
不正確な擬ラベルを用いた半教師ありセグメンテーション
3つの要点
✔️ 不正確な擬ラベルを学習に用いる、新しい半教師ありセグメンテーション手法である$U^2PL$を開発した。
✔️ 擬ラベルをエントロピーによって正確と不正確に分類し、不正確ラベルを各クラスの負サンプルのキューとして用いた。
✔️ 様々なベンチマーク実験において、本論文手法はSOTAを記録した。
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
written by Yuchao Wang, Haochen Wang, Yujun Shen, Jingjing Fei, Wei Li, Guoqiang Jin, Liwei Wu, Rui Zhao, Xinyi Le
(Submitted on 8 Mar 2022 (v1), last revised 14 Mar 2022 (this version, v2))
Comments: Accepted to CVPR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
半教師ありセグメンテーションでは、ラベルなしデータに十分な数の擬ラベルを与えることが重要です。従来の手法では、予測に自信のあるピクセルをGround Truthとして用いますが、ほとんどのピクセルは自信が無いため学習に用いられない問題があります。直感的には、自信のないピクセルは特定のクラス間で予測を迷っており、その他のクラスには属さないという高い自信があるはずです。したがって、それらのクラスに対する負サンプルとして用いることができます。本論文では、ラベルなしデータを十分に用いる手法を開発しました。まず、エントロピーの値によってラベルを正確と不正確に分類し、不正確ラベルを各クラスの負サンプルのキューとして学習に用いました。モデル予測が正確になるにつれて、正確不正確の分類閾値を適応的に調整しました。
手法
ラベルありデータを${\cal D}_l=\{(x_i^l, y_i^l)\}_{i=1}^{N_l},$大量のラベルなしデータを${\cal D}_u=\{(x_i^u)\}_{i=1}^{N_u}$とします。$U^2PL$の概略は下図のようになります。StudentモデルとTeacherモデルから構成され、両者の違いは重み更新の方法のみです。Studentモデルの重み$\theta_s$は通常の方法で更新され、Teacherモデルの重み$\theta_t$は$\theta_s$の指数移動平均で更新されます。両モデルはCNNベースのエンコーダ$h$と、セグメンテーションヘッド$f$とレプリゼンテーションヘッド$g$を持つデコーダから成ります。各学習段階で$B$サンプルずつのラベルありデータとラベルなしデータ${\cal B}_l, {\cal B}_u$を取り出しました。ラベルありデータに関しては、通常のクロス・エントロピーを最小化し、ラベルなしデータに関しては、Teacherモデルに入れ、エントロピーの値から正確ラベルに対して擬クロス・エントロピーを最小化しました。最後に、不正確なラベルを用いるためにcontrastive lossを用いました。最終的なloss関数は次のようになりました。
