
【SCoRe】LLMの自己修正能力を高める強化学習!多段階的にエラーを特定して修正する
3つの要点
✔️ 自己修正能力を高めるため、強化学習を用いたSCoReという新手法を提案
✔️ 従来手法よりも精度を向上させ、特に数学やコーディングタスクで高いパフォーマンスを発揮
✔️ SCoReは自己生成データに基づく学習を行い、外部フィードバックなしでの自己修正が可能
Training Language Models to Self-Correct via Reinforcement Learning
written by Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, Aleksandra Faust
(Submitted on 19 Sep 2024)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
背景
従来の言語モデルでは、自身のエラーを修正することが難しいとされており、特に外部からのフィードバックなしに修正する「内在的自己修正」は、ほとんど成功していません。この問題を解決するために、SCoReでは自己生成データを用いて強化学習を行い、モデルが自身の回答を逐次修正できるように訓練します。
従来の手法では、モデルがエラーを修正するために複数のモデルや外部の指導者が必要でしたが、SCoReは単一のモデルで自己修正を実現することを目指しています。このアプローチの背景には、既存の学習方法がモデルに特定の修正パターンのみを強制してしまい、テスト時に有効な自己修正ができないことが挙げられます。SCoReはこの問題に対処するために、モデルが自ら生成したデータに基づいてオンラインで強化学習を行い、モデルがより効果的に自己修正を学習できるように設計されています。
提案手法
SCoReの革新性は、自己生成データを用いてモデルが複数回の試行を行い、エラーを特定して修正する方法を学習する点にあります
- まずベースモデルを初期化し、第一段階では最初の回答の精度を保ちながら、2回目の回答での修正を強化します。
- そして、第二段階では、修正をさらに促進するための報酬ボーナスを用いて、モデルが効果的に自己修正できるように学習します。
この2段階のアプローチにより、テスト時にもモデルが自身の誤りを正確に修正できるようになります。
例えば、数学やプログラミングの問題に対して、SCoReは初回の解答が誤っていた場合でも、モデル自身がその間違いを検出し、次の試行でより正確な解答を導き出します。この過程では、正しい部分を維持しつつ、誤りのみを修正することが求められます。SCoReは、この自己修正のプロセスを強化学習で学び、最終的に修正後の精度を大幅に向上させることに成功しています。
この手法により、特に外部フィードバックのない環境での自己修正能力が大幅に向上し、従来の方法に比べて15.6%の精度向上を達成しています。
実験
この論文の実験では、SCoRe(Self-Correction via Reinforcement Learning)が他の手法と比較してどの程度効果的に自己修正を行えるかを検証しています。実験は主に数学問題の解決とプログラムコードの生成という2つの異なるタスクで行われました。
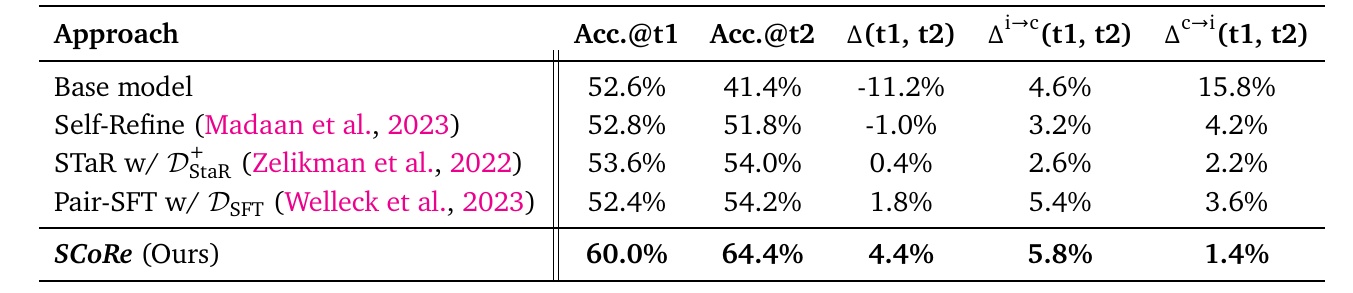
