
生のデータを共有せずに高精度な画像分類を実現!Model-Contrastive Federated Learningを紹介
3つの要点
✔️ 連合学習に対照学習を導入することで高精度な画像分類を実現
✔️ 対照学習においては,データ拡張を活用したSimCLRの発想を元にした概念を導入
✔️ モデルの出力同士の比較を導入し精度を向上
Model-Contrastive Federated Learning
written by Qinbin Li, Bingsheng He, Dawn Song
(Submitted on 30 Mar 2021)
Comments: Accepted by CVPR 2021
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
連合学習の概要
連合学習とは,データセットが複数のクライアントまたはデバイスに分散しているような状況下において,それらのクライアントまたはモデルごとに機械学習のモデルを用意し,学習を行った上で,結果として得られる各モデルの更新結果(重みの差分)を共有することによって機械学習モデルの開発を行う手法です.
連合学習が導入された経緯
連合学習が登場する以前においては,データが分散しているような場合においてはそれらのデータを学習に先立ってデータを中央サーバーに集約させる必要がありました.
しかし,従来手法においては各媒体が中央サーバーに生のデータを送信するという過程を必要とするため,個人情報や機密情報が含まれているようなデータを扱う際に情報が流出するというリスクが存在していました.また,一箇所にデータが集約されている中央サーバーは攻撃の対象を受けやすいことから,セキリュティに脆弱性が生じるという問題点がありました.
さらに,近年人々のプライバシーに対する意識が向上したことに伴って,従来のようにデータを集約してから機械学習を行うという手法に抵抗を感じる企業や組織が増加するようになりました.そのような状況下において提案されたのが連合学習という手法です.
連合学習は,分散しているデータそのものの共有を行うことなく機械学習のモデルを開発することができる手法であり,近年大きな注目を集めている手法となっています.
連合学習の類別(水平型連合学習と垂直型連合学習)
連合学習は,複数の媒体が持つデータのうち,どの部分が共通しているかという基準に基づいて水平型連合学習と垂直型連合学習に類別することができます.
水平型連合学習とは,複数の異なる媒体が共通の特徴量を持つようなデータである場合に用いられる連合学習の手法です.例えば,複数の異なる病院の患者が持つ属性のうち,年齢や性別といった基本的な要素はどの病院でも共通していると考えられます.そのため,それらのデータを統合する際には水平型連合学習が活用されています.
一方で垂直型連合学習とは,複数の異なる媒体が共通の対象を持つようなデータである際に用いられる手法です.例えばあるユーザーが,ある病院とある金融機関の二つに属しており,それらのデータを統合する際には垂直型連合学習が活用されています.
本論文では水平型連合学習が導入されているため,この記事では水平型連合学習について詳しく説明します.
連合学習のアルゴリズム
前述したように,水平型連合学習は,特徴量が共通しているようなデータが複数組織に分散しており,それらを統合する際に使用されるモデルです.水平型連合学習のアルゴリズムは以下のようになります.
Step0:中央サーバーが所持するモデル(このモデルをグローバルモデルといいます)のパラメータをランダムな状態に固定します.
Step1:中央サーバーの所持するグローバルモデルを,連合学習に参加する各クライアントに配布します.
Step2:各クライアントは,自身が所持するローカルデータを用いて,配布されたモデルを活用した学習を行います.
Step3:各クライアントは,更新によって得られる更新の重みの差分を中央サーバーに送信します.
Step4:中央サーバーは各クライアントから集められたローカルモデルの情報を受け取り,それらの情報を元にグローバルモデルを更新します.
Step1~Step4の一通りの手順は一ラウンドと言われており,連合学習においては複数のラウンドを繰り返すことによって,徐々にグローバルモデルの精度を向上させていきます.
