Meet DialoGPT, A Powerful ChatBOT From Microsoft
3 main points
✔️ A chatBOT for generating human-like conversations.
✔️ A large dataset of conversations from Reddit with about 2 billion words.
✔️ State of the art performance on both automatic and human evaluation.
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
Written by YizheZhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan
(Submitted on 1 Nov 2019 (v1), last revised 2 May 2020 (this version, v3))
Comments: accepted by ACL 2020 system demonstration.
Subjects: computation and Language (cs.CL); Machine Learning (cs.LG)
code:.
Introduction
One of the most exciting use cases of Natural Language Processing(NLP) is chatbots. Chatbots have already proven to be valuable for customer service tasks. These chatbots are simple and therefore are easily confused by unseen questions. They need to be specifically designed for the company/task at hand, which is an expensive task to do. Even then, there is no guarantee for robustness. Transformers like GPT-2 which have been trained on large corpuses of data are able to generate fluent text that is rich in content. These large language models could be used to create more robust chatbots that can handle even tough unseen queries.

In this paper, we extend GPT-2 to overcome the challenges of conversational neural response systems. Our model is called DialoGPT which was trained on a large corpus of dialogue sessions extracted from Reddit. DialoGPT achieves state-of-the-art performance on both automatic and human evaluation. The responses generated by DialoGPT are diverse and relevant to the query.
Technique
Reddit Dataset
We use the discussion sessions extracted from Reddit to train our model. These are sessions from 2005 till 2017. Reddit organizes these discussion sessions in the form of trees. Each reply forms a new branch in the tree with the discussion theme/question serving as the root of the tree. Each path from the root to a leaf is taken as a training instance. The extracted data was rigorously filtered to remove the offensive language, repetitive words, very long/ very short sequences. After all the filtering, we ended up with 147,116,725 dialogue instances with 1.8 billion words in total.
Model
DialoGPT is based on OpenAI's GPT-2. GPT-2 is a transformer model composed of a stack of masked multi-headed self-attention layers, which has been trained on a large corpus of web text. We first concatenate all dialogues into a long text sequence x1,x1....xN, with a special end-of-sequence token in the end. We denote the source sentence as S = x1,x2,...xm, and target sequence as T = xm+1,xm+2...xN. The conditional probability of P(T|S) is given by,
Chatbot models are prone to generating bland, uninformative, irrelevant responses. In order to solve this problem, we implement a maximum mutual information scoring function. We use a pretrained model to predict the source sentences from responses i.e. P(Source|Response). Maximizing this likelihood penalizes bland and uninformative responses.
Experiment and Evaluation
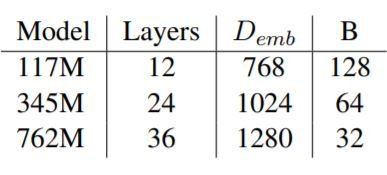
We trained three different models each with a vocabulary size of 50,257. The smaller and medium models were trained for 5 epochs and the largest one was trained for 3 epochs.
We tested our model on the DSTC-7(Dialog System Technology Challenges-7 track) dataset which tests the ability of a model to conduct human-like interactions with an initially undefined goal. Conversations in DSTC-7 are different from goal-oriented dialogues like booking tickets and reserving seats. We also compare our model to the PersonalityChat model that has been used in production as a cognitive service for Microsoft. The results are shown in the table below.
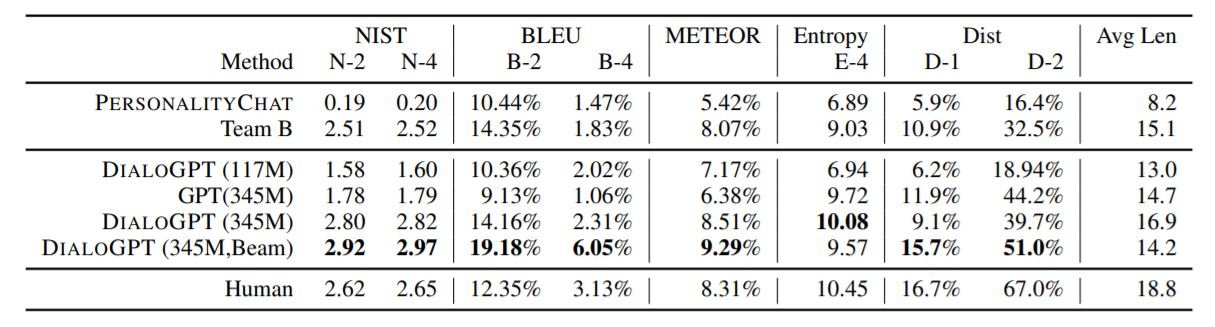
DialoGPT with 345M parameters with beam search(beam width 10) outperforms all other models. Here are a few samples of the responses produced by our model.


Summary
DialoGPT is a powerful neural conversational system. Since it has been trained on information from the Internet(Reddit), it is prone to producing unethical, offensive, or biased responses despite our efforts to limit them. The objective of DialoGPT is not only to improve chatbot performance but also to provide researchers a testing ground to learn to eliminate such biases and unethical responses from chatbots. Although DialoGPT receives better scores than humans, it is not indicative that DialoGPT converses better than humans. It is still not quite robust to the uncertainty in human conversations. You can test the chatbot for yourself from this link.



Categories related to this article






