
あらゆるディープフェイクを見破る「Face X-ray」Microsoftが取り組むSOTAな技術とは?
3つの要点
✔️ブレンドされた顔画像の痕跡に着目した汎用的なディープフェイクの検出モデルを提案
✔️ブレンドされた痕跡を効率的に見つける Face X-ray という特徴情報を導入
✔️学習時にディープフェイクデータを必要としない自己教師あり学習を実現
Face X-ray for More General Face Forgery Detection
written by Lingzhi Li, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, Fang Wen, Baining Guo
(Submitted on 31 Dec 2019)
subjects : Computer Vision and Pattern Recognition (cs.CV)
この記事について
近年、ある人物の顔を別の人物のものに置き換える、顔偽造技術が話題になっています。
最初に注目されたのは、2017年にRadditで Deepfakes という匿名ユーザーが投稿した、顔偽造されたポルノ動画と言われています。これ以降、悪意のある偽画像がたくさん投稿されています。
| 時期 | コンテンツ |
| 2018年4月 | オバマ元大統領の演説動画 (youtube.com) |
| 2019年5月 | 民主党のナンシー・ペロシ下院議長の演説 (youtube.com) |
| 2019年6月 | Facebook CEO ザッカーバーグ氏の偽動画 (youtube.com) |
偽物とは見分けがつきにくく、勘違いする人も多くいます。情報の信憑性や個人情報の安全性に対して大きな不安が広がっています。
そのため、顔偽造を検出する技術の研究開発が盛んに行われています。このような状況に対して、2019年秋には、Facebook が中心となり、AWS、Microsoft などと 顔偽造検出技術を競う Deepfake Detection Challenge を企画しました。
今回は、いま注目分野である顔偽造検出において、Microsoft Research Asia が報告した最新論文をご紹介します。
さまざまなディープフェイクを検出する汎用性の高いモデルを提案
この論文では、2つの人物画像をブレンドして作成された顔の偽造を検出するために、新たに Face X-ray という特徴情報を導入し、ブレンドの痕跡(境界線)を検出しています。
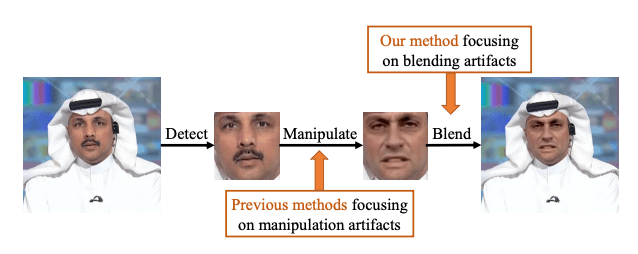
一般的な顔偽造技術は、上図のように3ステップで構成されています。
- 顔の検出(Detect)
- 顔の合成(Manipulate)
- 合成した顔を元の画像にブレンド(Blend)
既存のディープフェイクを検出する技術は、2つ目のステップに注目しています。画像がどのように編集されているのか、そのパターンを学習させることで、ディープフェイクを検出します。この方法では、ディープフェイクの手法で作成された偽画像を学習データに使います。
この方法は、学習させたディープフェイクの手法は、高い精度で検出できますが、学習させていない新規のディープフェイクの手法に対しては、精度が著しく低下することがわかっています。
この論文では、(ブレンドされている場合は)3つ目のステップに着目し、ブレンドの痕跡を見つけることで、2つ目のディープフェイクの手法によらず、汎用性の高い検出モデルが作れるとしています。
人の目ではわからない画像に隠れる差異
ディープフェイクの技術向上によって、人の目で見ても真偽の見分けがつかなくなっています。どこで画像が貼り合わされているのか、一見しただけではわかりません。
しかしながら、実は、見かけの色や形が同じように見える画像でも、撮影機材(センサー、レンズなど)や画像処理(圧縮処理など)などによって、画像データにわずかな違いが生じます。人の目では見えないが、画像取得プロセスで生じる根本的な違いが明らかになります。
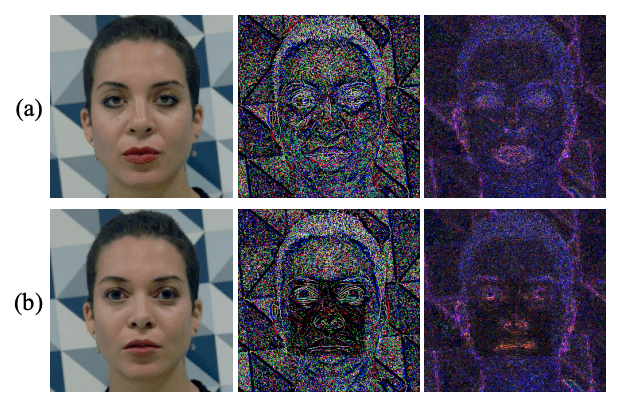
この論文では、Face X-ray という特徴情報によって、ブレンドで生じる画像内の差異の境界線と位置を検出します。
Face X-ray の正体とは?自己教師あり学習の方法とは?
