
異なる解像度の特徴をどう結びつけるべきか?:Sonyが提案したD3Net
3つの要点
✔️ 高密度な推定が必要なタスクのための機構D3 Blockを提案!
✔️ dilated convolutionとskip-connectionで起こるエイリアシングの問題を解決!
✔️ セマンティックセグメンテーション・音源分離タスクでSoTAを達成しモデルの一般性を示した
Densely connected multidilated convolutional networks for dense prediction tasks
written by Naoya Takahashi, Yuki Mitsufuji
(Submitted on 21 Nov 2020 (v1), last revised 9 Jun 2021 (this version, v2))
Comments: CVPR2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
今回紹介するのはSonyの提案したdensely connected multidilated DenseNet(D3Net)です、CVPRに採択されています。D3Netは高密度な推定タスク、つまり入力画像の次元と同じ次元の推定が必要なセマンティックセグメンテーションや音源分離などのタスクに焦点を当てたネットワークです。最近はCNNをViTの性能に近づけるための大規模化の研究が盛んで、主に受容野の拡大のためにカーネルサイズの変更やDeformable Convolution(変形可能な畳み込み)の採用など畳み込み層に焦点を当てた設計が目立ちます。そんな中で今回の手法はDilated convolution(膨張畳み込み)を使用した受容野の拡大を効率的に行うための手法を提案しています。特に高密度タスクを扱い、複数の解像度における特徴抽出の重要性、つまりグローバルな特徴とローカルな特徴の両立に着目し非常に密に接続する設計をしています。
主な貢献は次の通りです。
- 複数の解像度における密な特徴抽出の重要性を主張し、skip-connectionとdilated convolutionを組み合わせたD2 Blockを提案した
- D2 Blockはmultidilated convolutionを組み込み、dilated convolutionをそのままDenseNetに組み込んだ際に起こるエイリアシングの問題を解決した
- D2Blockをネスト構造に組み込み、異なる膨張率の畳み込みを複数回行うことで各解像度で柔軟に特徴を抽出するD3 Blockを提案した