数学問題に関しては、MATHデータセットを用いて、まずベースモデルの性能を評価しました。次に、SCoReを適用し、初回の回答と2回目の回答を比較して、モデルが自己修正できるかどうかを確認しました。結果として、SCoReは初回の回答精度を60.0%から64.4%に向上させ、自己修正によって正確性が高まることが確認されました。特に、初回の回答が誤っていた場合に正しい解答に修正される割合が増加し、誤った修正が行われるケースは減少しました。
また、プログラムコードの生成に関しては、HumanEvalという評価基準を用いて、SCoReがコーディングタスクでも自己修正を行えるかを確認しました。このタスクでは、初回の解答が誤っていた場合に、SCoReは2回目の試行で精度を12.2%向上させることに成功しました。これにより、プログラムのエラー修正能力が大幅に向上し、特にプログラムの一部を保持しながら誤りを修正する能力が確認されました。
さらに、SCoReは計算資源を効率的に使用することができ、少ない試行回数で優れた結果を得ることができました。これは、従来の手法と比較して、モデルが効果的に自己修正を学習し、より少ない計算リソースで高い精度を実現できることを示しています。
このように、SCoReは複数の分野において、自己修正能力を持つモデルの学習において高い効果を発揮していることが実証されました。
結論
この論文の結論として、SCoRe(Self-Correction via Reinforcement Learning)は、大規模言語モデル(LLM)が自己修正能力を持つための効果的なアプローチであることが示されました。
さらに、SCoReは単に誤りを修正するだけでなく、正しい解答を維持しつつ、不要な変更を避けることにも成功しています。これにより、モデルは過度に保守的な修正ではなく、適切な範囲で修正を行い、正確性を高める能力を獲得しました。今後の研究では、より複数回にわたる自己修正の有効性を高める方法や、さらなる強化学習の工夫が期待されます。
図表の解説
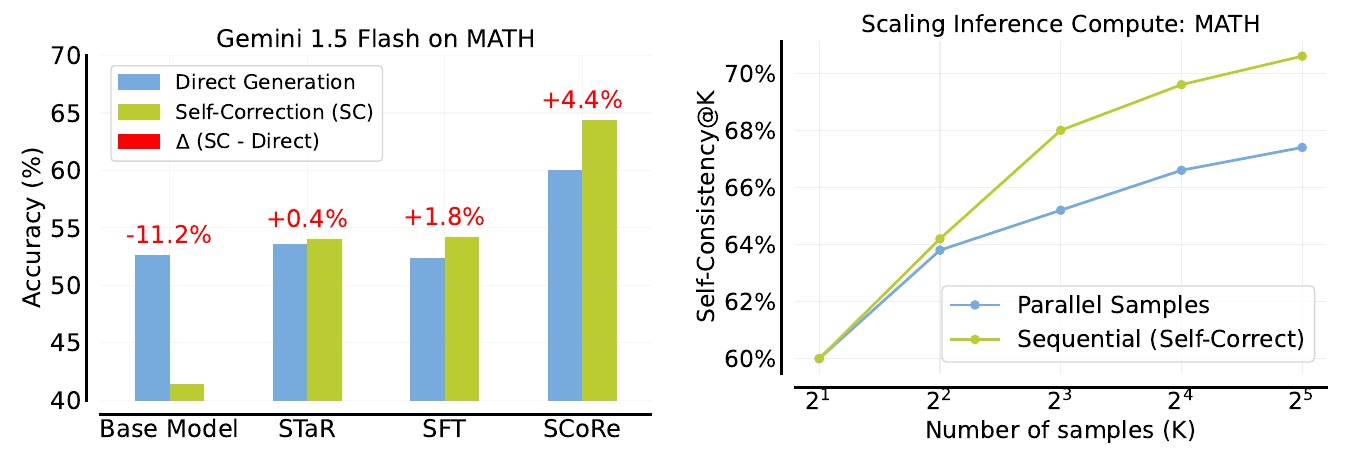
この図表は、言語モデルの自己修正能力を評価するための実験結果を示しています。具体的には、数学の問題を用いたテストでのモデルの性能を比較しています。
左側のグラフでは、Base Model、STaR、SFT、およびSCoReという4つの異なる手法における正答率(Accuracy)が示されています。Base Modelは元のモデルであるのに対し、他は異なる学習手法を用いて改善を試みたモデルです。青色のバーは直接問題を解く正答率を示し、緑色のバーは自己修正後の正答率を表しています。赤文字の数値は自己修正によってどの程度改善されたかを示しており、SCoReが最も高い改善率(+4.4%)を示しています。SCoReは他の手法に比べても正答率が高いことがわかります。
右側のグラフは、並列サンプリングと自己修正による逐次サンプリングの性能を、サンプル数を増やした際の一貫性(Self-Consistency)で比較しております。縦軸は一貫性の割合を示しており、横軸はサンプル数を表しています。緑色のラインは自己修正を使った逐次サンプリングである一方、青色のラインは並列サンプリングを示しています。サンプル数が増えるに従い、逐次サンプリングの方が一貫性が高くなることが示されています。
この結果から、言語モデルが自己修正する能力が、数学の問題解決において有効であり、大規模なデータ処理においても効果的であることが示唆されています。