$${\cal L}={\cal L}_s+\lambda_u{\cal L}_u+\lambda_c{\cal L}_c$$
ここで$\lambda_u, \lambda_c$はバランスパラメータ、${\cal L}_s, {\cal L}_u$はラベルありとラベルなしのloss関数で次のように表されます。
$${\cal L}_s=\frac{1}{|{\cal B}_l|}\sum_{(x_i^l,y_i^l)\in {\cal B}_l}l_{ce}(f\circ h(x_i^l;\theta), y_i^l)$$
$${\cal L}_u=\frac{1}{|{\cal B}_u|}\sum_{x_i^u\in {\cal B}_u}l_{ce}(f\circ h(x_i^u;\theta), {\hat y}_i^u)$$
ただし$y_i^l$は$i$番目のラベルありデータのアノテーションラベル、${\hat y}_i^u$は$i$番目のラベルなしデータの擬ラベル、$f\circ h$は$f$と$h$の合成関数です。${\cal L}_c$は次のようになります。
$${\cal L}_c=-\frac{1}{C\times M}\sum_{c=0}^{C-1}\sum_{i=1}^{M}\log\left[\frac{e^{<{\bf z}_{ci},{\bf z}_{ci}^+>/\tau}}{e^{<{\bf z}_{ci},{\bf z}_{ci}^+>/\tau}+\sum_{j=1}^Ne^{<{\bf z}_{ci},{\bf z}_{cij}^->/\tau}}\right]$$
ここで$M$はアンカーピクセル数、${\bf z}_{ci}$はクラス$c$の$i$番目のアンカーピクセルのレプリゼンテーションです。各アンカーは正のサンプルと$N$個の負のサンプルを持ち、レプリゼンテーションはそれぞれ${\bf z}_{ci}^+,{\bf z}_{cij}^-$です。$<\cdot,\cdot>$はコサイン類似度で$\tau$はハイパーパラメタです。
擬ラベリング
$i$番目の画像の$j$番目のピクセルに対する、Teacherモデルのセグメンテーションヘッドの確率分布を${\bf p}_{ij}\in {\mathbb R}^C$とします。ここで$C$はクラス数です。エントロピーは
$${\cal H}({\bf p}_{ij})=-\sum_{c=0}^{C-1}p_{ij}(c)\log p_{ij}(c)$$
と表され、学習エポック$t$における擬ラベルを次のように定義します。
$${\hat y}_{ij}^u=\left\{\begin{array}{ll} argmax_{c}p_{ij}(c)&{\rm if}\ {\cal H}({\bf p}_{ij})<\gamma_t \\ ignore & {\rm otherwise} \end{array} \right.$$
ここで$\gamma_t$は閾値で全体のエントロピーの何パーセンタイルを切り捨てるかを決めます。
不正確ラベルの利用
$U^2PL$はアンカーピクセル、正のサンプル、負のサンプルから成ります。
・アンカーピクセル