- 異なるドメイン・タスクの高密度な推定タスク(セマンティックセグメンテーション・音源分離)でSoTAを達成し、提案手法の一般性を実証した
少し前の論文ですが、膨張畳み込みのエイリアシングに着目して精度を向上させた点が興味深いです。それではD3Netを見ていきましょう。
高密度な推定タスク
セマンティックセグメンテーションや音源分離など、入力次元と同じ出力が必要となるタスクでは、ピクセルレベルで分類・回帰が必要となります。そのため細かな部位や信号を特定するローカルな特徴と物体全体を把握するグローバルな特徴の両方が重要です。
当然ながらグローバルな特徴とローカルな特徴は依存関係があります。特定の解像度の特徴ではなく、異なる複数の解像度の特徴を同時に考慮することが重要です。
しかし既存のアプローチ(FCN,UNet,HRNetなど)は異なる解像度の特徴マップを数回程度しか結びつけません(下図)。本論文ではこの点を問題視し、複数の解像度の特徴を同時に密にモデリングする重要性を主張し、D3Netを提案しています。

全体像
まずはD3Netの全体像を説明します。D3NetはCNNの代表的モデルであるDenseNetをベースとしています。DenseNetはDenseBlockを4層接続し、各ブロック内の全層をskip-connectionさせた非常に密なネットワークです。skip-connectionによりローカルな特徴を後段まで保持でき、モデルサイズを抑えながら情報を最大限利用できます。そのため様々な特徴を密に接続させたい本論文のモチベーションとしては最適です。DenseBlockに対して、dilated convolutionによる効率的な受容野の拡大、エイリアシングの解決のためのmultidilated convolutionの採用、より柔軟なモデリングのためのネスト構造を取ったものをD3 Blockとして提案し、D3 Blockで構成したネットワークをD3Netとして提案します。
Multidilated Convolution
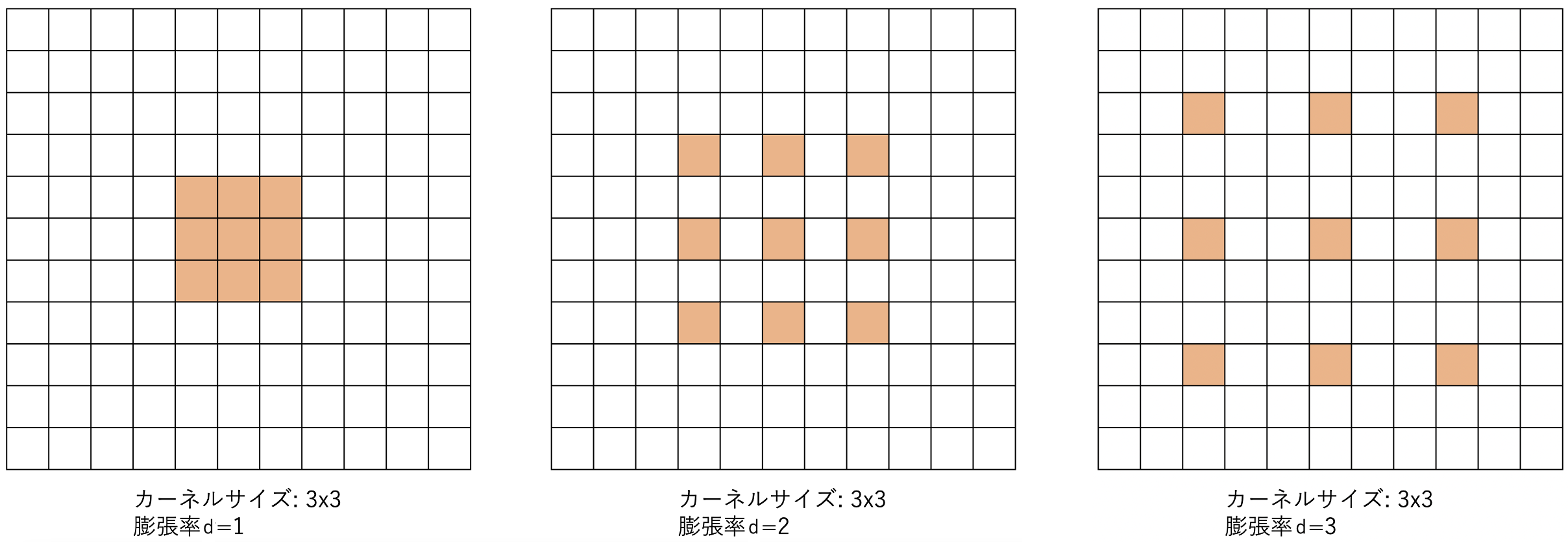
まずは核となる要素から説明します。CNNの受容野の拡大はCNNの大規模化・高精度化では必須の課題です。受容野の拡大により長距離依存性を獲得し、グローバルな特徴も捉えられるようになるため、高密度な推定に十分生かすことができます。本論文では効率的に受容野を拡大するため、dilated convolution(膨張畳み込み)に着目しました。その名の通り、同じパラメータ数でカーネルを膨張させることで広範な特徴を考慮することができます。下の図がイメージです。同じパラメータ数でサンプリング間隔を変えることで受容野を拡大しています。