今回のモデルでは、ブレンド箇所の検出に焦点を当てています。そのため、ブレンド画像を生成し、それに対応する Face X ray を自動生成することができれば、特殊なディープフェイク画像を集める必要なく、自己教師あり学習が可能になります。
この論文では、具体的に3つのステップでブレンド画像と Face X-ray を生成しています。
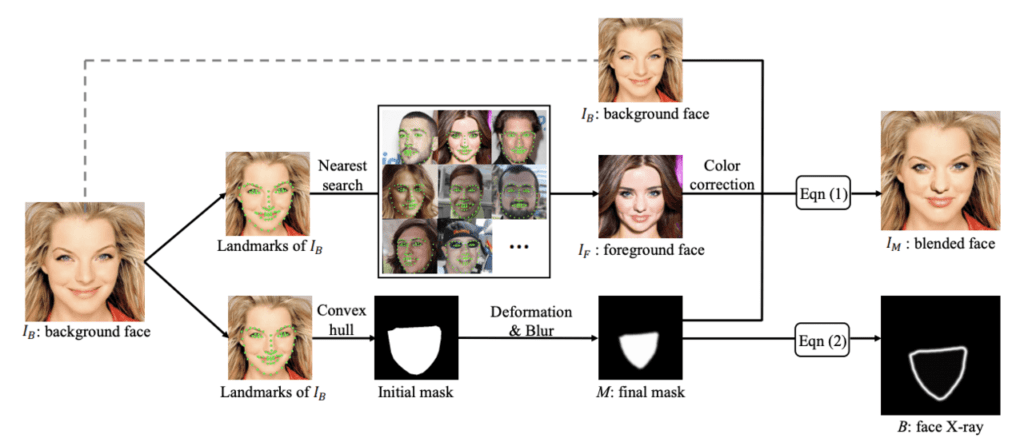
- ベースとなる画像(IB)が与えられると、IB とのブレンドに使う画像(IF)をあらかじめ用意したデータベースから探します。このとき、顔を探す基準は、ランドマーク間のユークリッド距離が一致以内の近さとなるものとします。また、データのランダム性を高めるために類似度の高い上位100個の中からランダムに IF を選びます。
- ブレンド領域の決定と Face X-ray の元になるマスク(M)を生成します。まず IB から取得したランドマークが内包されるようにマスクを定義し、ブレンドしやすい形に変形やぼかしの処理をします。
- IB, IF, M が得られると、式(1)から ブレンドされた画像(IM)が生成されます。
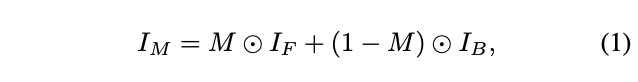 ここで、Mのピクセル値は 0.0〜1.0のグレースケールで表されます。なお、ブレンドの際には、IB の色と一致するように、IF に対して色補正を適用しています。また、式(2)から Face X ray(B)が生成されます。
ここで、Mのピクセル値は 0.0〜1.0のグレースケールで表されます。なお、ブレンドの際には、IB の色と一致するように、IF に対して色補正を適用しています。また、式(2)から Face X ray(B)が生成されます。
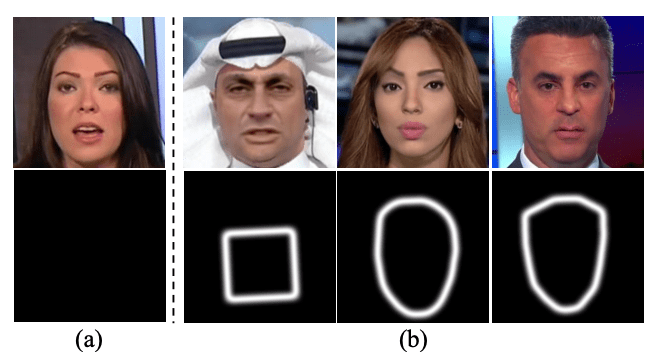
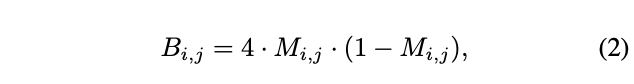 入力画像がブレンドされていなければ、B はすべてのピクセルで0となるように定義されます。
入力画像がブレンドされていなければ、B はすべてのピクセルで0となるように定義されます。
Face X-Ray を使ったディープフェイク検出モデル
学習データセットとして、画像(I)、その画像に対応する Face X-ray(B)、画像(I)のブレンドの有無(c)のセットを用意します。D = {I, B, c} 。
ネットワークでは、入力された画像(I)に対して、Face X-ray(B)を出力し、このFace X-ray(B)に基づいて、ブレンドされているかどうかの確率を算出します。
従来のモデルと比べても簡単で高精度!SOTAなモデル
汎用性を検証するために、学習データに含まれないデータセットに対する精度の減少幅を調べています。モデルはHRNet/Xceptionを使って実験をしています。
以下の表では、各学習データに対するディープフェイクのAUCを算出しています。
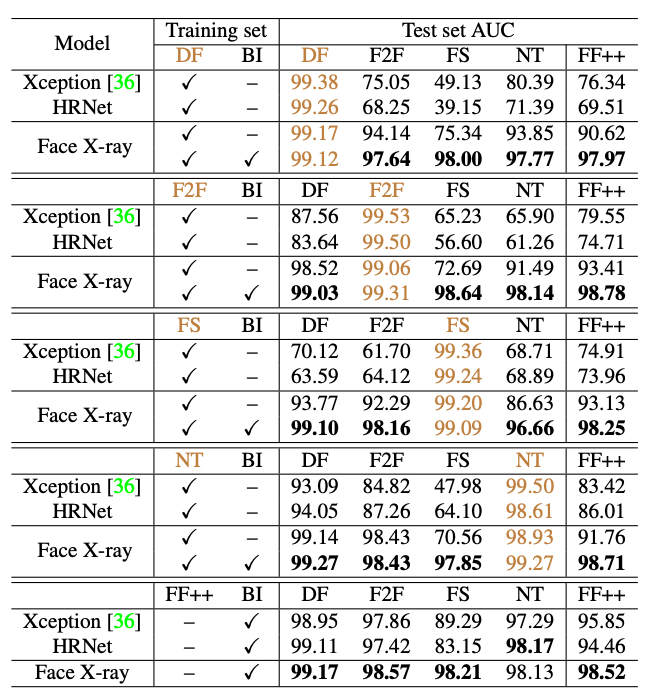
実験の結果、いずれのモデルでも学習データと同じデータセットに対しては、99%を超える精度が得られていますが、学習データに含まれていないデータセットに対しては、10%以上も精度が低下しています。