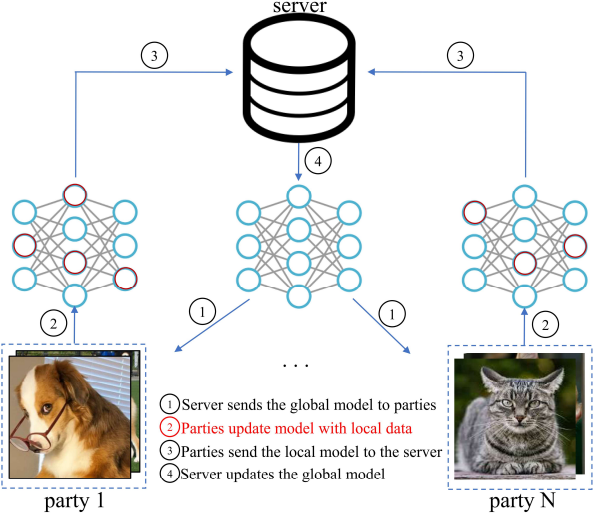
連合学習が最初に提案された論文においては,各クライアントから集められた損失関数の加重平均が最小となるようにグローバルモデルを決定していました.しかし,このモデルはクライアントが所持するデータが不均衡であるような場合に連合学習の精度が下がってしまうことが課題となっていました.
そのため,現在では,単にクライアントの重みの加重平均をとるのではなく,データセットが持つ性質に応じて損失関数に応じて補正項を加えるなどの改善手法が提案されています.(本論文で紹介しているMOONも,そのような改善手法の一つとなっています.)
連合学習の画像分類への応用
連合学習は表形式データの解析やテキストデータ分類などの分野で活用されている手法ですが,現在は画像分類の領域への応用が進んでいます.
しかし,画像データは表形式データやテキストデータなどのデータと比較して複雑かつ多様であり,クライアント間でそれらのデータは不均衡となりやすいという性質を持ちます.そのため,画像分類に連合学習を適用させるとグローバルモデルとローカルモデルが乖離してしまい,高い精度を出すことができないということが起こってしまう可能性があります.
そこで,それらの問題を解消するために,連合学習に対照学習を事前学習として導入するという手法が存在しています.
対照学習の概要
対照学習とは,最終的な分類結果が似ている画像同士は互いに類似しているということを活用した教師なし学習の手法の一つです.対照学習の損失関数は,同じクラスに属する画像のペア同士の類似性が高くなるように,異なるクラスに属する画像のペア同士の類似性が低くなるになるような関数となっており,この損失関数が最小となるように,機械学習を行います.
なお,対照学習を行うにあたっては,実際には画像そのものではなく,画像を特徴空間に射影した際に得られる特徴ベクトル同士の比較を行うことが一般的です.この特徴ベクトルは,クライアントが所持する画像に対して,CNNのエンコーダーにより特徴量の抽出を行うことによって得られます.
なお,CNNとは,画像分類に特化したニューラルネットワークモデルです.特徴量を抽出する畳み込み層と,情報を圧縮し,平行移動に対してロバスト性を保つように学習を行うプーリング層を持つことを特徴としています.有名なCNNのモデルとしては,AlexNetやGoogleNetなどが挙げられます.
対照学習の仕組み
対照学習は,教師なし学習の手法,その中でも自己教師あり学習という学習法の主要なひとつです.
教師なし学習は生成タスクによる手法や,識別回帰タスクによる手法,比較タスクによる手法など,さまざまなアプローチが存在しますが,識別・回帰タスクや比較タスクに分類される手法は自己教師あり学習手法と呼ばれることがあります.
「自己教師」という名称から分かるように,データ自体から教師の信号(ラベル)を作り出すという手法となっています.この手法はオートエンコーダによる画像生成や,自然言語処理における単語の埋め込み表現を学習する過程などにおいて活用されています.
自己教師あり学習は事前学習とファインチューニングを組み合わせた構造を持っており,学習において普遍性を高めつつも,さまざまなタスクに応用できる可能性のある分野です.音声認識や自動運転などの様々な分野に活用することが期待されています.
