When Should Agents Explore?
3 main points
✔️ Focus on when to search, whereas previously we only considered the amount of search
✔️ Enable flexible search design by increasing variables
✔️ Experiment with the effect of each variable
When should agents explore?
written by Miruna Pîslar, David Szepesvari, Georg Ostrovski, Diana Borsa, Tom Schaul
(Submitted on 26 Aug 2021 (v1), last revised 4 Mar 2022 (this version, v2))
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
first of all
Reinforcement learning has had great success in several areas, including board games, video games, and robot control, but the problem of search remains a central challenge.
One of the basic considerations in reinforcement learning is the balance between exploding and exploitation. The question is how to strike a balance between taking the best option from the information we have at the moment or going to gather information to find a better option.
The question of how much to search has been the subject of much research so far, such as epsilon-ready and entropy-maximizing reinforcement learning such as SAC, which is also used in DQN. However, there has not been much research on the issue of when to search. In this article, we introduce a paper written by DeepMind's research team, which was accepted for publication in the 2022 ICLR.
technique
search method
First of all, we consider a method that has a search mode and an exploitation mode. For example, epsilon-greedy is equivalent to this. The exploitation mode is to take the best action in the value function we have now, while the search mode is to find a better action. In the search mode, two types of search methods are considered in this paper: one is uniform exploration, which, as the name suggests, selects actions completely at random, e.g. ε-greedy. The other is intrinsic motivation search, which is the method used in RND.
Granularity of search
Next, we consider the granularity of the search. This can be classified into the following four patterns.
Step Level (C)
The most common setting determines whether to search every step. A prominent example is epsilon-greedy.
Experimental level (A)
All behaviors are determined in exploratory mode and learned off-policy. This is also a common method and is equivalent to using an intrinsic reward.
Episode Level (B)
Choose whether or not you want to explore each episode.
intra-episodic(D,E,F,G)
This method is between the step level and the episodic level. Exploration continues for several steps but does not extend over the entire episode. It is the least studied setting, and the present study deals mainly with this setting.
Each of these methods is illustrated in the following figure. On the left, pink represents the exploration mode and blue represents the exploitation mode. The right figure shows the relationship between the amount of exploration and the length of exploration. px shows how much exploration is included in all actions, and medx shows how much exploration is continued continuously once the user enters the exploration mode. The area surrounded by skin color corresponds to intra-episodic, and as you can see from this, the method is quite flexible.

switching method
Now let's look at how to switch between search and exploitation modes. There are two main types of algorithms.
blind switching
This is the simplest method and considers only the frequency of switching without considering the state. For example, we can prepare a counter to switch a certain number of times, or we can use a probabilistic selection method like epsilon-greedy.
informed switching
The method uses the agent's internal state for higher-level decision-making and consists of two components. First, a scalar-valued trigger signal is emitted by the agent at every step. Secondly, the agent makes a mode-switching decision based on that signal. As a practical example, in this paper, we use the value promise discrepancy, which is a quantity expressed by the following equation, as the trigger signal.
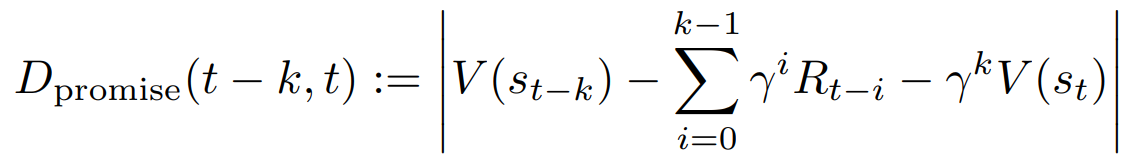
This represents the difference between the prediction before k steps and the realized value after the actual action, and the method switches to the search mode when this value is large, i.e., the prediction is not working.
Another important question is what the initial mode should be at the start of the episode. Of course, it depends on the task to be adapted, but in many cases, it is effective to start with the exploitation mode. This is because the initial state neighborhood is visited relatively more often than other states, and thus the predictions are more accurate.
experiment
setup
It uses 7 Atari games. We have chosen to focus on the most difficult ones, such as Montezuma's Revenge.
We choose R2D2 as the main reinforcement learning algorithm. This is a distributed DQN that uses RNNs to represent the Q-function. We compare this R2D2 based on the R2D2 with the search granularity and mode-switching algorithm introduced above. Of course, mode-switching is only used in training, and the greedy strategy is used in the evaluation.
baseline
To compare intra-episodic with other methods, we consider the following four baselines
- All search mode (experiment-level-X)
- All exploit mode (experiment-level-G)
- ε-greedy ε=0.01 (step-level-0.01)
- Bandit meta controller to select and lock between episodes (episode-level-*)
For each of the above, we provide two search modes: uniform search (X_U) and intrinsically motivated search (X_I).

The figure compares these baselines with the proposed intra-episodic method (solid red line). The left two figures show the uniform search case, and the right two figures show the intrinsic motivating search case. We can see that intra-episodic is superior in both cases.
Variations of intra-episodic
Many variations of the term intra-episodic can be considered. They are enumerated below. The notation in parentheses corresponds to a symbol indicating the method.
- How to search: uniform search (XU), intrinsically motivated search (XI)
- Search period: fixed (1,10,100), adaptively selected by bandit (*), or handled by the same algorithm as switching to search mode (=)
- Switching: Blind, Informed
- Duration to continue to exploit mode:
- For blind switching. Fixed (10,100,1000,10000), stochastic (0.1,0.01,0.001,0.0001), adaptive selection with bandit (n*, p*)
- For Informed Switching. Select target rate. Fixed (0.1,0.01,0.001,0.0001), adaptive selection by bandit (p*)
- Mode at start: Exploit (G) or Search (X)
Based on these, one method is expressed as follows.