dilated convolutionを採用することで効率的に受容野を拡大することができますが、DenseNetとdilated convolutionの組み合わせは実は既に提案されています。本論文ではこの時起こるエイリアシングの問題に着目し、改良をおこなっています。dilated convolutionにおけるパラメータ同士の間隔はそのままサンプリング周波数と捉えることができます。つまりナイキスト周波数以上の高周波が低周波と区別がつかなくなるエイリアシングの問題が起きうると言うことです。
既存手法はdilated convolutionの前に標準の畳み込み層を複数適用し、ローパスフィルタの役割を負わせることで一意に処理できない高周波成分を除去しています。しかしDenseNetのようにSkip-Connectionを行う場合はそのような処理は行えず、下図の(a)のようなエイリアシングの問題が発生します。
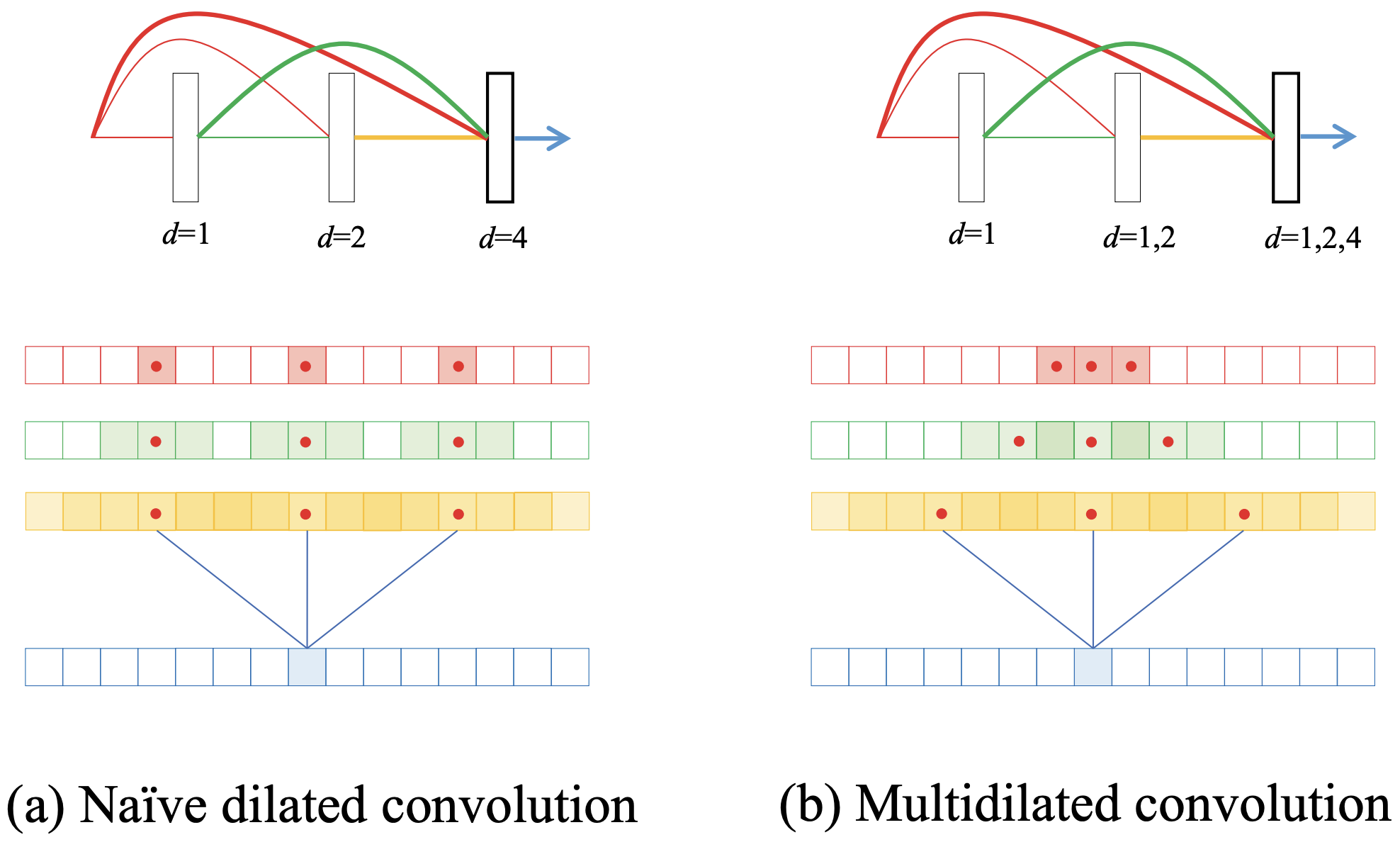
膨張率dを倍にすることで指数関数的に受容野を拡大しています。簡単のために特徴マップに対するサンプリングを1次元で表すとエイリアシングの問題を把握できます。特徴マップのサンプリングに死角がなければエイリアシングは起きません。3層目のdilated convolution(d=4)にはskip-connectionで前の全層の特徴マップが接続されます。ここでd=4で各マップをサンプリング(赤の点)すると受容野の死角を確認できます。赤のマップは入力そのもののため、受容野はサンプリングした点のみ(赤マス)で、エイリアシングの問題が最も顕著に起きます。続いてd=1、つまり通常の3x3畳み込みで処理した緑のマップのサンプリングを考えます。1マスをサンプリングすれば間接的に3x3マスを考慮することができます(緑マス)が、それでも受容野に死角が存在していることが分かります。直前の黄色のマップでは死角がないため、一見このままdを大きくし続けるなら影響がないように見えます。しかしD3Netは決してdを大きくし続けるのではなく、ブロック単位でdを再び1にリセットし、何度もdilated convolutionを繰り返していきます。これは高解像度・低解像度の特徴抽出を密に繰り返すことが重要なためです。つまりこのままではブロック毎にエイリアシングの問題が顕著に起こる不安定なモデルになってしまいます。