対照学習の代表例(SimCLR)の仕組み
教師がないのにも関わらず,画像同士の意味的な距離をどのように学習することができるのでしょうか.今回は対照学習の要点を説明するために,対照学習の代表例であるSimCLRというモデルを例に,対照学習の仕組みを紐解いていきます.
SimCLRは、ある特定の一つの画像を意図的に反転、または回転させた画像を用意して、同じ画像から由来するもの同士の距離が小さくなるように、そして異なる画像同士の距離が大きくなるように学習を行う対照学習のモデルです.つまり,同じ画像であった画像を反転や回転させた画像でも,同じ画像に由来するということを識別できるように学習を行うことを示します.このように,一つのデータから多様なデータを生成することをデータ拡張といいます.
対照学習の事前学習を行うことによって機械学習のモデルはデータが持つ多くの側面を考慮できるようになるために,分類のモデルの質は向上すると考えられます.SimCLRのモデルはシンプルでありながら高い性能を示すことから,対照学習の主流のモデルとなっており,自然言語処理や画像処理などの領域で広く使用されています.
SimCLRはNormalized Temperature Cross Entoropyという考え方を活用しています.その損失関数を以下の式に示します。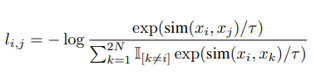
ここで、simというのはコサイン類似度、つまり特徴ベクトルの方向性がどれほど似ているかを表す関数となっています。
分子は、同じ画像から由来する特徴ベクトルの類似度が大きくなるということをきちんと学習できているほど損失関数が小さくなることを示しています。分母は、ある特定の一枚画像xkに対して、xk以外のすべての画像とのコサイン類似度を計算しており、異なる画像から由来する特徴ベクトルの類似度が小さくなるということをきちんと学習できているほど損失関数は小さくなることを示しています.
MOONの概要
この手法の精度をさらに一段階上げることに成功した、2021年に提案されたモデルであるModel Contrastive Federated Learning(通称MOONと呼ばれているモデル)の概要について解説します.
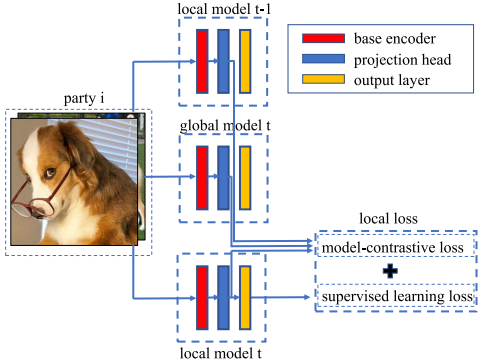
MOONの機構を図に示します.あるクライアントが所有している画像データに対して,三種類の機械学習モデル(上から順に,一ラウンド前のクライアントにおけるモデル,グローバルモデル,現在のローカルモデル)を通し.出力の比較を行っています.
赤色の層はCNNのエンコーダーであり,特徴抽出を行う層です.青色の層は表現学習専用の多層パーセプトロン層であり,特徴ベクトルをある次元(本論文では256次元)に変換する層です.黄色の層は最終出力としての分類結果の確率分布を表しています.多層パーセプトロン層とは,全結合層のみから構成されるニューラルネットワークモデルでのことで,シンプルでありながら複雑なモデルを学習できることで知られています.
MOONの損失関数の定義
先ほど述べたように、従来の画像分類の連合学習においては、あるクライアントが所持するある画像に対照学習を導入する(つまり,あるクライアント内の画像同士を一つの機械学習モデルに通し,予測される確率分布と真の確率分布を比較する)ことによって画像分類を行っていました.それに対して,MOONという手法では先ほどとは似て非なる異なる考え方で損失関数を導出し,従来の損失関数に加算しています.
具体的な損失関数は以下のようになります.なお,μとは事前に指定するハイパーパラメータです.
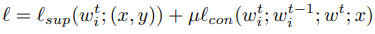
この損失関数においては,ある一つのモデルを元に対照学習を行った損失関数と,一つの画像を元に対照学習を行った損失関数の加算を行っています.
