
ByteTrack+ Appearance Features Are The Strongest: SMILETrack
3 main points
✔️ Tracking based on ByteTrack considering appearance features
✔️ Proposed a mechanism to identify individuals of the same class based on Attention robustly
✔️ Proposed a gate function robust to occlusion and motion blur
SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking
written by Yu-Hsiang Wang, Jun-Wei Hsieh, Ping-Yang Chen, Ming-Ching Chang
(Submitted on 16 Nov 2022 (v1), last revised 17 Nov 2022 (this version, v2))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
After all, ByteTrack also needed to have exterior features! I would like to introduce SMILETrack, a SoTA model for object tracking. I was skeptical about ByteTrack, which relies only on motion information (IoU) for associations, but a new method was proposed that suggests using appearance features as well.
Object tracking can be divided into the Separate Detection and Embedding model (SDE), which relates detection results between frames based on a detector, and the Joint Detection and Embedding model (JDE), which uses a single model for everything from detection to tracking. SDE tends to be more accurate because it allows separate optimization of detection and tracking models. On the other hand, SDE tends to be more accurate because it uses two separate models for detection and tracking, which makes real-time estimation problematic.
JDE can output detection and tracking at the same time in a single estimation, so real-time estimation is expected, but it leads to a decrease in accuracy due to competing training. The proposed method SMILETrack is an SDE approach. Taking over the approach of ByteTrack, which achieved SoTA using only motion information, we proposed an Attention-based appearance feature extractor and achieved SoTA in MOT17 and MOT20.
SMILETtack's main contributions include
- We proposed an appearance feature extractor, Similarity Learning Module (SLM), which clearly distinguishes between individuals detected using Attention.
- We pointed out the low robustness of ByteTrack and proposed Similarity Matching Cascade (SMC), which achieves association with robust appearance information.
- Robust association to occlusion and motion blur through gate functions that control appearance and motion information
Now let's look at SMILETrack.
ByteTrack
Tracking is the association between tracking up to the previous frame and the object detected in the current frame. Usually, the association is made using two pieces of information: position information based on motion prediction and object appearance information. ByteTrack, on the other hand, achieved SoTA using only motion information. It uses only motion information because appearance features may worsen accuracy if they are not useful, and achieved SoTA for MOT17 and MOT20 with a simple two-step association process: association only with objects with high detection confidence, followed by association of objects with low confidence.
However, this paper points out the vulnerability of ByteTrack without appearance information. The paper points out that the high accuracy achieved with only motion information is due to the simplicity of the MOTChallenge movements, that the accuracy drops for complex movements, and that the lack of appearance information makes it impossible to support ID switches.
SMILETrack
For the above reasons, SMILETrack combines the advantages of both ByteTrack and appearance feature extraction. By combining two levels of association using detection confidence with robust appearance information using Attention, SMILETrack achieves highly accurate tracking. The overall picture is shown in the figure below.
