Contrastive Learningの2大手法SimCLR・MoCo、それぞれの進化 (画像の表現学習2020夏特集2)
3つの要点
✔️ ビッグプレーヤー達がアプローチするContrastive Learning、その高い性能を競い合う
✔️ 大量なネガティブサンプルの必要性とその回避
✔️ 対抗手法の改善を取り込んで更に性能を向上させるバージョンアップ
Big Self-Supervised Models are Strong Semi-Supervised Learners (SimCLRv2)
written by Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, Geoffrey Hinton
(Submitted on 17 Jun 2020)
Comments: Published by arXiv
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
Paper Official Code COMM Code
Improved Baselines with Momentum Contrastive Learning (MoCo v2)
written by Xinlei Chen, Haoqi Fan, Ross Girshick, Kaiming He
(Submitted on 9 Mar 2020)
Comments: Published by arXiv
Subjects: Computer Vision and Pattern Recognition (cs.CV)
Paper Official Code COMM Code
ライター持ち込み特集企画「画像の表現学習2020夏」と題して、教師なし学習による各種手法をご紹介しています。
その1. ドメイン知識なし教師なし学習を実現したImage GPT、画像生成もすごい!
その2. Contrastive Learningの2大手法SimCLR・MoCo、それぞれの進化
その3. Contrastive LearningとクラスタリングでSOTA!?
その4. Contrastive Learningへの問い「What Makes?」
その5. 汎用性・実用性ともに優れたDeepMindの教師なし学習手法
二度に渡るAIの冬を乗り越え、大量の画像データセットImageNetで表現力を得ることで、2012年に画像のAIが大きく花開きました。しかし、これには人による画像のラベル付けに大きなコストが必要でした。これに対して、2018年に自然言語処理でフェイクニュースの懸念になるほど大きな社会的インパクトを与えたBERTは、莫大なデータをそのまま利用できることも大きな特徴です。
Contrastive Learning(対照学習)とは、コストのかかるラベル付けの代わりにデータ同士を比較する仕組みを使い、膨大なデータをそのまま学習できる教師なし学習の一つです。画像への応用で成果を上げてきており、すでにImageNet学習済みモデルの性能を超え、BERTのようにこれからのインパクトが画像分野で期待されています。
このContrastive Learning、近年数多くの論文が投稿され活況を見せています。
例えば Papers With Code (論文やそのコードをまとめた有名サイト)のリーダーボード "Self-Supervised Image Classification on ImageNet" (ImageNetの自己教師あり学習) を見ると、2020年・2019年に提案された手法でトップが占めらているのを見ることができます。
今回はトップ付近に出てくる手法の中で非常によく引用され、比較対象としても引き合いに用いられるデファクトスタンダードな手法「SimCLR」「MoCo」それぞれバージョン2に至るまでの道のりを取り上げます。
これらの論文が精度を上げるまで、どのような特徴や工夫、経緯があったのでしょうか。
まずは、基本的なモチベーションや狙い、そして基本となるContrastive Learningについて、おさらいしたいと思います。(詳しい方はどうぞスキップしてください)
なぜ画像の教師なし学習?
