追い続けろ!ターゲットとトラッカーを「戦わせる」物体追跡における深層強化学習の新手法
3つの要点
✔️ 複雑なシーンでも物体追跡が可能
✔️ トラッカーとターゲットは一対の「決闘」対戦相手という学習アルゴリズム
✔️ 2Dと3Dの両方で有効性と実用性を実証
AD-VAT: AN ASYMMETRIC DUELING MECHANISM FOR LEARNING VISUAL ACTIVE TRACKING
written by Fangwei Zhong, Peng Sun, Wenhan Luo, Tingyun Yan, Yizhou Wang
(Submitted on 28 Sep 2018 (modified: 07 Jul 2019))
Comments: Published by ICLR 2019
Subjects: Machine Learning
はじめに
今回紹介するのは、ICLR2019にも採用された、深層強化学習を使った物体追跡の論文です。不完全なゼロサム報酬を採用することによって、複雑なシーンでも環境に適応し追跡し続けることを可能にしています。
Visual Active Tracking
Visual Active Tracking(VAT)とは、トラッカー(追跡者)が、ターゲット(標的)を追跡するために、視覚的観察情報に従ってカメラの動きを能動的に制御しながら追跡することです(下の動画をイメージしてもらえば分かりやすいです)。主に、無人機によるビデオの撮影や人物撮影、または多くのロボットの分野に有用です。