提案手法(上図(b))は膨張率を複数用いることでエイリアシングの問題を解決しています。難しいことはなく、d=1の特徴マップにはd=2を、d=2のマップにはd=4と、エイリアシングが生じない最大の膨張率で各マップをサンプリングしているだけです。これによりエイリアシングの問題を解決しつつ、1つの層で複数の解像度で畳み込みを行うことができます。3層目の畳み込みではd=1で密に抽出したローカルな特徴マップから、d=1・d=2・d=4と順にグローバルになっていく特徴マップが両立されていることが分かります。式で表すと次のようになります。上が従来のdilated convolution、下が複数の膨張率を適用するmultidilated convolutionです。lは現在のレイヤー、xは特徴マップです。0からl-1までの特徴マップがskip-connectionで得られ、Batch NormalizationとReLUを適用しています(式ではψ)。これに対して従来のdilated convolutionは単純に各層毎のフィルタを適用しています。対してmultidilated convolutionではどの膨張率dの畳み込みからskip-connectionされたかを表すiで異なる膨張率diとフィルタを適用しています。
![]()
![\begin{align*}
x_l = \sum_{i=0}^{l-1}\psi([x_0,x_1,\cdots,x_{l-1}])\;\circledast_{d_i}\;w_l^i
\end{align*}](https://texclip.marutank.net/render.php/texclip20230113154150.png?s=%5Cbegin%7Balign*%7D%0A%20%20x_l%20%3D%20%5Csum_%7Bi%3D0%7D%5E%7Bl-1%7D%5Cpsi(%5Bx_0%2Cx_1%2C%5Ccdots%2Cx_%7Bl-1%7D%5D)%5C%3B%5Ccircledast_%7Bd_i%7D%5C%3Bw_l%5Ei%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
このように複数のmultidilated convolutionを接続したブロックをD2 Blockと呼び、D3 Blockの核となるブロックとして提案しています。D2 Blockはこのようにしてエイリアシングを回避し指数関数的に拡大する受容野でさまざまな解像度の情報を同時にモデリングできます。
最後にD2 Blockの概要図を示します。上で示した図の2次元の例です。
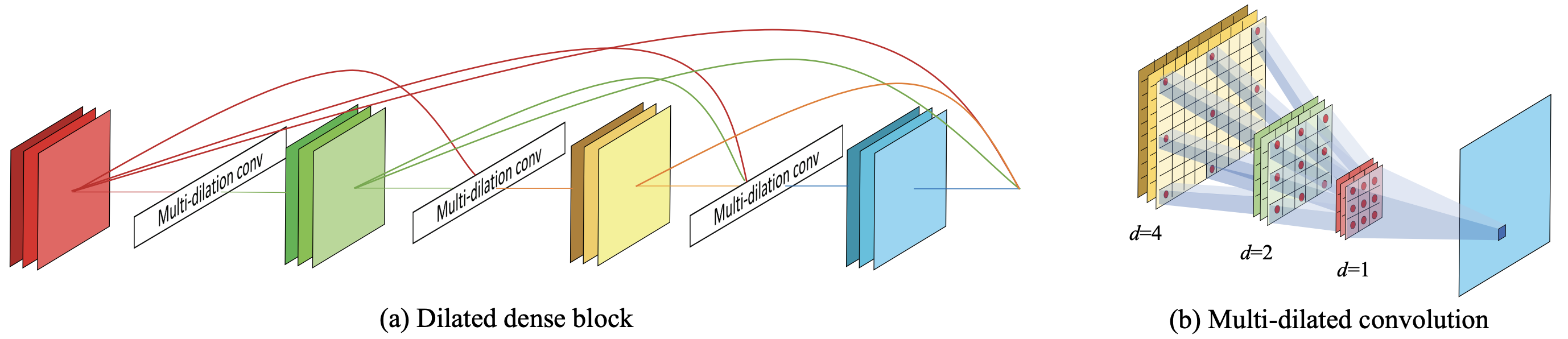
D3 Block
提案手法はここから更に、各解像度の情報を柔軟に解釈できるD3 Blockを提案しています。D3 Blockは次の図の構造を持ちます。先にD2 Blockの細かな部分を抑えておきます。成長率kです。