式の後半においては,特定の一枚のある画像に対して,クライアントのモデルを通して得られる出力と、そのクライアントにおける一ラウンド前のモデルの出力の対照学習を行うことを示しています.
おそらくここがこのモデルの一番重要な部分であると思うので、概念の対比図を用いて改めて説明します.
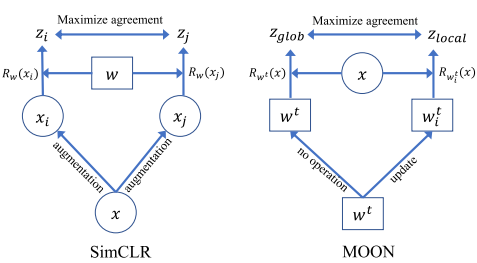
左図に示しているのがSimCLRの手法で、あるクライアントにおける画像同士を一つの機械学習モデルを通し,画像の類似度の導出を行なった図です。右図に示しているのがMOONの手法で、一つの画像を複数の異なる機械学習モデルに通し,その出力の比較を行っています.この図を見れば分かるように,MOONはSimCLRと似て非なる概念を導入していることが分かると思います.
MOONのモデルの決定方法
連合学習におけるグローバルモデルは,各クライアントの平均損失関数を重みづけした値をあらゆるクライアントについて足し合わせ,その損失関数が最小となるように学習を行っています.
MOONのアルゴリズムの決定方法

MOONにおけるモデルの更新のアルゴリズムを改めて示すと図のようになります.ここで,Tは総通信回数,Nはクライアントの総数を表しています.Eは,ローカルエポック数,ηは連合学習における学習率,τは事前に指定するハイパーパラメータを表しています.
実験結果
画像分類におけるMOONの精度を確かめるために,既存の手法であるFed Average, Fed Proxをはじめとした連合学習の手法と画像分類の精度比較を行いました.画像のデータセットは,CIFAR-10,CIFAR-100,Tiny-ImageNetという三種のデータセットを活用しました.この三つは,いずれもコンピュータビジョンにおけるベンチマークである自然画像データセットです.
画像分類のベースとしてはRes-Net50を用いています.なお,Res-Netとは,画像分類に特化した機械学習モデルです.スキップ接続という機構が導入されたモデルであり,層を深くしていくと関数の最適化が困難になることで精度が落ちてしまうデグレーデーションという問題を,層を飛ばす処理を行い解消しています.この考え方は様々な深層学習モデルに導入されています.
仮想的なクライアントの数を10として,実験の試行回数を3回行い,平均値と標準偏差を導出した結果を,以下のように示します.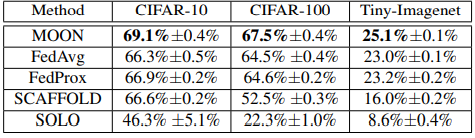
この実験より,いずれの画像データセットにおいても,MOONは既存の手法よりも画像分類において高い精度を出すことが分かりました.
まとめと今後の展望
連合学習とは,データが分散しているような状況下において,プライバシーを保護しつつも少ないコストで機械学習を行うことができる手法であり,この手法を導入することでプライバシー保護を実現することができるだけでなく,モデルを更新する際に中央サーバーにデータを送信する際の通信コストを削減することができるようになると考えられています.
また,リアルタイムにモデルを更新することができるために,柔軟性のある学習を行うことができると考えられています.
本論文ではMOONという画像分類に特化した連合学習のモデルが提案されていますが,このモデルは既存の連合学習モデルの精度を大きく上回ることが示されました.
MOONは,医療画像分類,物体検出などの様々なコンピュータビジョンに対して応用されることが期待されています.さらに,MOONは入力データを画像に限定していないことから,視覚画像以外の様々な領域にこの手法が応用されうる可能性について示唆されています.また,MOONに限らず自己教師あり学習を活用した手法は今後においても重要な役割となると考えられており,今後の研究に注目が集まります.






この記事に関するカテゴリー





