
Which LLM Is The Most Accurate In The Mental Health Care Domain: Mental-LLM: Leveraging Large Language Models For Mental Health Prediction Via Online Text Data
3 main points
✔️ A paper examining which LLMs are best suited for mental health care
✔️ Suggests that the GPT series may have sufficient mental health care knowledge in its knowledge space due to prompt ingenuity
✔️ LLMs The paper also identifies the amount of data required for fine tuning in LLMs, and argues that it is important to collect small amounts of data in a diverse manner
Mental-LLM: Leveraging Large Language Models for Mental Health Prediction via Online Text Data
written by Xuhai Xu, Bingshen Yao, Yuanzhe Dong, Saadia Gabriel, Hong Yu, James Hendler, Marzyeh Ghassemi, Anind K. Dey, Dakuo Wang
(Submitted on 26 Jul 2023 (v1), last revised 16 Aug 2023 (this version, v2))
Comments: Published on arxiv.
Subjects: Human-Computer Interaction (cs.HC); Computation and Language (cs.CL)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
What kind of research?
In a study examining what type of LLM is appropriate for mental health care, the following five types of LLM were compared
- Alpaca-7b
- Alpaca-LoRA
- FLAN-T5-XXL
- GPT-3.5
- GPT-4
As a background of this study, the mental health care domain is a field that has been attracting attention in recent years for research on the state of business and organizational management. However, comprehensive research has not been conducted on the performance of LLM in the mental health care domain and how accurate it actually is. Therefore, this paper investigates the potential of LLM in the comprehensive mental health care domain.
Differences from Previous Studies
The paper does not indicate that there have been no studies or surveys of LLM related to mental health care, and presents several relevant studies. However, it is noted that most of the studies are not as comprehensive as the present study, and that most of the studies are zero-shot studies using simple prompt engineering.
