継続学習における事前学習言語モデルを比較する
3つの要点
✔️ 事前学習言語モデルに継続学習手法を適用
✔️ 各モデル・継続学習手法のロバスト性を比較
✔️ 事前学習言語モデルを各層ごとに分析
Pretrained Language Model in Continual Learning: A Comparative Study
written by Tongtong Wu, Massimo Caccia, Zhuang Li, Yuan-Fang Li, Guilin Qi, Gholamreza Haffari
(Submitted on 29 Sep 2021)
Comments: ICLR2022
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
破局的忘却を回避しながらモデルの学習を行う継続学習(Continual Learning)は、以前より様々な研究がなされ、多くの手法が提案されています。また、自然言語処理の領域では、BERTやALBERTなど、多くの事前学習モデルが提案され、活発に研究されています。
この記事では、継続学習と事前学習モデルを組み合わせた場合における性能について包括的な比較研究を行い、事前学習モデルを利用した継続学習に関する様々な情報を明らかにした論文について紹介します。
前置き
まず、比較実験の対象となる事前学習済み言語モデル、継続学習の設定、継続学習手法などの前提知識について紹介します。
事前学習済み言語モデル(PLM)
事前学習済み言語モデル(PLM)を利用することは、質問応答や要約などの多くのNLPタスクにおいて有効な方法だと言えます。論文では、以下の5つの事前学習済み言語モデルを利用します。
- BERT:本サイトの解説記事
- ALBERT:本サイトの解説記事
- RoBERTa:本サイトの解説記事
- GPT-2:左から右に向かい1トークンずつ予測する自己回帰言語モデルであり、自然言語生成タスクに多く利用されます。
- XLNET:本サイトの解説記事
詳細は元論文または本サイトの解説記事を参照ください。
継続学習の問題設定
継続学習は、与えられる一連のタスクを、以前に学習したタスクの性能を低下させることなく学習することを目標とします。このとき、学習時のインクリメンタル(incremental、増分)な分類タスク設定で評価されることが一般的です。より具体的には、クラス・ドメイン・タスク増分学習の三つの設定が用いられます。
どの学習設定でも、継続学習アルゴリズムは各タスクを順番に一度ずつ与えられますが、以下のような違いが存在します。

- Task-IL:test時に、処理するタスクに関する情報(task-ID、タスクラベル)が与えられます。
- Domain-IL:test時に、処理するタスクに関する情報(task-ID)は与えられませんが、処理中のタスクに関する情報を予測する必要はありません。
- Class-IL:test時に、処理するタスクに関する情報(task-ID)は与えられない上、処理中のタスクに関する情報を予測する必要があります。
この設定は過去の研究に従っています。
継続学習手法
継続学習手法は大きく三つ(リハーサル、正則化、動的アーキテクチャ)に分類することができます。
・リハーサルベース手法
リハーサルベース手法では、過去のサンプルを何らかの形で保存し、新たなタスクの学習時に再利用します。最も単純な方法は、過去のサンプルを新しいデータと共にリプレイすることで、破局的忘却を抑止します。これはExperience Replay(ER)として知られており、しばしば高度なベースラインとなります。
単純なリプレイではなく、過去のサンプルを利用した制約付きの最適化を行うことで、過去タスクでの損失増加を防ぐ手法等も存在しており、ERの性能・効率を高めるために多くのリハーサルベース手法が提案されています。
・正則化ベース手法
正則化ベース手法では、過去のタスクで重要であるとみなされたパラメータの大幅な更新を防ぐことで、破局的忘却に対処します。これらの手法はElastic-Weight Consolidation(EWC)に始まり、EWCでは以前に学習した重みをL2正則化損失を用いて大きな変化を抑制します。
正則化ベース手法はタスクの境界に依存する傾向があり、長いタスクシーケンスやタスクIDが与えられない設定では失敗することが多いです。
・動的アーキテクチャ手法
動的アーキテクチャ手法はパラメータ分離法とも呼ばれており、異なるタスクにフィットするために、モデルパラメータの異なる部分集合を利用します。これに分類される有名な手法としては、Hard Attention to the Task(HAT)などが挙げられます。
正則化ベース手法と同様、通常の動的アーキテクチャ手法では、テスト時にタスクIDが必要となります。
実験
ベンチマークによるPLMの継続的学習
実験では、次の三つの疑問について調査します。
- (1)PLMの継続学習時に破局的忘却の問題は存在するか?
- (2)PLMにおいて、どの継続学習手法が最も効率的か? その理由はなにか?
- (3)どのPLMが継続学習に対し最もロバストであるか? その理由はなにか?
