to use the tool for each task instance. |
Handling streaming data with Dispatcher
In real-world scenarios, task instances typically arrive in sequence. To accommodate this data flow, the authors introduce a third LLM, the dispatcher, which determines whether to engage the tool user or the tool maker for each arriving task. This module is similar to the tool selection function in existing studies. However, the authors' dispatcher is unique in its ability to identify new tasks that cannot be addressed by existing tools and to engage toolmakers to generate new tools for these tasks.
Specifically, the dispatcher maintains a record of existing tools produced by toolmakers. When a new task instance is received, the dispatcher first determines whether a suitable tool exists for the task at hand. If a suitable tool exists, the dispatcher passes the instance and its corresponding tool to the tool used for task resolution. If no suitable tool is found, the dispatcher identifies the instance as a new task and either resolve the instance with a strong model or calls a human labeler. Instances from the new task are cached until enough cached instances are available for the toolmaker to create a new tool. The dispatcher workflow is illustrated in Figure 4. Given the simplicity of the dispatcher's task, the dispatcher can be a lightweight model with appropriate prompts, adding only a small cost to the overall pipeline. an example of an LATM prompt is shown. the dispatcher can be a lightweight model with appropriate prompts, adding only a small cost to the overall pipeline.

| Figure 4 Illustration of the dispatcher In an online environment where task instances arrive sequentially, the dispatcher, a lightweight model, evaluates each example as it comes. If a suitable tool already exists to tackle the task, the dispatcher selects this tool and forwards the task instance to the tool used for resolution. If no suitable tool is found, the dispatcher forwards the task instance to the toolmaker to create a new tool for later use by the tool user. |



experiment
setting (of a computer or file, etc.)
data-set
We evaluate LATM on six datasets from domains as diverse as Logical Deduction, Tracking Shuffled Objects, Dyck Language, Word Sorting, Chinese Residual Theorem, and Meeting Scheduling. The first five datasets were provided by BigBench; we use the 5-object version of the Logical Deduction and Tracking Shuffled Objects tasks and refer to them in the paper as Logical Deduction (5) and Tracking Shuffled Objects (5). We also constructed the Scheduling Meeting task to demonstrate the effectiveness of LATM in real-world scenarios.

| Table 1 Utility functions generated by toolmakers to solve problems. |
Model Setting
In the tool creation phase, the Temperature was set to 0.3 to introduce randomness into the generation process, allowing for retries as needed. In this phase, we experimented with the ChatCompletion API using the GPT-4 and GPT-3.5 Turbo models to provide an interactive experience by constantly appending responses to the chat history. During the tool use phase, only one call to the LLM API is made, and ablation studies are also conducted using GPT-3 type models with the standard Completion API. When using the tool, Temperature is unified to 0.0. In the tool proposal and tool validation phases, the maximum number of retries was set to 3.
Effects of the tool-making stage
The tool creation phase uses a powerful, slow model to generate generic Python functions tailored to specific tasks. This step is performed only once for each task, and the overhead is amortized across all instances of that task. In this experiment, we use GPT-4 as a representative toolmaker, yet we also investigate toolmaker functions for other models. As shown in Figure 3, we induce the language model to generate a generic Python program and provide a few exemplars of a few shots.
When GPT-4 was used as the toolmaker, it was observed that it frequently devised algorithms suitable for solving the task. For example, as shown in Table 1, the toolmaker creates code to solve the logical deduction task by searching all permutations and selecting the correct one that satisfies the given constraints.
LATM improves the performance of lightweight LLMs
Table 2 compares the performance of Chain-of-Thought prompting and LATM, employing GPT-4 as the toolmaker to generate the tools for the six tasks and evaluating the performance of both GPT-3.5 Turbo and GPT-4 as tool users. The results demonstrate that with the help of the tools, a lightweight model such as the GPT-3.5 Turbo achieves performance comparable to the GPT-4 and significantly outperforms the CoT prompt. Furthermore, the average cost of using GPT-3.5 Turbo with the tool is much lower than using GPT-4. This demonstrates that LATM improves the performance of lightweight models and is more cost-effective than employing more expensive models. Interestingly, for Dyck language tasks, GPT-3.5 Turbo as a tool user even outperforms GPT-4. Investigating the failure cases, we found that when converting questions to function calls, GPT-4 sometimes unnecessarily solves part of the problem and produces incorrect function output.

