
DeepFoids:深層強化学習を用いた魚の群行動シミュレーション
3つの要点
✔️ 色々な環境に適応した魚の群行動を深層強化学習により自律的に獲得する手法を提案
✔️ 提案手法とUnityによるシミュレーションを用いて本物と酷似した合成データセットを作成
✔️ いけすの中の様々な種類の魚を数える深層学習モデルの学習に成功
DeepFoids:Adaptive Bio-Inspired Fish Simulation with Deep Reinforcement Learning
written by Yuko Ishiwaka , Xiao Steven Zeng, Shun Ogawa, Donovan Michael Westwater, Tadayuki Tone, Masaki Nakada
(Submitted on 01 Nov 2022 (v1), last revised 24 Dec 2022 (this version, v2))
Comments: NeurIPS 2022
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
深層強化学習(DRL)を用いて魚の群行動を自律的に生成する手法を提案しています。これにより、個体密度に応じた複数の明確な集団行動パターンを実現しました。そして、Unityによる環境シミュレーションを用いた高品質な合成データセットを作成することで、いけすの中の様々な種類の魚を数える深層学習モデルの学習に成功しました。
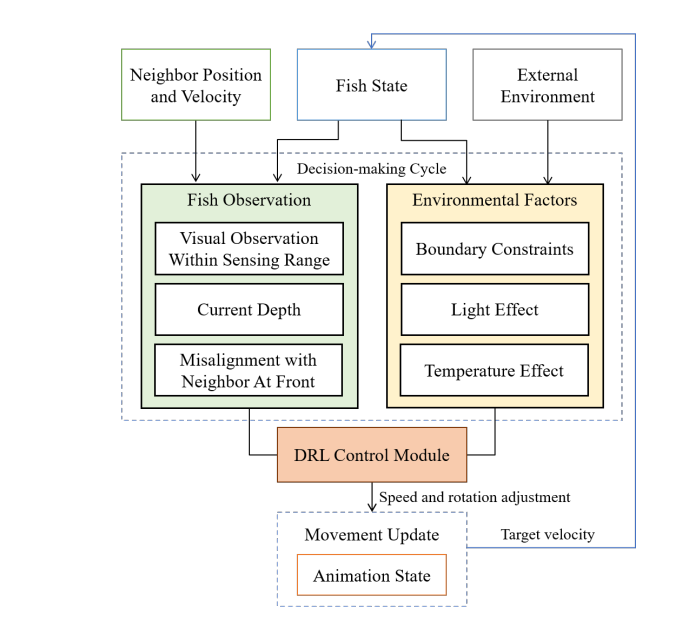
魚は隣接する魚の快適な距離内に留まり、進行方向を前方の隣接する魚の方向と一致させるといったことが挙げられます。他にも、ケージ内の魚は支配的なグループと従属的なグループに分かれており、支配的なメンバーが従属的なメンバーに積極的に接近して攻撃的な行動を始めること等があります。これらの要因は各時間ステップtにおける魚の速度∆$v_t^f$を生成する制御方針を学習する過程に組み込まれています。(詳しくは後述)
また、魚は光量と水温の好みの範囲を持っており、快適な範囲にとどまるように鉛直位置を変化させます。この論文ではそれらを∆$v_{light}$と∆$v_{temp}$として表現しています。上記の構成要素に加え、魚の環境変化に対する応答の遅延を模倣するために、魚の意思決定間隔をフレームワークに統合します。シミュレーションの意思決定間隔∆$t_{res}$は、先行研究に基づいてあらかじめ定義されています。