
GANを用いた自己アテンションに基づく時系列インピュテーションネットワークSTING
3つの要点
✔️ STING (Self-attention based Time-series Imputation Networks using GAN) と呼ばれる多変量時系列データに対する新しいインピュテーション手法を提案
✔️ 潜在的なバイアスを回避するために、新しいアテンション機構を導入
✔️ 既存の最先端手法よりも置換精度や置換された値を用いた下流タスクの点で優れている
STING: Self-attention based Time-series Imputation Networks using GAN
written by Eunkyu Oh, Taehun Kim, Yunhu Ji, Sushil Khyalia
(Submitted on 22 Sep 2022)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
実世界のアプリケーションの多くで用いられる時系列データでの最も一般的な問題の1つは、データ収集プロセスの本質的な性質によって、時系列データが欠損値を持つ可能性があることです。そのため、多変量(相関)の時系列データから欠損値をインピュテーションすることは、データ駆動型の正確な意思決定を行いながら予測性能を向上させるために必要不可欠です。従来のインピュテーションは、欠損値を削除したり、平均値やゼロに基づいて欠損値を埋めるだけでした。また、近年ではディープニューラルネットワークを用いた手法が注目されていますが、多変量時系列の複雑な生成過程を捉えるにはまだ限界があります。本論文では,STING (Self-attention based Time-series Imputation Networks using GAN) と呼ばれる多変量時系列データに対する新しいインピュテーション手法を提案します。生成的敵対ネットワークと双方向リカレントニューラルネットワークを利用し、時系列の潜在的表現を学習します。さらに、時系列全体の重み付けされた相関を捉え、無関係な相関がもたらす潜在的なバイアスを回避するために、新しいアテンション機構を導入します。3つの実世界データセットでの実験結果は、STINGが既存の最先端手法よりも置換精度や置換された値を用いた下流タスクの点で優れていることを示しています。
はじめに
多変量時系列データの多くのリアルタイムアプリケーション領域では、これらの信号を解析し、予測分析を行っています。例えば、株価予測に関する金融マーケティング、患者の医療診断予測、天気予報、リアルタイム交通予測などです。しかし、あるデータの特徴が後から収集されたり、機器の損傷や通信エラーで記録が失われたりするなど、何らかの理由で時系列データに欠損値が含まれることは避けられません。医療分野では、例えば生検から収集された特定の情報は、入手が困難であったり、危険であったりすることもあります。このような種類の欠損データは、モデルの品質を著しく低下させ、かなりの量のバイアスを導入することによって間違った判断を下すことさえあります。そのため、時系列の欠損値を埋め込むことは、データ駆動型の正確な意思決定を行うための最重要課題となっています。
従来の欠損値代入法は、識別法と生成法の2つに分類されます。前者にはMICE(Multivariate Imputation by Chained EquationsやMissForestが、後者にはディープニューラルネットワークに基づくアルゴリズム(Denoising Auto Encoder (DAE) やGenerative Adversarial Networks (GAN) など)が含まれます。しかし、これらの方法は非時系列データに対して開発されているため、時系列における観測値間の時間依存性はほとんど考慮されていない可能性があります。特に、DAEは学習段階において完全なデータを必要とするが、欠損値が問題の固有構造の一部であるため、この要件はほとんど不可能です。時系列データインピュテーションのための最新の研究は、リカレントニューラルネットワーク(RNN)とGANに基づいています。これらは、時間減衰、特徴相関、時間的信念ゲートなど、観測された(または欠損した)データの特性の様々な側面と時間依存性を捕らえるものです。
ここでは、多変量時系列データに対する新しいインピュテーション手法であるSTING (Self-attention based Time-series Imputation Network using GAN)を提案します。本論文では、不完全な時系列データをインプットする際に、真のデータ分布を推定することができる生成敵対ネットワークを基本アーキテクチャとして採用します。具体的には、生成器は多変量時系列データの基礎分布を学習して欠損値を正確にインプットし、識別器は観測された要素とインプットされた要素を区別するために学習します。GANの生成器は、非固定的なタイムラグを持つ観測値間の潜在的な関係を学習するために、新しいRNNセルであるGRUI (GRU for Imputation) を内部に採用します。タイムラグに従って、過去のオブザベーションへの影響を重み付けしています。将来の観測値と過去の観測値の両方からの情報を利用して、現在の欠損値をインプットするために、双方向RNN(B-RNN)を採用し、前方と後方の両方向から変数を推定します。さらに、各時系列において関連性の高い情報に選択的に注目する新しい注目機構を提案します。これにより、時系列シーケンスが長く、2つの観測の時間間隔が大きい場合、効率的な学習が可能となります。3つの実世界データセットでの実験結果から、STINGはインピュテーション性能の点で最先端手法を凌駕していることが示されます。このモデルはまた、置換性能の間接的な指標であるポストインプットタスクにおいても、ベースラインより優れています。