| Table 2 Comparison of LATM and Chain-of-Thought (CoT) Performance For LATM, GPT-3.5 Turbo and GPT-4 used the tool created by GPT-4. The results showed that applying LATM significantly improved the performance of GPT-3.5 Turbo, often outperforming or matching the performance of GPT-4, which used CoT, in certain scenarios. The last column shows the overall cost of processing n samples. where C represents the cost of one call to GPT-4 and c represents the cost of one call to GPT-3.5 Turbo. A few-shot CoT demonstration of the first four tasks was provided by Suzgun et al. and the last two tasks were applied directly with a few-shot prompt without CoT. |

| Table 2 Success rates for generating new tools (Python functions that passed the tool validation step) during the tool creation phase with GPT-4 v.s. GPT-3.5 Turbo 5 trials for each model for each task, n/5 means n trajectories to generate a valid tool out of 5 successful attempts. For difficult tasks such as logical deduction and tracking shuffled objects, GPT-3.5 Turbo failed on every attempt, indicating the need to use a more powerful model as a toolmaker. |
Extend LATM to mixed-task streaming environments
LATM can be extended to a streaming setup where instances from (potentially) different tasks arrive on the fly. In this case, another model, the dispatcher, is needed to determine the task to which the instance belongs; GPT-3.5 Turbo is used as the dispatcher to evaluate its capabilities:
1) Identify existing tools to resolve the instances entered
2) Request tool creation for instance from the unknown task
Identification of existing tools
We first evaluate the dispatcher's ability to identify existing tools for a given instance by randomly mixing six tasks to generate a test set with 100 samples. For each instance in the test set, a prompt with an example task associated with an existing tool is used to identify the appropriate existing tool in the dispatcher. If the tool is correctly identified, it is considered successful. For five random configurations of the test set, the accuracy in determining the correct tool was 94% ± 2%.
Request a tool production
Next, we evaluate the dispatcher's ability to request tool creation for instances from unknown tasks. We randomly select four tasks as existing tasks for which tools have been prepared. Next, select four tasks for testing, two from unknown tasks and two from within existing tasks. create a test set with 100 samples. For each instance in the test set, use the dispatcher to determine if it is necessary to request tool creation or if it can be resolved with existing tools. The accuracy of making the correct request was 95% ± 4%.
The results show that the dispatcher can effectively identify existing tools and request tool creation for unknown tasks without significant performance loss. This suggests that LATM can smoothly scale to mixed-task streaming settings.
sectional analysis
Capacity required for language model to create tools
We investigated the capacity requirements of the language models used in the tool creation phase. In general, this phase is performed only once for each task, and we found that more powerful and expensive models better serve our purposes, as high accuracy is critical to effectively pass the tool to smaller models. Specifically, for difficult tasks such as logical deduction and shuffled object tracking, the GPT-3.5 Turbo failed on all five trails. And the main reason for failure is that the tool is not general enough and may only be used for training samples. On the other hand, we also found that for simple tasks, Toolmaker can be a lightweight language model. For simple tasks such as word sorting, GPT-3.5 Turbo can effortlessly generate programs that solve the task. Another limitation that can cause toolmaker failure is context length constraints. To increase the reliability of the tool creation phase, a full history is used at each step of the tool creation process, which also introduces a long context. In this case, a GPT-4 with a context length of 8192 is preferred.
Capacity required for tool use a language model
The capacity requirements of the models using the tool are investigated. The results are shown in Table 4, which confirms that the GPT-3.5 turbo has the best balance between performance and cost among all the models tested. For the older models of the GPT-3 series (ada, babbage, curie, and davinci), we found that the models before instruction tuning sometimes performed better than the models after instruction tuning. This suggests that for these models, the instruction tuning phase may have hurt the in-context learning ability, which is important during the tool-use phase.