シミュレーションステップの時間間隔∆$t_{sim}$が与えられると、魚は⌊∆$t_{res}$/∆$t_{sim}$⌋ステップごとに環境の観察結果を更新し、更新の間に行動を起こします。そして、各シミュレーションステップで適用する累積速度(∆$v_t^a$)は、以下のように導出されます。
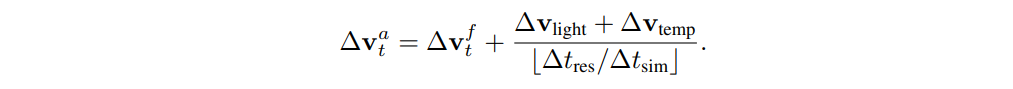
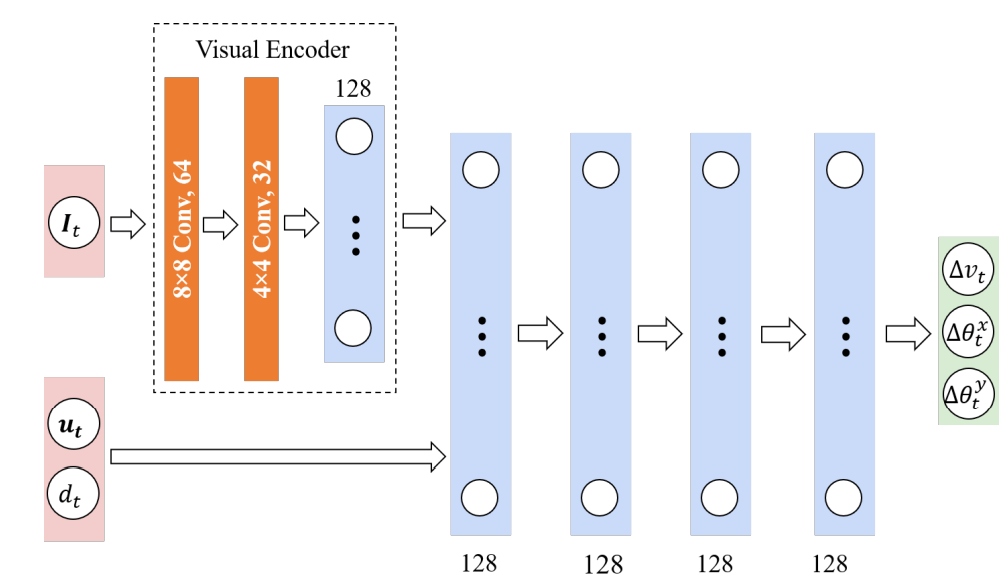
各状態$s_t$は、タプル($u_t,d_t,I_t$)で表現します。$u_t$は現在の時間ステップtにおけるエージェントとその前方にいる最近傍の魚との前進方向の差、$d_t$は水面に対するエージェントの深さ、$I_t$は視覚情報に伴う観測についてのテンソルです。魚エージェントは、探索の間、実際の魚の感知領域を模した空間グリッドセンサで視覚観測を収集します。視覚観測は、グリッドの幅、グリッドの高さ、チャンネル数を次元とする3次テンソルです。幅と高さはグリッドの解像度によって定義され、34×20に設定されています。魚の感知範囲$d_{sense}$内の最も近い検出物体からエージェントまでの距離(正規化)と、物体タイプ(魚、境界、障害物など)のワンホットエンコーディングが6チャンネルあります。$d_{sense}$はブリ(Yellowtail)では2体長、サーモンとマダイでは3体長で設定されています。すべての状態成分はエージェントのローカル座標系で計算され、原点は体の中心に位置し、z軸は魚の向きと平行です。
行動$a$は、速度(Δ$v_t$)と、x軸(∆$\theta_t^x$ )とy軸(∆$\theta_t^y$ )に関する回転角です。z軸の回転角は不自然な挙動を避けるため、小さな角度 $\theta^{zt}$で固定しています。また、∆$v_t$ はケージ環境で許容される最大速度 ∆$v_{max}$ で固定されます。また、方策のネットワークの構造は下図のようになっています。
Reward:
各時間ステップにおける報酬$r_t$は、衝突を避けながらも群行動を促すよう以下に定義されます。それぞれ1つずつ解説していきます。
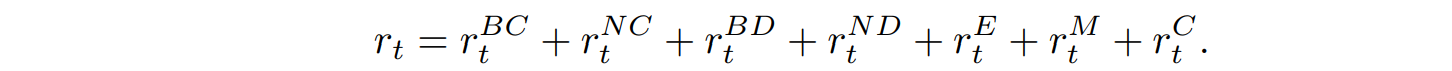
$r_t^{BC}$はケージの壁や水面などの空間的境界への衝突によるペナルティを表します。境界衝突が発生した場合は-300、それ以外は0という固定値です。