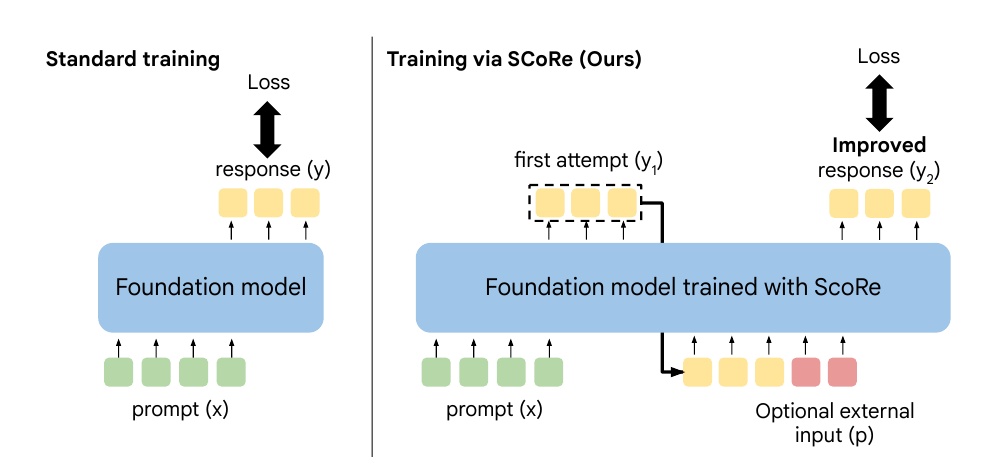
この図は、2つの異なる機械学習モデルのトレーニング方法を示しています。
左側は「標準的なトレーニング方法」を示しています。ここでは、基礎モデルが「プロンプト(x)」を入力として受け取り、「応答(y)」を生成するプロセスです。この際、生成された応答に基づいて損失(Loss)が計算され、その情報をもとにモデルの改善が行われます。
右側は「SCoReによるトレーニング方法」を示しています。この方法では、まずモデルが最初の試行として応答(y₁)を生成し、その後「オプショナルな外部入力(p)」を使ってモデルが自己訂正を行い、改善された応答(y₂)を生成します。これに基づいて損失が計算され、モデルを改善します。このプロセスにより、モデルは初期の応答を自己訂正しながらより良い結果を目指します。
SCoReのアプローチは、自己訂正を通じた応答の精度向上を目指しており、標準的な手法に比べてより効果的なトレーニングを実施しています。
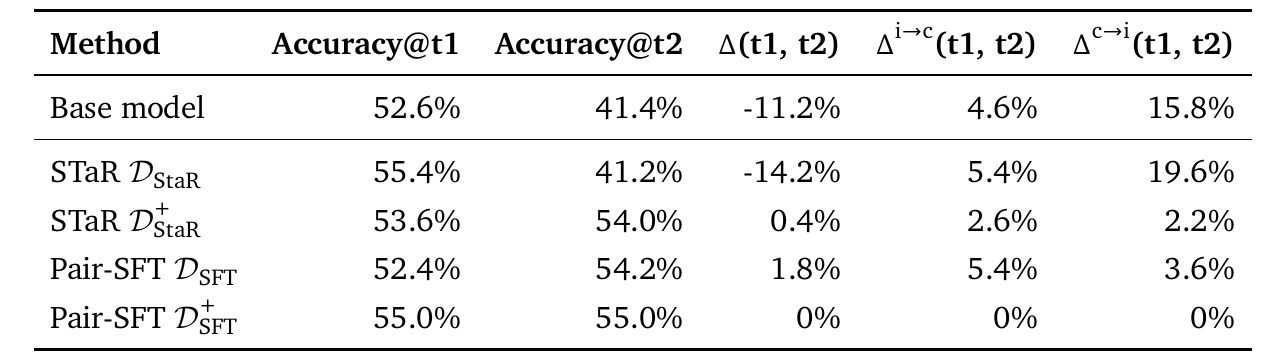
この表は、自己訂正能力に関するさまざまなモデルの性能を比較しています。特に注目すべき点は以下の通りです。
まず、"Accuracy@t1" と "Accuracy@t2" は、1回目と2回目の試行におけるモデルの正確性を示しています。例えば、ベースモデルの1回目の正解率は52.6%ですが、2回目には41.4%に低下しています。このことから、最初の回答からの改善は見られないことがわかります。
次に、"Δ(t1, t2)" は1回目から2回目への正確性の変化を示し、数値が高いほど改善が大きいことを意味します。ベースモデルは-11.2%で、2回目の試行でパフォーマンスが下がっています。
また、"Δi→c(t1, t2)" は最初に間違えた問題が2回目で正解になる割合を示し、この値が高いほど自己訂正が効いていると言えます。たとえば、Pair-SFT D_SFTは5.4%であり、一定の自己訂正が成功していることを示しています。
一方、"Δc→i(t1, t2)" は最初に正解だった問題が2回目で間違えになる割合を示します。低いほど望ましい結果です。ベースモデルは15.8%で、2回目で大きく正確性を落としていることがわかります。
この表を通じて、自己訂正の困難さや、各手法の改善点、課題点を把握することが重要です。さまざまな方法で多角的にモデルの性能を比較し、効果的な自己訂正モデルの開発に繋げることが期待されます。
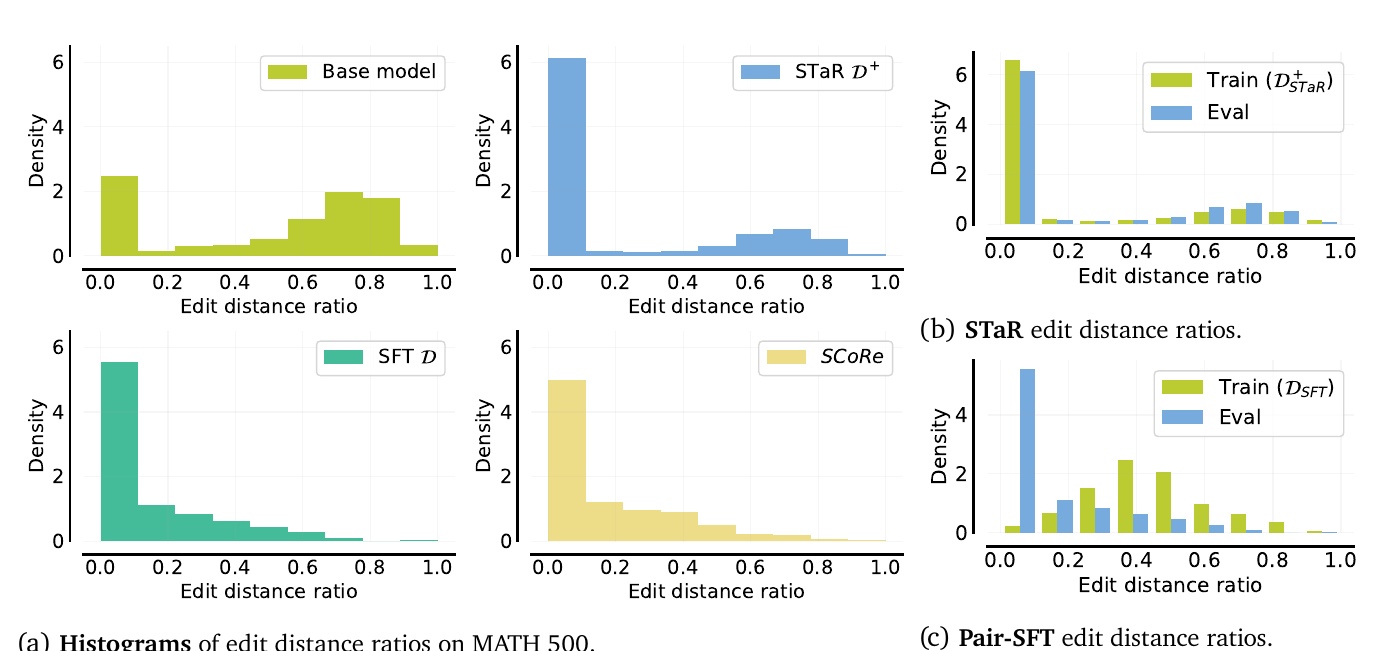
この図は、異なる手法による編集距離の割合を示したヒストグラムです。編集距離の割合とは、モデルがどの程度自己修正を行うかの指標で、0に近いほど変更が少ないことを意味します。
左上に示された「Base model」の図は、元のモデルが比較的多くの変更を加えたことを表しています。全体的に修正が幅広い範囲にわたっていることがわかります。
右上の「STaR D⁺」は、修正がほとんど行われず、変更が少ないことを示しています。モデルがあまり自己修正を行わない傾向が見られます。
左下の「SFT D」の図は、修正がわずかに行われていることを示しており、多くの場合で修正が少ないことがわかります。
右下の「SCoRe」の図では、修正が中程度行われていることが示されています。これは、自己修正が効果的に行われたことを示している可能性があります。