| Table 4 Performance comparison of various tool user models using the same tools generated by GPT-4 All costs are based on rates at the time of writing. Of all the models, GPT-3.5 Turbo demonstrates the best trade-off between performance and cost, since GPT-3 was the model before instruction tuning and the model after instruction tuning was found to perform considerably worse during the tool-use phase. the pre-tuning model was selected. We speculate that this is because the instruction tuning phase impaired the in-context learning capability that is essential for the tool use phase. |
CoT as a tool is not useful
In addition to LATM, we are investigating whether reusing Chain-of-Thought (CoT) from larger to smaller models, similar to the LATM pipeline, can improve task performance. Specifically, the same large model (GPT-4) is used in the "CoT creation" phase, the zero-shot prompt "Let's think step by step." is used to elicit intermediate thinking steps, and the generated CoT is used in the same small tool use model (GPT-3.5 Turbo). We tested this on two tasks and report the results in Table 5. We observe that the CoT from the larger model performs as well as the human-written CoT or much worse than the LATM.

| Table 5 Accuracy when using CoTs generated by GPT-4 Performance is close to human-written CoTs, far inferior to LATM |
summary
Introducing LATM, a closed-loop framework that allows Large Language Models (LLMs) to create and use their tools for a wide variety of tasks The LATM approach is inspired by the human evolutionary progress of tool-making and employs two key stages The LATM approach is inspired by the human evolutionary progression of tool making and employs two key phases: "tool creation" and "tool use. This division of labor allows for the utilization of advanced LLM capabilities while significantly reducing computational costs. The authors' experiments have confirmed the effectiveness of LATM on a variety of complex tasks, demonstrating that this framework is more cost-effective while having performance comparable to resource-intensive models. They also showed that adding another dispatcher LLM would add flexibility to the framework, allowing tools to be created and used on the fly.
The evaluation process identified a significant lack of high-quality datasets that faithfully represent everyday human-computer interactions in raw natural language format, such as email and telephone meeting schedules and airline ticket reservations. The authors state that they hope that the creation of such datasets will stimulate a research community to foster the next generation of AI systems. Such systems will be able to generate and apply their tools and will be able to handle complex tasks more effectively. In the future, as in software development, toolmakers could improve existing tools to address new problems. Such adaptability could further facilitate the evolution of the AI ecosystem and unlock a wealth of opportunities.
This paper examines the possibility of enabling large-scale language models (LLMs) to create their tools, thereby allowing the ecosystem to develop more autonomously. While this research avenue is promising, it also raises important ethical, safety, and control considerations that need to be carefully addressed. One of the most significant impacts of the authors' study is the potential for LLMs to grow automatically and achieve unprecedented capabilities. This could significantly increase the range and complexity of tasks that LLMs can handle, potentially revolutionizing the areas of customer service, technical support, and even research and development. It could also lead to more efficient use of computing resources and less human intervention, especially for routine and repetitive tasks. However, this new autonomy of LLMs is also a double-edged sword: by giving LLMs the ability to develop their tools, it also creates a scenario in which the quality of the tools they develop may not always meet the standards and expectations set by human developers. Without appropriate safeguards, the LLM may produce suboptimal, erroneous, or potentially harmful solutions. Furthermore, as LLMs become more autonomous, the potential for loss of control increases. If these models become widely used without proper regulation, unintended consequences could arise and even lead to scenarios where humans lose control of AI systems.
This study does not address these control and safety issues in depth and thus has some limitations to the research here. The proposed framework, LLM As Tool Maker, while effective in the scenarios tested, is still in the early stages of development. It is crucial to note that the real-world performance and safety of the system may vary based on the complexity and nature of the task to which it is applied. Furthermore, the evaluation and verification of tools created by tool makers in a real-world setting is a challenge that needs to be addressed, according to the report.



Categories related to this article

![Libra] A New Multimo](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