画像の機械学習はもうすでに当たり前のように応用され、十分に性能が出ている、そんな認識が広まっているように思われます。
前回の記事「ドメイン知識なし教師なし学習を実現したImage GPT、画像生成もすごい!」に今までの経緯について書きましたが、きっかけとしては自然言語処理 (NLP) で「BERT (Devlin et al., 2019)」が非常に大きな影響力を与えたことにあるかもしれません。
※ BERT について詳しくは本メディア「Googleが公開した自然言語処理の最新技術、BERTとは何者なのか」も御覧ください。
BERTをきっかけとして様々なタスクの性能が向上し、NLPの進歩が見られたことから、画像に対しても同じように教師なしでモデルを学習させることで、性能の向上が期待されました。また、
ImageNet学習済み → (転移学習) → 画像分類・物体検出・セグメンテーションなどのタスク応用
この使い方が定着している状況で、2018年にはImageNet学習済みモデルの利用に疑問を投げかけた論文が書かれました。物体検出でImageNetを使った転移学習で必ずしも性能が上がるわけではなく、むしろ使わないほうが良い場合もあることが示されたのです。

"Rethinking ImageNet Pre-training" (He et al., 2018)
ImageNet学習済みモデルの利用に一石を投じた
加えて、その当時すでに提案済みの事前学習手法が十分評価に耐えられる性能が出ていなかったようで、疑問を投げかけています。
万能な表現を追い求めるべきなのか? はい、万能な表現を学習することは努力に値する目標だと信じています。我々の結果はこの目標からそれているわけではありません。実際、我々の研究は、ランダムに初期化したときに良い結果を出せることを示したように、(自己教師あり学習で得られた)学習済みの特徴量の評価をもっと注意深く行うべきと示唆しています。
そして、この問題を提起した著者Heら自ら、下の結果を出しました。ImageNet学習済みモデルより、MoCoで自己教師あり学習したモデルのほうが物体検出の性能が上がることが示されたのです。
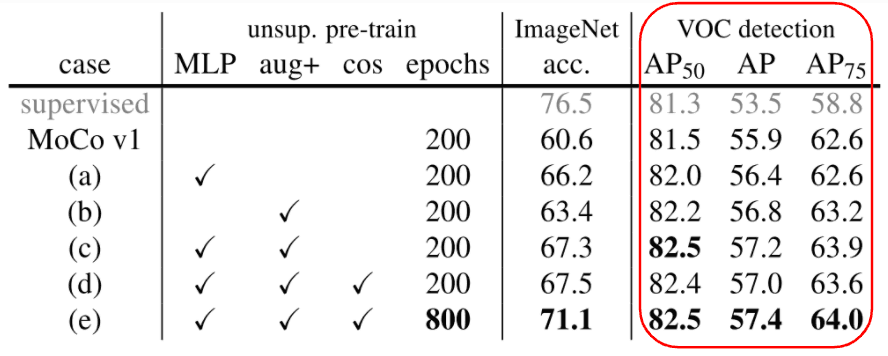
論文 MoCo v2のTable 1より、性能が上がることを実現した結果
- VOC detectionが物体検出の結果で「教師あり(supervised)」との比較。MoCoで事前学習した結果の方が精度が高いことが分かる。
- ただし、ImageNetの分類精度は教師あり(supervised)の方が高いままであることも特徴的。
また、NLP同様にインターネットの膨大なデータを有効活用して、データ量が多くなることで性能が上がることも期待されます。実際、莫大なデータを使うことで、すでにImageNet学習済みモデルの性能を上回っています。
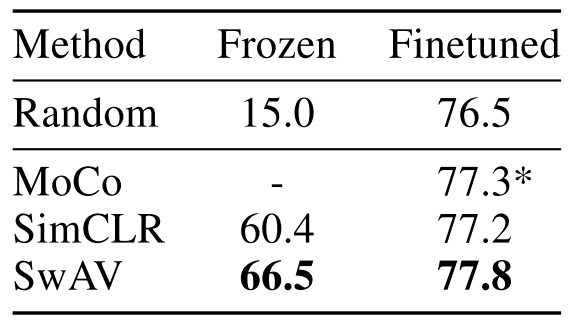 論文 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments (Caron et al., 2020)、Figure 1よりImageNetのTop-1精度
論文 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments (Caron et al., 2020)、Figure 1よりImageNetのTop-1精度
- Randomは通常のImageNet学習モデルの結果で、76.5%(ResNet-50)。
- 対する各手法は、どれもその結果を上回っている。→ 膨大な未選別Instagram画像を使って教師なし事前学習した結果。
教師なし学習にはいくつかの手法がありますが、その中で傑出した性能を実現したのがContrastive Learning(対照学習)です。
続きを読むには
(9919文字画像15枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