ミニバッチ内のラベルありデータとラベルなしデータの、各クラスのアンカーピクセルをそれぞれ${\cal A}_c^l, {\cal A}_c^u$とすると、
$${\cal A}_c^l=\{{\bf z}_{ij}|y_{ij}=c,p_{ij}(c)>\delta_p\}$$
$${\cal A}_c^u=\{{\bf z}_{ij}|{\hat y}_{ij}=c,p_{ij}(c)>\delta_p\}$$
のようになります。ここで$y_{ij}$は$i$番目の画像の$j$番目のピクセルのGround Truth、${\hat y}_{ij}$は擬ラベル、${\bf z}_{ij}$はレプリゼンテーション、$\delta_p$は閾値です。したがって最終的なクラス$c$のアンカーピクセル${\cal A}_c$は次のようになります。
$${\cal A}_c={\cal A}_c^l \cup {\cal A}_c^u$$
・正のサンプル
正のサンプルはアンカーピクセルと同じクラスの重心です。
$${\bf z}_c^+=\frac{1}{|{\cal A}_c|}\sum_{{\bf z}_c\in {\cal A}_c}{\bf z}_c$$
・負のサンプル
二値変数$n_{ij}(c)$を、ラベルありデータの場合$n_{ij}^l(c)$,ラベルなしデータの場合$n_{ij}^u(c)$とします。${\cal O}_{ij}=argsort({\bf p}_{ij})$として、
$$n_{ij}^l(c)={\bf 1}[y\neq c]\cdot{\bf 1}[0\leq {\cal O}_{ij}(c)<r_l]$$
$$n_{ij}^u(c)={\bf 1}[{\cal H}({{\bf p}_{ij}})> \gamma_t]\cdot{\bf 1}[r_l\leq {\cal O}_{ij}(c)<r_h]$$
のように定義します。ここで$r_l, r_h$は閾値です。最終的に、クラス$c$の負のサンプルは次のように定義されます。
$${\cal N}_c=\{{\bf z}_{ij}|n_{ij}(c)=1\}$$
・カテゴリーメモリーバンク
ミニバッチ内での負のサンプル数を確保するため、各クラスに対してメモリーバンク${\cal Q}_c$を用いました。
結果
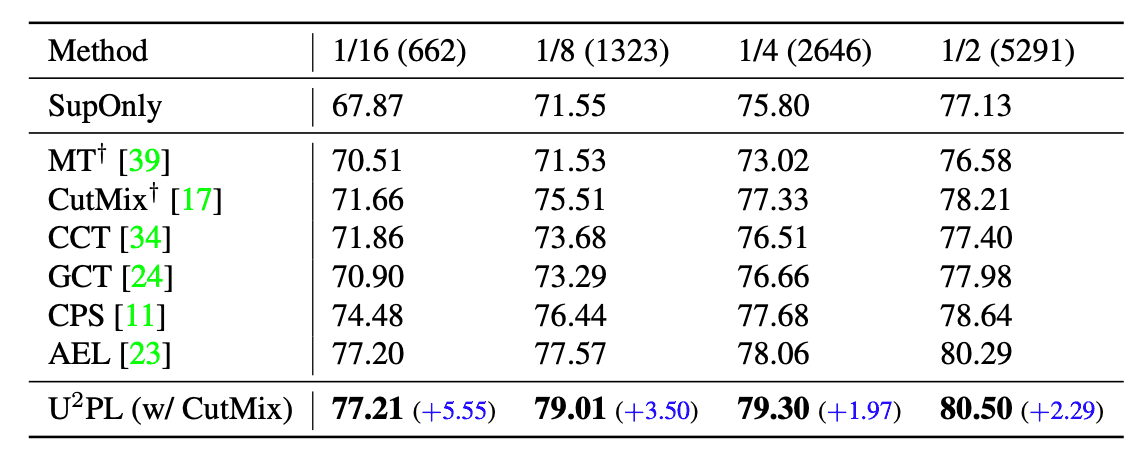
PASCAL VOCデータセットを分割した時の、各半教師あり学習手法と本手法の比較結果は下表のようになりました。表から、全ての分割方法に対して本手法が最も高い精度となりました。
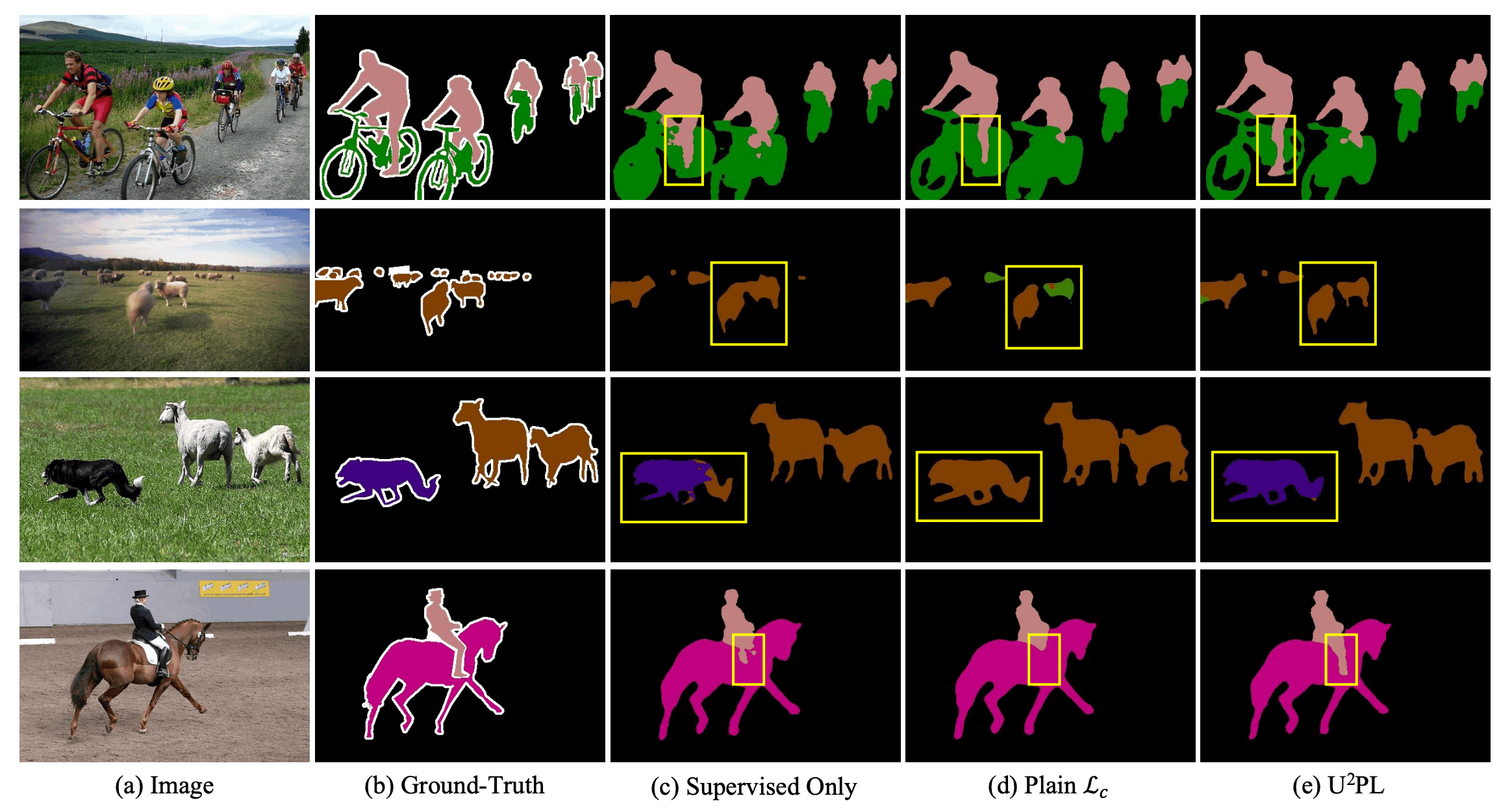
また、定性的な比較結果例を下図に示します。図から、ラベルありデータのみで学習したモデルでは不完全だった箇所を本手法では正しく予測できていることが分かります。
まとめ
本論文では、不正確なデータを利用する新しい半教師ありセグメンテーション手法である$U^2PL$を提案しました。本手法は従来の半教師あり手法よりも高い性能を示しました。教師あり学習と比べ、学習時間がかかることが半教師あり学習のデメリットですが、大量のラベルデータなしで高い精度を実現するためには、時間を代償とする必要があるようです。






この記事に関するカテゴリー