これは、学習データで使われたディープフェイクの手法に対して、オーバーフィットしていると考えられます。
しかし、今回提案されたモデルでは、学習データに含まれていないデータセットに対しても、ほぼ同等の精度となっています。また、自己教師ありデータのみを使用した場合でも、高い検出精度を達成できることを示しています。
汎用化という観点では、これまでも研究されていました。それぞれのディープフェイクの手法に対応する学習データを使う従来方法では、実運用には、とても労力がかかります。新しいディープフェイクの技術が開発されるたびに、モデルを再学習させなくてはいけません。
そのため、近年ではこの他にも各種ディープフェイクに対して汎用性の高い検出モデルをが報告されています(下表)。
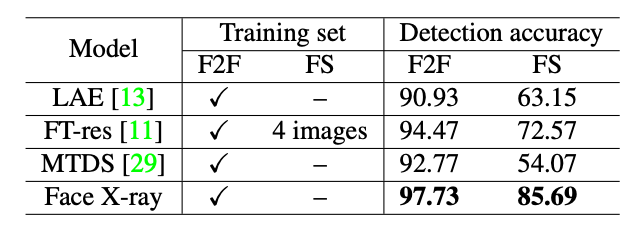
しかし、Face X-ray を用いて、ブレンドによる画像の差異に着目するモデルが最も汎用性が高いことがわかりました。
今後の課題
実験では一般的な検出で満足のいくパフォーマンスを実証しましたが、この手法には、2つの技術的な限界があるとされています。
- ディープフェイクのうち、画像がブレンドされている場合にのみ有効な点です。
したがって、画像が完全に合成されている場合、この方法が正しく機能しない可能性があります。ただし、誰かが言っていないことや行ったことのビデオなどの偽のニュースは、通常、後処理ステップとしてブレンドする必要があります。これは、これまでブレンドせずに、目的のターゲット背景を持つ現実的な画像を完全に生成する可能性が低いためです。私たちは確かに、これらの多数の混合偽造を検出する有望な方法を提供します。 これに対しては、より汎用的なモデルの研究開発やほか手法との併用によって、実用に耐えうる汎用性の高いモデルが求められます。 - Adversarial Samples に対する脆弱性がある点です。このモデルにおいても、Adversarial Samples に対する脆弱性は存在します。
このほかに、他の検出モデルと同様の問題を抱えています。例えば、低解像度の画像では、十分な特徴量を得られないため、検出精度は低下します。FF++において、High Quality(低圧縮率)の画像と Low Qualiry(高圧縮率)の画像で検出精度を比較すると、以下のようになります。
| Datasets | AUC |
| FF++ / High Quality(低圧縮率) | 87.35% |
| FF++ / Low Quality(高圧縮率) | 61.6% |
これに対しては、Data Augumentation などでいくらか軽減することはできると思いますが、根本的な解決には、ディープラーニングに対するより理論的な検証が求められます。
まとめ
この論文では、ほとんどのディープフェイクの手法に共通して発生するブレンドによる差異のみに注目することで、ディープフェイクの手法によらない、汎用性の高い検出モデルを実現しています。
また、このブレンドによる差異を表現するために Face X-ray というシンプルなグレースケール画像を導入したことで、学習データも生成しやすくなっています。そのため、従来の手法のように、ディープフェイクの手法に応じた学習データを用意する必要はなく、自己教師あり学習が可能になっています。





この記事に関するカテゴリー