$r_t^{NC}$は近傍魚との衝突に関連するペナルティを表します。重み$w^{NC}$ を用いて与えられ、衝突したエージェントの数$N_{hit}$ に応じて累積されます。
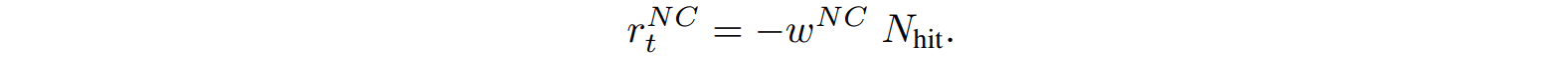
境界回避報酬$r_t^{BD}$は、検出された空間境界から距離を置くように促します。その値はエージェントの感知範囲$d_{sense}$、検出された境界の数$N_{bnd}$ 、境界 i までの距離$d_i$ 、境界回避重み$w^{BD}$ に依存します。
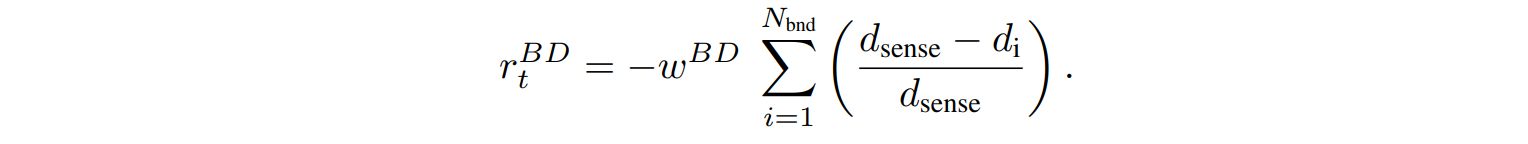
$r_t^{ND}$は、魚がセンシング範囲内にいる近傍の魚に近づき、その方向を近傍の魚の方向と合わせるように促します。エージェントとその$N_{nei}$体の近傍の魚のそれぞれの方向との間の角度∆$\theta_i^{mov}$(度)、重み$w^{ND}$で計算されます。
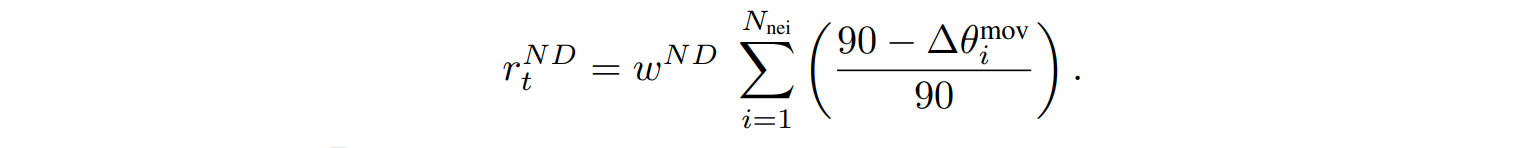 一方、$r_t^E$は、魚が体を回転させたり、速度を調整したりする際のエネルギー消費にペナルティを与えるものです。これは、回転ペナルティ重み$w^r$、速度ペナルティ重み$w^s$と、現在の時間ステップにおける体回転の角度差∆$\theta_t$と累積速度差∆$v_t^a$から計算されます。
一方、$r_t^E$は、魚が体を回転させたり、速度を調整したりする際のエネルギー消費にペナルティを与えるものです。これは、回転ペナルティ重み$w^r$、速度ペナルティ重み$w^s$と、現在の時間ステップにおける体回転の角度差∆$\theta_t$と累積速度差∆$v_t^a$から計算されます。
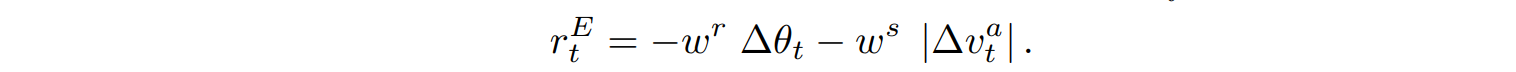
移動報酬$r_t^M$は、魚が最小速度より速く泳ぐことを促し、積極的なピッチ運動(ローカルx軸の周り)による急激な深さの変化を罰します。以下の式において、変数$\theta^{rt}$はピッチ角閾値、$v^{st}$は速度閾値、$\theta_t^x$は現在のピッチ角、$v_t^a$は現在の累積速度を表します。
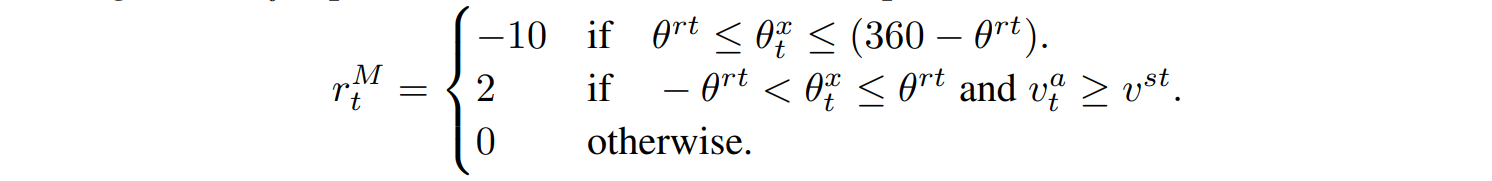