What also differentiates this study from existing studies is that it comprehensively studies and evaluates various techniques to improve the ability of LLMs in the mental health domain, including changes in model performance with prompts, the amount of data or items to watch for in fine tuning, and the evaluation of users' reasoning about text. The main goal of this study is to
Results of this study
The results of this study are summarized in the following four points.
(1) In the mental health care domain, we proved that GPT-3 and GPT-4 store sufficient knowledge in their knowledge space.
(2) We showed that fine tuning can significantly improve the ability of LLMs in multiple mental health-specific tasks across different datasets for multiple tasks at the same time.
(iii) Provided open fine-tuned LLMs for mental health prediction tasks
(iv) Provided a framework for the quantity and quality needed to create datasets for LLMs for future research in the area of mental health care.
Regarding (1) and (2)
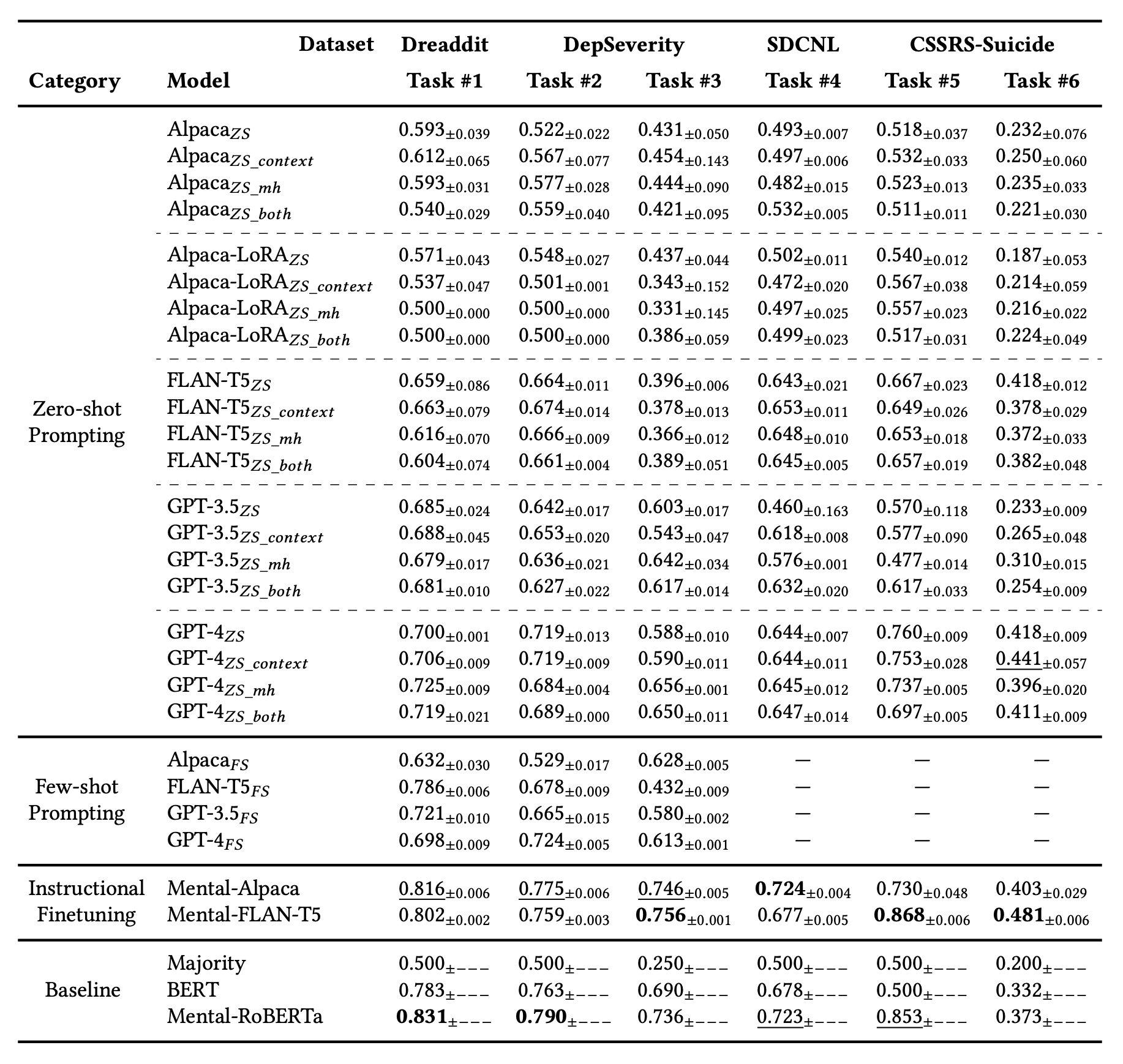
The following table shows the results of each model, from the top row: zero shot learning, zero shot learning + add with more contexts than questions, zero shot learning + give role to LLM, zero shot learning + add with more contexts than questions + give role to LLM.
Below are some samples presented in Few-shot Learning and answered.
From these results, the best performing TASK#1 is surprisingly the existing BERT model Mental-RoBERTa. The fact that there is no significant difference between Zero-Shot and Few-Shot when compared within GPTs indicates that the GPT series has sufficient knowledge about mental health in its knowledge space. This indicates that the GPT series contains sufficient knowledge about mental health in its knowledge space.
Another comparison between Alpaca and FLAN-T5 before and after fine tuning shows that before fine tuning, the performance of Alpaca and FLAN-T5 is overwhelmingly better than that of FLAN-T5. However, after fine tuning, Alpaca's performance catches up with that of FLAN-T5. This result suggests that early networks such as FLAN-T5 have inferior natural language understanding compared to LLM-based networks. As a result, we argue that Alpaca may have absorbed more information from the fine-tuning data during the fine-tuning process, and thus approached the FLAN-T5 result.