実験設定
実験では、PLMと線形分類器を組み合わせることで、次の手法について比較検討を行います。
- Vanilla:前のタスクで学習したモデルをそのまま次のタスクで最適化します。破局的忘却が最も発生しやすい設定であり、弱い下界にあたります。
- Joint:全タスクを同時に学習します。破局的忘却の影響を受けないため、性能の上界にあたります。
- EWC:正則化ベース手法であるEWCを利用します。
- HAT:動的アーキテクチャ手法であるHATを利用します。(Class-IL設定では適用できません。)
- ER:リハーサルベースの手法であるERを利用します。
- DERPP:リハーサル・正則化ベースのハイブリッド手法であるDERPPを利用します。
評価指標は以下の通りです。
- Forward transfer:$FWT=\frac{1}{T-1}\sum^{T-1}_{i=2}A_{T,i}-\tilde{b_i}$
- Backward transfer:$BWT=\frac{1}{T-1}\sum^{T-1}_{i=1}A_{T,i}-A_{i,i}$
- Average accruacy:$Avg.ACC=\frac{1}{T}\sum^T_{i=1}A_{T,i}$
ここで、$A_{t,i}$は$t$番目のタスクでモデルを学習させた後の$i$番目のタスクのテスト精度で、$\tilde{b_i}$はランダム初期化での$i$番目のタスクのテスト精度です。
実験に用いるデータセットは以下の通りです。
- CLINC150
- MAVEN
- WebRED
各データセットのデータ分布は次の通りです。
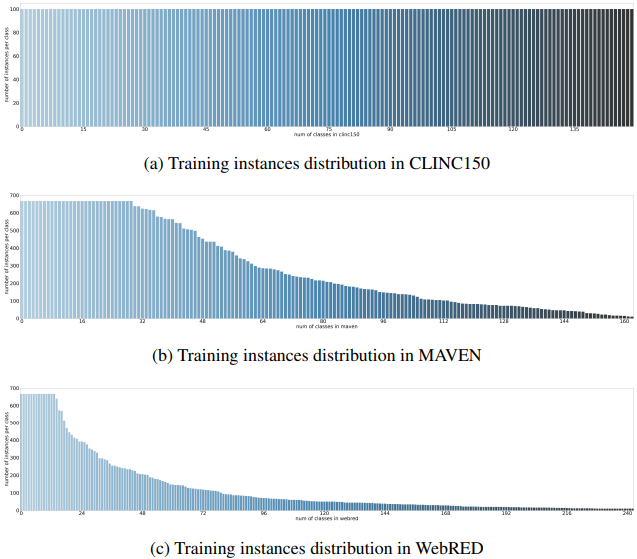
縦軸はクラスごとのデータ数、横軸はクラス数を示しています。
実験結果
各設定で実験を行い、得られた精度は以下の表にまとめられています。
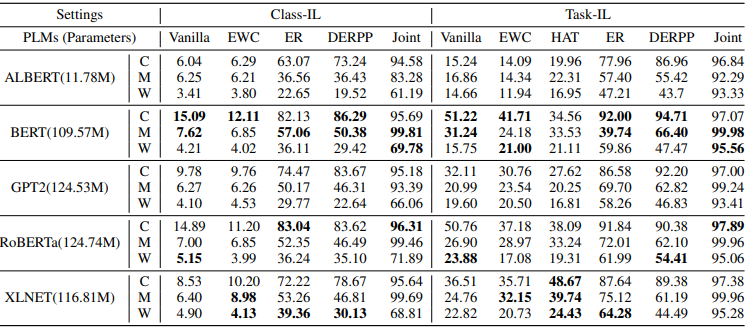
各PLMのVanillaとJointの精度を比較すると分かる通り、PLMでは深刻な破局的忘却が起きています。これは全データセット(C,M,W)に共通であり、特にClass-IL設定でより深刻です。また、各モデルごとの異なる継続学習手法の結果と、各継続学習手法ごとの異なるモデルの結果の比較は以下の通りです。
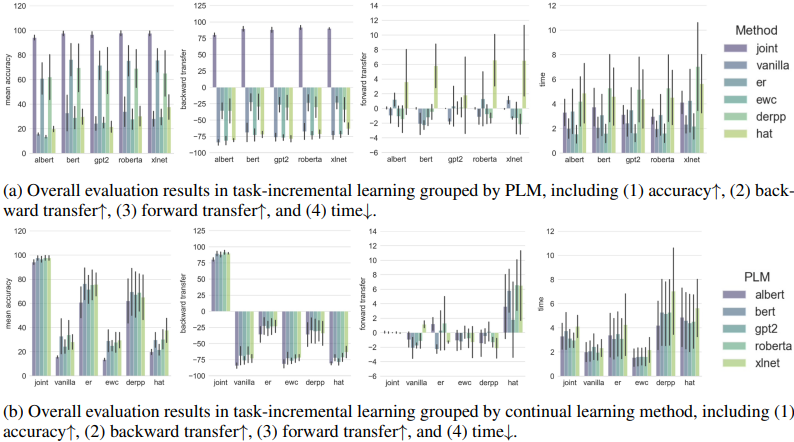
総じて、PLMの中でBERTが最もロバストであったこと、継続学習手法の中でリハーサルベース手法が最も有効であったことがわかりました。
論文では上記の結果についてより詳細に分析するため、次の疑問についてさらなる調査を行っています。
- (1)継続学習中、BERT のブラックボックス内で何が起こっているのか?