関連研究
Cheらは、ヘルスケアデータセットにおいて、不完全な時系列の欠損パターンを学習し、欠損値を埋めながら目標ラベルを予測するGated Recurrent Unit with Decay (GRU-D)を提案しました。このモデルは、RNNを用いて、その最後の観測値と経験平均の加重結合を考慮します。彼らは、減衰係数を制御するために、入力減衰率と隠れ状態減衰率を導入しました。しかし、このモデルは、データの欠損パターンが対象ラベルと相関していることが多い(=情報的欠損)ことを大前提としています。この事実を考慮し、インピュテーションと予測タスク(すなわち、ターゲットラベルの)を一つのプロセスに統合することで、統一的なアプローチをとっています。このため、対象ラベルが完全に観測されているかどうかに依存するため、モデルの一般性が低くなります。そのため、ラベルのない教師なし設定やラベルが明確でない場合には利用が難しいです。また、推論された値が最後の観測値と経験的平均値の比であるという統計的仮定を課しています。
同様の研究として、Caoらは、双方向RNNグラフの潜在変数と考えられる欠損値を直接学習する、BRITS(Bidirectional Recurrent Imputation for Time Series)というRNNベースの手法を提案しました。これは、特徴相関のための履歴ベース推定と特徴ベース推定を組み合わせ、欠損値に遅延勾配を取らせる学習戦略を適用するものです。しかし、与えられた時系列に基づいてターゲットラベルを予測すると同時に、インピュテーションの学習を行うことを目的としています。そのため、学習段階でターゲットラベルを知る必要があります。しかし、ターゲットラベルは未知であったり、欠損値を含んでいる可能性があるため、これはかなり強い制約です。その結果,Imutationの性能はターゲットラベルの完全性に非常に敏感です。これらとは異なり、本論文のモデルはどのようなプロセスにおいてもターゲットラベルに依存しません。
Luo らは GAN-2-stages と呼ばれる GAN ベースのインピュテーションモデ ルを提案しました。時間的不規則性を持つ分布をモデル化するために,Gated Recurrent Unit for Imputation (GRUI) を提案し,不規則な時間間隔での時間経過の長さに応じて,過去の観測値の影響を減衰させるように学習させます。彼らはさらに、生成器の入力「ノイズ」を学習させ、生成されたサンプルが元のサンプルと最も類似するように、潜在的な入力空間から最適なノイズを見つけます。しかし、元のサンプルが欠損度によって異なる時間減衰を持つのに対して、生成されたサンプルは完全性によって同じ時間減衰を持ちます。この時間減衰の明確な違いにより、識別器は偽データと実データの区別がつきやすく、識別器の収束が早くなるため、生成器の安定した学習を防ぐことができます。さらに、学習中の誤った出力がその後の学習に最後まで反映され続けるセルフフィード学習方式をとっています。
Luoらは、End-to-End Generative Adversarial Network (E2GAN)を提案しています。彼らは、ノイズ除去オートエンコーダを用いて、「ノイズ」最適化段階を回避する圧縮と再構成の戦略を利用します。生成器では、ランダムなノイズを入力として元の時系列に加え、エンコーダが入力を低次元ベクトルに写像しようとします。そして、デコーダが低次元ベクトルから再構成し、サンプルを生成します。この過程を通じて、E2GANは元の時系列の分布を学習しながら、入力の圧縮表現を強制的に学習することができました。しかし、E2GANはGAN-2-stageの制約である、生成器と比較して識別器の収束が早いことや、RNNの自己学習などの制約を依然として抱えています。本論文では、観測値を利用した生成器でのRNNモデルの学習を迅速かつ効率的に行うため、双方向遅延勾配を採用しています。また、提案する識別器は、入力行列全体ではなく、入力行列の各要素が真値(観測値)か偽値(生成値)かを識別することで、より具体的な問題を解決しようとするため、安定した敵対学習が可能です。
問題定義
多変量時系列データ X = {x1, x2, ..., xT } をT個の観測値の列とし、t番目の観測値 xt∈ RD はD個の特徴量 {xt1, xt2, ..., xtD} から構成されるとします。すなわち、xtdはxtのd番目の変数の値として示されます。Xは欠損値を持つ不完全行列です。また、xtにおいて変数が欠落している位置を示すために、マスクベクトルmtを導入します。そこで、mtdは以下のように定義されます。
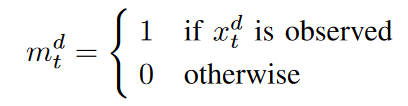
xtd が欠損値である場合、Xハットは 0 であることを除いて X とほぼ同じであると定義します。タイムスタンプの時間間隔は同じとは限らないので、最後の観測から現在のタイムスタンプ st までの時間間隔を δd t と定義します。
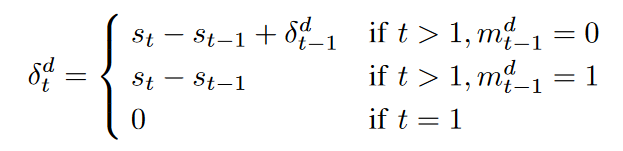
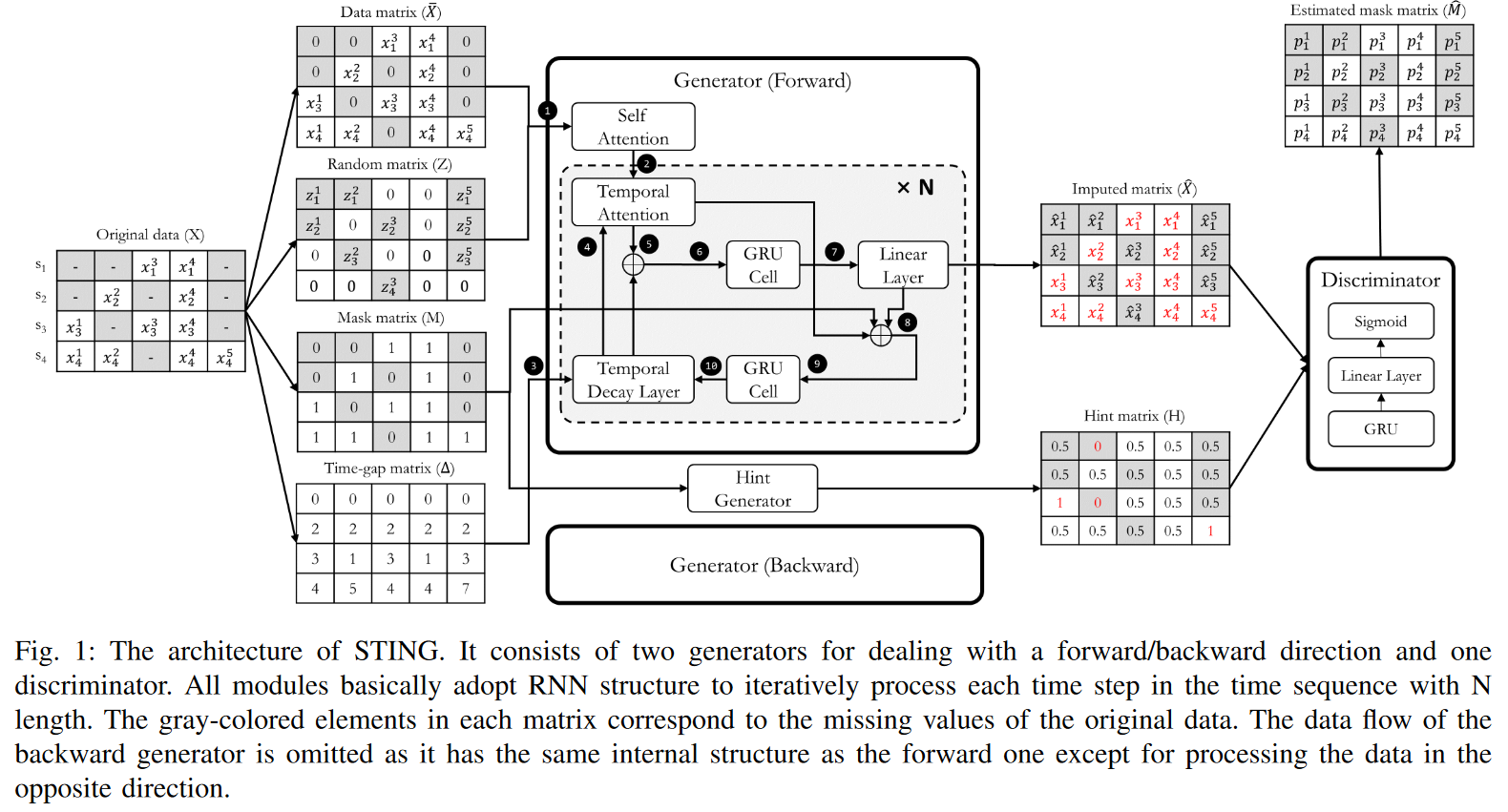
入力行列を用いた例をFig.1に示します。この例では、SをS = {0, 2, 3, 7, ..., sT }と定義しています。
その目的は、GANの敵対的学習機構により不完全行列Xの欠損値を精度よくインピュテーションすることです。生成器はXの基礎となる分布を学習して完全な時系列行列ˆ Xを作ろうとし、識別器は完全行列の各要素がXからの実値かˆ Xからの偽値かを識別して推定マスク行列ˆ Mとマスク行列Mを一致させようとします。ˆ Mの各要素は、ˆ Xの各要素が実値である確率を表しています。この確率をpdt∈[0, 1]と表記します。
手法