「b」と「c」の図は、異なるデータセットでの編集距離の割合を示しています。トレーニングデータと評価データでの編集距離の違いが視覚的に示されており、「b」ではSTaR、そして「c」ではPair-SFT手法の結果が示されています。
全体としてこれらの図からは、異なるモデルの自己修正能力の違いを視覚的に比較することができます。それぞれの手法の特徴をつかむことで、モデルの改善点を見出すことが可能です。
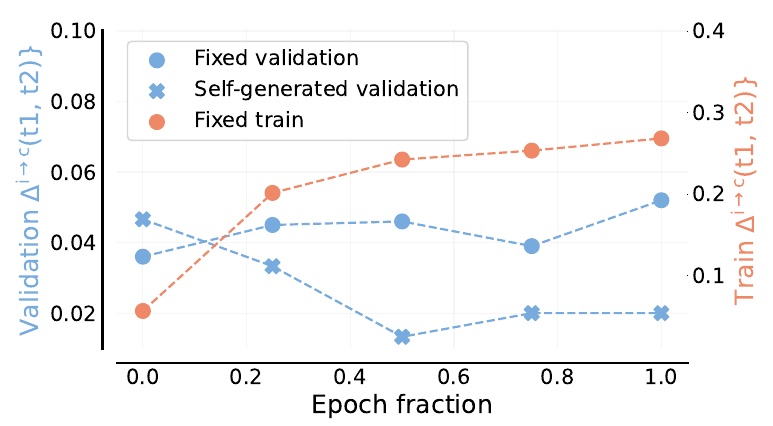
この図は、モデルの自己修正能力を異なる条件下で評価した結果を示しています。縦軸は修正によって正しくなった割合を示し、横軸はエポックの進行状況を表しています。オレンジの線は固定されたデータでの訓練を示し、青の線と水色の×印はそれぞれ固定された検証データと自動生成された検証データでの結果を示しています。
はじめに訓練データでは、エポックの進行に従って正しくなる割合が増えていきます。一方、固定された検証データでは、成績の向上が観察されますが、自動生成された検証データではあまり一定せず、成績の向上は控えめです。
図から分かるように、固定されたデータでは学習が進むにつれて自己修正の能力が向上しますが、自動生成されたデータではこの効果があまり見られません。これにより、データの種類によってモデルの自己修正能力に違いがあることが示唆されています。
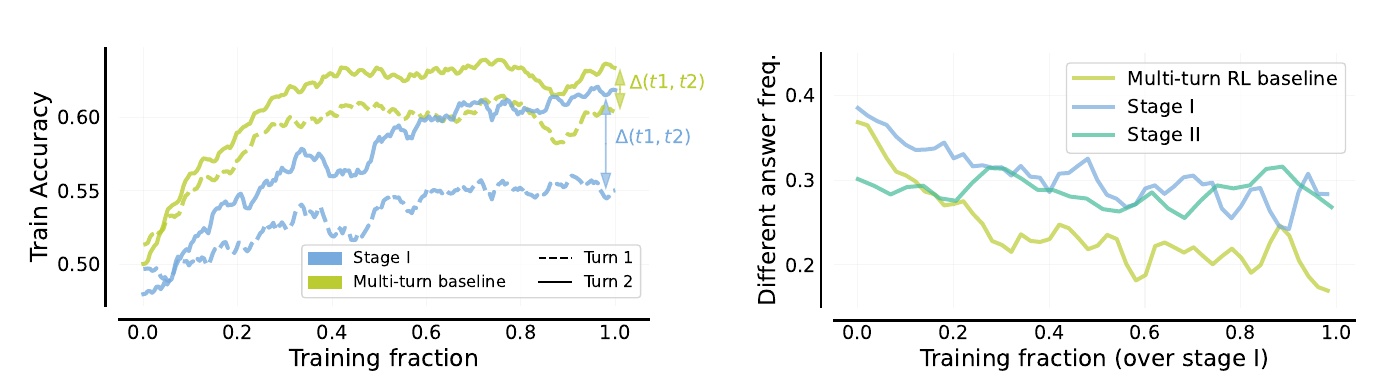
図の左側は、訓練の進行状況に対する精度の変化を示しています。「Stage I」と「Multi-turn baseline」は、各試行における精度を比較しています。左側のグラフでは、青色の線が示しているように、「Stage I」では訓練の進行とともに精度が向上していきます。緑色の線は「Multi-turn RL baseline」を表し、こちらも精度の向上が見られますが、Stage Iよりも一貫性が劣ります。特に「Turn 2」では、Stage Iがより優れた結果を出していることがわかります。
右側の図は、異なる答えを提案する頻度を示しています。「Stage I」と「Stage II」および「Multi-turn RL baseline」を比較していますが、青とグリーンの線で示されるStage IとStage IIが頻度を保ちながら段階的に減少する傾向があります。これは、訓練が進むにつれ、モデルが以前と同じ答えを出す頻度が減少していることを示しており、学習による改善が表れています。一方、緑色の「Multi-turn RL baseline」は、同じような減少を示していますが、最終的にはStage IIを下回る傾向があります。
これらの結果は、自己修正能力を高めるために多段階の訓練手法が有効であることを示しており、特にStage IとStage IIの組み合わせが有用であることを示唆しています。
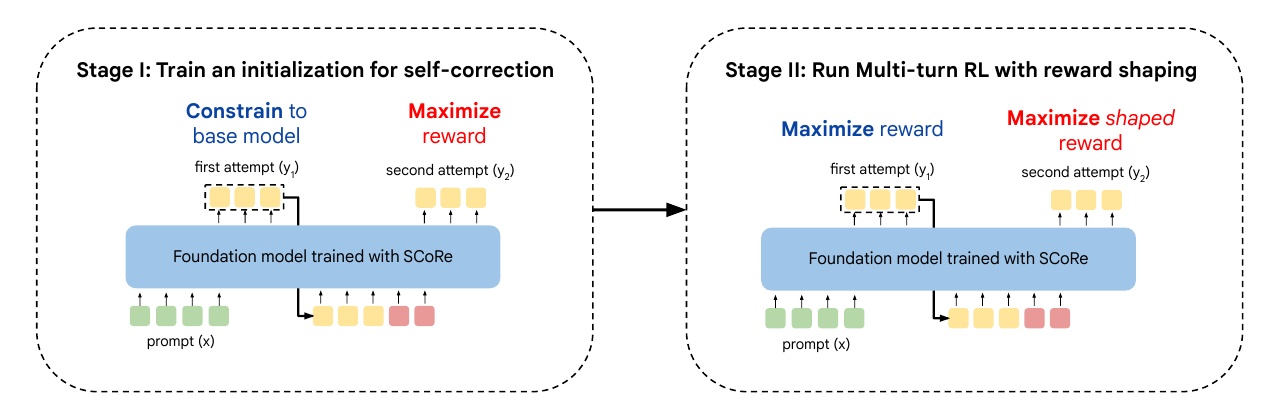
この図は、SCoReと呼ばれる自動訂正のための学習手法を説明しています。SCoReは、二段階の強化学習(RL)プロセスを通じてモデルに訂正能力を持たせるものです。