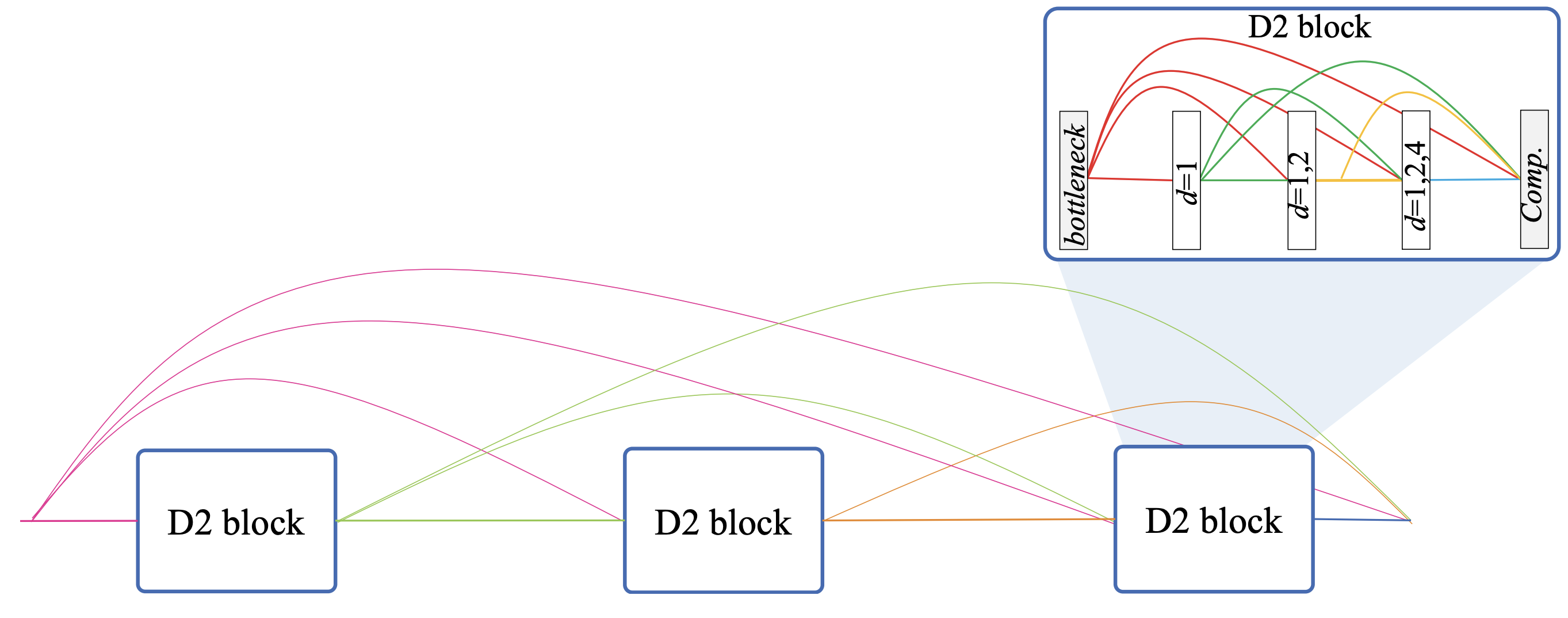
成長率(growth rate k)
D3Netは先述のようにDenseNetをベースとしています。DenseNetはResNetのように単純に畳み込みでチャンネル数を増やしていく機構とは違い、メインのn個の特徴マップから分岐し、k個の特徴マップを生成したものをメインに追加しています(n+k個)。そのためこのkを成長率と呼びます。D2 Blockの式では各x0,x1,...,xlがk個のマップを持っています。ただD2 Blockは前後にBottle neck層とComp層を持ち、チャンネル圧縮を行うため、n+kが厳密なチャンネル数ではありません。
またここまで、multidilated convolutionで複数の解像度を考慮していますが、ダウンサンプリングは行っていないため、特徴マップのサイズはいずれも同じものです。
ネスト構造
D3 BlockはM個のD2 Blockで構成されます。図から分かるとおり、D3 Blockはskip-connectionのネスト構造をとっています。multidilated convolutionの全層をskip-connectionさせたD2 Blockと同じように、D2 Blockの全ブロックをskip-connectionさせています。つまり、ブロック間でもブロック内でも密にskip-connectionさせる構造をとっています。これにより、あるD2 Blockは前のD2 Blockですでに複数の解像度の情報を考慮した特徴を更に複数の解像度で解釈するため、D3 Blockが極めて密で柔軟なモデルと分かります。
ハイパーパラメータ
D3 Blockは5つのパラメータ(M,L,k,B,c)を持ちます。先述したようにMはD2 Blockの数、LはD2 Block内のmultidilated convolutionの層数、kは成長率です。Bはbottleneck層のチャンネル数で本論文ではB=4kと設定しています。最後のcはComp層の圧縮率でチャンネル数をc倍に圧縮します。
D3Net
D3NetはD3 Blockを採用した任意のモデルを指しますが、本論文ではDenseNetをベースとした改良モデルを使用しています。ここまでダウンサンプリングは行われてきませんでしたが、D3NetはDenseNetと同様にTransition層でチャンネル数の変更とダウンサンプリングを行います。これにより、次のD3 Blockでは異なるマップサイズでまた複数の解像度の特徴抽出を行っていきます。
実験