ここでは、多変量時系列データに対するインピュテーションモデルの構築方法を、Fig. 1に示すようなアーキテクチャと全体のワークフローに着目して説明します。
既存の深層生成ニューラルネットワークにヒントを得て、STINGは二つの生成器(Gs)と一つの識別器(D)から構成されています。2つのGは順方向と逆方向の時系列を入力とし、それぞれが指定された方向に従って時系列行列ˆ Xを生成します。両方向の生成は、時系列データの欠損値の多さに悩む単方向GRU構造における情報不足の問題を補完するものです。Gの内部は、2つの注意モジュールと2つの修正GRUセルで構成されています。注目モジュールはシーケンス全体の相関重みを計算することにより、後続のGRUモジュールに多くの手がかりを提供することができます。そして、2つのGRUセルは、時間間隔が不規則な時系列の入力に対処するために設計されています。一方、DはGに比べ比較的単純な構造で、時系列処理のためのGRUモジュール、次元を下げるための線形層、最後に各要素の確率を出力として出すシグモイド活性化から構成されています。
ワークフローの観点からは、我々のアプローチは、まず̄ Xを各欠測値に対してゼロで埋め、次にそれらの要素をzd tで置き換えることから始まります。Mは、Xのどの要素が観測値か欠損値かという情報をGに知らせる役割を果たします。これにより、Gはˆ xtを繰り返し生成する際に、直前のタイムスタンプのどの値が信頼できるか、できないかを判断することができます。∆ また、△は、任意に欠損値がある場合に、Gがどの程度前の隠れ状態を参照すべきかという重要な情報を持っています。これら4つの入力行列を基に、Gはインピュテーション行列ˆ Xを生成し、既に知っているxtdを生成する必要がないため、Xの観測値を埋めて洗練させます。すなわち、ˆ xtdはその要素が観測値であれば、xtdに置き換えられます。これがインピュテーションの結果であり、識別器に転送されます。
一方、Dはˆ Xを入力とし、各要素が観測値であるか否かを区別して学習します。この際、ヒント行列Hも追加入力として与えられ、Mの特定の部分をDに知らせ、特定の成分に注意を向けさせます。Hは、htd = 0(欠損値として)またはhtd = 1(観測値として)で、Mのいくつかの部分を明らかにします。さらに、htd = 0.5は、Dの学習が集中しうるmtdについて何も示唆しません。これは、Dが0.5の標本点に対して0と1のどちらかを選択しなければならないため、比較的難しい学習点となり、Dはより良い適合を得ることに集中することになるからです。つまり、ヒント機構がなければ、Gが元のデータで一意に定義される所望の分布を学習することは保証されません。実際には、ヒント生成器のHを変化させることで、Mに関するヒント情報量を制御することができます。ヒントが多ければ多いほど、Dは学習しやすくなります。最後に、Dの出力はˆ Mであり、各要素はˆ Xの各要素が観測値である確率pdtを表しています。
GとDをmin-maxゲームにより共同で学習させることで、Gは元データXの基礎分布を学習し、Dが区別できないように欠損値を適切にインプットすることができます。Gの理想的な結果は、生成された偽の値ˆ xtdに対応するˆ Mの各ptdが1に設定されることです。したがって、Dの理想的な結果は、偽の値ˆ xtdに対応する各ptdを0に設定し、それ以外の場合は1に設定することです。このことは、Dがマスク行列Mに等しい結果ˆ Mを正確に予測することを意味します。STINGの特徴の1つとして、Dは入力行列全体ではなく、行列のどの要素が本物(観測値)か偽物(帰属値)かを区別することを試みています。この戦略により、Dはより特定の分類問題に集中することができ、それによって性能を向上させることができます。
A. 生成器
STINGは、Fig. 1に示すように、時間的に両方向の依存性を考慮するために、2種類の生成器(すなわち、前方Gと後方G)を利用します。両者の役割は、後述の「整合性損失」で説明する一部を除き、同じです。したがって、本節の大部分では前方Gの詳細のみを説明し、後方Gについては紙面の都合上、説明を省略します。各Gは、自己注意と時間注意の2種類の注意層、時間減衰層、二重GRU-cellを持つ高度なGRU構造で構成されています。詳細な構成と学習目標は以下の通りです。
アテンションは、クエリ値が与えられた入力の中から最も関連性の高い部分を見つけ出し、クエリに応じた表現を生成することにより、入力データの異なる座標間の構造的依存関係を学習することを目的としています。アテンション機構は、基礎となるデータ分布の構造的特性を学習させることにより、様々な分野で有効であることが示されています。例えば機械翻訳タスクでは、このメカニズムを用いて、デコード時にエンコーダのシーケンスの各単語にどの程度の注意を払うべきかを測定することができます。様々な注意のアルゴリズムの中で、スケールドットプロダクト注意は次のように定義されます。
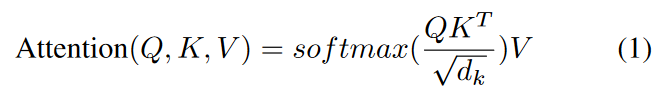
ここで、Qはクエリ、Kはキー、Vは値を表します。スケールファクター√dkは、特に次元が高い場合に内積の値が大きくなりすぎないようにするためのものです。そこで、キーと値としてのエンコーダのシーケンス全体と、クエリとしてのデコーダの特定の時間ステップとの間の、アテンションスコアと呼ばれる相関の重みを計算することで、アテンション機能を実現します。特に、自己アテンションモジュールは、同じ配列の表現を計算するために、自己の配列の異なる位置(すなわち、Q=K=V)間でアテンションスコアを計算します。
モデルが異なる位置の異なる表現部分空間からの情報を共同で注意できるようにするために、さらに次のように定義されるマルチヘッド注意を採用します。
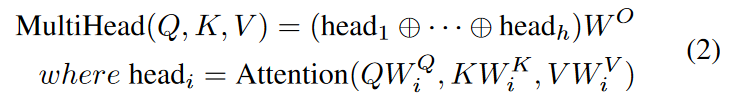
