There's A Lot Of Duplicate Sentences Lurking In The Language Dataset!
3 main points
✔️ The current dataset has duplicates in the training and test data
✔️ The model will remember the duplicate data as it is
✔️ Removing the duplicate data will make the model better
Deduplicating Training Data Makes Language Models Bette
Written by Katherine Lee, DaphneIppolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, ChrisCallison-Burch, Nicholas Carlini
(Submitted on 14 Jul 2021)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG)
code:.
The images used in this article are from the paper or created based on it.
first of all
In the last few years, linguistic datasets have become increasingly large, but it has been pointed out that the quality of these datasets has become low due to the lack of manual review. Some common language datasets have been found to contain many duplicate examples and long repeated strings.
Naive deduplication is easy, but performing full deduplication on a large scale is computationally difficult and requires advanced techniques. (And for datasets like the one we're discussing, some form of naive deduplication is already in place.
The current dataset contains overlaps between training and test data, and we suspect that the accuracy of the training model is overestimated. It has also been confirmed that the training model remembers and outputs sentences that frequently occur in the dataset.
In this work, we propose two methods for detecting and removing duplicate data and investigate duplicate content in common language datasets (C4, Wiki-40B, LM1B).
proposed method
The easiest way to find duplicate statements is to perform string matching on all pairs, but this is not recommended due to the computational complexity. Therefore, we introduce two complementary methods.
We first use a suffix array to remove duplicate substrings from the dataset if they occur verbatim in multiple examples.
Next, we use MinHash. This is an efficient algorithm for estimating the n-gram similarity between all pairs of examples in a corpus, and if there is a lot of n-gram overlap with other examples, it removes the entire example from the dataset.
ExactSubstr
Because of the diversity of human languages, the same information is seldom expressed identically in multiple documents unless one expression is copied from the other or both are taken from a shared source. Such duplication can be removed by finding a complete substring match. This approach is called ExactSubstr.
The suffix array enables efficient computation of substring queries and identifies duplicate training examples in linear time. It has been widely used in natural languages processing tasks such as efficient TF-IDF computation and document clustering.
To find all repeated strings, we need to scan the SUFFIX array linearly from beginning to end, looking for sequences. Strings with a common prefix whose length exceeds a threshold are recorded. This algorithm can be run in parallel, so the dataset can be processed efficiently. In this case, we set 50 tokens as the threshold for matching substrings.
NearDup
This method is called NearDup, and it performs approximate duplicate deletion to handle the very common case of identical template parts, especially for web documents.
MinHash is an approximate matching algorithm that is widely used in large-scale duplicate removal tasks. If Jaccard coefficients of the n-grams of a document are sufficiently large, the documents are likely to be a close match; if two documents are considered to be a match, edges are created between them and graphed. In this way, we build a cluster of similar documents.
Indicates the percentage of duplicates detected by ExactSubstr and NearDup.
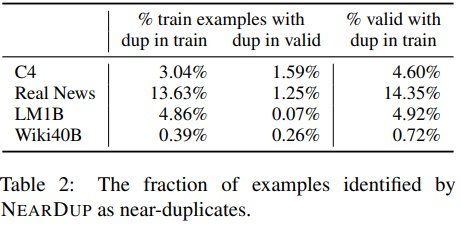
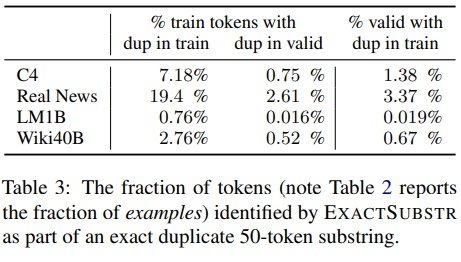
Using ExactSubstr, on average, removes more content than using NearDup. The exception is LM1B, where ExactSubstr removes one-eighth as much data as NearDup. Upon investigation, it was found that this was due to the LM1B document being much shorter.
Sentences with less than 50 tokens are not considered matches by ExactSubstr, even if the entire sequence matches. both NearDup and ExactSubstr may remove the same content. 77% of the training data that NearDup removes from C4 has In 77% of the training data that NearDup removes from C4, there is a match of length 50 or more detected by ExactSubstr.
The creators of RealNews and C4 explicitly attempted to remove duplicates while building the dataset, but their methods were insufficient to capture the subtle types of duplicate strings found on the Internet.
It is likely that much of the text identified in C4 and Wiki-40B as near-duplicates is automatically generated. With the exception of nouns such as location, company, product, date, etc., the text is identical. Since these examples often differ by only a few words at a time, a duplicate removal strategy that relies on full string matching will not identify a match.
In the case of RealNews and LM1B, both of which are derived from news sites, you can see that there is a lot of duplication as the same news appears on multiple news sites in slightly different formats.
Implications for model learning
XL models with 1.5 billion parameters, trained on C4-Original, C4-NearDup, and C4-ExactSubstr data, respectively; for data with almost no overlap, such as the C4 validation set, all models have comparable complexity.
However, the model trained on the duplicate deleted data has a significantly higher complexity than the model trained on the original data. ExactSubstr yields a larger difference in perplexity than NearDup. This trend is also true for the XL size models.
This may suggest that ExactSubstr results in the least overfitting of the model on the training set, but note that both of these methods use separate thresholds, and different threshold choices may change the results.
Duplicate deletion does not compromise, and in some cases improves, the complexity of the model, even though the training is faster due to the smaller dataset.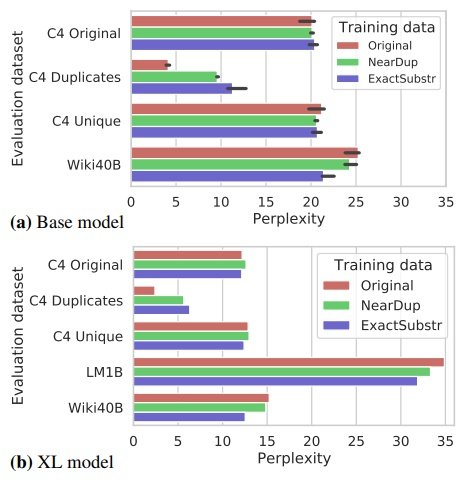
text generation
Data duplication has the effect of biasing the training model towards certain types of examples. This increases the likelihood that the generated sentences will be copied from the training data.
First, we evaluate the memory tendency when the model generates text without a prompt sequence: we generate 100000 examples, with a maximum length of 512 tokens.
In XL-Original, more than 1% of the generated tokens are included in the memorized subsequence. This is 10 times more memorized than XL-ExactSubstr or XL-NearDup.
summary
In this study, we focused only on English, but it is likely that similar problems exist in other languages. Recent work has also focused on the potential harm that can arise from problematic datasets. However, this work focuses on the amount of duplicate content in a typical dataset, the impact of duplicate deletion on the complexity of the trained model, and the reduction of the stored content of the trained model due to duplicate deletion. It does not focus on the nature of the data that is removed or stored by duplicate deletion.
Memorization is an important topic for future work because it can have serious privacy implications. Duplicate deletion is also not helpful for removing privacy-protected data that should not be used, such as passwords or medical records.
Although many of the sentences memorized by the model were considered harmless, we did not systematically assess their risk because it is beyond the scope of this study.
So far, we have only identified the benefits of duplicate deletion and have not investigated any negative effects. Some language tasks require explicit memorization, such as document retrieval and book question answering.
Whether memorization is a desirable or undesirable property of a language model depends on both the nature and the application of the memorized text. Developing techniques for remembering and forgetting specific texts depending on the application is a promising future line of research.



Categories related to this article