図1End to end Active Object Tracking and Its Real world Deployment via Reinforcement Learning
VATでは、ターゲットから一定の距離を維持した、アクティブな視覚追跡が必要ですが、このようなアクティブな視覚追跡を達成するために、トラッカーは、物体追跡に加え、カメラ制御も考慮する必要があります。
しかしながら、伝統的な視覚追跡方法の研究では、カメラの動きを制御する方法を考慮せず、ターゲットを抽出することに焦点を合わせているだけでした。
深層強化学習の限界
そこで登場するのが深層強化学習です。
以前の研究では、深層強化学習に基づくエンドツーエンドのVATが提案されており、同時に物体追跡とカメラ制御を行うことに成功しています。
しかしながら、深層強化学習トレーニングに基づくそのような追跡者の性能は、依然としてトレーニング方法によって制限されています。深層強化学習は学ぶために多くの試行錯誤を必要とするので、現実の世界でロボットを直接作ろうとすることコストが高くつきます。一般的な解決策はトレーニングに仮想環境を使用することですが、このアプローチにおける最大の問題は、モデルを実際のアプリケーションに展開できるように、仮想と実世界のギャップを克服しなければならないことです。
大規模で忠実度の高い仮想環境を構築するなど、この問題を解決するためのいくつかの試みはありましたが、環境の多様性を増幅するために様々な要因(表面テクスチャ/光条件など)を使用しなければいけませんでした。
AD-VAT(Visual Active Tracking)
本稿では、VAT(Visual Active Tracking)を学習するための、AD(Asymmetric Dueling mechanism)と呼ばれる、ゲームベースの深層強化学習フレームワークに基づくトレーニングを提案しています。(通称、AD-VAT)
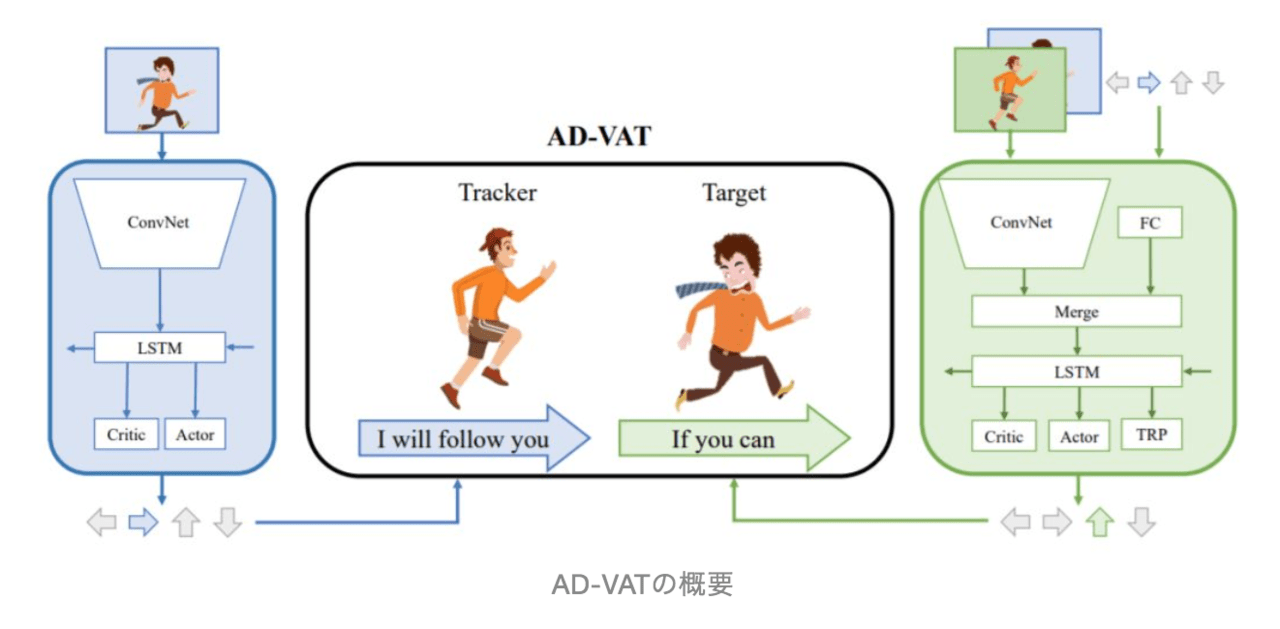
このトレーニングメカニズムでは、トラッカーとターゲットは一対の「決闘」対戦相手として扱われます(上図を参照)。つまり、トラッカーは可能な限りターゲットを追跡する必要があり、ターゲットはトラッキングから外れる道を見つける必要があります。この種の競争メカニズムは、互いに挑戦し合いながら互いに促進します。
この、決闘/敵対的メカニズムにより、ターゲットはトラッカーの弱点をより頻繁に発見しますが、それはトラッカーをより強固にする一種の「弱さの克服」としても役立ち、最終的にそのロバスト性を著しく向上させます。
しかしながら、実際には、VATを訓練するために敵対的RL法を使用することは不安定であり、収束するのが遅いという課題があります。この問題に対処するために、論文では、訓練を安定させる追加の補助的なタスクを2つ装備しています。
AD-VATでは「部分的なゼロサム報酬(PZR)」と「トラッカー認識モデル(TAM)」を導入します。ゼロサム報酬は、トラッカーとターゲットが特定の相対範囲内でゼロサムゲームを行うことを奨励するハイブリッド報酬構造で、ターゲットが一定の距離に達すると、追加のペナルティが与えられます。つまり、報酬はターゲットがトラッカーから逃げたときにトラッカーがターゲットを観察することができないという現象を回避するように設計されています。そのため、このゲームは不完全ゼロサム報酬と呼ばれます。
一方、ターゲットに逃げるための最適な方針を学ばせるために、トラッカーを意識した、「トラッカー認識モデル(TAM)」を用いて、ターゲットに、自身の観察に加えて、ドラッカーの観察や行動を学ばせます。
具体的には、ターゲット自身の視覚的観察に加えて、トラッカーの観察と運動出力がターゲットネットワークに入力として追加されます。トラッカーの戦略を知っていると、ターゲットはトラッカーよりも「より強く」なります。
さらに、トラッカー側の即時の報酬を予測するさせるために、ターゲットに補助タスクを追加します。
このような「非対称対決」メカニズムからより強いターゲットを生成することができ、最終的にはそれがより強いトラッカーを生み出します。
実験環境
方法の有効性を検証するために、さまざまな異なる2Dおよび3D環境で実験を行いました。2D環境は、障害物、ターゲット、トラッカーなどを表すためにさまざまな値を使用する単純なマトリックスマップです。
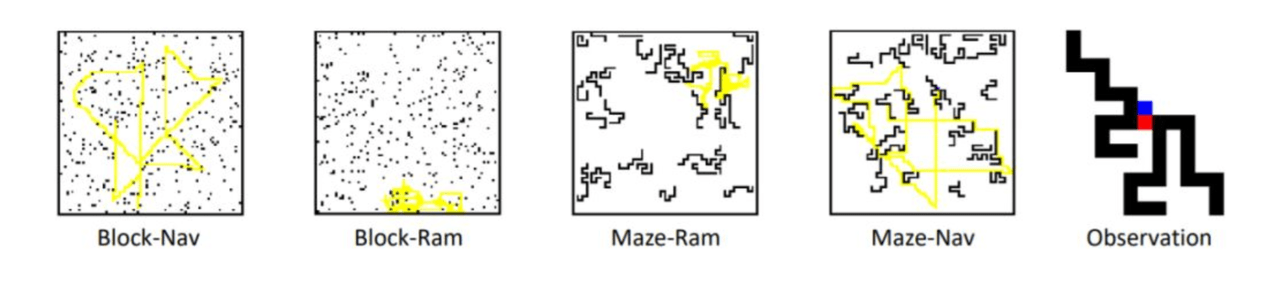
一方、3D環境は、UE4とUnrealCVに基づいて構築された仮想環境です。ドメインランダム化手法を使用する部屋(DR Room、Domain Randomized Room)でトレーニングを行い(環境内のオブジェクトの表面テクスチャと照明条件をランダムに設定できる)、3つの異なるシーンの現実に近いシーンでモデルをテストします。