ここで, W Q i ∈ Rdmodel×dq , W K i ∈ Rdmodel×dk , W V i ∈ Rdmodel×dv , W O ∈ Rhdv×dmodel は学習可能なパラメータ行列です。 ⊕は連結演算を表します。本モデルでは、dmodel がデータの入力次元に相当し、縮小された次元で 4 つの並列注目ヘッドを計算し、元の次元に連結します。
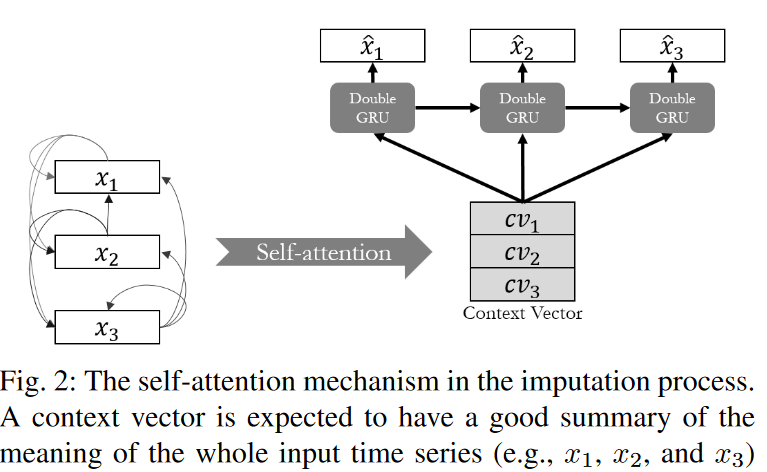
本論文では、2つの理由から、インピュテーション問題により的を絞った手がかりを提供するために、注意メカニズムを採用しました。まず、時間的順序だけでなく、比較的類似したパターンを持つ時間ステップにモデルが注意を払うことができます。これは、特に周期性を持つ時系列に適しています。多くの時系列はシーケンスに周期的な特性を持つ可能性があります(例えば、天気予報、交通予測など)。第二に、数回の時間ステップの往復だけでなく、シーケンス全体から十分な情報を得ることができます。シーケンスに欠損値が多い場合、一部のタイムステップからだけよりも、シーケンス全体から提供される情報の質が向上します。このような特性は、時間順序に依存する従来の手法(RNN手法)では捉えにくいです。そこで、本モデルでは、Fig. 2に示すように、自己注視モジュールを用いて、入力系列を文脈ベクトルに変換し(すなわち、QとKは同じ入力系列から得られる)、系列全体の量的相関を考慮します。その後、GRUの隠れ状態と文脈ベクトル(Qは隠れ状態、Kは文脈ベクトル)の相関を反映させる時間的注意モジュールを設計します。
Temporal decay layerは、GRUにおける不規則な時間間隔での過去の観測の影響を制御するものです。減衰率は、欠落パターンが未知で複雑な可能性があるため、変数に関連する基礎的な性質に基づいて変数ごとに異なるので、データから学習する必要があります。すなわち、tにおける減衰率γtのベクトルは以下のように定義されます。
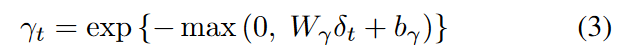
ここで、Wγとbγは学習可能なパラメータであり、各減衰率が0から1の範囲で単調減少するように指数負整流器を用いています。 これらの条件さえ満たせば、関数は他のものに置き換えることができます。直感的には、生の入力変数から直接ではなく、隠れた状態から抽出された特徴を減衰させる効果があります。隠れ状態が持つ以前の情報がどの程度減衰して利用されるかを学習することで、減衰率はGRU-cellに入る前に以前の隠れ状態(ht-1)を要素ごとの乗算でh′t-1に調整します。
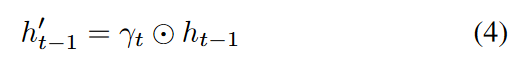
ここで、要素ごとの乗算を表します。
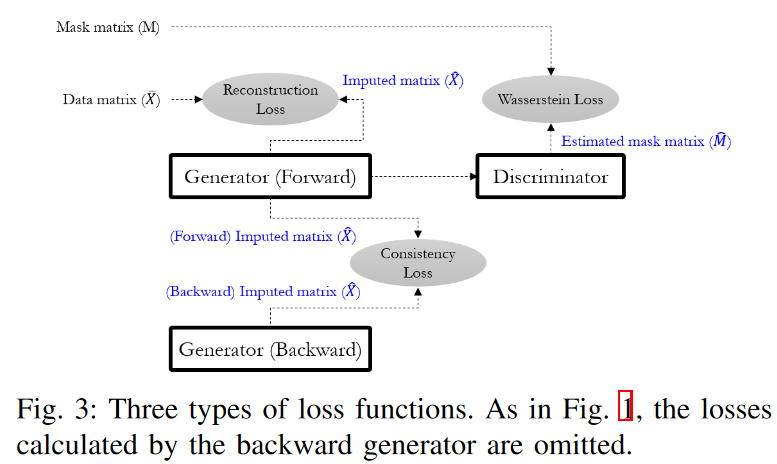
B. 識別器
GANの枠組みと同様にGを学習させる敵として識別器(D)を導入します。Dは時系列処理のためのGRUモジュール、次元を減らすための完全連結層、そして最後に各要素の確率を出力として出すシグモイド活性化で構成されます。Dは比較的容易に収束することが実験的に判明しているため、安定な敵対的学習のためにGに比べてシンプルな構造にしています。また、Dを学習する際の損失関数も比較的単純です。Gと同じ理由で、従来のWasserstein GANの損失をそのまま適用することはできませんでした。Dの入力はGによってインプットされた行列ˆ Xであり、これは要素としてインプットされた値と観測値の組合せです。つまり、それぞれが偽値または実値に相当します。つまり、損失関数は行列に含まれる2種類の入力を同時に考慮する必要があります。このため、Dの損失関数(LD)を次のように定義します。
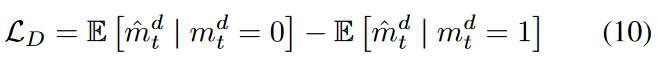
ここで、第1項はDが偽の値を入力した場合、第2項は実の値を入力した場合 の損失をそれぞれ示しています。Dが偽の値をとるときは0を、実の値をとるときは1を出力するはずです。 前方Gと後方Gでは、それぞれが出力として行列を生成するので、Dも両 方に対応する2つの損失を持ちます。しかし、便宜上1つだけ示します。
C. 最適ノイズを探す
GAN を用いた研究の多くは、「ノイズ」と呼ばれるランダム なベクトル z を変化させることで、現実的な複数のサンプルを生成 することを目的としています。しかし,この方法はImutationの問題には適用できないかもしれません。すなわち,欠損値を埋めるだけでなく,観測値を正確に一致させるという2つのタスクをうまくこなすことが必要です。このような特異性から、z探索が重要な役割を果たします。具体的には、ランダムノイズベクトルzは、ガウス分布のような潜在空間からランダムにサンプリングされます。このことは、入力されるランダムノイズzが変化すると、生成されるサンプルG(z)が大きく変化することを意味します。生成された標本が元のデータの真の分布に従うとしても、xとG(z)の類似度は十分に大きくない可能性があります。つまり、両者の分布は広い意味では似ているが、個々のサンプルは特定の見方で大きく異なっている可能性があります。この問題に対処し、類似度をさらに高めるために、最もマッチした最適雑音z′を求めることが導入されます。すでにいくつかの条件(サンプルにおける観測値)がわかっているので、それらを用いてより適切なzを繰り返し見つけることができます。この方法は、画像データのテクスチャ変換やインペインティング 、表データインピュテーションの分野で広く応用されています。