- Stage I(第一段階)では、基礎となるモデルに対して初期化を行います。この段階では、モデルが誤りを訂正するための第一歩として、最初の試み(first attempt)の出力を基礎モデルに近く保つことを重視します。これにより、モデルがもともとの性能を維持しながら、次の試み(second attempt)での報酬を最大化することに焦点を当てます。
- Stage II(第二段階)では、多回ターンの強化学習を用いて、さらなる最適化を行います。このステージでは、最初の試みと次の試みにおける報酬を最大化することを目指しますが、特に次の試みでは、「形を整えた」(shaped)報酬を活用し、自己修正の進捗を促進します。これは、モデルがより良い答えに辿り着くための指導として機能します。
このように、段階的にアプローチを変えることで、モデルが効果的に自己訂正を行えるように設計されています。
論文の図表は、異なる手法によるモデルの自己修正性能の比較を示しています。ここでは、まずモデルトレーニングの4つの異なる方法と、それぞれの自己修正性能を示した5つの指標が示されています。
1. Accuracy@t1とAccuracy@t2は、1回目の試行時点と2回目の試行時点のそれぞれにおける正確さを示します。
2. デルタ(t1, t2)は、2回目の試行でどれだけ正確さが改善されたかを示す指標です。
3. Δi→c(t1, t2)は、1回目で間違っていたものが2回目で正しくなった割合を示しています。
4. Δc→i(t1, t2)は、1回目で正しかったものが2回目で間違った割合を示します。
この結果から、「SCoRe」という手法が最も高い自己修正性能を示しています。具体的には、Accuracy@t1とAccuracy@t2の両方で他の手法よりも高いパフォーマンスを達成しており、特にDelta(t1, t2)で4.4%の改善を示しました。これは他の手法と比べて顕著に高く、修正能力の向上を意味しています。また、Δi→cの値も5.8%と最も高く、この点でも優れた自己修正能力を持っていると言えます。一方で、Δc→iは1.4%と低く、間違って上書きされる割合が少ないことを示しています。
全体として、この図表は「SCoRe」が他の手法に比べて自己修正に優れたモデルであることを示していると言えます。
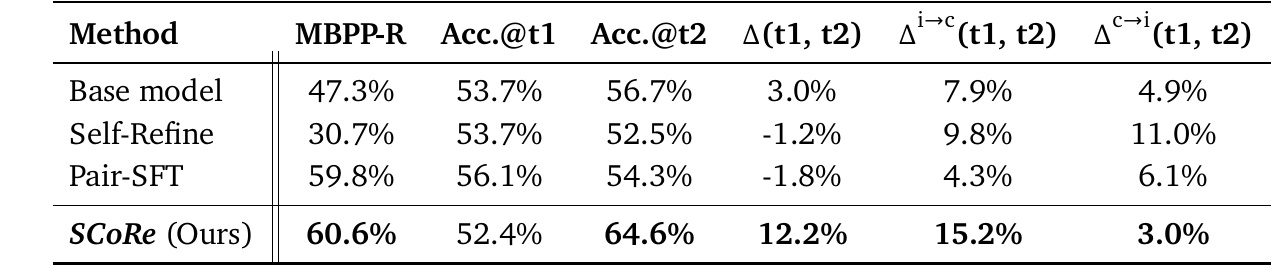
この表は、複数のモデルが特定のタスクにおいてどの程度の性能を発揮するかを示しています。評価基準には、初回と2回目の試行時の正確さ(Accuracy)や、その改善率が含まれています。
1. MBPP-Rは、各モデルが特定のコード生成タスクで達成した正確さの割合を示します。ここでは、SCoReが60.6%で最も高い性能を見せています。
2. Acc.@t1とAcc.@t2はそれぞれ初回(t1)と2回目(t2)の試行時の正確さを表します。SCoReは2回目の試行で64.6%となり、他のモデルを上回っています。
3. Δ(t1, t2)は、1回目から2回目の試行にかけての改善率です。これもSCoReが12.2%と最も高い向上を見せています。
4. Δi→c(t1, t2)は、1回目で不正解だった問題が2回目で正解になった割合を示します。SCoReは15.2%で、他の手法より高い改善を示しています。
5. Δc→i(t1, t2)は、1回目で正解だった問題が2回目で不正解になった割合です。ここでSCoReは3.0%と、他のモデルと比べて相対的に低いことが示されており、解答の劣化が少ないことを示しています。
