高解像度画像翻訳の"超"高速化:ASAP-Net
3つの要点
✔️ 画像翻訳タスクにおいて、既存手法と比較して大幅な高速化に成功
✔️ 高解像度を低解像度における演算に落とし込む
✔️ 高速化したにもかかわらず、生成画像の品質は既存手法と同程度
Spatially-Adaptive Pixelwise Networks for Fast Image Translation
written by Tamar Rott Shaham, Michael Gharbi, Richard Zhang, Eli Shechtman, Tomer Michaeli
(Submitted on 5 Dec 2020)
Comments: 1Accepted to arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
はじめに
画像をあるドメインから別のドメインへ変換するタスクは近年広く研究されています。現在のアプローチは条件付きGANを用いて、一方のドメインから別のドメインへの直接的なマッピングを学習します。これらのアプローチは、視覚的な生成画像の品質という点では急速に進歩していますが、モデルのサイズや計算量も大幅に増加しています。このような莫大な計算量は、実世界でのアプリケーションで用いようとする場合にとても深刻な問題となります。
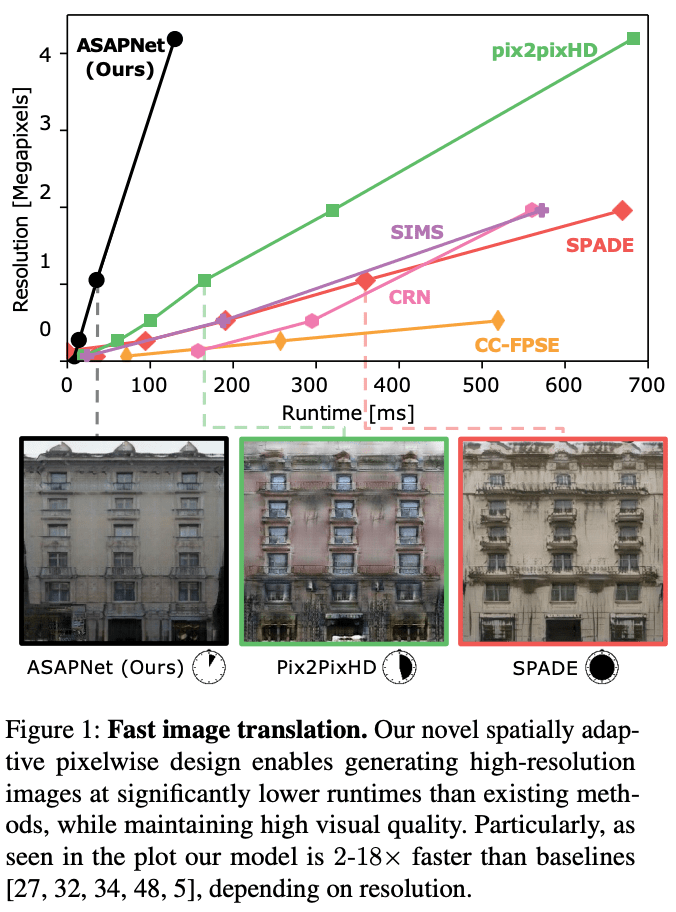
本論文では画像のスタイル変換タスクの高速化を目的として新しいアーキテクチャを開発しています。ASAP-Net(A Spartially-Adaptive Pixcelwise Network)と名付けられたそのモデルは高解像度の入力に対しても非常に短い時間で画像を生成することができます(Figure 1)。
手法
先にも述べましたが、タスクは2つの画像領域間のマッピングを行うようにNNを学習することです。すなわち、入力画像$x\in R^{H\times W\times 3}$が与えられたとき、生成画像$y\in R^{H\times W\times 3}$はターゲットドメインに属するような見た目でなければなりません。本論文の目的は、既存手法よりも効率的でありながら、既存手法と同程度の品質をもつ出力を得られるようなネットワークを構築することです。