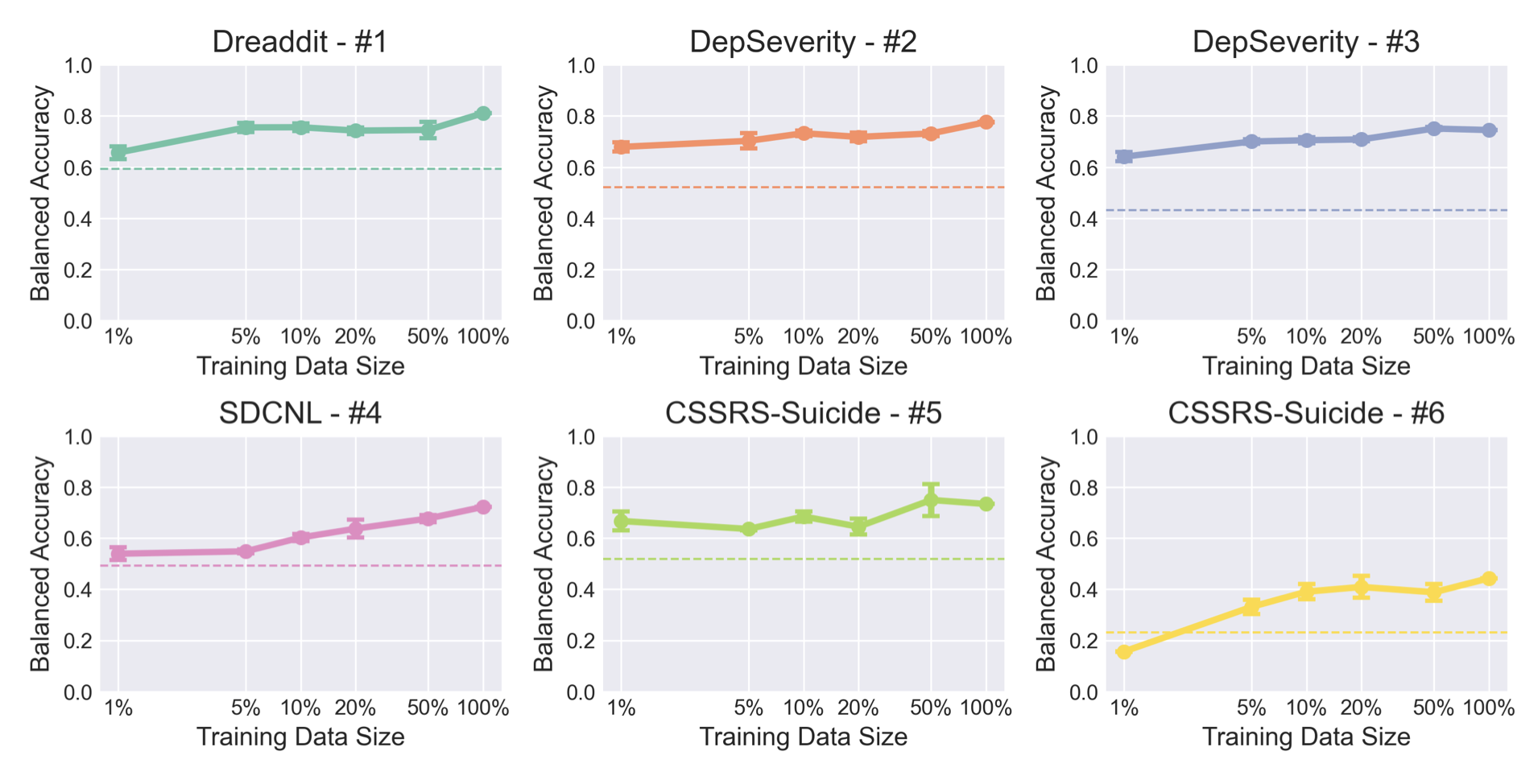
About (4)
The figure below, Fig. 1 in the paper, shows the transition in accuracy of the published Mental-Alpaca model as described in (3) when the training set is changed. The results show that after fine tuning, the accuracy of the base model is basically improved. Furthermore, we can see that the size of the dataset is not necessarily directly related to the accuracy of the system. This indicates that the quality and diversity of the dataset for fine tuning in LLM are more important than quantitative issues.