結果
2D環境では、著者は最初にAD-VATがベンチマーク法と比較して効果的な改善をもたらすことができることを検証しました。
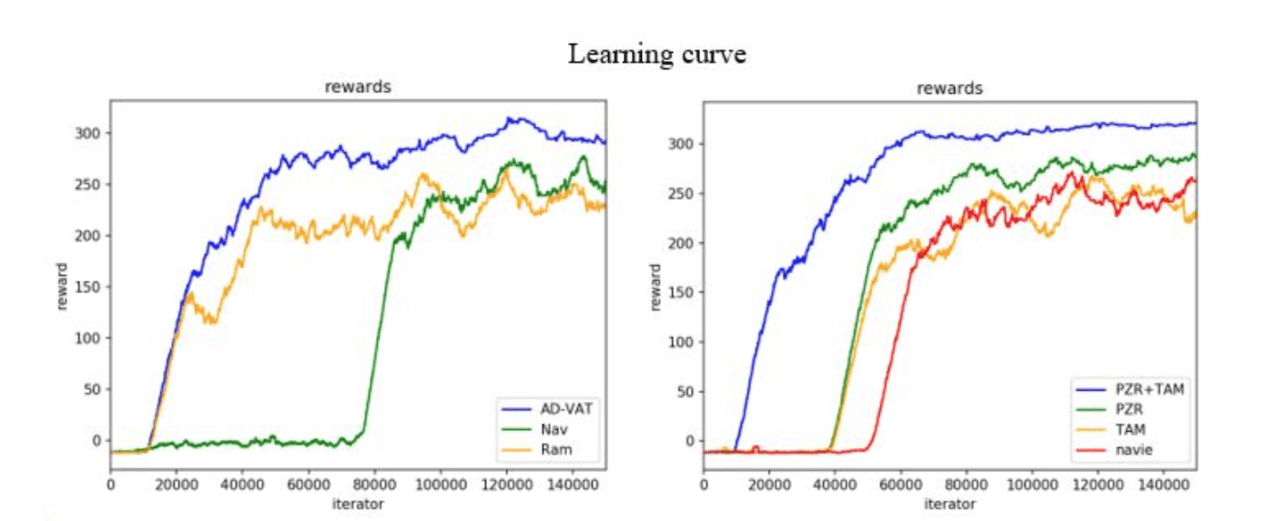
3D環境での実験は、この方法の有効性と実用性をさらに実証しています。
トレーニングプロセス中に、、ターゲットが、追跡者を混乱させるための「ステルス」効果を達成するために、ターゲットはそれ自身のテクスチャに近い背景の領域に行く傾向があります。トラッカーは、絶えず「ストリーミング」された後、最終的にこれらの状況に適応することを学びます。

その中でも、Snow VillageとParking Lotは2つの非常に困難な環境です。
snow villageは地面が険しく、カメラが雪の落下、バックライトなどの要因でターゲットがブロックされがちです。

駐車場内の光は不均等に分散され(明暗の変化)、ターゲットは列によって遮られる可能性があります。

各モデルのパフォーマンスはさまざまな程度に低下していますが、本稿で提案されたモデルはより良い結果を達成しました。AD-VATトラッカーが複雑なシーンにより適応可能であることを示しています。
今後の研究としては、より複雑な環境に耐えうるVATを開発することや(例えば、多数の障害物がある環境や、移動する障害物がある環境) 、動く物体をつかむことができるトラッカーの開発を目標としているそうです。
交通×ディープラーニング 。信号機にDQNを用いて、交通渋滞を改善させる
また出た!パワーワード「〇〇 is All You Need」強化学習の最新手法、報酬機能なしでスキルを独学
 AI(人工知能)への注目度は、年々高まっています。そのため一部企業では、日本ディープラーニング協会の主催する「G検定」「E資格」の社内合格者を公開して、自社のAIに関する知見をアピールする動きも出てきています。
AI(人工知能)への注目度は、年々高まっています。そのため一部企業では、日本ディープラーニング協会の主催する「G検定」「E資格」の社内合格者を公開して、自社のAIに関する知見をアピールする動きも出てきています。
そう言った人材がいることもAI開発のある意味1つの実績になります。
AI-SCHOLARを読んでいる読者は、今こそE資格を取得し、早めに自分のスキルアップを狙っていきましょう!
企業においてはある調査で、AI開発に成功している企業は社員全体のAIに対する知識レベルが高いそうです。
AI開発やAIを用いる社会になる今こそ企業は社員のAIレベルをあげましょう!



この記事に関するカテゴリー