これらの研究にヒントを得て、本モデルでは、元データの分布上のサンプルに対してより適した欠損値を生成する推論段階での学習により、最適なノイズz′を探索します。推論段階での学習は、モデルのパラメータを学習するのではなく、反復毎に更新される入力ztに対してバックプロパゲーションを行う。zt の学習は (9) の学習 G (LG) と同じ損失を用います。すなわち、gradient - ∂LG/∂zt を繰り返し更新し、より適切なものを探索します。入力の1つとして最適なノイズz′tを探索した後、フォワードGとバックワードGによりそれぞれ2つのインピューテッドマトリックスを生成します。最後に,2つの行列の平均値を用いて,最終的なインピュテーションの結果を決定します。
実験
本節では、以下のリサーチクエスチョンに答えることで、提案するSTINGモデルの有効性を証明する目的で実験を行います。
- RQ1 STINGは他の最先端インピュテーション手法より優れているか?
- RQ2 STINGはポストインピュテーションとして下流タスクにどのように作用するか?
- RQ3 どのモジュールがSTINGの性能向上に最も影響を与えるか?
以下では、まず実験に使用したデータセットとベースライン手法を説明します。次に、提案するSTINGを他の比較手法と比較し、2つの異なる実験設定下でのSTINGの詳細な分析を行います。最後に、STINGの主要モジュールの影響を分析するために、切り分け研究を行います。
実験の基本設定の詳細については,すべてのデータセットについて,実験中にmin-max正規化を適用しました.すべての実験は10回繰り返され、実験中のあらゆる種類のランダム性を考慮し、精度の平均が報告されました。生成器は(6)と(7)のLRとLCで10エポック分事前学習しました。我々は、ジェネレータを事前に少し学習させると、より速く収束し、より良い性能を得ることができることを実験的に見出しました。その後、反復毎に生成器と識別器を一つずつ交互に更新しました。モデルの学習はAdamオプティマイザーを用いて行いました。生成器と識別器の学習率はそれぞれ0.001と0.0001でした。識別器に与えるヒントの比率は0.1に固定とした。バッチサイズは128としました。(9)の損失に関するハイパーパラメータとして、λrとλcを10と1に設定しました。このモデルはPyTorchで実装し、全ての学習を11GB RAMのシングル2080Ti GPUで行いました。
A. Datasets
PhysioNet Challenge 2012 Dataset (PhysioNet) - PhysioNet Challenge 20121に由来し、病院内死亡率の患者別予測手法の開発を目的としたデータセットです。これは、集中治療室(ICU)滞在からの12,000の多変量臨床時系列の記録で構成されています。我々はデータセット全体のうちトレーニングセットA(4,000 ICU stay)を使用します。実験用の前処理されたデータセットは、合計192,000個のサンプルを持ちます。各サンプルには48時間にわたるDiasABP, HR, Na, Lactateなど37の変数が含まれます。死亡ラベルが正の患者は554人(13.85%)です。このデータセットは欠損率が高く(80.53%)、非常にスパースであるため、死亡率予測などの下流タスクを単純に実行することは困難です。そのため、多くの先行研究がこのデータセットを用いて、インピュテーションやポストインピュテーションタスクの性能を評価する実験を行っています。
KDD CUP Challenge 2018 Dataset (Air Quality) - UCI Machine Learning Repositoryからアクセス可能なKDD CUP Challenge 2018 Dataset (Air Quality) は、公共の大気品質データセットで、KDD CUP Challenge 2018で使用され、将来の48時間の大気品質指数(AQI)を正確に予測することができます。記録は、北京の12のモニタリングステーションからのPM2.5、PM10、SO2など、合計12の変数があります。期間は2013年3月1日から2017年2月28日までで、変数は1時間ごとに測定された。総サンプル数は420,768で、一部欠損値(1.43%)があります。
Gas Sensor Array Temperature Modulation Dataset (Gas Sensor) - UCI Machine Learning Repositoryからアクセスできます。3週間ガスクェンバーで一酸化炭素(CO)と湿った合成空気の動的混合物にさらされた14個の温度変調金属酸化物(MOX)ガスセンサーを含みます。実験には全データセットのうち1日分を使用します。サンプル数は 295,704 です。各サンプルはガ スチャンバ内の CO 濃度を含む 20 変数から構成されます。他のデータセットと異なり、全てのサンプルが完全に観測されています。
B. Baselines
我々のモデルの性能を評価するために、以下の代表的なベースラインと比較する。統計学ベース(Stats-based)、機械学習ベース(ML-based)、ニューラルネットワークベース(NN-based)の3種類です。MLベースモデルは、pythonパッケージのsklearnとf ancyimputeをベースに実装しました。NNベースモデルのハイパーパラメータなどの実験設定は、それぞれ対応する論文にしたがって設定しました。
- Meanは、単に対応する変数のグローバル平均で欠損値を埋める。
- 前値充填(Prev)は、以前に観測された値で欠損値を充填する。この方法は、時系列という特性上、非常にシンプルで計算効率の高いインピュテーションが可能である。
- KNN [35]は、K-Nearest Neighborsを使用し、類似した10個のサンプルを見つけ、これらのサンプルの平均値で欠損値を埋め込む。
- Matrix Factorization (MF) [36] は,不完全行列を勾配降下法で解いた2つの低ランク行列に直接因数分解し,行列補完により欠損値をインピュテーションする方法である.