画像の中身を分析・理解することは複雑なタスクであり、それに応じて深いNNが必要ですが、この分析はフル解像度で行う必要はないと本論文では考えています。まず、軽量で並列化が可能な演算子を用いて高解像度のピクセルを合成します。次によりコストのかかる画像解析を非常に粗い解像度で実行します。この設計によりフル解像度での計算を最小限に抑え、非圧縮性の重い計算をより小さな入力で実行しながらも高い品質の画像を生成することが可能となります。
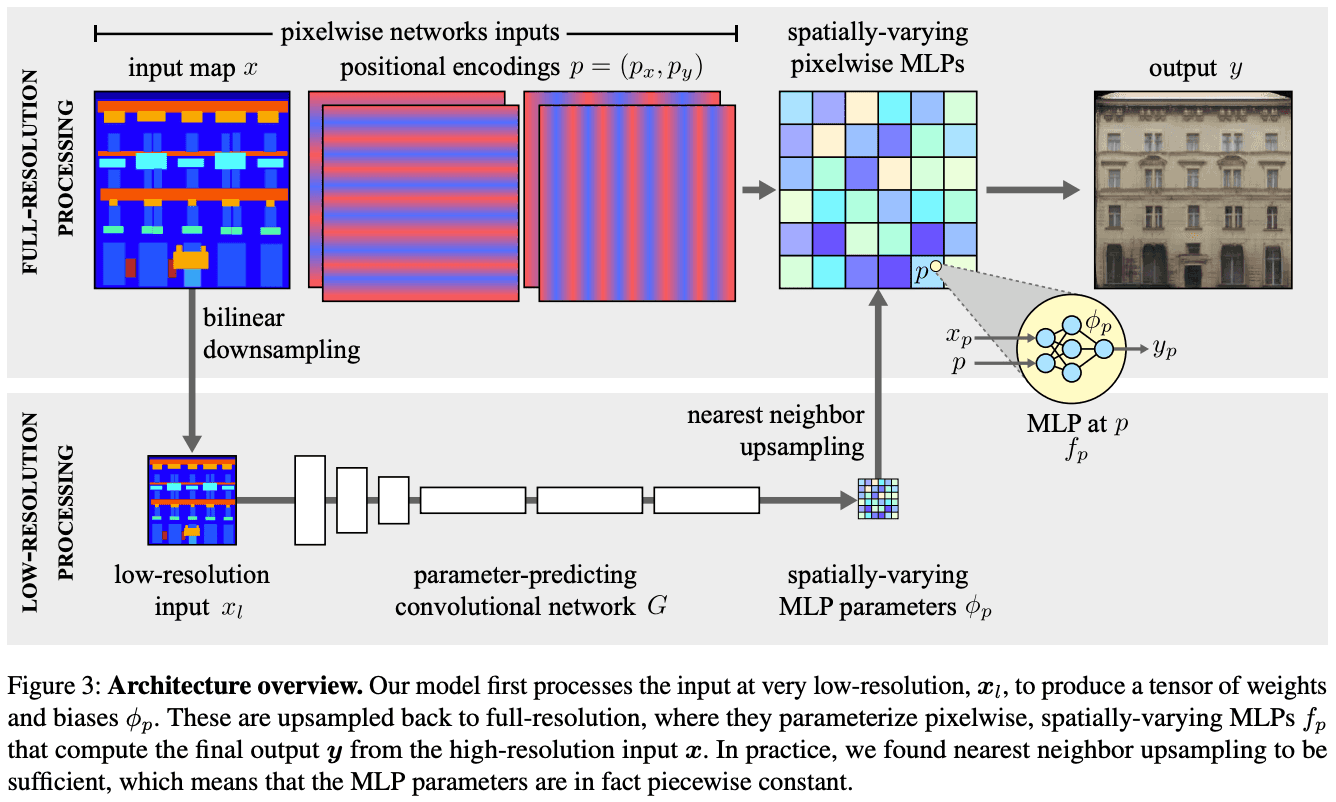
提案手法のアーキテクチャの全体図は以下のFigure 3です。
Pixelwise Networks
入力がフル解像度の場合、計算量がとても多くなります。実行時間を抑えるためにポイントごとの非線形変換$f_p$をモデル化します。ここで、$p$はピクセルの座標を表します。この処理はFigure 3の上に該当します。各ピクセルは他のピクセルから独立して考えるため計算を並列化することが可能となります。しかし、各ピクセルを独立して考えるということは慎重に設計しないとモデルの表現力がかなり制限されてしまいます。
空間情報を保持するために、2つのメカニズムを用いています:
- 各ピクセル単位の関数$f_p$は色値$x_p$に加え、ピクセルの座標$p$を入力とする
- ピクセル単位の関数$f_p$は空間変数$\phi_p$でパラメータ化され、具体的には多層パーセプトロン(MLP)であり、以下のようなマッピングが定義されている

式(1)において、$f$はMLPアーキテクチャ(すべてのピクセルで共通)を、$\phi_p$はMLPの重みとバイアス(空間的に変化する)を表しています。MLPは、5層かつ1層あたり64チャネルが短い実行時間でよりよい品質の画像を生成することを発見しました。
入力画像が異なればピクセルごとのパラメータのセットも異なります。入力順応性と空間的に変化するパラメータという2つの特性がなければ、提案手法は$1\times 1$の畳み込み層を積み重ねただけの表現力の低いモデルとなってしまいます。
Predicting pixelwise network parameters from a low-resolution input
適応的な変換を行うためには$\phi_p$が入力画像の関数であることが必要です。しかし、各ピクセルのパラメータベクトル$\phi_p$を個別に予測することは、非常に困難です。その代わりとしてはるかに低解像度の画像$x_l$で畳み込みニューラルネットワーク$G$によって予測されます。具体的には、ネットワーク$G$は、$x$よりも$S$倍小さい解像度のパラメータのグリッドを出力します。このグリッドはnearest neighbor interpolationを用いてアップサンプリングされ、以下のようになります。