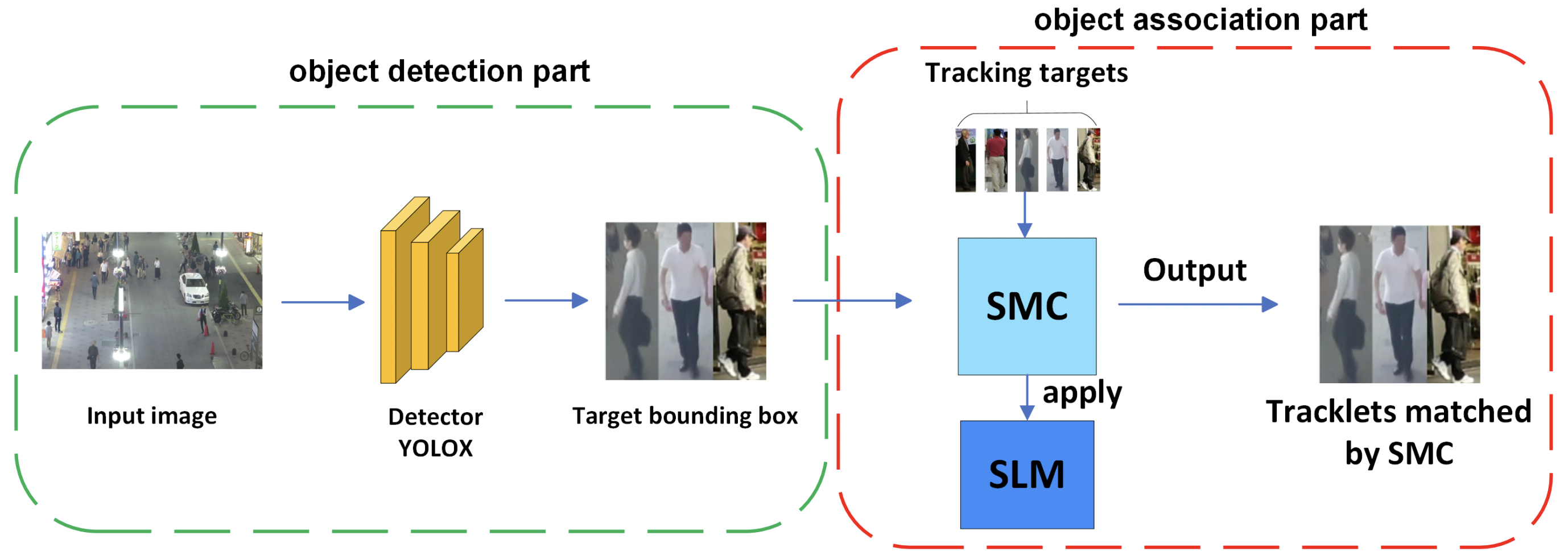
Similarity Learning Module (SLM)
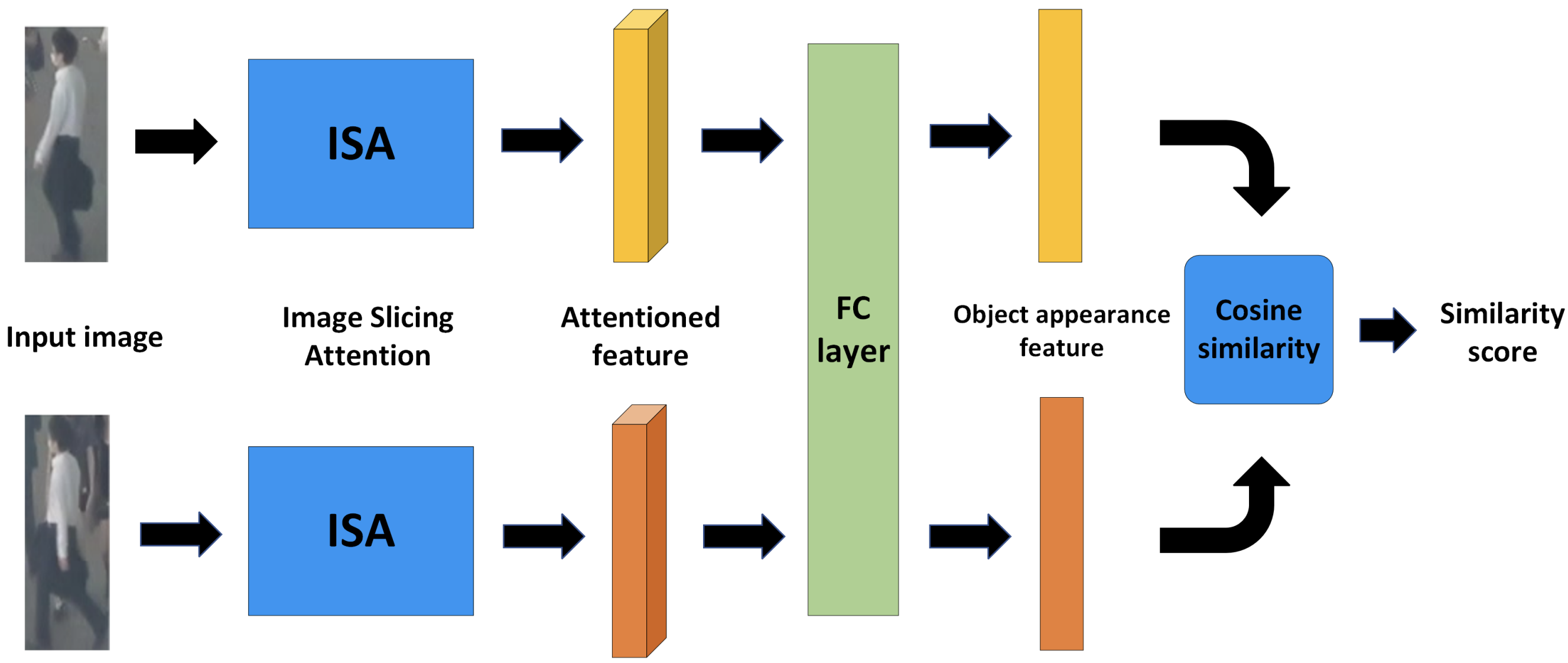
The appearance features of objects handled in tracking require more severe features than detection. While high-level features that discriminate between different classes are important for detection, low-level features that discriminate between different individuals within the same class are important for tracking. This paper proposes an appearance feature extractor called a Similarity Learning Module (SLM), which consists of an Image Slicing Attention (ISA) Block, to flexibly extract features for each individual that are more suitable for discrimination.