- MICE(Multiple Imputation by Chained Equations) [10], [37] は、欠損値を持つ各特徴を他の特徴の関数として反復的にモデル化し、その推定値を用いてインピュテーションを行うものである。
- Generative Adversarial Imputation Nets (GAIN)[18]は、GANを用いて、実際に観測されたものを条件として欠損値をインピュテーションする。
- Gated Recurrent Unit with Decay (GRU-D) [2]は、GRUをベースに、不定期な時間間隔での減衰メカニズムを用いて欠損値をインピュテーションするものである。
- E2GAN(End-to-End Generative Adversarial Network)[16]は、GANをベースに、生成器がオートエンコーダ構造を持っているのが特徴である。つまり、元の時系列の分布を学習しながら、低次元のベクトルを最適化することができる。
- Bidirectional Recurrent Imputation for Time Series (BRITS) [15]は、データセットに対する特定の仮定なしに、欠損値を埋め込むために双方向RNNを適応する。
C. Direct Evaluation of Imputation Performance (RQ1)
本実験では、ベースラインとSTINGとのインピュテーション性能を直接評価することを目的としています。本実験では,ある割合の観測値をランダムに消去し,グランドトゥルースとして使用しました。その結果、残りの観測値をインピュテーションモデルの学習データとして用いました。各モデルの置換学習が終了したら、各モデルを経由して欠損値を置換し、完全なデータを推論しました。その後、推論された値とグランドトゥルースを比較し、各モデルの性能をRMSE(Root Mean Squared Error)で測定し、値が小さいほど性能が良いことを示します。最初の実験では,真値との比率を20%に設定し,3つのデータセットに対して,全てのモデルの性能を比較しました.2回目の実験では、真実の比率を10%から90%まで変化させ、最も性能の良いベースラインの性能を評価しました。
Table I は、最初の実験の結果をまとめたものです。STINGが全てのデータセットで最高の性能を達成していることがわかります。最も性能の良いベースライン(すなわちBRITS)と比較すると、結果の誤差改善率はそれぞれ4.0%、21.0%、59.1%です。統計的手法の一つであるPrevはかなり高い性能を持っています。これは、時間がかかり、複雑な他のモデルよりも、単純に過去の値で代入した方が良い性能を発揮する可能性があることを示しています。これは、時系列データ収集の性質上、過去のサンプルへの依存度が高いため、合理的です。特に、時間的変化の少ないデータセットでは、過去の値で埋めることで、少ないコストで大きな効果を得ることができます。また、PrevはGRU-Dと似た性能の傾向を示しています。これは、GRU-Dが平均値と過去値の比率を学習し、欠損値を埋め込むため、非常に理にかなった結果です。MLベースモデルのうち,KNNはガスセンサデータセットにおいてBRITSと同様の最高の性能を示したが,他のデータセットでは性能が安定しません.一方、MICEは全てのデータセットにおいて比較的良好な性能を安定的に示します。GANに基づくGAINは、時系列データセットにおいて、時系列に適した学習戦略がないため、良い性能を示しません。
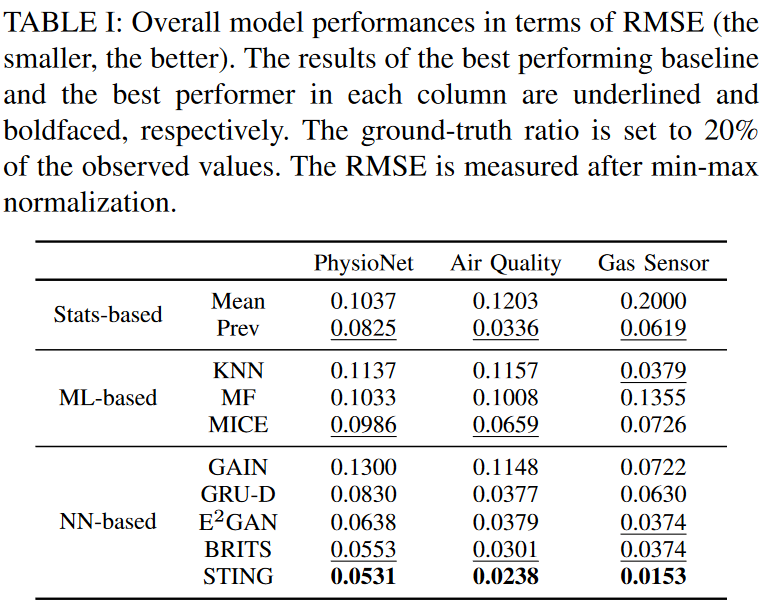
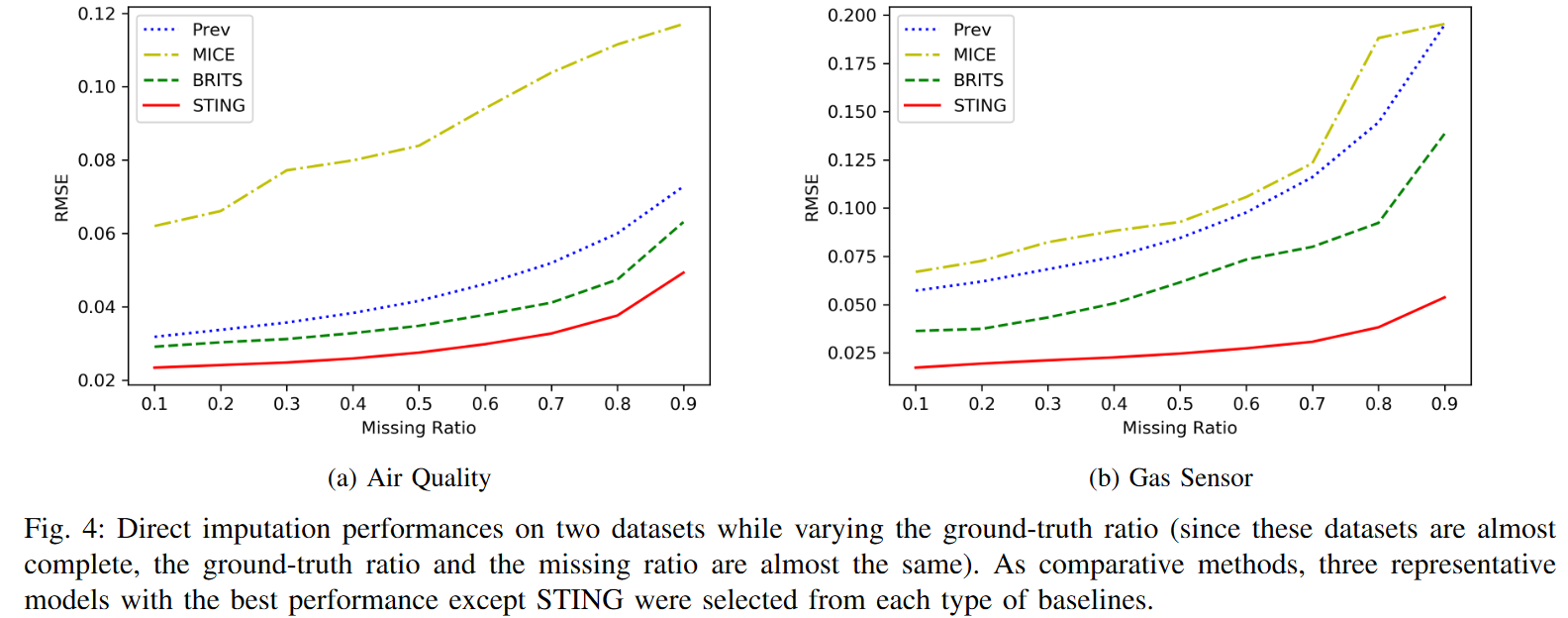