最後に、$r_t^C$は、魚の社会的地位に基づく攻撃または逃走行動を促す追跡報酬です。支配的な魚(攻撃者)が小さな確率$p_a$でランダムに追跡モードを開始し、最近傍の従属的な魚(ターゲット)に対して攻撃を開始します。これによって、追われている魚は逃走モードを開始し、攻撃者から離れるように泳ぎます。攻撃者がターゲットに衝突した場合、固定された大きな値で報酬を与えます。この処理は、攻撃者の速度$v_t^a$、攻撃者からターゲットまでの正規化ベクトルd、攻撃者に対する追跡報酬重み$w_{agg}$、ターゲットに対する脱出ペナルティ重み$w_{tar}$を用いて以下のように表現されます。

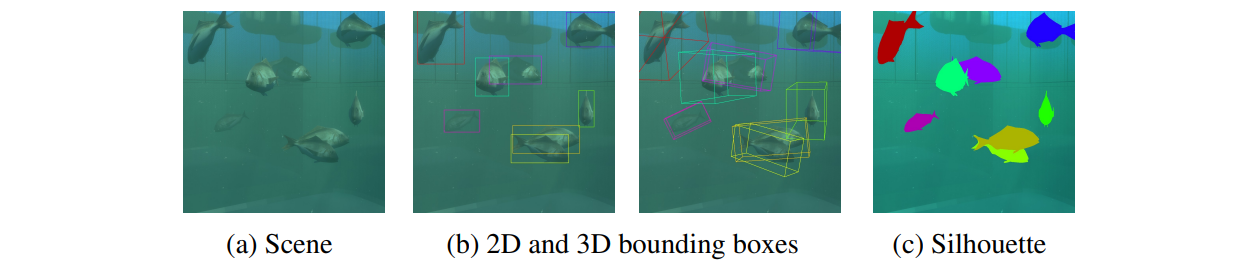
魚類計数システムは、①入力映像を画像列に変換しノイズ除去を施す画像前処理モジュール、②合成データセットを用いてYOLOv4 に基づくネットワークを学習させた魚類検出モジュール、③魚類計数モジュールの3つから構成されます。
Training:
学習にはギンザケ、ブリ、マダイの3種類を用いました。まずそれぞれの種ごとに事前学習させた後、魚種、魚のサイズ、魚の数、ケージのサイズ、ケージの形状が異なる環境にて転移学習を行いました。このような2段階の学習スキームを用いることで、環境ごとに一から学習するよりも収束が早く、全体的なパフォーマンスが向上することがわかりました。また、エージェントがケージの壁や水面に衝突した場合、そのエピソードを早期に終了させることができるようにしました。その場合、エージェントはケージ内のランダムな位置から、ランダムな有効回転と初期速度$v_0$で新しいエピソードを再開します。
Fish Behavior:
シミュレーションで得られた画像と水中で撮影された映像の定性的な比較を下図に示します。この画像から3種の魚の泳ぎ方が異なることがわかります。このような行動の違いや、照明、水の色、濁りなどの環境変化を、シミュレーションで再現することに成功しました。
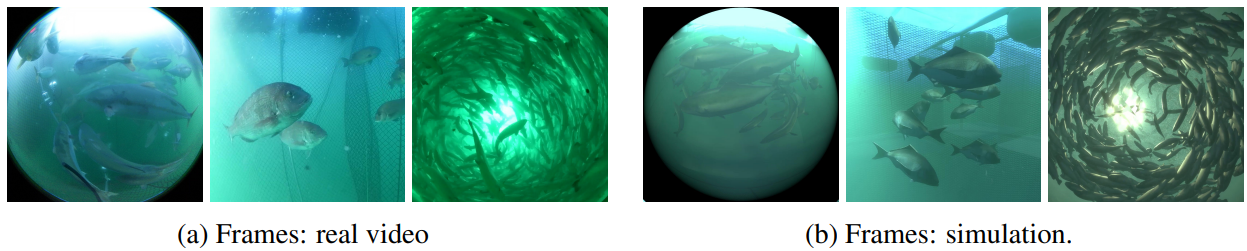
また、魚種、魚の大きさ、魚の数、ケージの大きさ、形状の異なる5つの環境を設定した場合のシミュレーション結果を下図に示します。ギンザケ、ブリ、マダイのデフォルトの体長は収集したフィールドデータに従ってそれぞれ0.49メートル、0.52メートル、0.34メートルに設定されました。魚の泳ぎ方は、先ほど述べたような様々な要因の組み合わせにより、シーンの構成によって変化します。例えば、図a(左3枚)の10匹のマダイは、ケージのサイズが小さいため、ケージの中心をゆっくりと周回しますが、図a(右3枚)の同じ10匹の魚は、ケージのサイズがはるかに大きいため、中心から離れるように速く泳ぐことを学びます。