Experiment Details
As for the prompts, we have experimented with three patterns: no context, including similar information in the context, and giving the model the role of an expert, as well as a combination of the latter two, for a total of four patterns.
As we have just presented, the results show that the GPT series performs well regardless of the presence or absence of information in the prompts, and we judge that the knowledge about mental care is embedded in the knowledge space as basic information.
The design of each prompt is shown below for Zero-Shot and Few-Shot, respectively.
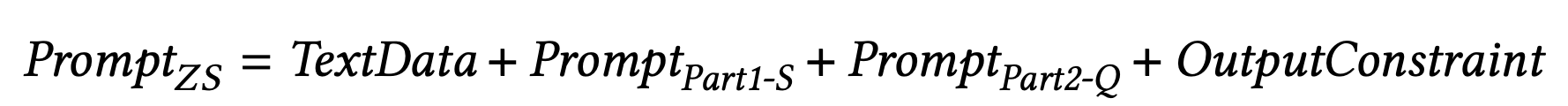
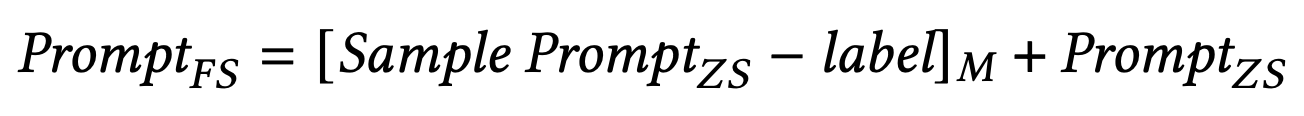
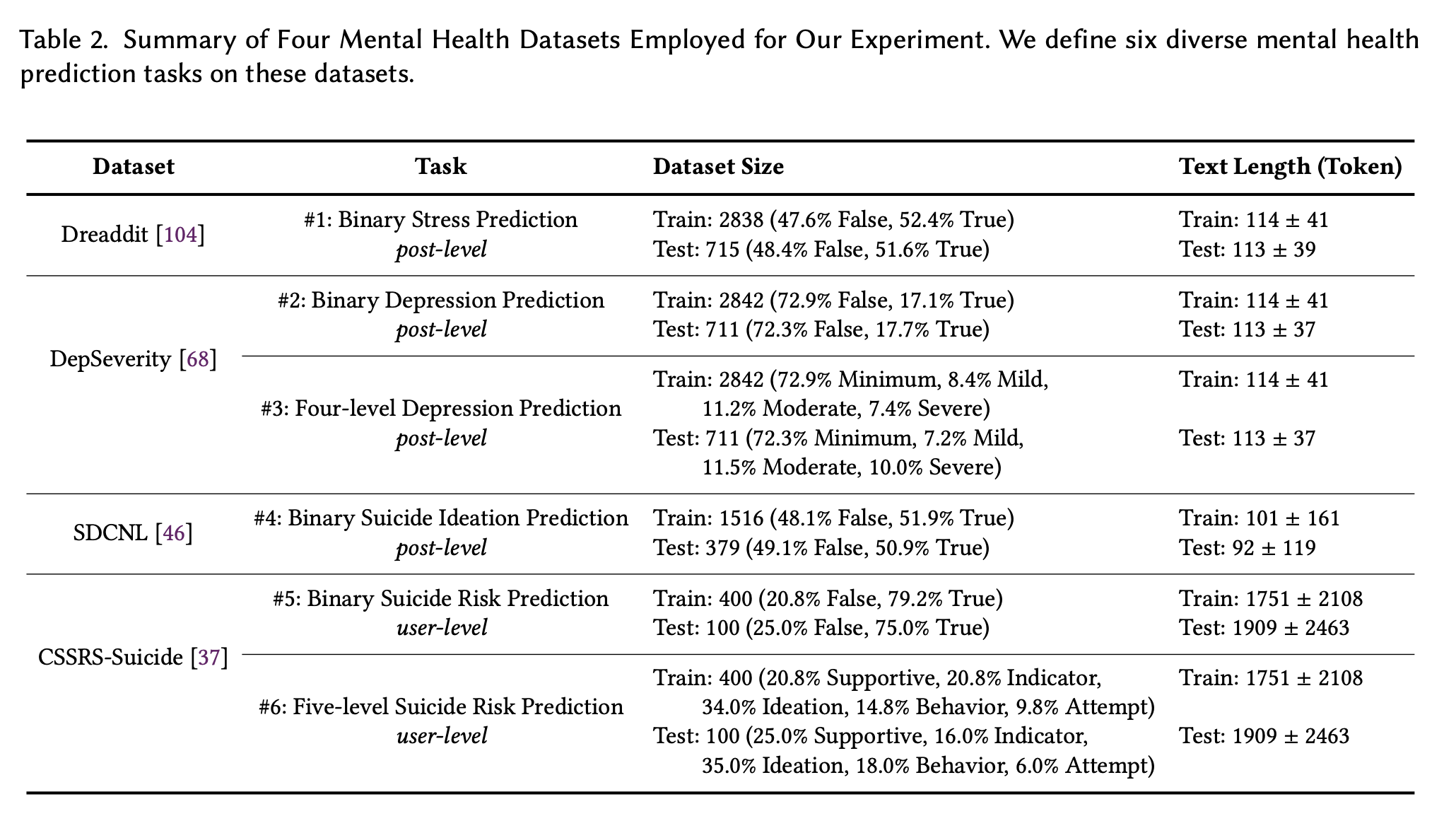
Next, the datasets used in the experiment are Dreaddit, DepSeverity, SDCNL, and CSSRS-Suicide. Each dataset is briefly introduced below.
Dreaddit
The Dreaddit dataset is a collection of posts from Reddit (a popular social networking site in the U.S.) and includes 10 subreddits in five domains (abuse, socializing, anxiety, PTSD. finance). Multiple human annotators evaluated whether a passage indicated stress for the poster, and the annotations were aggregated to generate the final label. We use this dataset for post-level binary stress prediction (Task 1).
DepSeverity
The DepSeverity dataset leverages the same submissions collected on Dreaddit, but differs in its focus on depression: two human annotators classify the submissions into four levels of depression according to DSM-5: minimal, mild, moderate, and severe. The data set was then used to create a task set with two submission levels. We employ this dataset for two submission-level tasks. (1) binary depression prediction (i.e., whether a post indicates at least mild depression, Task 2) and (2) four-level depression prediction (Task 3).