実験では高密度な推定が必要な2つのタスクで検証することで提案手法がタスク・ドメインに対して一般性を持つことを実証しています。
セマンティックセグメンテーション
D3Netのバックボーンとしての評価に焦点を当てています。用いたデータセットはCityScapesという50の都市で自動車前方の映像を写した5000枚の画像で構成されたデータセットです。各画像で対応する物体クラスが次のようにピクセルレベルにアノテーションされています。評価は19のクラスについてクラス単位のIoUの平均mIoUです。
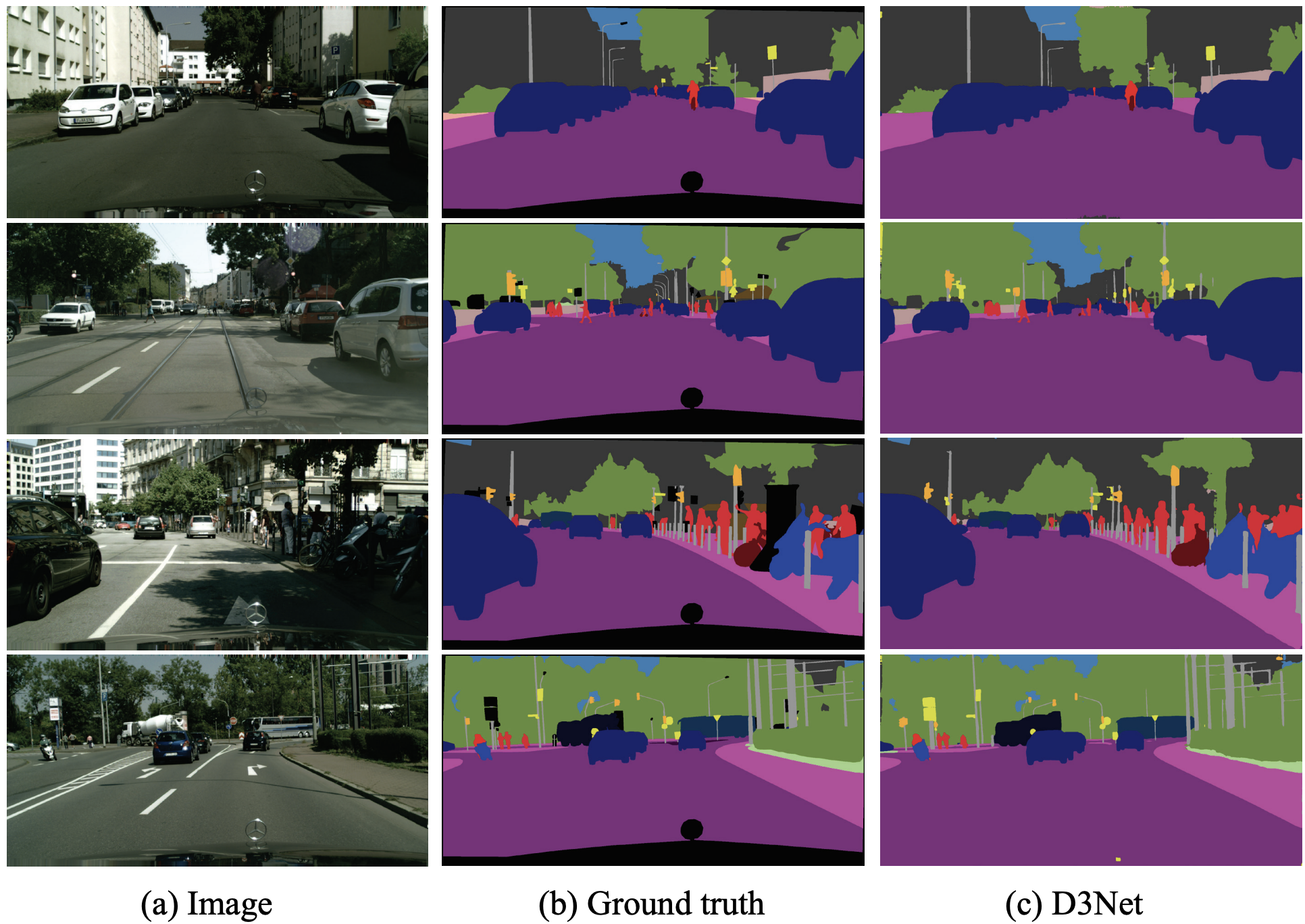
アーキテクチャ
D3Netは2つのモデルを想定しています。D3Net-Sは(M,L,k,c)=(4,8,36,0.2)で各D3 Blockの出力チャンネル数は(32,40,64,128)です。D3Net-Lは(M,L,k,c)=(32,48,96,192)です。
結果
アブレーションがこちらの表です。multidilated convolution(D2 Block)の有効性を示すために、標準的な畳み込み(without dilation)・標準的な膨張畳み込み(standatd dilation)でも学習しています。またD3 Blockの有効性を示すために、同程度のパラメータ数を持つDenseNet-133・DenseNet-189を用意し、DenseBlockと比較しています。
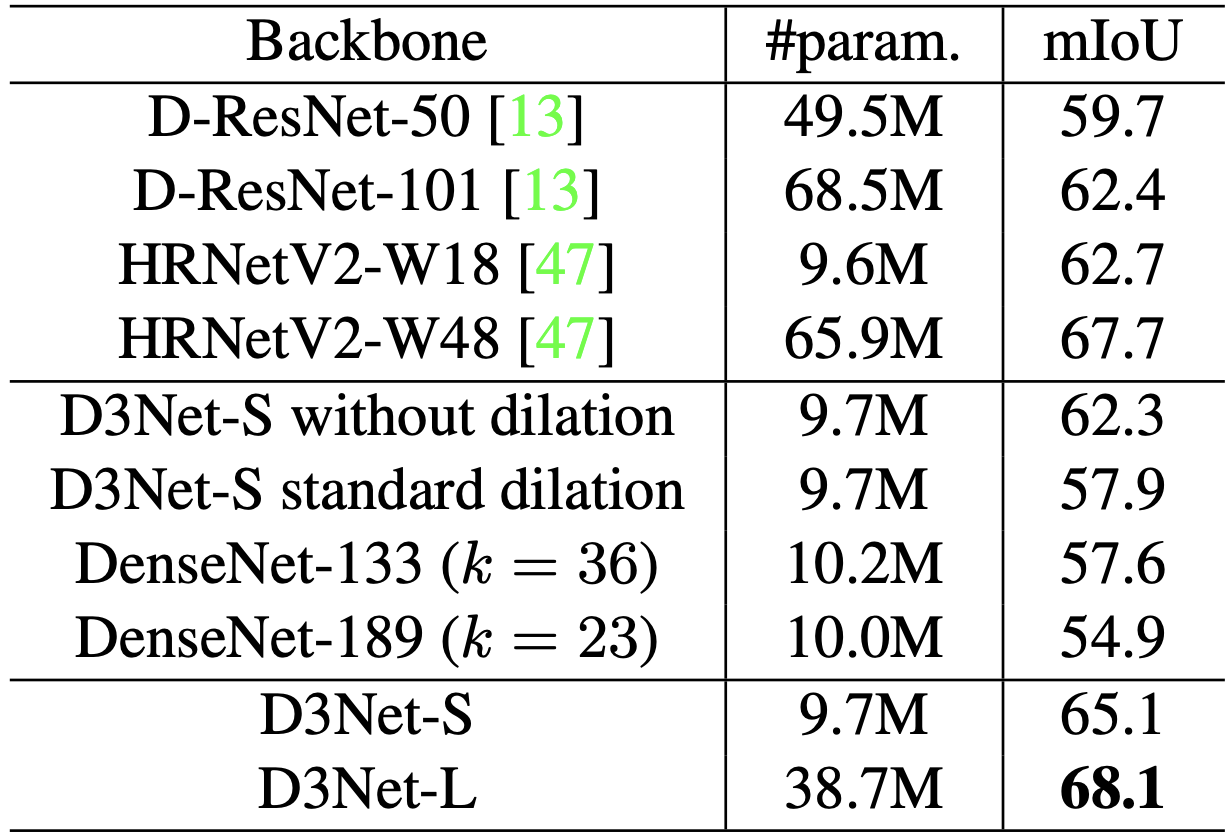
D3Net-Sはwithout dilationやstandard dilationより大幅に性能が良く、mIoUを向上させています。また興味深いことにstandard dilationはwithout dilationよりも精度が低下しました。これはエイリアシングの問題によるものと考えられます。提案手法はエイリアシングを回避し、見事精度向上に繋げることができました。またD3Netと同程度の規模のDenseNetに対して高精度を達成し、dilated convによる受容野の拡大や効率的なパラメータ数により高いkを設定できるようになったD3Netの有効性を示しています。
D3Net-Lは論文掲載当時のSoTAモデルHRNetV2W48よりも少ないパラメタータ数で全てのベースラインを超える最高精度を達成しました。
続いてSoTAモデルとの比較です。D3Net-Lのみモデルの規模の公平性を保つため学習回数を増やしています。
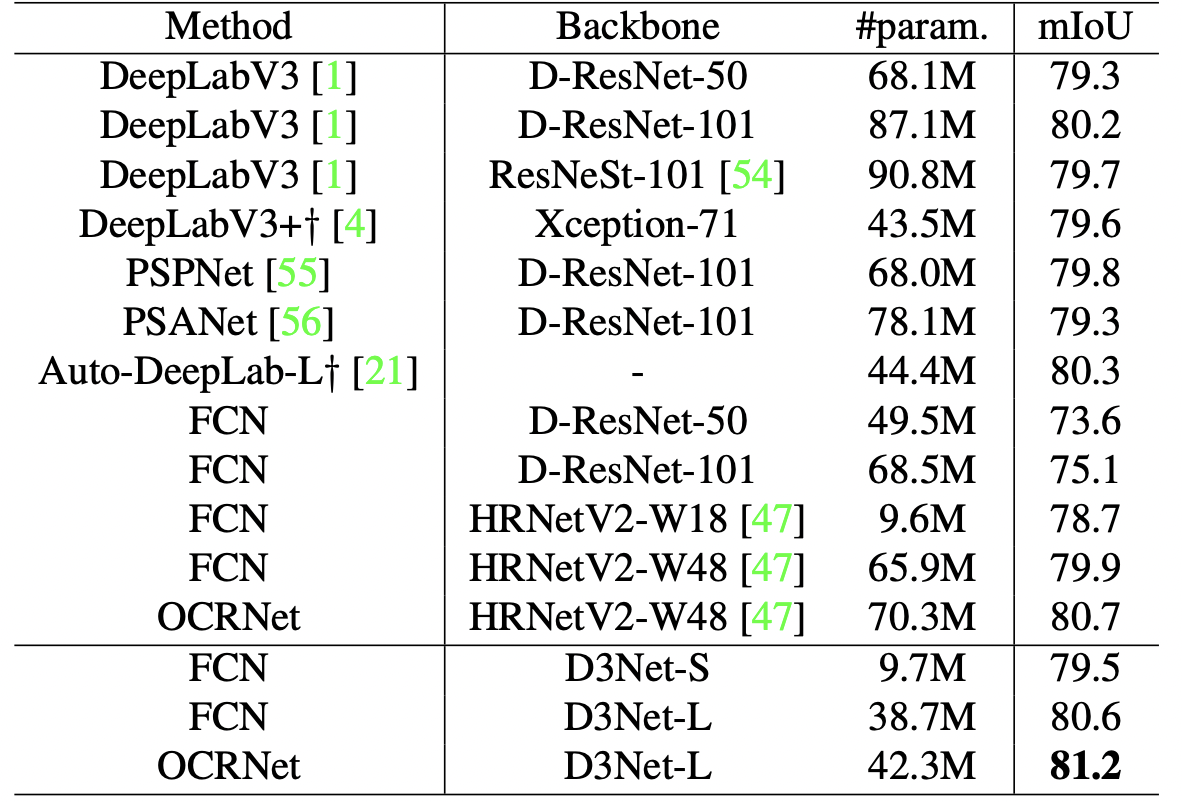