SLM has the mechanism of a Siamese network, shown in the figure below, to learn and evaluate the similarity between detected objects. The goal is to give a high similarity to the same individual (person) and a low similarity to different individuals. The cost of association is obtained by calculating the cosine similarity between them.
The ISA block takes the detected objects into 4 sliced images and extracts the relationship between them with Attention. First, the input is resized to a fixed size and input to ResNet-18. The resulting feature map is then divided into 4 slices and made into a slice image. The four segmented positions are embedded in linearly projected Q, K, and V and input to Q-K-V attention.
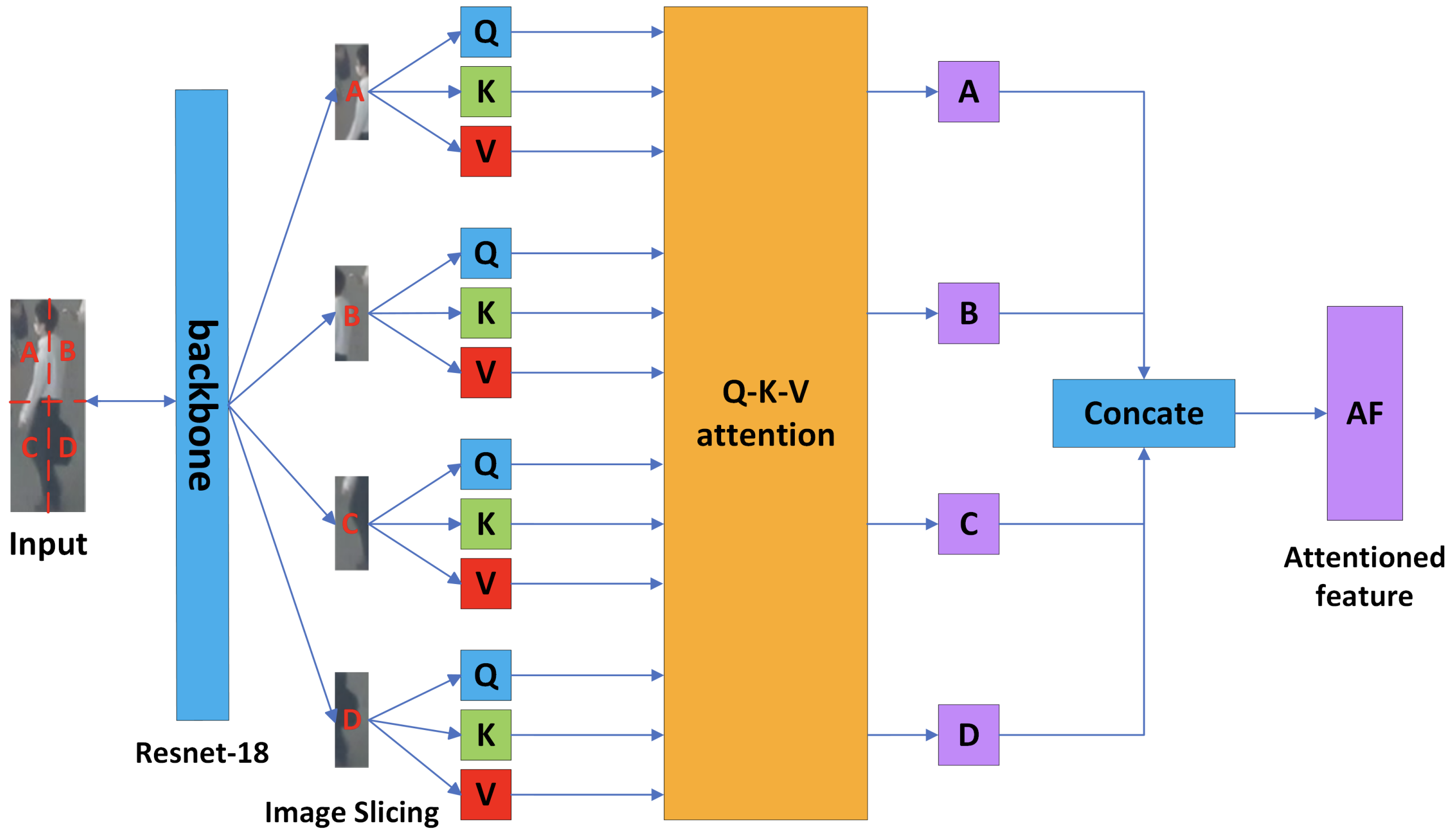
The Q-K-V attention block calculates Self-Attention and Cross-Attention between slices. The obtained features of the slices are finally combined to obtain the features of the detected object. By evaluating similarity with such Attention-based reliable features, a mechanism that can discriminate different objects of the same class with high accuracy is realized.
%2BCA(Q_%7BS1%7D%2CK_%7BS2%7D%2CV_%7BS2%7D)%0A%20%20%5C%5C%26%26%2BCA(Q_%7BS1%7D%2CK_%7BS3%7D%2CV_%7BS3%7D)%2BCA(Q_%7BS1%7D%2CK_%7BS4%7D%2CV_%7BS4%7D)%0A%5Cend%7Beqnarray*%7D&f=c&r=300&m=p&b=f&k=f)
(SMC)
SMC relates the obtained appearance information (SLM) with motion information (IoU) using a Kalman filter. The figure below shows the overall picture. First Association and Second Association, shown in light blue, are the two-step associations also found in ByteTrack.