Fig. 4は、2つのデータセットの欠損率を変化させた場合の第2実験の性能結果です。なお、PhysioNetは欠損率が非常に高い(80.53%)ため、この実験では除外しています。欠損率が高くなると、逆にインピュテーション学習に使用する学習データが減少するため、全てのモデルの性能が低下します。それでも、STINGはすべての条件で最高の性能を達成し、緩やかに性能が低下していくことがわかります。つまり、データセットに欠損値が含まれるほど、STINGは他と比較して欠損値のインピュテーションの感度が低くなる。この結果から、STINGはシーケンス全体を参照することで比較的多くの情報を利用できるため、注意のメカニズムを利用していることが確認できました。
D. Indirect Evaluation of Imputation Performance (RQ2)
本実験では,下流タスクの解答結果によって,間接的にインピュテーションの性能を評価することを目的としています。元データとインピュテーションデータの分布が似ていれば、下流タスクの結果も似ているはずです。そのため、予測結果を通じて間接的に不完全なデータがどの程度インピュテーションされたかを見ることができます。予測モデルの安定的な学習のために、元々完全なデータであるガスセンサー・データセットのみを利用します。また、このデータは、全ての欠損値をグランドトゥルースで置換した理想的な置換モデルを仮定することができるため、上限予測性能を得ることができます。本実験では、この理想的な置換モデルもベースラインとして含めます。なお、本実験では予測性能の向上ではなく、インピュテーション性能の測定を目的としているため、インピュテーションと予測のタスクを同時に学習させることはしません。ラベル以外のテストデータをインピュテーションした後、それらは既に学習済みの完全な訓練データに対して学習した予測モデルで推論します。これは、ラベルが明確でない、あるいはラベルに欠損があるような典型的なセットアップでモデルを公平に比較することを意図しています。
本実験の手順は以下の通りです。インピュテーションモデルと回帰モデルとの独立した設定のため、最初にデータセットを80%のトレーニングデータと20%のテストデータに分けます。この完全な学習データを用いて、まず目標とするCO濃度を予測する回帰モデルを学習させます。回帰モデルとしては、2層でドロップアウトを0.3とし、最終的に完全連結層を持つ単純なGRUを構築しました。そして、学習データは、ある比率で完全にランダムに欠損値を持つようにしました。学習データに対して本手法とベースラインを学習させた後、得られたモデルによりテストデータの対象以外の欠損値をインプットし、各モデルに対応する異なるインプット済みテストデータセットを得ることができます。そして、インプットされたテストデータに基づいて、回帰モデルを用いてターゲットを予測します。最後に、予測された目標値と実際の目標値の間のRMSE結果を測定します。この評価方法により,類似の分布は類似の性能を得るという仮定のもと,インプットされたデータが元データの分布に従うかどうかを判断することができる.つまり、元のテストデータの回帰結果(理想的なモデルでインプットしたもの)にどれだけ近いかを比較することで、どのインプットデータがより真の分布に近いかを知ることができます。ここで注意すべきは、我々は最先端の予測性能を達成することを目的としていないことです。
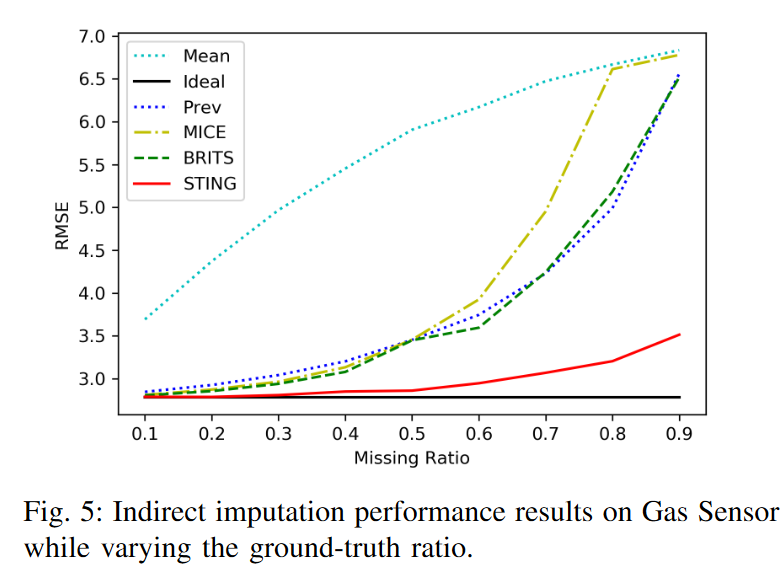
Fig. 5は、各インプットされたデータについて、基底真理値比率を変化させながら回帰モデルのRMSEの結果を示したものです。理想的なモデルは、どのような欠損率であっても元のテストデータをインピュテーションすることができるため、RMSEが最も低く、一定であることがわかります。比較したインピュテーションモデルの中で、STINGはどのような比率であっても最高のパフォーマンスを達成しています。一方、Meanは最悪のパフォーマンスを示し、平均値で時系列をインプットすることがいかに非効率的であるかを示しています。興味深いことに、約0.5の欠損比率の間に明確な差があります。以前は、ほとんどのモデルが3.5以下では同程度の良好な性能を維持していましたが、その後RMSEが劇的に増加します。グランドトゥルースが0.9の場合、STINGは条件が悪いにもかかわらず、比較的小さな誤差の増加を示しています。GANを使用して新しい時系列を生成し、注意のメカニズムによりシーケンス全体の情報を利用する利点があるようです。