DCNベースの手法とOCRNetベースの手法がありますが、FCNベースではD3Net-LはHRNetV2p-W48やD-ResNet-101、DResnet-50よりもはるかに少ないパラメータ数で全てのベースラインより優れた性能を示しました。OCRNetベースではD3Net-Lは更に性能が向上し、論文掲載当時最高精度の81.2%を達成しました。
音源分離
音源分離は音声信号を音源毎に分離するタスクです。本論文が使用するMUSDB18データセットでは約10時間150曲の音源を、ベース・ドラム・ボーカル・Otherの4つの音源に分離することが目的です。
評価
多くの手法は短時間フーリエ変換(STFT)により時間領域の信号を時間窓単位の周波数情報に変換し、画像として扱っています。つまりこのタスクもセグメンテーションタスクに似ており、2次元のSTFTマップに対して各音源の振幅を推定するタスクとなります。セグメンテーションと異なる点もあります。単なる分類ではなく振幅を推定する回帰問題であることや、最もカメラに近い前面の物体しか映らない画像と違い、音声信号は複数の音源の複雑な重なりであること、STFTでは周波数についてグローバルな不変性を持たないことなどが挙げられます。
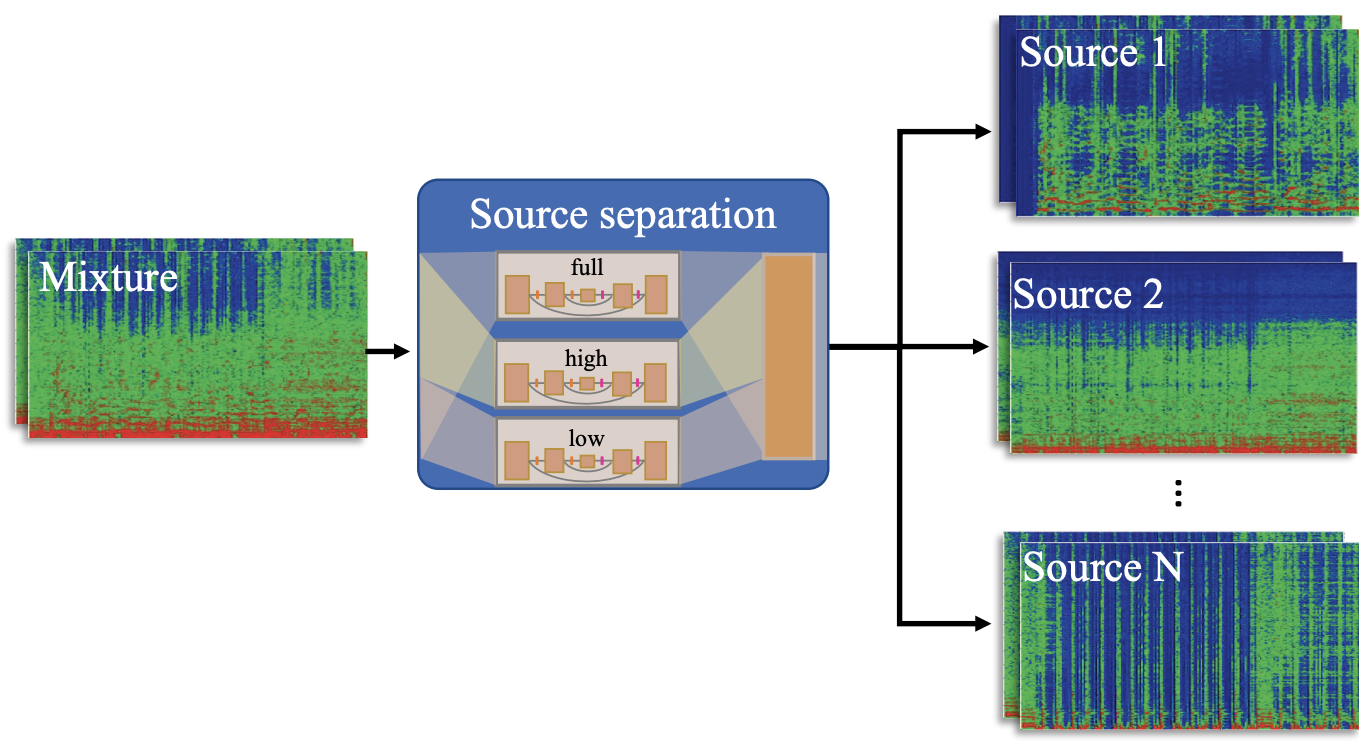
アーキテクチャ
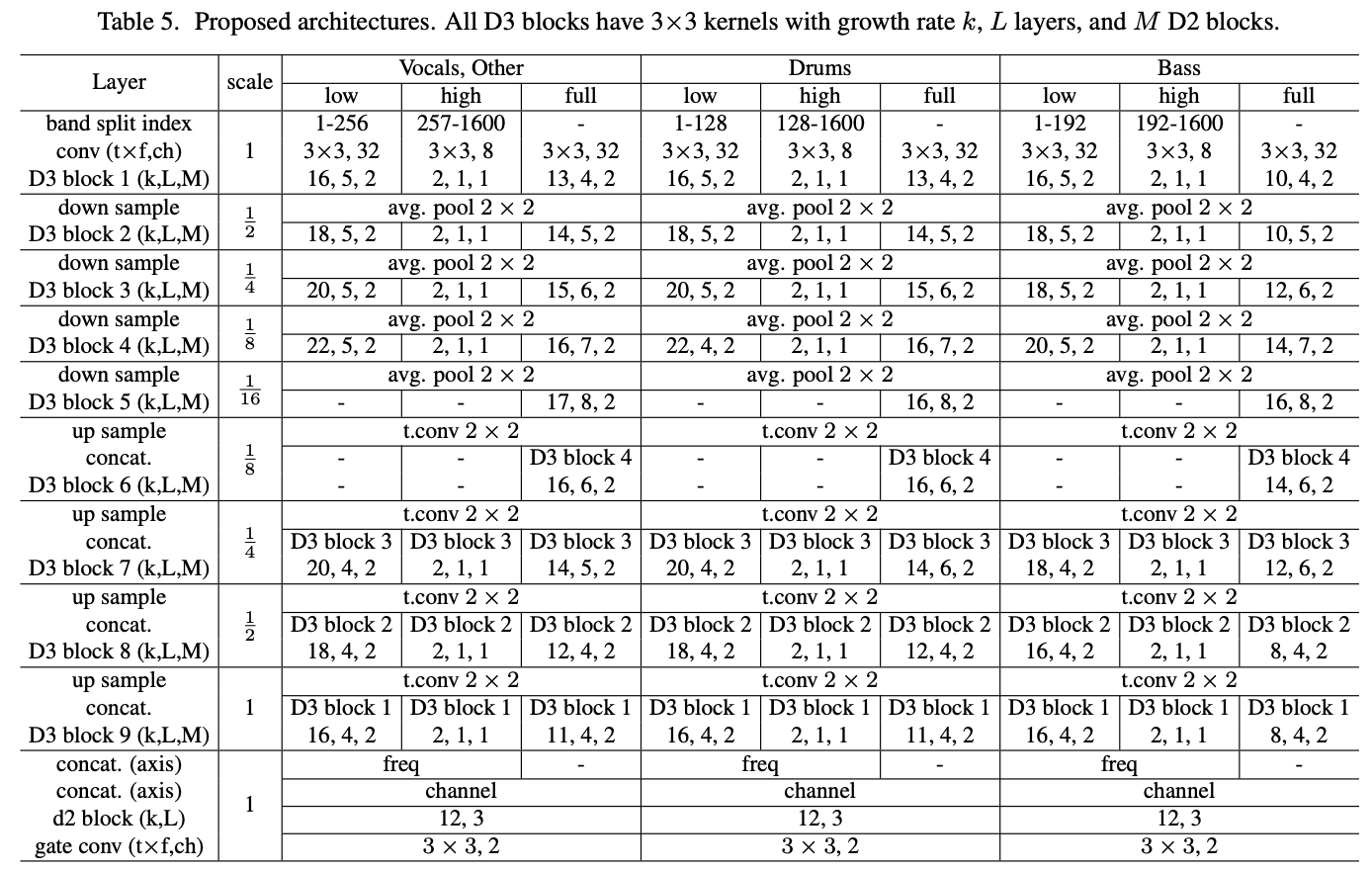
D3Netは各4つの音源それぞれに対してネットワークを用意し、スペクトログラムを学習・推定します。ネットワークの出力は損失はMSEです。またベストモデルに従って周波数バンドはlow・high・fullと3つで分けて学習させます。つまり、D3Netは4つの音源毎3つのバンドで学習させる計12個のネットワークを用います。ネットワークの出力はmultichannel Wiener filter(WMF)という一般的に用いられる周波数領域の音源分離手法に用いられ、最終的な分離結果を得ます。モデルの詳細は以下の表の通りです。
結果
提案手法とSoTAモデルのSDR(signal-to-distribution ratios)を示します。 周波数領域で処理する手法と時間領域で処理する手法(*)があります。D3Netはボーカル・ドラム・伴奏(Acco)に対して最高精度を示しました。Accoはドラムやベース・Otherの合計です。4つの楽器の平均のSDRは6.01dBであり、TAK1とUHL2などのSoTAモデルを含む全てのベースラインより優れる結果となりました。