It shows that the search is uniformly performed, the search mode is 100 steps continuous, the probabilistic blind switching is selected by Bandit, and the initial mode is exploitation.
performance
We now look at how this intra-episodic variation affects exploratory performance. The following figures show how the amount of exploration changed as the episode progressed (columns 1 and 3). In each of the first and third columns, the horizontal axis shows the mode mode mode mode mode mode mode mode mode mode mode mode mode mode mode mode mode mode mode mode mode mode mode normalized by the episode length, and the vertical axis shows the proportion of the exploration mode mode mode in all steps. The start of training is represented by a square and the end of training is represented by an X. It is interesting to note that these two figures are similar even though uniform search and intrinsically motivated search are very different.

switching
Next, we compare switching.

The left and middle figures show how exploitation (blue) and exploration (red) are distributed when the mode is switched to blind and informed, respectively. We can see that there is a variation in the density of exploration in the informed case. The figure on the right shows the returns of each method, with informed performing better in the end.
Mode at start
Next, we look at the effect of the mode at the start of the episode.
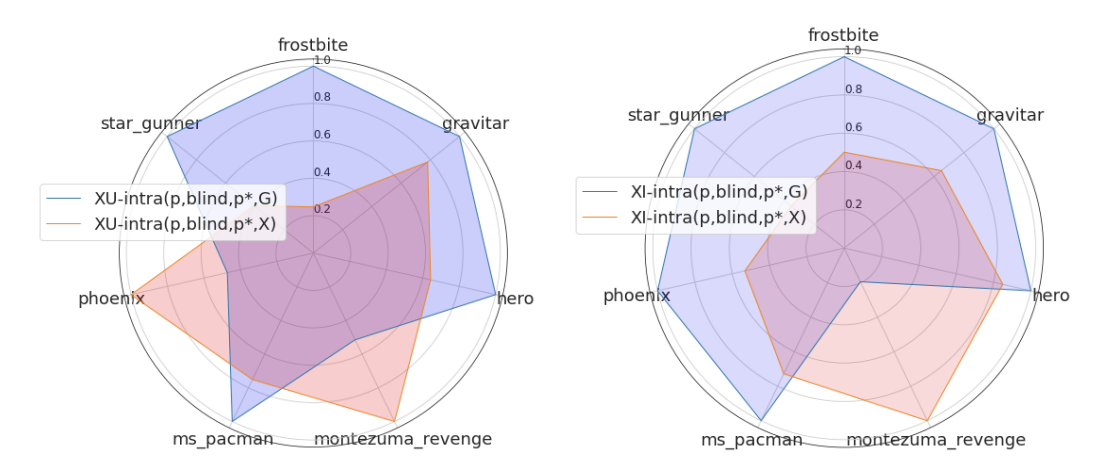
The figure above shows the returns for the search start (red) and exploitation start (blue) for each of the seven games, with a uniform search on the left and an internal motivated search on the right. We can see that the exploitation start case is better. This can be interpreted as the state at the beginning of the episode is visited more often and the prediction is more stable. However, in a game like Montezuma's Revenge, which requires a long period of exploration, the exploration starts will perform better, and you will need to have a good idea about the environment you are adapting to.
Mode switching in blind switching
Finally, we compare the counting and probability formulas for mode switching methods in blind switching.
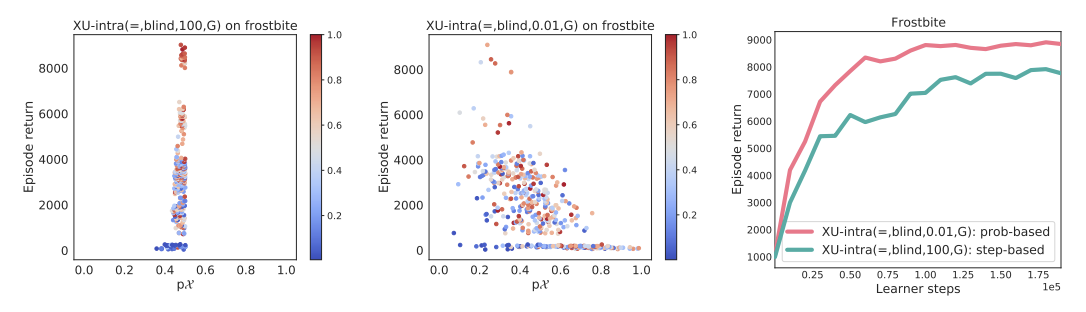
The left two figures show the relationship between the amount of search and return in each episode. As training progresses, the color of the dots changes from blue to red. In the left panel (counting type), there is no significant change in the search fee between episodes, and the return increases steadily as the training progresses. In the middle (establishment type), we can see that the search fee varies a lot between episodes and the return falls as the search increases. The figure on the right shows the returns of these methods, and we can see that the probabilistic method performs better.
summary
In this article, we introduced a paper that went into the "when" aspect of an agent search. The intra-episodic distinction proposed by the authors of this paper allows us to design agents' exploration more flexibly than before. However, the problem is that this is limited to cases where there is a clear distinction between exploration and exploitation modes. Currently, the mainstream methods for continuous value control are based on entropy-maximizing reinforcement learning, such as SAC. These algorithms do not switch between modes and can be said to be always exploring in some sense. Future research is expected to develop this intra-episodic concept so that it can encompass SAC and other methods.



Categories related to this article






