煙でイラストを描く!流体と絵の鮮やかな合成画像の生成
論文:Transport-Based Neural Style Transfer for Smoke Simulations
画画像から”スタイル”を抜き出し別の画像に合成する”スタイル変換”の技術は、AIの得意分野の一つです
これまでにも人工知能を用いた画像認識やスタイル変換は様々試みられてきました。その中でも、この論文では”流体”のスタイル変換に取り組んでいます。
”流体”における特徴量抽出では様々な最適化が行われてきましたが、そのほとんどは手計算のハイパーパラメータも多く計算量は膨大になりがちでした。そのため、”流体”のコントロールは依然として課題と言えます。
今回紹介する手法では、”流体の画像”をベクトル表現を用いて鮮やかに特徴抽出し、他の画像にそのパターンを合成することを目標とします。
このスタイル変換アルゴリズムを用いれば、例えば、ウサギの絵をまるで煙で描かれているように変換することが可能になります。

流体画像の鮮やかな表現とコントロール
従来の方法と異なる点として以下の2つの点があります。
(1) 流体画像の連続的な特徴を再現する速度場のベクトル表現
(2)パターン合成の曖昧さの双方向へのコントロール
(1)は、これまでのCNN画像認識モデルの多くが特徴量抽出や勾配計算に関数(スカラー)を用いていたのに対し、本モデルは画像の鮮やかさの表現にベクトルを採用し、速度場の考え方(grad,div,rotといったベクトル解析の知識など)を利用することでな体の鮮やかな特徴抽出を実現しています。
(2)に関しては元となる画像の原型を、合成の際にどこまで保つかの曖昧さ(ボカシ具合)をコントローラブルにします。CNNの層の深さを変更することでこれら調整を実現します。
また、流体のデータが少ないため、学習段階においては画像分類作業のCNNから転移学習させたモデルを用いています。
転移学習とは?
転移学習とは、他実験で大規模データを事前学習したモデルの重みを用いて、似た特徴データを取り扱う実験を少ないデータ数で学習する手法のことを言います。これにより、モデルは実験に必要なデータが足りない場合でも、十分な精度で学習することができます。より具体的には、入力層から出力層にかけて抽出する特徴は細かくなっていのだから、大まかな特徴表現の学習を他データによる学習で済ませてしまおう、ということになります。今回は、煙からの特徴抽出に加え、その特徴パターンと画像の合成アルゴリズムは転移学習されたCNNを使用します。
実験結果
(i)画像と”スタイル”の合成, (ii) 曖昧さのコントロールによる比較, (iii)既存モデルとの比較の3つの評価で行っています。
(i)画像と”スタイル”の合成
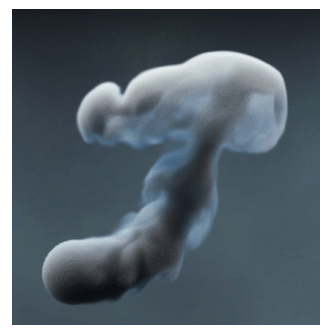
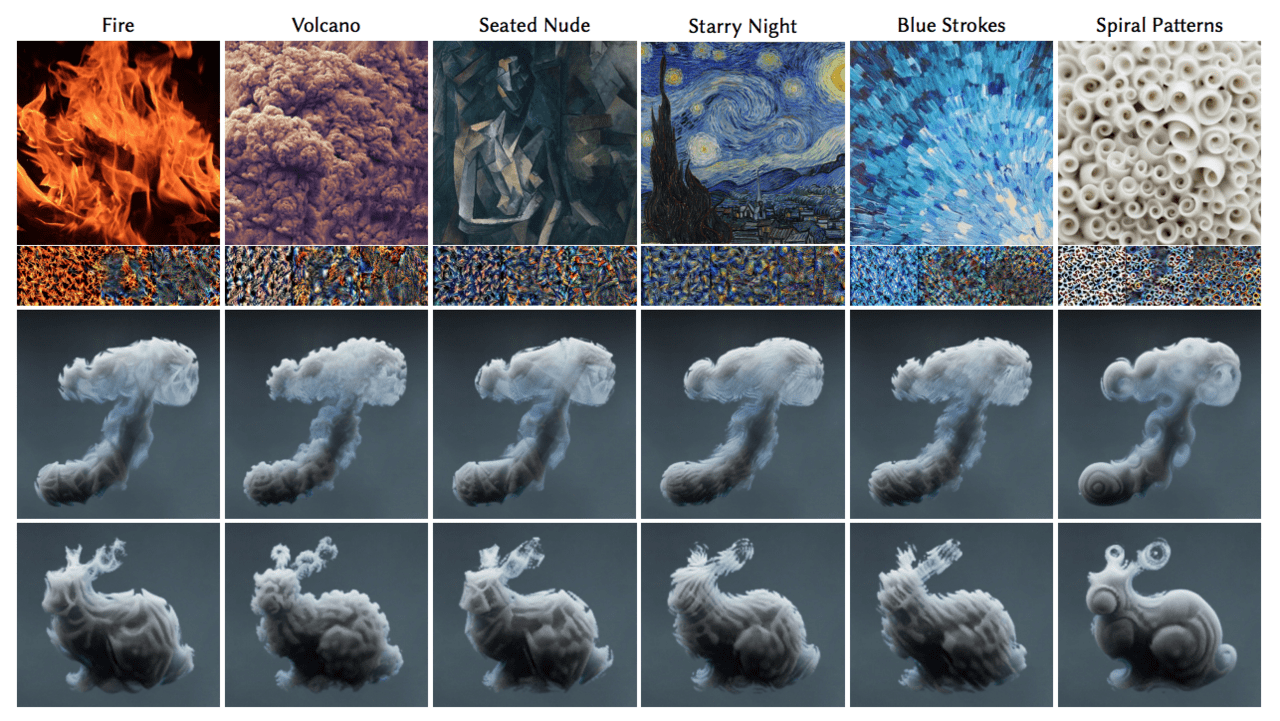
インプットをキノコ型の煙と、兎の画像としました。加えて各スタイルを入力し、特徴量を抽出することで認識されたパターンを画像と合成させます。
上記画像の結果から、一目見てわかるクオリティで各画像がスタイルを取り入れ、特徴を表していることがわかります。
(ii)曖昧さのコントロールによる比較