SDCNL
The SDCNL dataset is also a collection of posts from Reddit, including r/SuicideWatch and r/Depression. Through manual annotation, we label each post as indicating suicidal ideation or not. We employ this dataset for post-level binary suicidal ideation prediction (Task 4).
CSSRS-Suicide
The CSSRS-Suicide dataset contains submissions from 15 mental health-related subreddits. 4 active psychiatrists followed the guidelines of the Columbia Suicide Severity Rating Scale (C-SSRS) and 500 users were manually annotated on five levels: support, indicators, ideation, behavior, and attempted suicide risk. We utilize this dataset for two user-level tasks: binary suicide risk prediction (i.e., whether the user exhibited at least a suicide indicator, Task 5) and five-level suicide risk prediction (Task 6).
The split ratio of training data and test data and the number of data are shown in the image below.
These results were presented earlier.
Summary
When data and computational resources for fine tuning are not available, using an LLM focused on task resolution may yield better results. When sufficient data and computational resources are available, fine-tuning a dialogue-based model has been shown to be a better choice.
On the other hand, it was also noted that models such as Alpaca, with its interactive conversational capabilities, may be more compatible with downstream applications, such as mental health support for end users.
The following two issues are pointed out as future challenges
- More case studies are needed to bring it closer to practical application.
- Multiple datasets, more LLMs are needed for validation



Categories related to this article
![Libra] A New Multimo](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