この表から、SCoReが他の手法に比べて全体的に高い性能を発揮していることがわかります。特に自己修正能力に優れており、最初の試行後の結果を大きく改善しています。
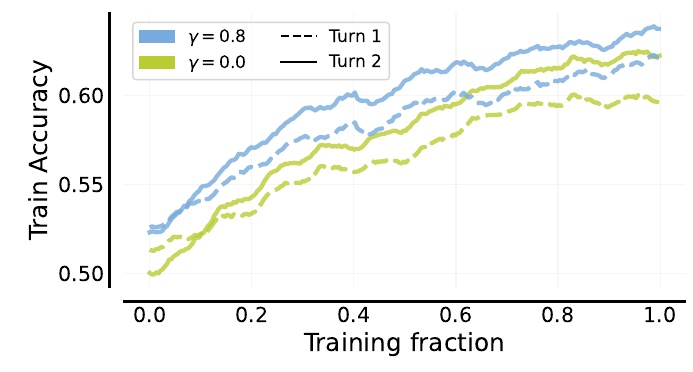
この図は、機械学習のモデルがどのように訓練データを用いて精度を上げていくかを示しています。上部にある凡例によれば、γというパラメータが異なる2つの条件(γ=0.8とγ=0.0)で、モデルが訓練されています。このγは、標準的な強化学習の設定におけるディスカウントファクターと考えられます。
図の横軸は「Training fraction」を示しており、これは全訓練データの中でどのくらいの割合が使用されたかを表しています。つまり、0.0から1.0までの範囲で段階的にデータが使われていく様子を示しています。
縦軸は「Train Accuracy」で、これはモデルの訓練精度を表しています。線の種類も重要で、「Turn 1」と「Turn 2」と書かれた破線および実線があります。これらは、各γの設定での1回目と2回目の試行での精度を示しています。
γ=0.8の青色の線は、1回目と2回目の試行での精度が比較的高く、訓練が進むにつれて精度が向上していることを示しています。一方、黄色のγ=0.0では、精度が少し低い傾向にあります。
これにより、ディスカウントファクターが訓練精度に与える影響を比較することができ、効果的なパラメータ設定について考察できる内容になっています。
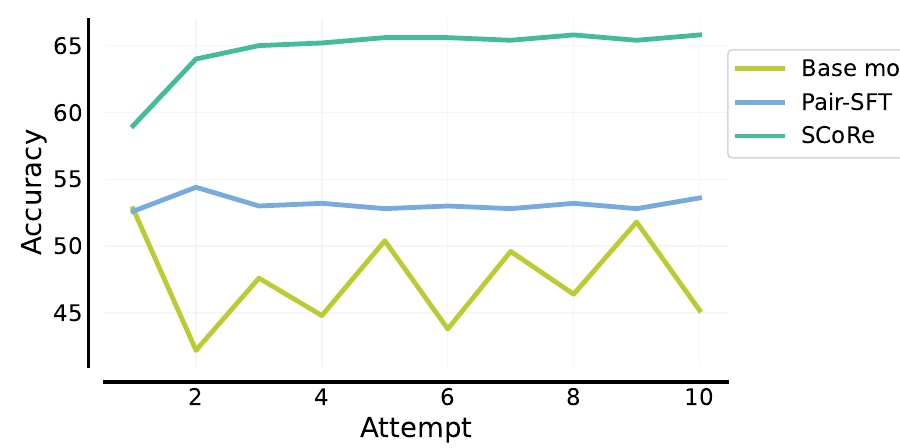
この図は、機械学習のモデルが「試行」回数に対してどれだけの精度(Accuracy)を達成したかを示しています。縦軸が精度を、横軸が試行回数を表しています。具体的に、三つの異なるアプローチのパフォーマンスが比較されています。
まず、緑色の線で示されているのがSCoReという新しいアプローチです。このアプローチは、試行回数が進むにつれて高い精度を維持しており、他の手法と比べてもそのパフォーマンスの一貫性が際立っています。
次に、青色の線で表されているのがPair-SFTです。この手法は、SCoReほど高い精度には達していませんが、比較的安定しています。
そして、黄色の線で示されているのがBase modelです。このアプローチは、精度がどちらかといえば低く、試行ごとの変動が大きいことがわかります。
この図からは、SCoReが他の手法と比較して高い精度を達成し、安定した結果を出していることが理解できます。特に、試行の回数が増えてもその傾向が続いている点が特徴的です。このことは、SCoReが自己修正能力に優れていることを示しており、新しい学習アプローチとしての効果を表しています。

この図表は、Gemini 1.5 FlashとGemini 1.0 Proという2つの異なる基礎モデルのハイパーパラメータの設定を示しています。ハイパーパラメータとは、モデルの学習を調整する際に外部から設定するパラメータのことです。
左側の表はGemini 1.5 Flashモデルに関する情報を示しています。最適化アルゴリズムとして「Adam」が使用されています。学習率は「5e-6」で、学習ステップ数は3000回です。バッチサイズは512で、サンプリングの際の温度は1.0に設定されています。さらに、αの値は10、β1は0.01、β2は0.1です。