- (2)PLM間・各PLM内の層間における性能差は何か?
- (3)リハーサルベースの手法が正則化ベースの手法よりもロバストである理由は何か?
- (4) リプレイはどの層で最も貢献しているのか?
これらの疑問に答えるため、実験ではまず、BERTの各層の各タスクにおける表現力、各タスクの各層における表現力を測定しました(詳細は元論文4.1参照)。
結果は以下の通りです。
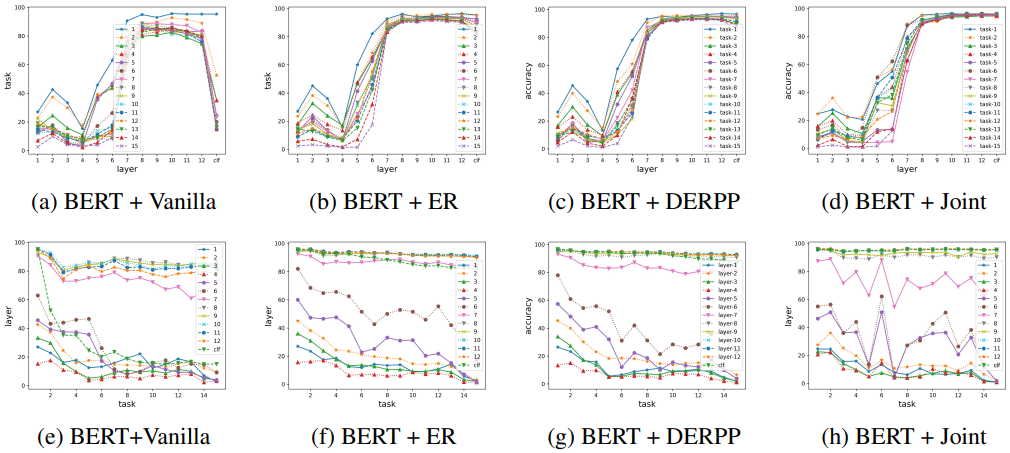
この結果から、破局的忘却が中間層と最終層の両方で生じること、ERが中間層と最終層の忘却を抑制できることがわかりました。また、各PLMモデルについて、Vanilla設定の場合と、異なるバッファサイズでER手法を適用した場合の各層の表現力は以下の通りです。
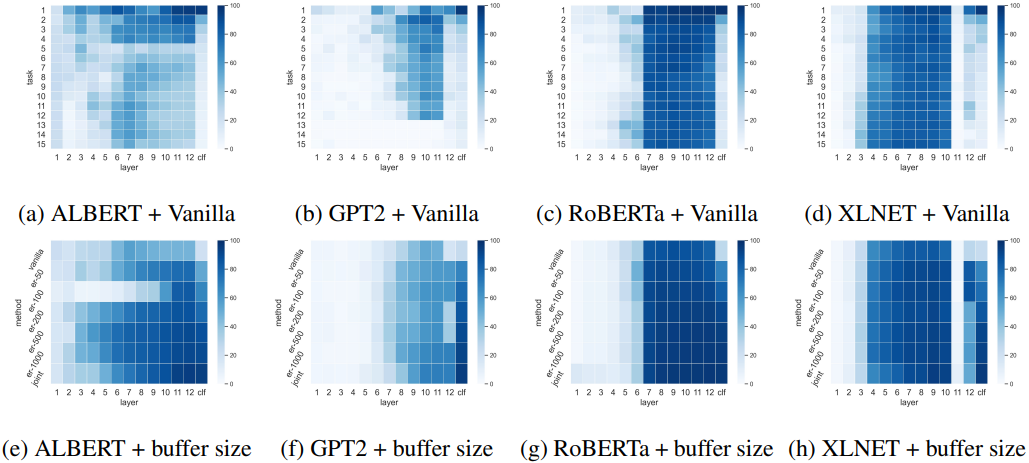
図(a~d)では各PLMのバニラ設定における各タスク・各層の表現力を、(e~h)はERを適用した場合のバッファサイズと各層の表現力(色が濃いほど良好)を示しています。実験の結果、どのPLMかによってロバストな層や脆弱な層が異なり、リプレイによりどの層の性能が向上するかも異なることがわかりました。
例えばALBERTの隠れ層はBERTやRoBERTaよりも脆弱であり、これはパラメータ共有メカニズムによると思われます。またERによる影響については、XLNetでは12層・clf層の性能が向上している一方、RoBERTaやGPT2では主にclf層の性能が向上しています。
総じて、継続学習に対するロバスト性は層によって異なり、かつどの層がロバストであるかもPLMのアーキテクチャによって異なる、という興味深い結果が得られました。
まとめ
本記事では、代表的な事前学習言語モデルと継続学習を組み合わせた場合の性能特性を調査し、各言語モデル内の層ごとの分析を行った研究について紹介しました。
この研究から得られた洞察は、PLMを利用した継続学習における重要な貢献であると言えるでしょう。



この記事に関するカテゴリー