(i)と同様の入力画像に対して、CNNの深さを変えることにより、合成の曖昧さを変更することができます。
画像①と画像②を比較すると、わずかながら②の方が各入力画像の原型を保っていることがわかります。(特にうさぎ)
この実験では、異なるスタイルではなく同条件において、曖昧さのみを差別化し比較実験を行うことができれば、より明確な結果が得られた気がします。
(iiI)既存モデルとの比較
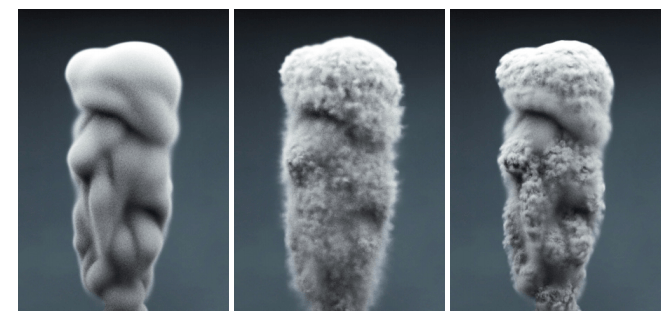
あるモチーフに対し、毛皮のスタイルの合成を行いました。左から順に、元画像、既存モデルによる合成画像、最新(今回)モデルによる合成画像となります。
最新モデルは、既存モデルに比べて入力画像の形状をより詳しく再現しており、かつ毛皮のスタイルを細かく表現していることがわかります。定量的な分析に置いても、既存のシュミレーションの解像192×256×192と比較し、最新のモデルのシュミレーションでは200×300×200と各方向成分において確実に解像度を上昇させることができました。
まとめ
煙などの”流体”からイメージを取り出し、別画像との合成を行う新たなスタイル変換モデルを紹介しました。膨大な量の流体的モチーフからモデルを用いて特徴量を抽出し、自動的に具体化することを可能にしています。このスタイル変換は1,600,000ボクセルまでの高解像度でシミュレーションを行うことができます。
本モデルは流体の”パターン認識”は可能ですが、色の識別などは行なっていないため今後は色の状態も抽出して合成を行う機能の研究も行うと面白いのではないでしょうか。ライター個人としては、前記事で紹介したイメージと文字の合成スタイル変換モデル(参考 : 芸術的な画像と文字の自動合成を可能にする新たなGAN)との組み合わせにより実現可能性がある気がします。



この記事に関するカテゴリー