右側の表はGemini 1.0 Proモデルの設定です。最適化アルゴリズム、サンプリングの温度、α、β1は左のモデルと同じですが、学習率は「1e-5」になっており、学習ステップ数は1500回と少ないです。また、バッチサイズも128と小さく設定されています。β2だけが異なっていて、こちらは0.25です。
これらの設定は、モデルの性能に大きく影響を及ぼしますので、各モデルの目的に応じた適切な設定が求められます。

この画像は、Pythonプログラミングにおけるいくつかのタスクを示しています。まず、`similar_elements`という関数があり、これは2つのタプルに含まれる共通の要素を見つけて、それをタプルにして返す関数です。この関数は、`set`を使うことでリストの重複を排除しながら共通部分を探します。
次に、`is_not_prime`という関数があります。この関数は、与えられた整数が素数でないかどうかを判定します。平方根までのループを用いて、2からその数の平方根までの整数で割り切れるかを確認します。どちらかで割り切れれば、素数ではないとして`True`を返します。そうでなければ`False`を返します。
これらの関数は、例としていくつかのテストケースを示しており、それぞれの関数が意図された動作をすることを確認するために使われています。これにより、異なるプログラムタスクに応じてPythonでのコーディングスキルを活用する例となっています。

この図はPythonのコードを示しています。このコードは、2つの単語を入力として受け取り、2番目の単語またはその任意の回転が最初の単語の部分文字列であるかを判定します。
具体的には、forループを用いて2番目の単語の各回転バージョンを生成し、それが最初の単語の中に含まれているかを調べます。含まれていればTrueを返し、そうでなければFalseを返す、という仕組みになっています。
このコードのポイントは「回転」の操作で、b[i:] + b[:i]という部分で文字列を切り取り、接続することで回転を実現しています。そして、a.find(rotated_b)が-1でないかどうかで判定しています。この条件式は、回転された文字列が最初の文字列に含まれている場合を示します。

この図は、Pythonのコードの一部を示しています。与えられた数値の偶数と奇数の桁数を数えて、それをタプルとして返す関数を表しています。
コードの構成を簡単に説明します。まず、数値の絶対値を取得して文字列に変換し、その各桁を取り出します。次に、その桁を整数に変換し、偶数か奇数かを判定します。偶数であれば`even_count`を増やし、奇数であれば`odd_count`を増やす仕組みになっています。
最終的に、偶数と奇数のカウントをタプル形式で返すことで、与えられた数値の構成を数値の観点から理解できるようにしているのです。このコードは、数値の分析や統計を行う際に便利です。

この図は、ある行列に関する数学の問題を解決する過程を示しています。問題では、行列 \( A \) が与えられていて、二つの異なるベクトルを用いてその行列の計算結果が示されています。そして、ユーザーは新たなベクトルに対する行列 \( A \) の作用を求める必要があります。
まず、1回目の解答では、スカラー \( a \) と \( b \) を使って、ベクトルを2つの既知のベクトルの線形結合として表現しようとしています。しかし、最初の解答では計算ミスがあり、誤った結果が得られています。