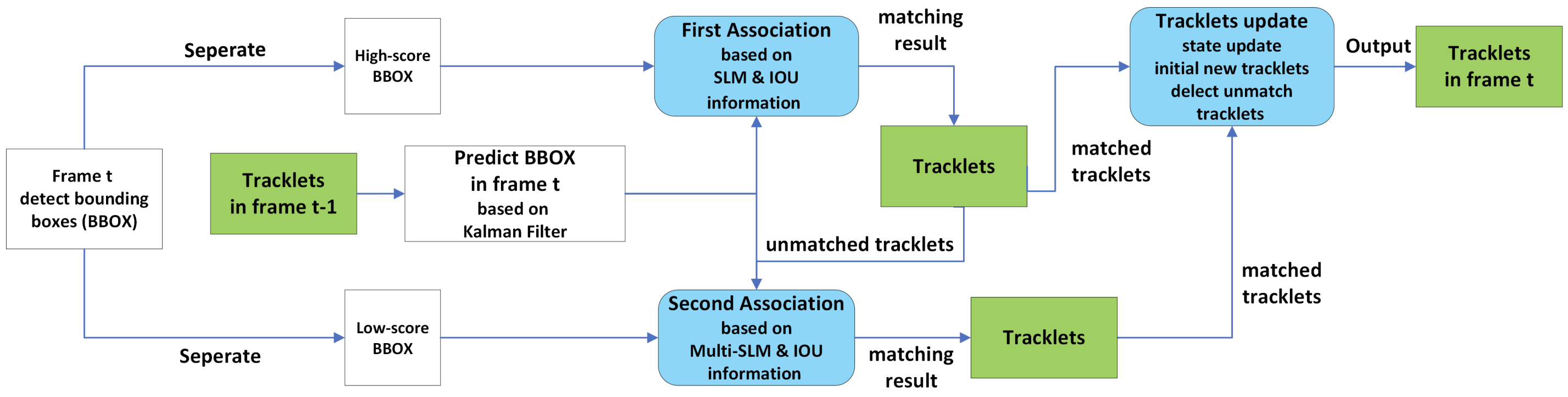
First, the detector divides the detection results (BBOX) for the current frame t into three categories according to the confidence level. Detections with confidence levels below 0.1 are considered background or noise and are not used for association. Detections with a confidence level higher than 0.1 are dichotomized by a threshold value of thres, where thres is the average of the confidence levels of the first half of the BBOXes, arranged in order of decreasing confidence level. BBOXes above this value are classified as high-score BBOXes, and BBOXes below this value are classified as low-score BBOXes.
Stage 1
In Stage 1,high-score BBOXes are preferentially used for the association, and tracking results up to frame t-1 (tracklet), and high-score BBOXes are linked by appearance information (SLM) and location information (IoU). This allows for reliable tracking using only high-quality information.
Stage 2
Stage 1 associates the low-score BBOX with the tracklet that was not associated in Stage 2. However, a slightly modified version of SLM, Multi-template-SLM, is used here. The reason for this is to cope with low-reliability detection.
Low confidence detection may be due to feature extraction difficulties caused by occlusion or motion blur. Therefore, the tracklet side uses multiple tracked frames instead of only one frame. The BBOX of each frame is stored as a feature bank, and each is input to the low-score BBOX and SLM to obtain similarity. The maximum value of similarity is used as the final cost of appearance information. This is referred to as multi-template-SLM in this paper.
Gate function