一方、図bのマダイは量が多いため、よりコンパクトな群れを形成し、小さなケージ全体をゆっくりと周回します。さらに、体格差の大きい魚(図c)と複数種の魚(図d)が混在する2つの架空のシーンについてもシミュレーションしました。サイズと種族が異なる魚は、同じいけすの中で他のグループの泳ぎに影響を与えながら、それぞれ異なる泳ぎ方をします。

Simulation vs Reality:
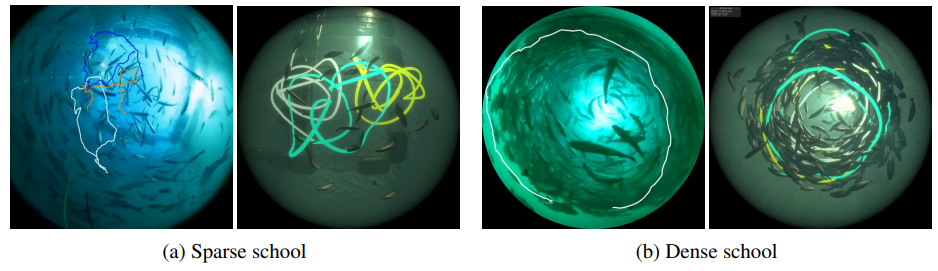
ケージ内の魚の密度と魚群状態の関係に注目し、シミュレーション結果と実データを比較しました。シミュレーションでは、疎(0.59匹/$m^3$ )と密(14.7匹/$m^3$ )の2種類の群れを用いました。実際の養殖場では、疎なケージは6.5m×6.5m四方、奥行き6mで、272匹が飼育されており、密なケージは6.5mの辺と10mの深さを持つ八角形で、約30000匹の魚が飼育されています。下図に、(a)疎な場合と(b)密な場合 の両方における魚の軌跡を示します。左が実際の映像、右がシミュレーション結果であり描かれる軌跡が似ていることがわかります。
Fish Counting:
合成データセットで学習させたYOLOv4モデルを実際の映像に適用しました。下図に、ギンザケ、ブリ、マダイの映像を用いた結果を示す。学習済みの魚の計数アルゴリズムを使って下図の各フレームの魚の数を推定した。ギンザケ、ブリ、マダイのカウント結果は、それぞれ69:61、22:32、7:7(左:学習済みモデル、右:人手によるカウント)でした。このことから、魚の密度が高く、オクルージョンが多く見られる場合には、カウントの精度は低下することがわかりました。

今回は様々な環境に適応した魚の群行動を深層強化学習により自律的に獲得する手法である「DeepFoids」について紹介しました。任意の環境下にあるいけすにおいて、マルチエージェントのDRLを用いた群行動の再現を実現しました。さらに、さまざまな場所や季節の水中景観を視覚的に再現可能な物理ベースのシミュレーションを組み込んだことにより、本物と酷似した画像データセットを生成することが可能になりました。
課題としては、報酬関数の重みを手動で設定していることであり、今後は、重みを動的に調整できる技術を模索する予定だと述べられていたので、これからの発展が楽しみです。




この記事に関するカテゴリー