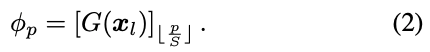
Figure 3の下部にあるように、低解像度の計算ではまず$x$を係数$S_1$でバイリニアにダウンサンプリングして$x_l$を得ます。この画像は$G$によって処理されます。$G$を用いてさらに係数$S_2$で縮小します。$G$の最終的な出力は、フル解像度を持つピクセル単位のネットワークの重みとバイアスに対応するチャンネルを持つテンソルです。ここでは$S_2=16$を使用し、$x_l$が最大256ピクセルを持つように$S_1$を設定します。したがって、ダウンサンプリングの合計$S$は画像サイズに依存します。つまり、低解像度の処理は、入力画像の非常に低い解像度の表現を処理することで$G$の計算量を劇的に減らすことができます。
提案手法の関数パラメータ$\phi_p$は低解像度で予測された後にアップサンプリングされます。そのため高解像度を詳細に予測する能力はやや制限されます。提案手法では、ピクセル単位の関数$f_p$を拡張して、ピクセル位置$p$のエンコーディングを追加入力として受け取ることでこれを回避しています。CPPN(Compositional Pattern-Producing Networks)のように空間的に変化するMLPはパラメータのサンプリングよりも細かく学習することができます。さらに、NNには低周波信号を最初に学習するスペクトルバイアスがあることがわかっています。そこで、式1のように$p$を直接MLPに渡すのではなく、2次元の画素位置$p=(p_x,p_y)$の各成分をアップサンプリング係数よりも高い周波数の正弦波のベクトルとして符号化することが有効だと考えられました。各MLPは画素値$x_p$に加えて、$2\times\times k$個の追加入力をします。このエンコーディングはFigure 3の上部分に該当します。
実験
実験設定
画像翻訳タスクにおいて提案手法の性能を検証します。特に実行時間と画質を先行研究と比較します。
- モデル
- Ours(ASAP-Net)
- CC-FPSE
- セマンティック領域を認識する新しい条件付き畳み込み層を導入
- SPADE
- 空間的に適応した正規化を用いてセマンティック画像からリアルな画像へ変換
- pix2pixHD
- SIMS
- セグメントの構成を改良
- CRN
- 高解像度変換
- データセット
- CMP