In both the first and second stages, a gate function is used for association. This is a mechanism for controlling appearance and motion information. The general approach is to weigh the cost of appearance information and the cost of IoU equally. In the equation below, α = 0.5.
![]()
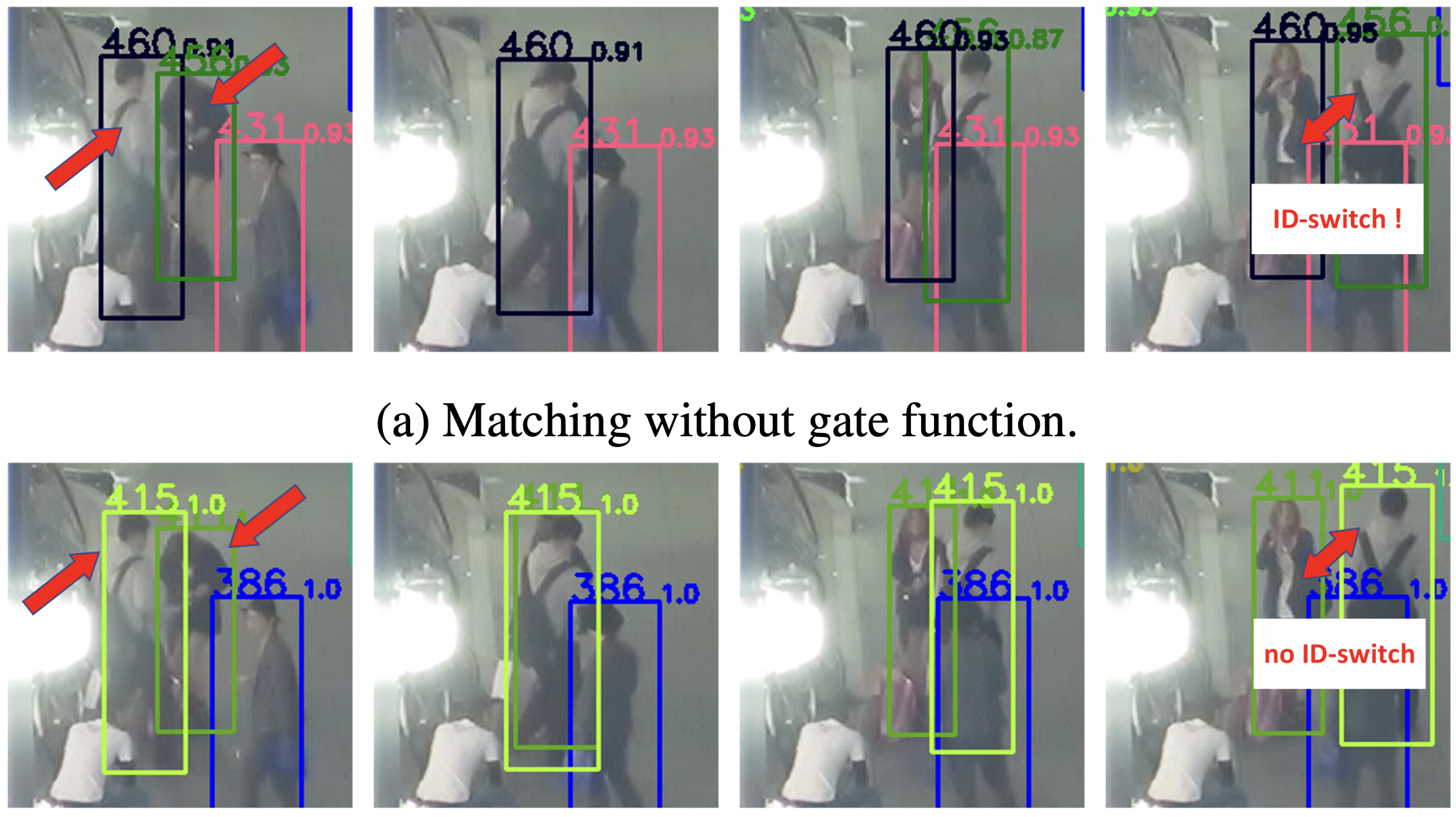
However, this creates a problem when the IoU between two different pedestrians is much higher than the similarity of their appearance characteristics. In other words, even if the two pedestrians are known to be different individuals based on their appearance if they overlap significantly in terms of location, the IoU will be high, resulting in the problem of an ID switch that associates them with different people.
This paper proposes a gating function that rejects matches with high IoU but appearance similarity lower than 0.7. This reduces the number of incorrect matches, where the overlap is good even if the appearances are different.
experiment
In the experiment, the MOT17 dataset is used for comparison and ablation studies with the SoTA model in terms of accuracy. For ablation, the first half of the MOT17 training data is used for Train and the second half for Validation; for comparison with the SoTA model, a combination of MOT17, CrowdHuma, ETHZ, and City person is used for training.
mounting
The detector of the proposed method uses a model called PRB, which is pre-trained on the COCO dataset and then fine-tuned on MOT16 and MOT17. The SLM is trained on a unique dataset culled from the MOT17 training set. 30+ frames Tracklets that could not be associated are deleted and the feature bank of multi-template-SLM is retained for up to 50 frames.