次に、2回目の解答では、同じ手法を用いてこのベクトルを再び \( a \) と \( b \) に変換し、方程式系を構築します。この過程で、方程式を正しく解き、それぞれの \( a \) と \( b \) の値を求めます。その結果をもとに行列計算を行い、正しい最終的な答えを導き出しています。
この図は、行列計算における線形結合の方法を用いて問題を解決する流れを視覚的に示しており、誤った試行とその修正過程が分かりやすく描かれています。

この図は、SCoReという自己修正アルゴリズムを説明するための例です。
最初の例題では、数学の式を簡約化する問題が示されています。最初の試行では、正しい答えが得られませんでした。具体的には、分数の計算において、割り算と掛け算のステップが間違っていました。続くSCoReによる二度目の試行では、計算の誤りが修正され、正しい答えが得られています。このプロセスを通じて、モデルがどのように間違った部分を見つけ出し、正しい結論に導いているかを示しています。
次の例題では、多項式の根についての問題が出されています。最初の試行では、公式を用いて数値を計算しましたが、最小の絶対値を求める部分で間違いが発生しました。SCoReによる二度目の試行では、計算のアプローチを修正し、論理的に根を評価することで、正しい最小値を見つけ出すことに成功しています。
これらの例は、SCoReが自己修正を通じて問題解決能力を向上させる様子を示しています。数式やロジックの誤りを自ら検出し、より良い答えを出すためのアルゴリズムの効果を視覚的に理解しやすくするためのものです。

この図は、数学の問題を解く際に、モデルがどのように解答を導き出すかを示しています。問題は、\((x + 5)(x + 2)/(x + 1)\) の最小値を求めることです。初めの試行では、モデルはこの式を展開し、部分的な簡約を試みますが、誤った結論に至ります。数式の変形によって、誤った最小値が6であるとします。これは、導かれる際に誤った計算が含まれており、正しい値に至っていません。このように、モデルが自己修正を試みて解を見つける過程が示されています。この例は、初めの回答が誤っている場合でも、再度考え直し、修正しようとする試みを示しているのです。

この画像では、SCoReというアプローチを用いた問題解決の例が示されています。ここでは、数式 (x + 5)(x + 2)/(x + 1) の最小値を求める問題について議論しています。
まず、分母と分子を分けて考え、この式を単純に変えています。数式 (x + 5)(x + 2)/(x + 1) は、(x^2 + 7x + 10)/(x + 1) に展開され、その後さらに部分的に (x^2 + x) + (6x + 6) + 4 に分けられています。この分解をもとにして、(x + 1)(x + 6) + 4/(x + 1) という形に簡約化されました。最終的に、この式は x + 6 + 4/(x + 1) となります。
次に、x が 0 より大きいという条件に基づきます。これにより、x + 1 は 1 より大きくなり、4/(x + 1) は 4 より小さくなるため、(x + 5)(x + 2)/(x + 1) は x + 6 より大きいと結論づけられます。
したがって、x が正の値であるとき、この式の最小値は 6 より大きくなることがわかります。この結果として、x + 6 + 4/(x + 1) の最小値は6です。



この記事に関するカテゴリー





