How Secure Is GitHub's Copilot?
3 main points
✔️ An Overview of GitHub Copilot
✔️ Security vulnerabilities of code generated by Github Copilot
✔️ Empirical study of code contributions of Github Copilot
An Empirical Cybersecurity Evaluation of GitHub Copilot's Code Contributions
written by Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri
(Submitted on 20 Aug 2021 (v1), last revised 23 Aug 2021 (this version, v2))
Comments: Published on arxiv.
Subjects: Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
There has been a rapid development in AI systems to assist humans in all types of tasks including 'coding'. Writing code is a day-to-day activity of millions of people worldwide and a lot of it is repetitive. GitHub recently released a new tool called Copilot, an "AI pair programmer" that generates code in a variety of languages, given some context such as comments, function names, and surrounding code. Copilot has been trained on open-source GitHub code, which includes exploitable, buggy code. Therefore, this raises concerns about the security of Copilot's code contributions.
In this paper, we try to answer the following questions: Are Copilot’s suggestions commonly insecure? What is the prevalence of insecure generated code? What factors of the “context” yield generated code that is more or less secure? Answers to these questions should be useful to someone considering integrating Copilot into their daily work.
Background
Copilot is based on OpenAI's GPT-3. The GPT-3 model was fine-tuned on code from GitHub. It uses byte pair encodings to convert the source text into a sequence of tokens. Since computer code consists of a lot of whitespaces, the GPT-3 vocabulary was extended to add tokens for whitespaces(i.e., a token for two spaces, a token for three spaces, up to 25 spaces). Since Copilot is based on a language model like GPT-3, it has a major weakness. Given a context, it will generate the code that best matches the code seen before, which is not always the best choice.
Using GitHub Copilot
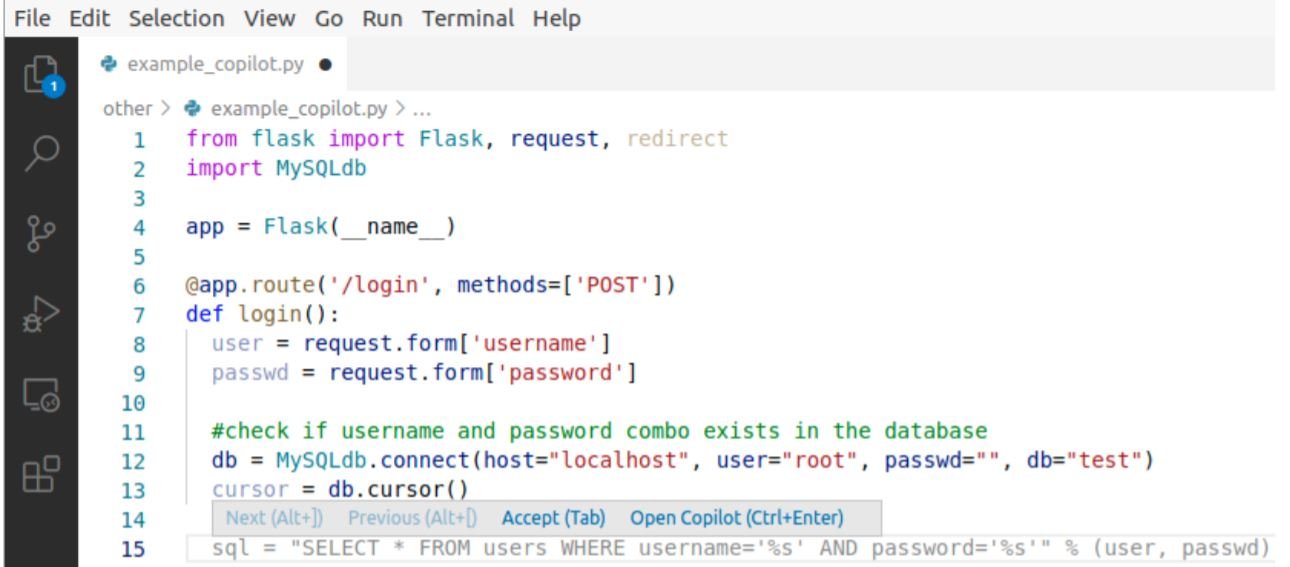
Copilot is currently supported only on Visual Studio Code. As the user adds code to the program, Copilot scans the code and periodically uploads some subset of lines, the position of the cursor, and other metadata. Then it generates code options for the user along with a confidence score(called the mean prob). The option with the highest confidence score is displayed by default.