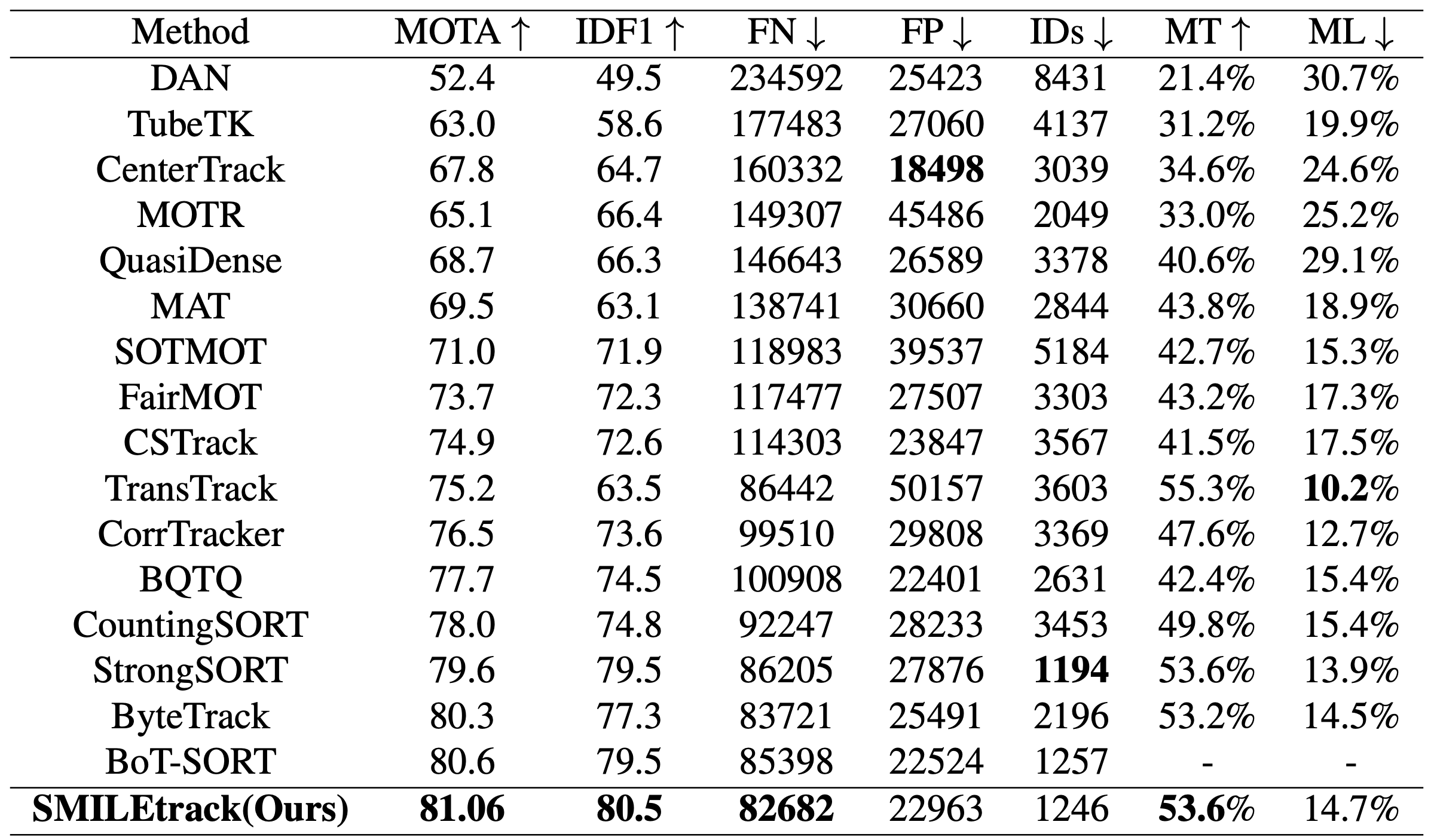
Comparison with the SoTA model
Accuracy of the MOT17 test set. The accuracy of SMILETrack was 81.06 for MOTA and 80.5 for IDF1, the highest accuracy among all methods. The SMILETrack achieved the highest accuracy among all methods, with 81.06 for MOTA and 80.5 for IDF1. This is based on the settings that achieved the highest accuracy in the next ablation study.
ablation
First is the effectiveness of SLM. We compare the accuracy of each stage of the association with or without employing appearance information (SLM). We use regular SLM instead of Multi-template-SLM for stage 2 as well. Therefore, as shown in the table below, the model using SLM has the highest accuracy only for Stage 1, which has a high confidence level, indicating that the use of appearance information based on the confidence level is appropriate.