E. Ablation Study (RQ3)
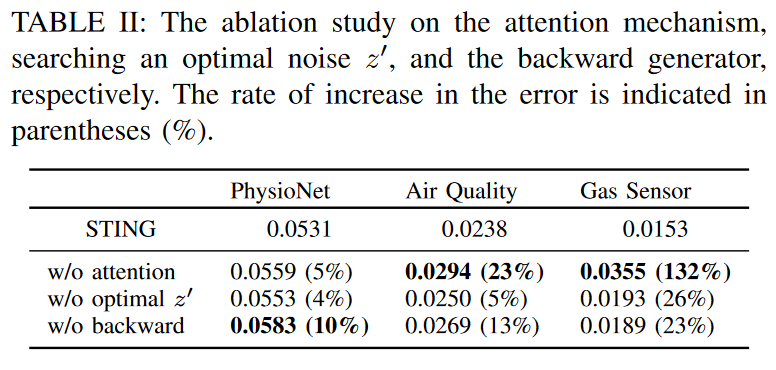
STINGの有効性の源泉となりうるのは、それぞれ、2つの注意モジュール、最適雑音z′の探索方法、後方生成器です。各主要機能がSTINGの性能向上にどのように影響するかを理解するため、アブレーション実験を行い、得られたアーキテクチャの性能をSTING全体のアーキテクチャと比較しました。そこで、3つのデータセットにおいて、STINGから1つの機能だけを除いた3つのモデルを実験しました。根拠となる真実の比率を観測値の20%とし、インプットした値でのRMSEを測定しました。
Table IIにアブレーションの結果を示しますが、すべてのケースでRMSEが増加しています。バックワードジェネレータを削除した結果は、PhysioNetで最も高いエラー率の増加を示しています。一方、注意モジュールを取り除いた結果は、Gas SensorとAir Qualityで最も高いエラー率の増加を示しています。このことは、提案するアテンションモジュールがSTINGにおいて比較的重要な機能を果たしていることを示唆しています。すなわち、シーケンス全体の相関を学習する過程で、どのようなデータセットにおいてもインピュテーションのための有意に重要な情報を生成しています。一方、最適なノイズz′を探索するモジュールは、比較的小さな効果しかありません。これは、zをランダムに生成しても、Xの観測値をSTINGのGの条件とするため、元のデータの実際の分布からよく一致するサンプルを作ることが可能であることを示しています。つまり、最適なノイズを用いないSTINGでも、元の時系列の分布を効率的に学習できる可能性があり、このプロセスは補完的な役割を担っていると言えます。
以上、他機種との比較実験により、STINGの有効性を実証しました。劣悪な条件下でも顕著な性能を発揮できた要因は主に2つあります。まず、GANのメカニズムがうまく機能し、元の時系列の真の分布に従うサンプルを生成することが確認できたことです。STINGがどのように設定されれば、望ましい分布に収束するのかを説明しました。特に、識別器の問題をWasserstein距離でより繊細に設定し、敵対的学習効果を最大化することを、GANを用いた先行研究と比較しながら説明しました。第二のキーファクターとして、提案した注意メカニズムがインピュテーションタスクにおいて有効であることを見出すことができました。STINGは、ある周期的なパターンやある時間ステップに注目することで、より多くの情報を取得することができました。この効果は、欠損率が高くなるほど顕著になり、インピュテーションの際に大量の情報を保持することの利点を明確に示しています。
まとめ
本論文では、生成的敵対ネットワークと双方向リカレントニューラルネットワークに基づき、時系列の潜在的表現を学習する多変量時系列データに対する新しいインピュテーション法であるSTINGを提案しています。また、時系列全体の重み付き相関を捉え、無関係な時間ステップからの潜在的なバイアスを防ぐために、新しい自己注視と時間注視のメカニズムを提案します。実世界のデータセットを用いた様々な実験により、STINGはインピュテーションの精度とインピュテーションされた値を用いた下流の性能の両方において、従来の最先端手法を上回ることが示されました。今後は、カテゴリ型を含むより一般的なデータのインピュテーションを調査する予定だとします。GANにとって、カテゴリ型データの生成は特に難しい問題です。GANのカテゴリ型データの生成とインピュテーションの可能性を検証することは、今後の研究課題だとしています。



この記事に関するカテゴリー