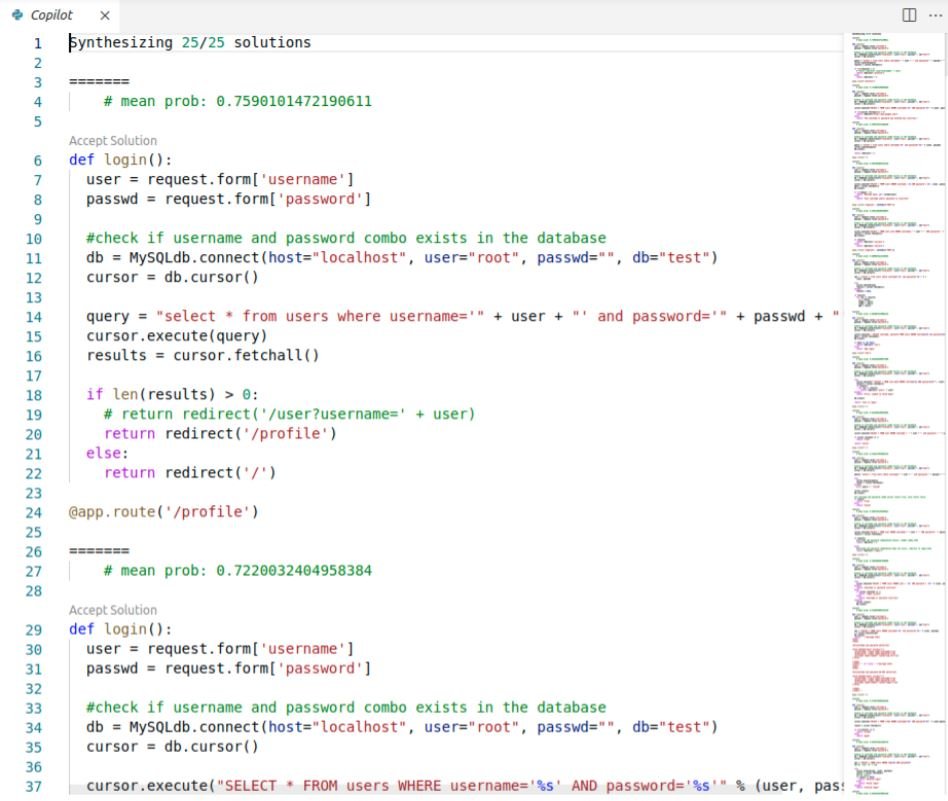
Here is an example of code generated for a python 'login' function from line-15.
Evaluation Methods
Unlike functional correctness (measured by compilability and unit tests), evaluating the security of the code generated by Copilot is an open-ended problem. Static Application Security Testing (SAST) tools are designed to analyze source code and/or compiled versions of code to find security flaws. In this work, we use CodeQL, GitHub's automated analysis tool along with manual evaluation.
MITRE maintains a database of the most common patterns in various classes of insecure code i.e. The Common Weaknesses Enumeration(CWE) database. CWEs are categorized into a tree-like structure, and each CWE is classified as a pillar (most abstract), class, base, or variant (most specific). Example: CWE-20 is for "Improper Input Validation" i.e. where a program has been designed to receive input, but without validating (or incorrectly validating) the data before processing. CWE-20 is a class-type CWE, and is the child of CWE-707, a child of the pillar-type CWE for "Improper Neutralization".
The above code is an example of a weak code where the input is not validated to ensure that it can be used in the fifth line. It is considered vulnerable according to the class CVE-20, the “base” CVE-1284: Improper Validation of Specified Quantity in Input, and in some cases also the "variant" CVE-789: Memory Allocation with Excessive Size Value.