- 400組の建築画像
- 360/40枚で訓練/推論データにわける
- 512*512,1024*1024
- Cityscapes
- 都市風景の画像とそのセマンティックラベルマップ
- 3000/500
- 256*512,512*1024
- NYU depth dataset
- 屋内風景画像1449枚
- 1200/249
- CMP
実験結果
・推論時間
Nvidia GeForce 2080 ti GPUを用いた。解像度にもよるが、提案手法はpix2pixHDと比べて最大6倍、SPADE,SIMS,CRNと比較して18倍の速度となっています。Figure 1をみると、提案手法の優位性は高解像度となるほどみられることがわかります。この理由として、提案手法は低解像度の畳みこみストリームが画像サイズに対してほぼ一定であることが挙げられます。
・生成画像の質
生成された画像はベースラインモデルに匹敵する視覚的品質を持っていることがわかります。


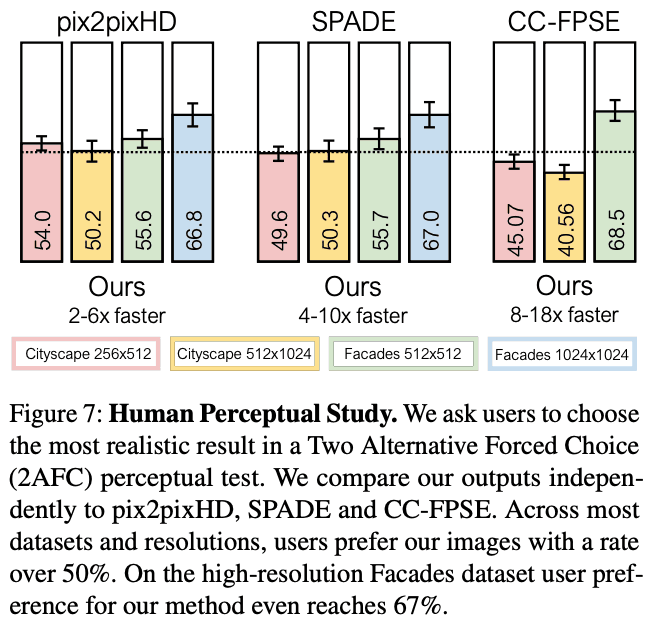
・人間による評価
AMTを用いて人間による生成画像の評価を行う。提案手法とベースラインモデルの生成画像がどちらがよりリアルに見えるかを尋ねた。Figure 7を見るとユーザは提案手法をベースラインモデルと同程度に評価していることがわかります。
 ・ 定量的評価
・ 定量的評価
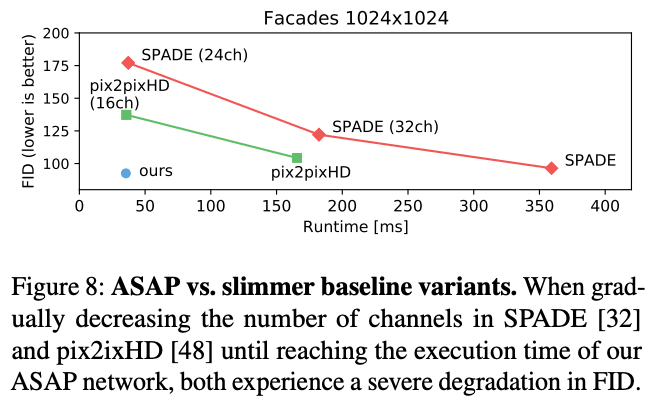
生成画像の品質を定量的に評価します。まず、生成画像をセマンティックセグメンテーションネットワークに通します。そしてFIDスコアを出し比較を行います。Figure 8を見ると、提案手法とpix2pixHD・SPADEは同程度のスコアを出していることがわかります。つまり提案手法はベースラインモデルと同程度の質を出しているにも関わらず実行時間がかなり短縮されていることがわかります。ベースラインモデルを提案手法と同程度の実行時間にするようにパラメータ数を削減するとFIDスコアが著しく低下していることがわかります。
まとめ
本論文では、敵対的画像変換タスクに対して特に高速化に着目したアーキテクチャを提案しました。高解像度の画像を低解像度の処理に落とし込み高速化をするにも関わらず、既存手法と同程度の品質の画像を生成することができました。低解像度で計算が行われているため画像サイズの3%以下の物体によってわずかにスコアが落ちてしまうことがあることに注意が必要です。





この記事に関するカテゴリー