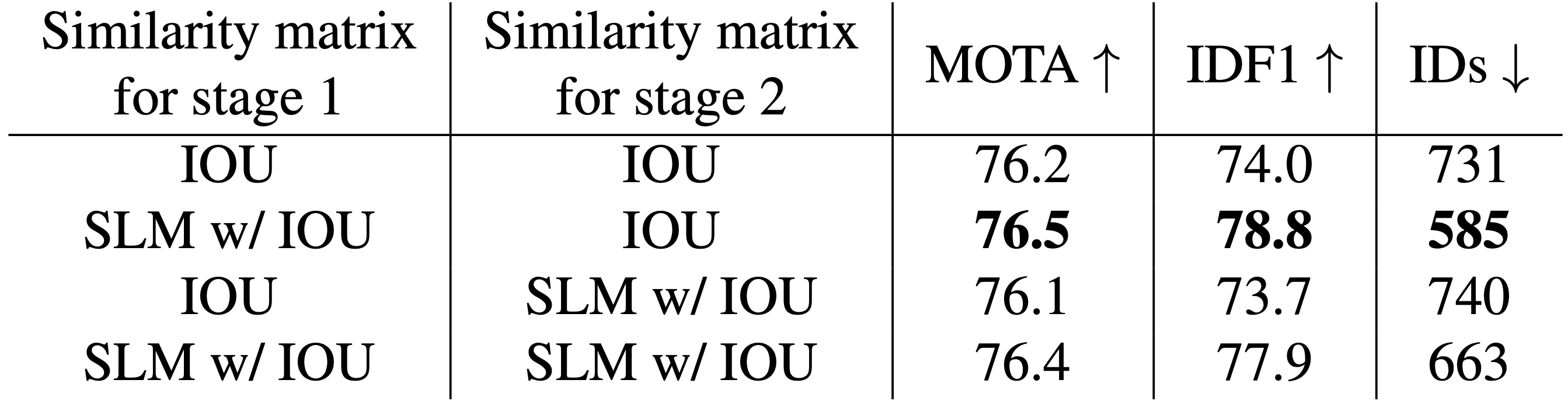
Finally, here is a comparison with and without gate function and Multi-template-SLM. Based on a model that uses motion information (IoU) and appearance information (SLM) for both Stage 1 and Stage 2, we compare the results with the case where Stage 2 is changed to Multi-template-SLM or where gate functions are employed for both stages. It can be seen that the accuracy improves when gate functions or Multi-template-SLM are employed. The model employing both achieved the highest accuracy in ablation, demonstrating the superiority of this method.

impression
We have introduced several tracking methods in the past, but this SoTA model appears to be a fairly simple mechanism. There is no mention of pre-processing such as camera shake correction or post-processing such as global linking to compensate for tracking breaks. I think it is necessary to verify whether the ByteTrack approach and Attention-based Siamese network worked to achieve SoTA despite this, or whether it is due to the good performance of the detector PRBs.
summary
We introduced a MOTChallenge SOTA method called SMILETrack. It inherited the advantage of ByteTrack, which performs two-step association at the confidence level of detection and improved the accuracy by extracting robust appearance features using a Siamese network with Attention. Appearance features that are problematic for low-confidence associations were properly handled using Multi-template-SLM and gating functions to minimize accuracy loss.
One issue is that this method is slower than the JDE model because it is an SDE model. They plan to consider approaches that can improve this trade-off. We look forward to future developments.



Categories related to this article