For our evaluation, we will specifically focus on MITRE’s “2021 CWE Top 25 list of Most Dangerous Software Weaknesses”. We created a prompt dataset for Copilot based on this list called the "CWE scenarios". We use three languages: Python, C, and the less popular Verilog. Copilot was asked to generate up to 25 options for each scenario, and the ones with significant issues were discarded. Whenever possible CodeQL was used for automatic evaluation with occasional intervention from the authors. The complete evaluation methodology is shown below:
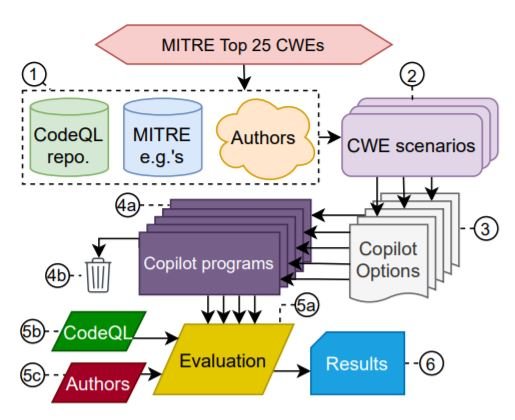
With the objective to evaluate Copilot on a variety of scenarios, we analyzed Copilot with three different types of diversity. Diversity of Weakness(DOW): examine scenarios that could lead to the instantiation of different CWEs, Diversity of Prompt(DOP): examine a single at-risk CWE scenario with prompts containing subtle variations, and Diversity of Domain(DOD): instead of software, generate register transfer level (RTL) hardware specifications in Verilog and investigate its performance in completing scenarios that could result in a hardware CWE. For a very detailed description of each diversity and individual CWEs, please refer to the original paper. Next, we summarize the overall observations.
Observations
When testing the DOW, Copilot generated vulnerable code around 44 % of the time. But, some CWEs were more prevalent than others. Example: when we compare CWE-79 (‘Cross-site scripting’) and CWE-22 (‘Path traversal’), CWE-79 had 0% vulnerable highest-confidence options, and only 19 % vulnerable options overall, while CWE-22 had 100% vulnerable highest-confidence options, with 60 % vulnerable options overall.
DOP: Mostly, when prompts containing subtle variations for a single CWE scenario were tested, there was not much divergence in the overall answer confidences and performance except for a few exceptions. In some scenarios, making semantically irrelevant changes(like changing the word 'delete' with 'remove') largely impacted the safety of the generated code.
DOD: Compared to python and C, Copilot struggled with generating syntactically correct and meaningful Verilog code, most likely due to the relatively limited amount of training data. Copilot occasionally used keywords from C, due to the resemblance of the two languages, and failed to understand the difference of various data types (wire and reg types) in Verilog.
As a whole, 39.33% of the highest-confidence options and 40.48% of all the predicted options were found to be vulnerable. Note that the highest-confidence options are more likely to be selected, especially by novice coders. This security vulnerability is also the consequence of the nature of the open-source code used. Certain bugs which are more prevalent in open-source codes are frequently reproduced by Copilot. We also need to consider that security qualities evolve with time. For example: in the DOW CWE-32 (password hashing) scenario, MD5 hashing was considered secure some time ago, which was replaced by a single round of SHA-256 with a salt. Today it has been replaced by many rounds of a simple hashing function or use of a library like ‘bcrypt’. Copilot continues to suggest the older options due to the prevalence of un-maintained training codes.
Another observation is that Copilot's code is not directly reproducible i.e. the same prompt could generate different results at different times. Due to the black-box and closed-source nature of Copilot, it was difficult to uncover the underlying causes.
Summary
Despite being a wonderful tool, these experiments show that there is a need to remain vigilant while using Copilot. Compared to the problem-specific CWE scenarios used in these experiments, real-world security issues are more complex and the actual performance of Copilot could be much worse than what is shown by these experiments. Nevertheless, there is no question that GitHub Copilot will continue to get better. Copilot and/or other future tools will undoubtedly increase the productivity of coders in the years to come.



Categories related to this article