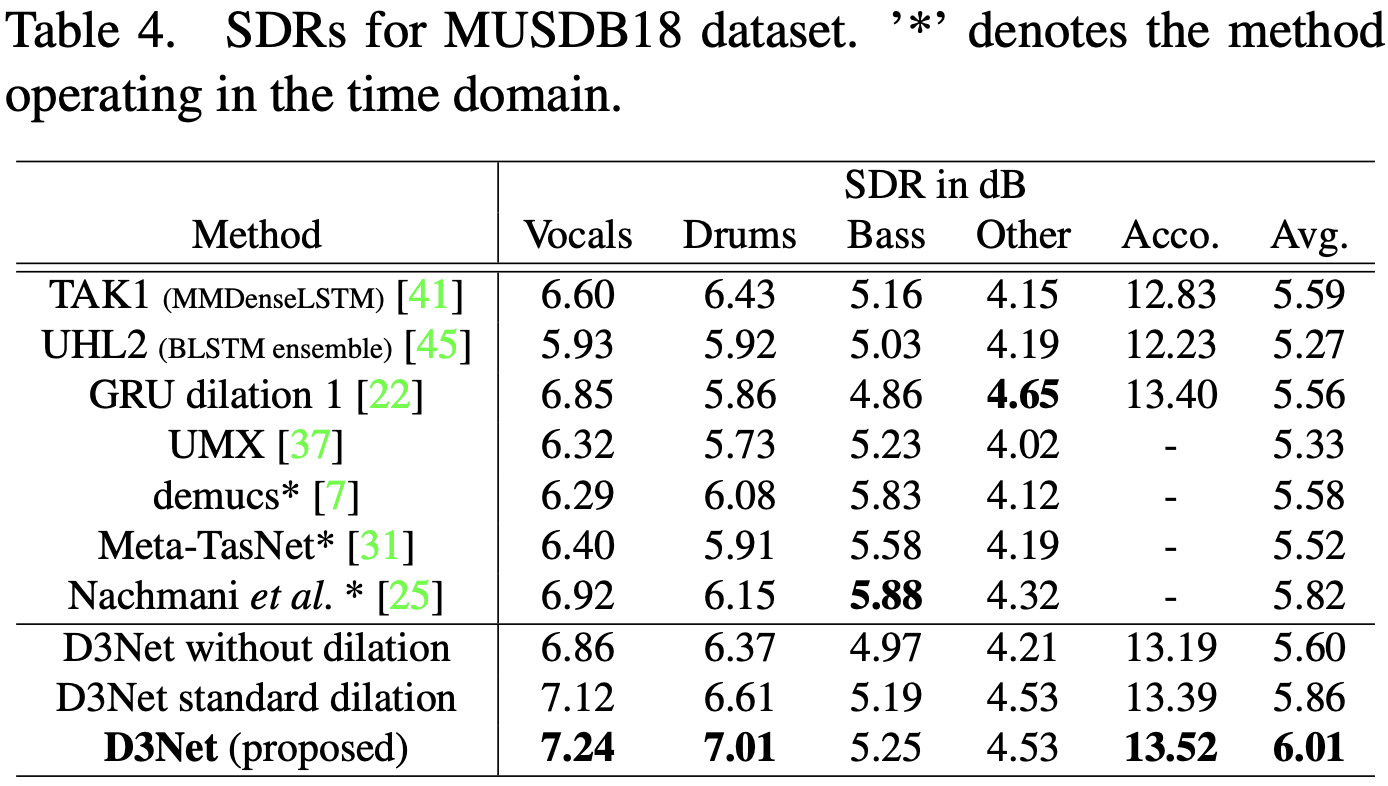 LSTMを用いた受容野の拡大を行うTAK1に対して、multidilated convとそのネスト構造を採用したD3 Blockの有効性が分かります。またGRU dilaltion1はアップサンプリングやダウンサンプリングを用いずにdilated convやdilated GRU unitで構成されていることから、複数の解像度で密に処理するD3Netの有効性が示されました。
LSTMを用いた受容野の拡大を行うTAK1に対して、multidilated convとそのネスト構造を採用したD3 Blockの有効性が分かります。またGRU dilaltion1はアップサンプリングやダウンサンプリングを用いずにdilated convやdilated GRU unitで構成されていることから、複数の解像度で密に処理するD3Netの有効性が示されました。
また低音については時間領域の方が復元が容易なため、既存手法に優ることはできませんでした。しかし周波数領域の手法ではD3Netが最も性能が良いことが分かります。
音源分離のアブレーションではwithout dilationよりstandard dilationの方が良い結果となりました。いずれにしても提案手法のmultidilated convは標準の畳み込みや標準のdilated convを大幅に上回り、エイリアシング問題を処理する重要性を示す結果となりました。
所感
dilated convは間の死角がどう影響するのかが気になっていましたが、エイリアシングという観点で解決する考えはなかったため良い知見となりました。
ところでdilated convよりも柔軟に動的にサンプリングするDeformable Convolution(変形可能な畳み込み)がありますが、ここではエイリアシングがどう影響するのかが気になります。以前紹介したInternImageはViTに性能を近づけるための戦略としてDCNv3を使用していますが、エイリアシングの問題が起こらないのか調べてみたいです。
まとめ
今回は高密度推定タスクにおいて複数の解像度を高密度に学習する重要性を示し、D3Netを提案しました。標準的なdilated convで起こるエイリアシングの問題を解決しつつ、密なskip-connectionを組み合わせ、ネスト構造を取ることで高密度推定タスクで高精度に機能します。
セマンティックセグメンテーションと音源分離の実験により、異なるタスクとドメインにおける提案手法の有効性と一般性を示し、少ないパラメータ数で最先端のバックボーンを凌駕しました。
本論文は、CNNを設計する際に、複数の解像度で局所的な情報と大域的な情報を密に結びつける頻度について重要な知見を示すと主張しています。これからの発展が楽しみです。



この記事に関するカテゴリー


